Constrained Diffusion Models with Primal-Dual Inference
Pith reviewed 2026-06-27 03:40 UTC · model grok-4.3
The pith
Diffusion models sample constrained optimal distributions by jointly inferring the dual variable during generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Primal-dual inference performs constrained diffusion sampling by denoising with the score field of the current dual-conditioned Gibbs distribution and then updating the dual multiplier via ascent on the observed constraint violation, so that the time-averaged dual converges to a neighborhood of the optimum while the effect of any residual mismatch on the final distribution remains bounded by schedule-dependent factors.
What carries the argument
The dual-conditioned score network, trained once over the family of Gibbs distributions indexed by the dual variables encountered during inference, which supplies the score field for each reverse step and enables the joint primal-dual trajectory.
If this is right
- The terminal samples satisfy the average constraints up to a factor that depends on the diffusion schedule.
- The same trained network supports sampling for any dual value encountered in the trajectory without retraining.
- The method applies directly to wireless resource allocation and portfolio management problems with average constraints.
- Convergence holds for the time average of the dual variables rather than requiring pointwise convergence at every step.
Where Pith is reading between the lines
- The same conditional-score idea could be tested in non-diffusion generative models that admit a score or energy formulation.
- Online dual updates during generation may reduce the need for separate constraint-projection layers in other sampling pipelines.
- Schedule-dependent stability bounds suggest that faster or slower diffusion schedules could be chosen to tighten the final constraint satisfaction.
Load-bearing premise
One network conditioned on the dual variable can accurately approximate the score for every Gibbs distribution that arises along the inference trajectory.
What would settle it
Run the method on a constrained mixture-of-Gaussians task until the time-averaged dual is within the proven neighborhood of the optimum, then measure whether the empirical constraint violation of the terminal samples exceeds the schedule-dependent bound; a consistent excess would falsify the stability claim.
Figures
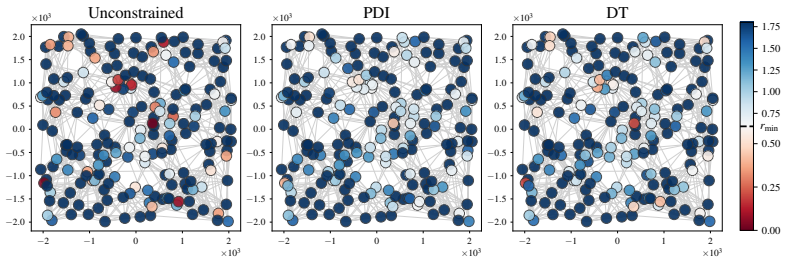
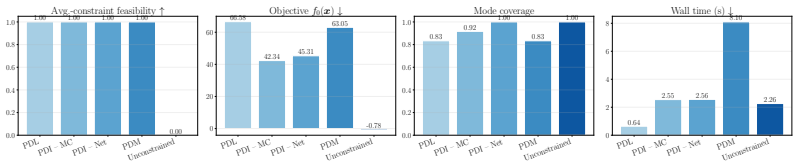
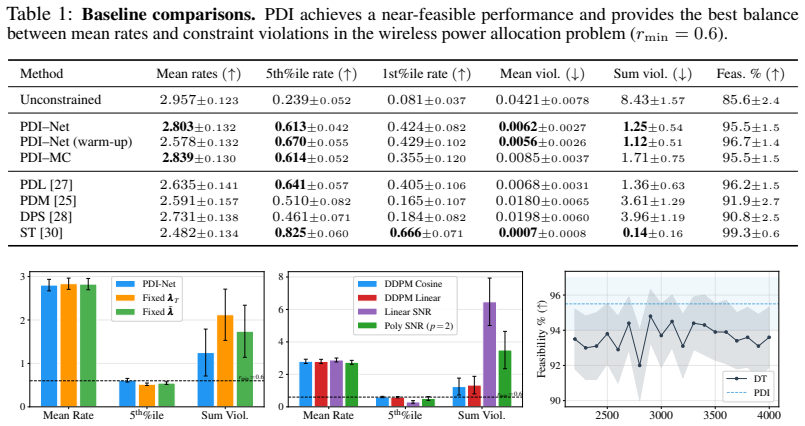
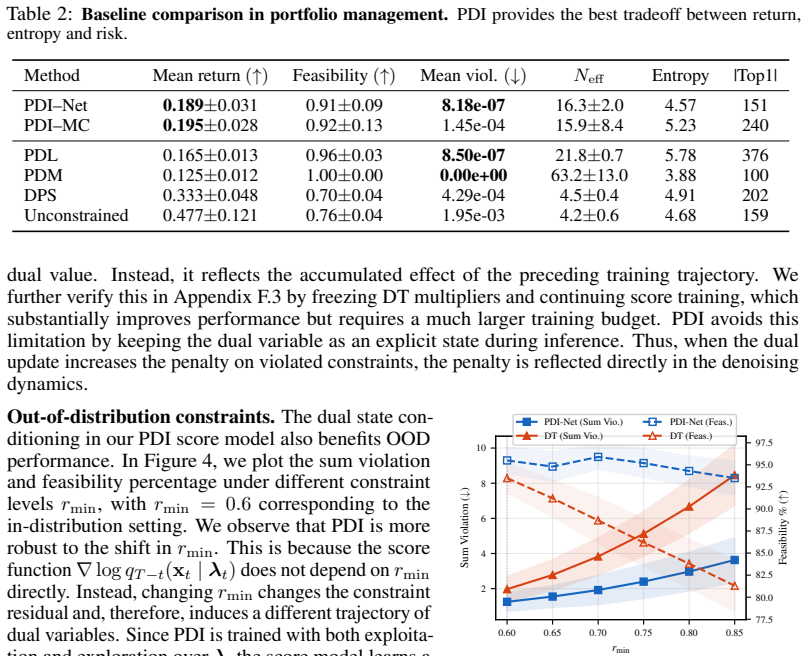

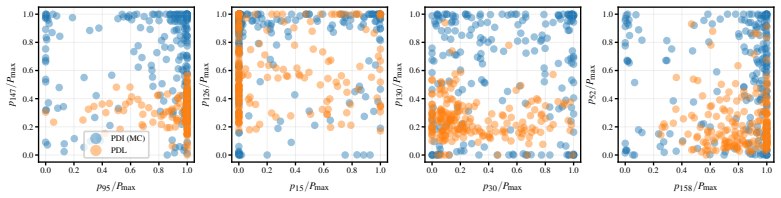
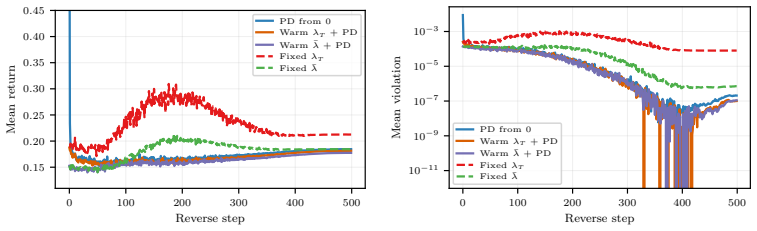
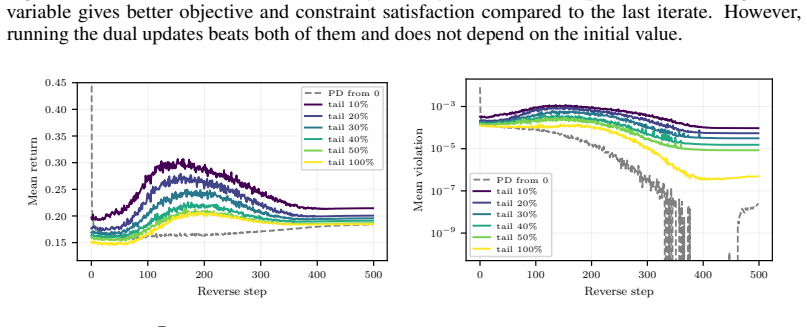
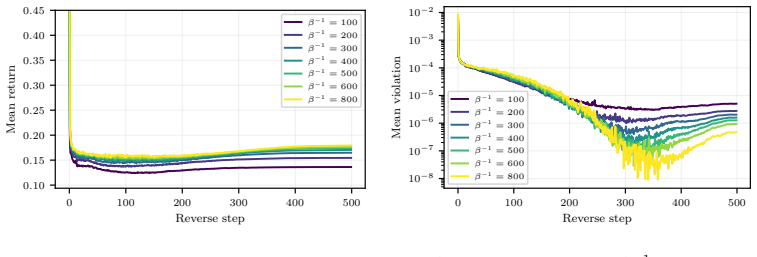
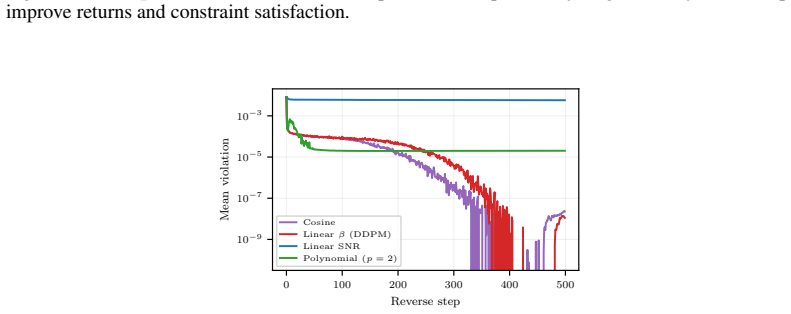
read the original abstract
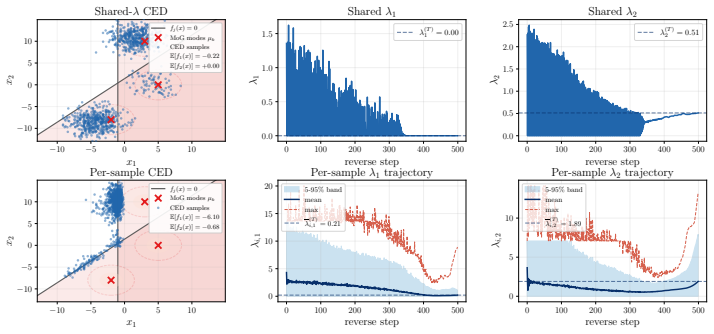
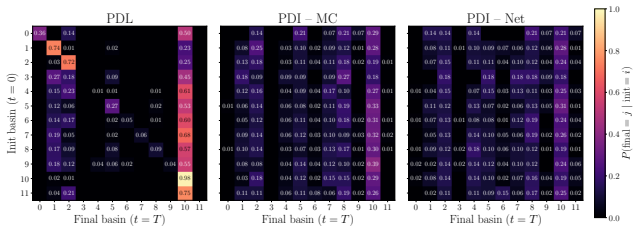
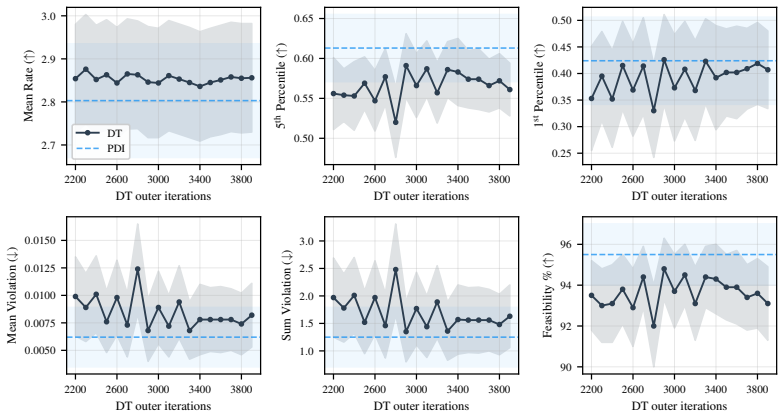
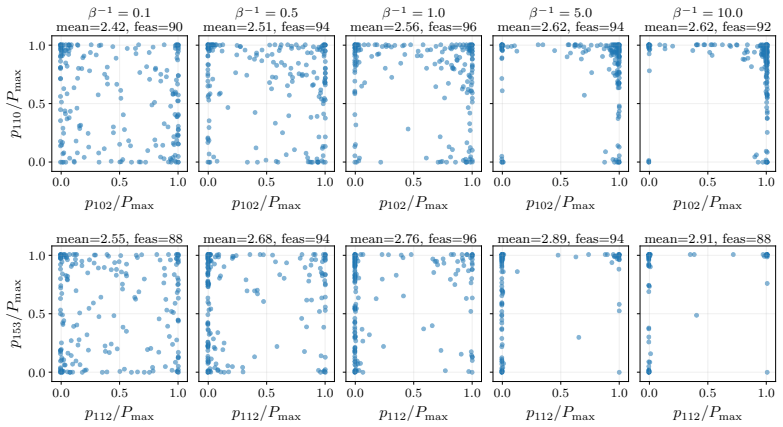
This paper develops constrained diffusion models with primal-dual inference (PDI) to sample from optimal distributions of entropy-regularized optimization problems with \emph{average} constraints. We formalize constrained sampling in the Lagrangian dual domain, where the optimal distribution takes the form of a Gibbs distribution indexed by the optimal dual variable. Rather than estimating this dual multiplier before sampling and freezing it throughout generation, PDI jointly infers the optimal primal distribution and its parametrizing dual variable. Each reverse diffusion step denoises using the score field associated with the current multiplier and then updates the multiplier through dual ascent using the estimated constraint violation of the denoised samples. To enable this conditional score field, we train a single dual-conditioned score network over the family of Gibbs distributions induced by the dual variables encountered during inference. We prove that the time average of the dual variables generated along the inference trajectory converges to a neighborhood of the dual optimum and bound the effect of residual dual mismatch on the terminal distribution through schedule-dependent stability factors. We evaluate PDI on constrained sampling from a mixture of Gaussians, wireless resource allocation, and portfolio management.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces primal-dual inference (PDI) for constrained diffusion models to sample from entropy-regularized problems with average constraints. It formulates the problem in the Lagrangian dual domain, where the target is a Gibbs distribution indexed by the optimal dual variable. PDI performs joint inference by alternating score-based denoising steps (using a dual-conditioned score) with dual-ascent updates on estimated constraint violations. A single dual-conditioned score network is trained over the induced family of Gibbs distributions. The central theoretical result states that the time average of dual variables along the inference trajectory converges to a neighborhood of the dual optimum, with the effect of residual mismatch on the terminal distribution bounded by schedule-dependent stability factors. Empirical evaluation is reported on a mixture of Gaussians, wireless resource allocation, and portfolio management.
Significance. If the convergence result holds with controlled approximation error, the approach would offer a principled alternative to pre-computing and freezing dual multipliers in constrained diffusion sampling. This could improve flexibility for average-constraint problems in generative modeling, with direct relevance to the three evaluated application domains. The combination of a dual-conditioned network, trajectory-based dual updates, and explicit stability bounds on the terminal distribution constitutes the main technical contribution.
major comments (2)
- [Abstract] Abstract and the convergence claim: the proof that the time average of dual variables converges to a neighborhood of the optimum (and the subsequent bound on terminal-distribution mismatch via schedule-dependent stability factors) requires that the single dual-conditioned score network supplies sufficiently accurate scores for every dual value visited along the inference trajectory. No quantitative bound on score approximation error, no restriction on the dual range, and no propagation of that error into the neighborhood size or stability factors are provided.
- [Method (training of dual-conditioned network)] The training procedure for the dual-conditioned score network: the manuscript states that the network is trained over the family of Gibbs distributions induced by dual variables encountered during inference, but supplies no explicit mechanism (e.g., sampling schedule, range restriction, or error metric) that guarantees coverage or controls the approximation quality for duals arising at inference time.
minor comments (2)
- [Method] Notation for the dual-conditioned score field and the precise form of the dual-ascent update should be introduced with explicit equations rather than descriptive text only.
- [Experiments] The three experimental tasks would benefit from an ablation that isolates the effect of joint dual inference versus a fixed dual estimated in advance.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the convergence claim and training procedure. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract and the convergence claim: the proof that the time average of dual variables converges to a neighborhood of the optimum (and the subsequent bound on terminal-distribution mismatch via schedule-dependent stability factors) requires that the single dual-conditioned score network supplies sufficiently accurate scores for every dual value visited along the inference trajectory. No quantitative bound on score approximation error, no restriction on the dual range, and no propagation of that error into the neighborhood size or stability factors are provided.
Authors: The stated convergence result and stability bounds are derived under the assumption of exact scores from the dual-conditioned network. We agree that the manuscript does not provide quantitative error bounds or propagate approximation error into the neighborhood size. In revision we will add an explicit statement of this assumption in the abstract and theory section, along with a remark noting that error propagation is left for future analysis. revision: partial
-
Referee: [Method (training of dual-conditioned network)] The training procedure for the dual-conditioned score network: the manuscript states that the network is trained over the family of Gibbs distributions induced by dual variables encountered during inference, but supplies no explicit mechanism (e.g., sampling schedule, range restriction, or error metric) that guarantees coverage or controls the approximation quality for duals arising at inference time.
Authors: The current description relies on dual variables sampled from ranges observed in preliminary runs, but we acknowledge the lack of an explicit, formalized mechanism such as a fixed sampling schedule or coverage metric. In the revision we will expand the method section to specify the dual sampling distribution used during training and report the empirical range covered on each task. revision: yes
Circularity Check
No significant circularity; derivation relies on standard duality and explicit training assumption
full rationale
The central claim is a mathematical convergence result for the time-averaged dual variables along the PDI trajectory, together with a bound on terminal-distribution mismatch via schedule-dependent stability factors. This rests on Lagrangian duality and dual-ascent updates applied to estimated constraint violations. The training procedure for the single dual-conditioned score network is stated as covering the family of Gibbs distributions induced by encountered duals, but the convergence statement itself is not obtained by fitting a parameter to the same data or by redefining a quantity in terms of its own output. No self-citation chain, uniqueness theorem imported from prior author work, or ansatz smuggled via citation appears in the provided text. The result is therefore self-contained against external benchmarks of convex duality and diffusion score matching.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard assumptions of diffusion processes and score matching hold for the family of dual-conditioned distributions.
- domain assumption Dual ascent on the estimated constraint violation produces a convergent trajectory under the chosen step-size schedule.
Reference graph
Works this paper leans on
-
[1]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inProceedings of the 32nd International Conference on Machine Learning(F. Bach and D. Blei, eds.), vol. 37 ofProceedings of Machine Learning Research, (Lille, France), pp. 2256–2265, PMLR, 07–09 Jul 2015
2015
-
[2]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”arXiv preprint arxiv:2006.11239, 2020
Pith/arXiv arXiv 2006
-
[3]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021
2021
-
[4]
High-Resolution Image Synthesis with Latent Diffusion Models ,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “ High-Resolution Image Synthesis with Latent Diffusion Models ,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Los Alamitos, CA, USA), pp. 10674–10685, IEEE Computer Society, June 2022
2022
-
[5]
Diffwave: A versatile diffusion model for audio synthesis,
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “Diffwave: A versatile diffusion model for audio synthesis,” inInternational Conference on Learning Representations, 2021
2021
-
[6]
Video diffusion models,
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. Fleet, “Video diffusion models,” inAdvances in Neural Information Processing Systems(S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, eds.), vol. 35, pp. 8633–8646, Curran Associates, Inc., 2022
2022
-
[7]
Generative diffusion models for resource allocation in wireless networks,
Y . B. Uslu, S. Hadou, S. S. Bidokhti, and A. Ribeiro, “Generative diffusion models for resource allocation in wireless networks,” in2025 IEEE 10th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), pp. 201–205, IEEE, 2025
2025
-
[8]
Diffusion model based resource allocation strategy in ultra-reliable wireless networked control systems,
A. Babazadeh Darabi and S. Coleri, “Diffusion model based resource allocation strategy in ultra-reliable wireless networked control systems,”IEEE Communications Letters, vol. 29, no. 1, pp. 85–89, 2025
2025
-
[9]
Generative diffusion model for risk-neutral derivative pricing,
N. Tiwari, “Generative diffusion model for risk-neutral derivative pricing,” 2026
2026
-
[10]
Factor-based conditional diffusion model for portfolio optimization,
M. He, X. He, and X. Gao, “Factor-based conditional diffusion model for portfolio optimization,” inNeurIPS 2025 Workshop: Generative AI in Finance, 2025
2025
-
[11]
Path integral sampler: a stochastic control approach for sampling,
Q. Zhang and Y . Chen, “Path integral sampler: a stochastic control approach for sampling,” in International Conference on Learning Representations, 2022
2022
-
[12]
Denoising diffusion samplers,
F. Vargas, W. S. Grathwohl, and A. Doucet, “Denoising diffusion samplers,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[13]
An optimal control perspective on diffusion-based generative modeling,
J. Berner, L. Richter, and K. Ullrich, “An optimal control perspective on diffusion-based generative modeling,”Transactions on Machine Learning Research, 2024
2024
-
[14]
Improved sampling via learned diffusions,
L. Richter and J. Berner, “Improved sampling via learned diffusions,” inThe Twelfth Interna- tional Conference on Learning Representations, 2024. 10
2024
-
[15]
Constrained diffusion models via dual training,
S. Khalafi, D. Ding, and A. Ribeiro, “Constrained diffusion models via dual training,”Advances in Neural Information Processing Systems, vol. 37, pp. 26543–26576, 2024
2024
-
[16]
Composition and alignment of diffusion models using constrained learning,
S. Khalafi, I. Hounie, D. Ding, and A. Ribeiro, “Composition and alignment of diffusion models using constrained learning,”arXiv preprint arXiv:2508.19104, 2025
arXiv 2025
-
[17]
Tweedie’s formula and selection bias,
B. Efron, “Tweedie’s formula and selection bias,”Journal of the American Statistical Associa- tion, vol. 106, no. 496, pp. 1602–1614, 2011
2011
-
[18]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Q. Nichol, “Diffusion models beat GANs on image synthesis,” inAdvances in Neural Information Processing Systems(A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, eds.), 2021
2021
-
[19]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[20]
Glide: Towards photorealistic image generation and editing with text-guided diffusion models,
A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image generation and editing with text-guided diffusion models,” 2022
2022
-
[21]
Reflected diffusion models,
A. Lou and S. Ermon, “Reflected diffusion models,” inInternational Conference on Machine Learning, pp. 22675–22701, PMLR, 2023
2023
-
[22]
Mirror diffusion models for constrained and watermarked generation,
G.-H. Liu, T. Chen, E. Theodorou, and M. Tao, “Mirror diffusion models for constrained and watermarked generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 42898–42917, 2023
2023
-
[23]
Riemannian score-based generative modelling,
V . De Bortoli, E. Mathieu, M. Hutchinson, J. Thornton, Y . W. Teh, and A. Doucet, “Riemannian score-based generative modelling,”Advances in neural information processing systems, vol. 35, pp. 2406–2422, 2022
2022
-
[24]
Metropolis sampling for constrained diffusion models,
N. Fishman, L. Klarner, E. Mathieu, M. Hutchinson, and V . De Bortoli, “Metropolis sampling for constrained diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 62296–62331, 2023
2023
-
[25]
Constrained synthesis with projected diffusion models,
J. K. Christopher, S. Baek, and F. Fioretto, “Constrained synthesis with projected diffusion models,”Advances in Neural Information Processing Systems, vol. 37, pp. 89307–89333, 2024
2024
-
[26]
Constrained diffusion with trust sampling,
W. Huang, Y . Jiang, T. Van Wouwe, and C. K. Liu, “Constrained diffusion with trust sampling,” NeurIPS, 2024
2024
-
[27]
Constrained sampling with primal-dual langevin monte carlo,
L. F. Chamon, M. R. Karimi, and A. Korba, “Constrained sampling with primal-dual langevin monte carlo,”Advances in Neural Information Processing Systems, vol. 37, pp. 29285–29323, 2024
2024
-
[28]
Diffusion posterior sampling for general noisy inverse problems,
H. Chung, J. Kim, M. T. Mccann, M. L. Klasky, and J. C. Ye, “Diffusion posterior sampling for general noisy inverse problems,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[29]
A projection method of the cimmino type for linear algebraic systems,
F. Sloboda, “A projection method of the cimmino type for linear algebraic systems,”Parallel Computing, vol. 17, no. 4, pp. 435–442, 1991
1991
-
[30]
Graph signal diffusion models for wireless resource allocation,
Y . B. Uslu, S. Hadou, S. S. Bidokhti, and A. Ribeiro, “Graph signal diffusion models for wireless resource allocation,” 2026
2026
-
[31]
Estimation of non-normalized statistical models by score match- ing.,
A. Hyvärinen and P. Dayan, “Estimation of non-normalized statistical models by score match- ing.,”Journal of Machine Learning Research, vol. 6, no. 4, 2005
2005
-
[32]
Generative modeling by estimating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[33]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations, 2021
2021
-
[34]
Improved denoising diffusion probabilistic models,
A. Q. Nichol and P. Dhariwal, “Improved denoising diffusion probabilistic models,” inInterna- tional conference on machine learning, pp. 8162–8171, PMLR, 2021
2021
-
[35]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,”arXiv preprint arXiv:2206.00927, 2022
arXiv 2022
-
[36]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” inProc. NeurIPS, 2022. 11
2022
-
[37]
Sequential controlled langevin diffusions,
J. Chen, L. Richter, J. Berner, D. Blessing, G. Neumann, and A. Anandkumar, “Sequential controlled langevin diffusions,” 2024
2024
-
[38]
C. Domingo-Enrich, M. Drozdzal, B. Karrer, and R. T. Chen, “Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control,”arXiv preprint arXiv:2409.08861, 2024
arXiv 2024
-
[39]
Improved off-policy training of diffusion samplers,
M. Sendera, M. Kim, S. Mittal, P. Lemos, L. Scimeca, J. Rector-Brooks, A. Adam, Y . Bengio, and N. Malkin, “Improved off-policy training of diffusion samplers,”Advances in Neural Information Processing Systems, vol. 37, pp. 81016–81045, 2024
2024
-
[40]
Gradient guidance for diffusion models: An optimization perspective,
Y . Guo, H. Yuan, Y . Yang, M. Chen, and M. Wang, “Gradient guidance for diffusion models: An optimization perspective,” inAdvances in Neural Information Processing Systems(A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, eds.), vol. 37, pp. 90736– 90770, Curran Associates, Inc., 2024
2024
-
[41]
Diffusion models as constrained samplers for optimization with unknown constraints,
L. Kong, Y . Du, W. Mu, K. Neklyudov, V . D. Bortoli, D. Wu, H. Wang, A. Ferber, Y .-A. Ma, C. P. Gomes, and C. Zhang, “Diffusion models as constrained samplers for optimization with unknown constraints,” 2025
2025
-
[42]
Training diffusion models with reinforcement learning,
K. Black, M. Janner, Y . Du, I. Kostrikov, and S. Levine, “Training diffusion models with reinforcement learning,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[43]
DIFUSCO: Graph-based diffusion solvers for combinatorial optimization,
Z. Sun and Y . Yang, “DIFUSCO: Graph-based diffusion solvers for combinatorial optimization,” inThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[44]
Distributionally robust optimization via diffusion ambiguity modeling,
J. Wen and J. Yang, “Distributionally robust optimization via diffusion ambiguity modeling,” arXiv preprint arXiv:2510.22757, 2025
arXiv 2025
-
[45]
Robust optimization with diffusion models for green security,
L. Kong, H. Wang, Y . Pan, C. W. Kim, M. Song, A. Nguyen, T. Wang, H. Xu, and M. Tambe, “Robust optimization with diffusion models for green security,” inProceedings of the Forty-first Conference on Uncertainty in Artificial Intelligence(S. Chiappa and S. Magliacane, eds.), vol. 286 ofProceedings of Machine Learning Research, pp. 2325–2344, PMLR, 21–25 Jul 2025
2025
-
[46]
Conditional diffusion guidance under hard constraint: A stochastic analysis approach,
Z. Guo, W. Tang, and R. Xu, “Conditional diffusion guidance under hard constraint: A stochastic analysis approach,”arXiv preprint arXiv:2602.05533, 2026
Pith/arXiv arXiv 2026
-
[47]
Mimo channel estimation using score-based generative models,
M. Arvinte and J. I. Tamir, “Mimo channel estimation using score-based generative models,” IEEE Transactions on Wireless Communications, vol. 22, no. 6, pp. 3698–3713, 2023
2023
-
[48]
Joint channel estimation and data detection in massive mimo systems based on diffusion models,
N. Zilberstein, A. Swami, and S. Segarra, “Joint channel estimation and data detection in massive mimo systems based on diffusion models,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 13291–13295, 2024
2024
-
[49]
Deterministic score-based diffusion model for channel estimation in ris-assisted mimo systems,
Z. He, F. Héliot, and Y . Ma, “Deterministic score-based diffusion model for channel estimation in ris-assisted mimo systems,” in2025 IEEE 26th International Workshop on Signal Processing and Artificial Intelligence for Wireless Communications (SPAWC), pp. 1–5, 2025
2025
-
[50]
Generating high dimensional user-specific wireless channels using diffusion models,
T. Lee, J. Park, H. Kim, and J. G. Andrews, “Generating high dimensional user-specific wireless channels using diffusion models,”IEEE Transactions on Wireless Communications, vol. 25, pp. 2907–2921, 2026
2026
-
[51]
Residual diffusion models for joint source channel coding of mimo csi,
S. K. Ankireddy, H. Kim, and H. Kim, “Residual diffusion models for joint source channel coding of mimo csi,” in2025 59th Asilomar Conference on Signals, Systems, and Computers, pp. 55–62, IEEE, 2025
2025
-
[52]
Generative diffusion model-based compression of mimo csi,
H. Kim, T. Lee, H. Kim, G. De Veciana, M. A. Arfaoui, A. Koc, P. Pietraski, G. Zhang, and J. Kaewell, “Generative diffusion model-based compression of mimo csi,” inICC 2025 - IEEE International Conference on Communications, pp. 6323–6328, 2025
2025
-
[53]
Diffusion model for multiple antenna communica- tion,
J. Guo, X. Xu, Y . Liu, and A. Nallanathan, “Diffusion model for multiple antenna communica- tion,”IEEE Communications Magazine, vol. 63, no. 10, pp. 44–50, 2025
2025
-
[54]
Channel-aware conditional diffusion model for secure mu-miso communications,
T. Hui, X. Tang, Y . Wang, Q. Du, D. Niyato, and Z. Han, “Channel-aware conditional diffusion model for secure mu-miso communications,”IEEE Transactions on Vehicular Technology, p. 1–6, 2026
2026
-
[55]
Improve the training efficiency of drl for wireless communication re- source allocation: The role of generative diffusion models,
X. Zhang and J. Yu, “Improve the training efficiency of drl for wireless communication re- source allocation: The role of generative diffusion models,”IEEE Transactions on Wireless Communications, vol. 25, pp. 11593–11608, 2026. 12
2026
-
[56]
Generation of synthetic financial time series by diffusion models,
T. Takahashi and T. Mizuno, “Generation of synthetic financial time series by diffusion models,” Quantitative Finance, vol. 25, no. 10, pp. 1507–1516, 2025
2025
-
[57]
Diffusion-augmented reinforcement learning for robust portfolio optimization under stress scenarios,
H. Choudhary, A. Orra, and M. Thakur, “Diffusion-augmented reinforcement learning for robust portfolio optimization under stress scenarios,” 2025
2025
-
[58]
Forecasting implied volatility surface with generative diffusion models,
C. Jin and A. Agarwal, “Forecasting implied volatility surface with generative diffusion models,” 2025
2025
-
[59]
Iterated denoising energy matching for sampling from Boltzmann densities,
T. Akhound-Sadegh, J. Rector-Brooks, A. J. Bose, S. Mittal, P. Lemos, C.-H. Liu, M. Sendera, S. Ravanbakhsh, G. Gidel, Y . Bengio, N. Malkin, and A. Tong, “Iterated denoising energy matching for sampling from Boltzmann densities,” inInternational Conference on Machine Learning (ICML), 2024
2024
-
[60]
Fast state-augmented learning for wireless resource allocation with dual variable regression,
Y . B. Uslu, N. NaderiAlizadeh, M. Eisen, and A. Ribeiro, “Fast state-augmented learning for wireless resource allocation with dual variable regression,” 2025. 13 A Extended Related Work Diffusion models and score-based generative modeling.Score-based diffusion models learn a stochastic reversal of a progressive noising process by matching the gradients o...
2025
-
[61]
train a single network across noise levels and sample via annealed Langevin dynamics, while denoising diffusion probabilistic models [2] frame generation as iterative Gaussian denoising guided by a simplified ELBO. These formulations are unified in [3] as instances of a common SDE, whose time reversal yields a generative process; and admits an equivalent ...
-
[62]
combined guided diffusion models and Langevin dynamics in a two-stage scheme that learns constrained samplers for optimization with unknown constraints. [42] reinterpreted the denoising chain as a multi-step Markov Decision Process (MDP) and applied policy-gradient methods to fine-tune diffusion models on non-differentiable rewards. Beyond continuous sett...
arXiv 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.