Position: RL Researchers Need to Distinguish Between Solving Simulators and Using Simulators as a Proxy
Pith reviewed 2026-06-30 01:26 UTC · model grok-4.3
The pith
RL researchers need to distinguish between solving simulators and using simulators as a proxy for learning in deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
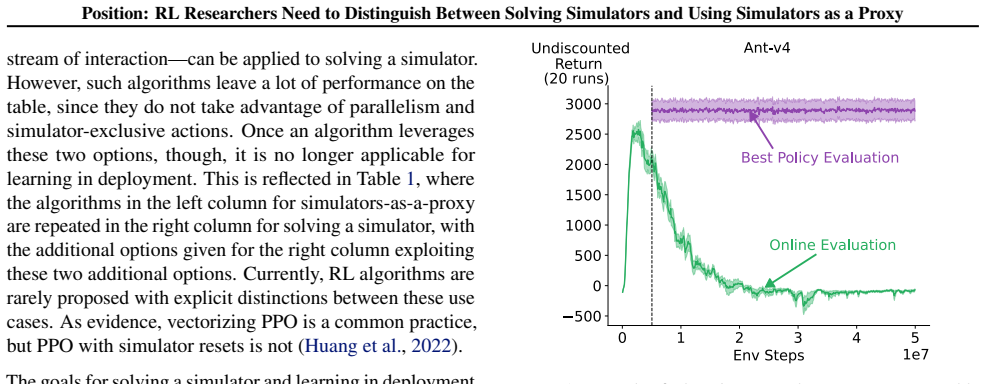
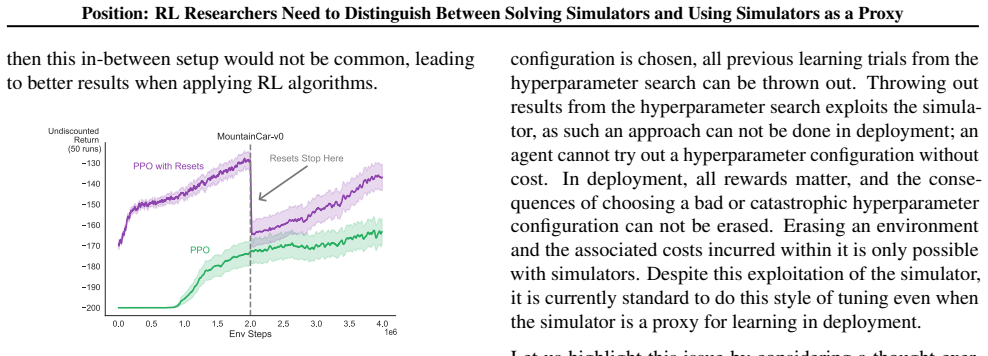
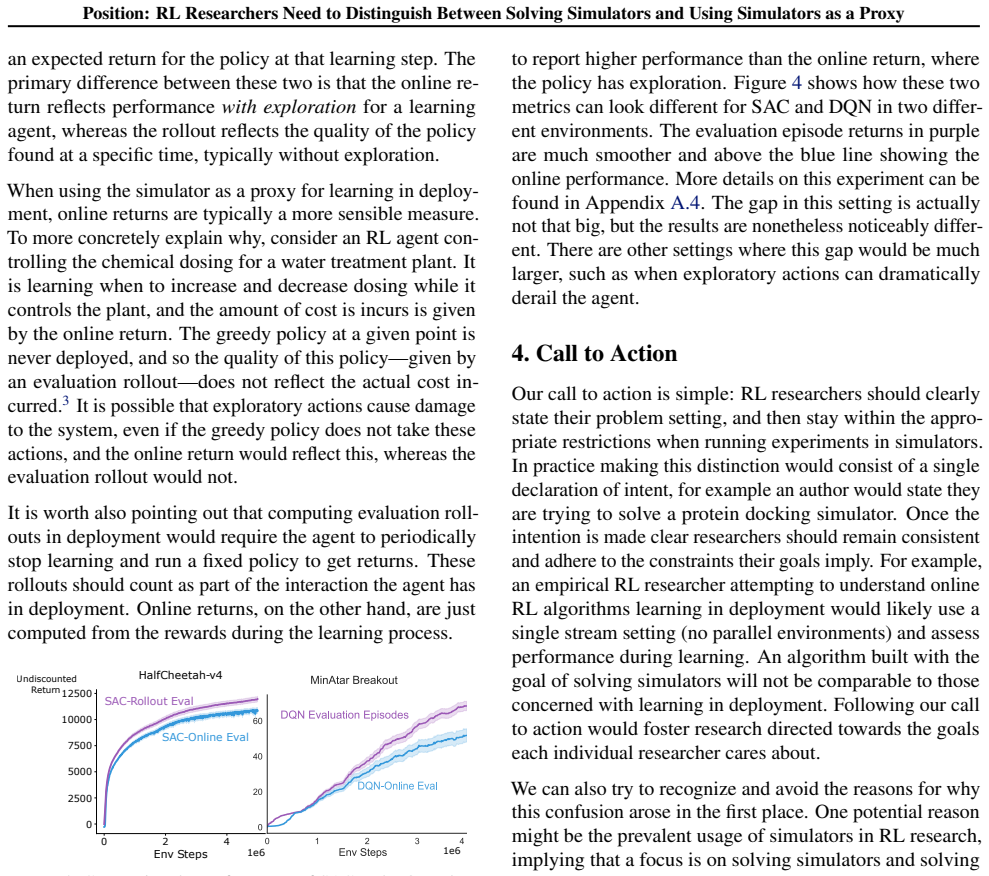
The central claim is that RL researchers need to distinguish between two use cases of simulators: solving simulators and using simulators as a proxy for learning in deployment. These two settings differ in the constraints placed on how the agent may interact with the simulator, in the algorithms that are appropriate, and in the evaluation metrics that make sense. Failing to keep the distinction clear allows solutions meant only for the simulator to be presented as progress toward deployable agents and produces misleading conclusions about research progress, as shown by examples and simple experiments. The work is a call for the community to begin stating clearly how simulators are being used
What carries the argument
The distinction between solving simulators (optimizing performance inside the given environment) and using simulators as a proxy (developing policies intended for use outside the simulator in deployment).
If this is right
- Algorithms developed under one use case may violate the access constraints of the other.
- Evaluation metrics chosen for simulator solving can overstate progress toward deployment.
- Research conclusions about general-purpose sequential decision making can rest on methods that only work inside the simulator.
- Published work would become clearer if authors stated which use case they address.
Where Pith is reading between the lines
- Benchmark suites could add separate tracks or reporting requirements for each use case to reduce mismatched comparisons.
- The distinction highlights why some high simulator scores fail to translate when the simulator is removed at test time.
- Similar separation of goals may be useful in other simulation-heavy fields such as robotics control.
Load-bearing premise
That failing to distinguish the two simulator use cases produces issues and misleading conclusions in RL research.
What would settle it
An experiment in which methods developed under one use case are applied to the other and no differences appear in outcomes, constraints, or conclusions.
Figures

read the original abstract
One goal in reinforcement learning (RL) research is to understand general-purpose sequential decision-making, using benchmark simulators as a proxy for learning in deployment settings. When running experiments, however, the goal of achieving high performance in the simulator can mutate into focusing exclusively on solving the simulator. To achieve high scores, researchers may adopt solutions exclusively meant for solving simulators, rather than learning while the agent is deployed outside a simulator. Solving simulators is also worthy of investigation, but it is a fundamentally different RL research question. In this paper, we argue that RL researchers need to distinguish between two use cases of simulators: solving simulators and using simulators as a proxy for learning in deployment. We first discuss how these two use-cases are importantly different, in terms of constraints on how the agent can use the simulator, which algorithms are appropriate, and which evaluation metrics are appropriate. We then highlight several issues and misleading conclusions that can occur by not making the distinction between these two settings clear, supported with examples and simple experiments. This work is a call to the community to begin clearly distinguishing how they are using simulators in their work, hopefully sparking further discussion on which empirical practices work best in each setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper claims that reinforcement learning (RL) research often conflates two distinct uses of simulators: solving the simulator (achieving high performance within it) versus using it as a proxy for learning deployable policies. The authors argue these use cases differ in terms of simulator access constraints, appropriate algorithms, and evaluation metrics. They support this by discussing the differences and highlighting issues from not distinguishing them, backed by examples and simple experiments, calling for clearer practices in the community.
Significance. If adopted, the proposed distinction would improve clarity in RL experimental design and reduce the risk of misleading conclusions from simulator-specific optimizations that do not transfer. The manuscript earns credit for its explicit enumeration of differences across constraints, algorithms, and metrics, as well as for grounding the normative argument in illustrative examples rather than unsubstantiated assertion.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive recommendation to accept the manuscript. Their summary accurately captures the core argument of the position paper.
Circularity Check
No circularity: position paper with no derivation chain
full rationale
This is a normative position paper arguing that RL researchers should distinguish 'solving simulators' from 'using simulators as a proxy for deployment.' It enumerates differences in constraints, algorithms, and metrics, then illustrates issues with examples and simple experiments. No equations, fitted parameters, theorems, or quantitative predictions are asserted that could reduce to inputs by construction. The load-bearing content is definitional and argumentative rather than deductive, so no self-definitional, fitted-input, or self-citation circularity applies. The paper is self-contained against external benchmarks as a call for clearer terminology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current RL research practices often conflate solving simulators with using them as proxies.
Reference graph
Works this paper leans on
-
[1]
Akhilan Boopathy, Aneesh Muppidi, Peggy Yang, Abhiram Iyer, William Yue, and Ila Fiete
Bonnet, C., Luo, D., Byrne, D., Surana, S., Abramowitz, S., Duckworth, P., Coyette, V ., Midgley, L. I., Tegegn, E., Kalloniatis, T., Mahjoub, O., Macfarlane, M., Smit, A. P., Grinsztajn, N., Boige, R., Waters, C. N., Mimouni, M. A., Sob, U. A. M., de Kock, R., Singh, S., Furelos-Blanco, D., Le, V ., Pretorius, A., and Laterre, A. Jumanji: a diverse suite...
- [2]
-
[3]
Go-explore: a new approach for hard-exploration problems.arXiv preprint arXiv:1901.10995, 2019
Ecoffet, A., Huizinga, J., Lehman, J., Stanley, K. O., and Clune, J. Go-explore: a new approach for hard- exploration problems.arXiv preprint arXiv:1901.10995,
-
[4]
Jayawardana, V ., Tang, C., Li, S., Suo, D., and Wu, C
URL https: //iclr-blog-track.github.io/2022/03/ 25/ppo-implementation-details/. Jayawardana, V ., Tang, C., Li, S., Suo, D., and Wu, C. The impact of task underspecification in evaluating deep rein- forcement learning. InAdvances in Neural Information Processing Systems,
2022
-
[5]
Luo, J., Paduraru, C., V oicu, O., Chervonyi, Y ., Munns, S., Li, J., Qian, C., Dutta, P., Davis, J. Q., Wu, N., et al. Con- trolling commercial cooling systems using reinforcement learning.arXiv preprint arXiv:2211.07357,
-
[6]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MinAtar: An Atari-Inspired Testbed for Thorough and Reproducible Reinforcement Learning Experiments
Young, K. and Tian, T. Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments.arXiv preprint arXiv:1903.03176,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[8]
The hyper- parameters used are the same hyperparameters as (Dohare et al., 2023). A.2. PQN Experiment To produce figure 2 we first ran PQN using the default hy- perparameters as specified in the configuration files on its official Github page (Gallici et al., 2025). We then changed only the number of environments to 1 within the configu- ration to produce...
2023
-
[9]
For both algorithms we report the online return. A.4. Evaluation Rollouts Experiment For this experiment we ran SAC and DQN using both online and evaluation rollouts/episodes. For SAC our evaluation episodes consisted of deterministic action selection rather Hyperparameter Name Value Observation Normalization False Reward Normalization False Advantage Nor...
2048
-
[10]
We used the Half-Cheetah MuJoCo environ- ment (Todorov et al., 2012)
than sampling. We used the Half-Cheetah MuJoCo environ- ment (Todorov et al., 2012). We run for five million steps over 30 seeds, plotting both the evaluation episode returns and the online return. The hyperparameters used for the SAC experiments in Figure 4 are shown in Table
2012
-
[11]
The hyperparameters used are listed in table
in Gymnax (Lange, 2022), running for 4,000,000 steps, plotting the evaluation and online return. The hyperparameters used are listed in table
2022
-
[12]
13 Position: RL Researchers Need to Distinguish Between Solving Simulators and Using Simulators as a Proxy Hyperparameter Name Value Observation Normalization False Reward Normalization True Advantage Normalization True Gradient Clipping False Value Loss Clipping False Rollout Length 2048 Epochs 10 Minibatch size 256 λ0.95 Discount factor,γ0.99 Clip Coeff...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.