High-Dimensional Theory of LoRA Fine-Tuning in a Solvable Attention Model
Pith reviewed 2026-06-28 02:12 UTC · model grok-4.3
The pith
Pre-training affects LoRA fine-tuning only through an effective noise term whose strength can be minimized by choice of pre-training task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
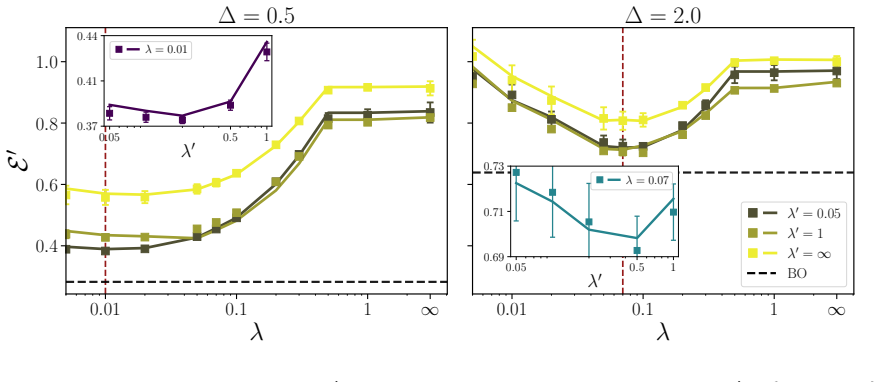
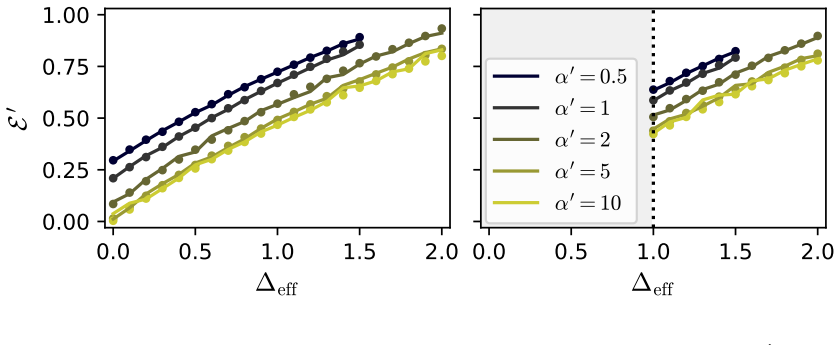
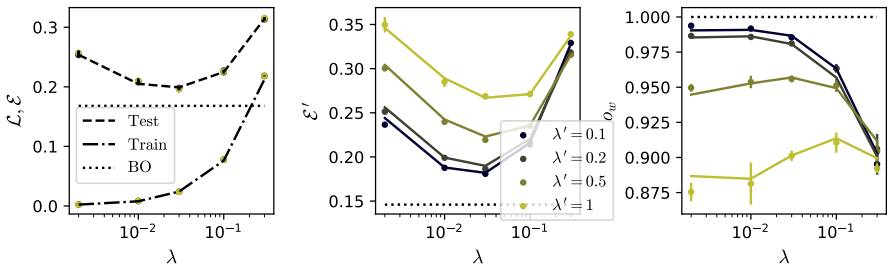
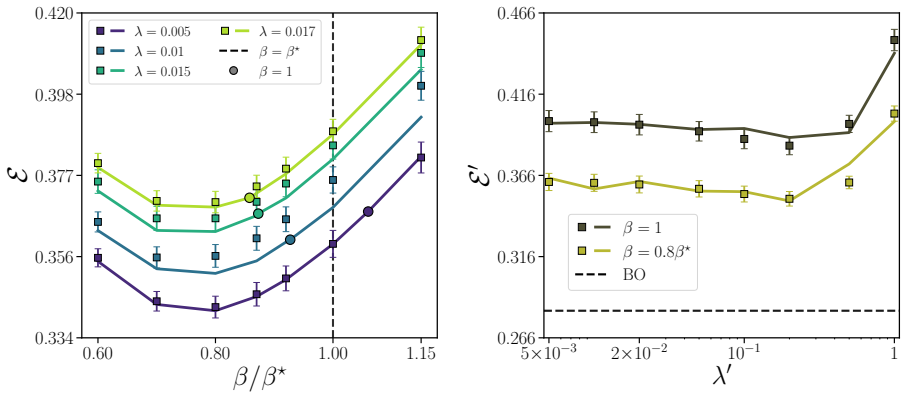
In the solvable attention model, the influence of pre-training on subsequent rank-one LoRA adaptation is fully captured by an effective noise term; the optimal pre-training procedure is the one that minimizes this term, and the same order-parameter equations also reveal a mismatch between test error and representation alignment under certain data regimes.
What carries the argument
The finite set of order parameters that give the exact high-dimensional asymptotics of both the pre-training and the rank-one LoRA fine-tuning stages.
If this is right
- The optimal pre-training task is the one that produces the smallest effective noise variance for the downstream LoRA step.
- Representation alignment and test error can be controlled independently by choice of pre-training data distribution.
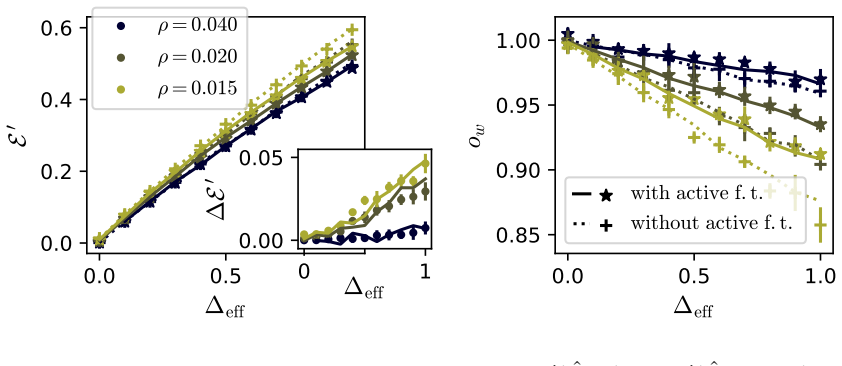
- Active fine-tuning can be performed by selecting examples that most reduce the effective noise felt by the LoRA update.
- The same order-parameter analysis supplies closed-form predictions for test error after any rank-one LoRA update.
Where Pith is reading between the lines
- The reduction to effective noise may extend to other low-rank adaptation schemes beyond rank-one LoRA.
- The mismatch between error and representation quality suggests that representation probes alone may not reliably predict downstream performance after adaptation.
- If the order-parameter equations remain tractable for multi-head or deeper attention stacks, the same noise-reduction principle could guide pre-training of full transformers.
Load-bearing premise
Both the pre-training and the fine-tuning stages admit a sharp asymptotic characterization in terms of a finite set of order parameters in the high-dimensional limit.
What would settle it
Numerical simulation of the solvable attention model at increasing dimension should show the predicted test error and alignment curves converging to the order-parameter formulas; any persistent deviation at large dimension would falsify the reduction to effective noise.
Figures

read the original abstract
We develop a high-dimensional statistical theory of low-rank adaptation (LoRA) in attention models, capturing the interplay between pre-training and fine-tuning. We introduce a solvable framework in which a single-head attention layer is first pre-trained on a data-abundant task and subsequently adapted via a rank-one LoRA update on limited data. In the high-dimensional limit, both stages admit a sharp asymptotic characterization in terms of a finite set of order parameters, yielding explicit predictions for test errors and representation alignment. Our analysis shows that the impact of pre-training on LoRA is summarized by an effective noise term, from which we derive prescriptions for the optimal pre-training procedure. We also demonstrate a regime with a mismatch between the value of the test error and representation quality, and propose an application of our theory to active fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a high-dimensional statistical theory of LoRA fine-tuning in attention models using a solvable single-head attention framework. A model is first pre-trained on abundant data and then adapted via rank-one LoRA on limited data. In the high-dimensional limit, both stages receive sharp asymptotic characterizations in terms of a finite set of order parameters, yielding explicit predictions for test errors and representation alignment. The impact of pre-training is summarized by an effective noise term, from which prescriptions for the optimal pre-training procedure are derived. The work also identifies a regime with mismatch between test error and representation quality and proposes an application to active fine-tuning.
Significance. If the asymptotic characterizations and order-parameter analysis hold, the paper supplies a rigorous mean-field-style framework for the interplay between pre-training and LoRA adaptation. The reduction of pre-training effects to an effective noise term is a potentially useful simplification that could guide practical choices in data-efficient fine-tuning. The mismatch regime and active-learning application add concrete implications beyond the core theory.
minor comments (2)
- [Abstract] The abstract states that both stages 'admit a sharp asymptotic characterization' but does not preview the explicit form of the order-parameter equations or the effective noise term; adding one sentence with the key expressions would improve readability for readers scanning the abstract.
- Notation for the order parameters (e.g., how the effective noise is defined from the pre-training stage) should be introduced with a clear table or list early in the main text to avoid repeated cross-references.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly captures the core contributions of the solvable attention model, the effective noise term, the mismatch regime, and the active fine-tuning application. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper develops a high-dimensional asymptotic analysis of a solvable single-head attention model, characterizing both pre-training and rank-one LoRA fine-tuning via a finite set of order parameters that yield explicit test-error and alignment predictions. The effective noise term summarizing pre-training impact is presented as an output of this two-stage mean-field calculation rather than an input assumption or fitted quantity. No quoted equations or self-citation chains reduce the central claims to tautological redefinitions or statistically forced predictions; the framework is internally consistent with standard high-dimensional statistical mechanics approaches and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. 11
2022
-
[2]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Larous- silhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning, pages 2790–2799, 2019
2019
-
[3]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 4582– 4597, 2021
2021
-
[4]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InAdvances in Neural Information Processing Systems, volume 36, pages 10088–10115, 2023
2023
-
[5]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 7319–7328, 2021
2021
-
[6]
The expressive power of low-rank adaptation
Yuchen Zeng and Kangwook Lee. The expressive power of low-rank adaptation. In International Conference on Learning Representations, 2024. arXiv:2310.17513
arXiv 2024
-
[7]
Yuanhe Zhang, Fanghui Liu, and Yudong Chen. LoRA-one: One-step full gradient could suffice for fine-tuning large language models, provably and efficiently. InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 75513–75574. PMLR, 2025. arXiv:2502.01235
arXiv 2025
-
[8]
Junsu Kim, Jaeyeon Kim, and Ernest K. Ryu. LoRA training provably converges to a low-rank global minimum or it fails loudly (But it probably won’t fail). InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 30224–30247. PMLR, 2025. arXiv:2502.09376
arXiv 2025
-
[9]
Ziqing Xu, Hancheng Min, Lachlan Ewen MacDonald, Jinqi Luo, Salma Tarmoun, Enrique Mallada, and Rene Vidal. Understanding the learning dynamics of lora: A gradient flow perspective on low-rank adaptation in matrix factorization. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258, pages 4636–4644. PMLR,...
arXiv 2025
-
[10]
Zi Liang, Haibo Hu, Qingqing Ye, Yaxin Xiao, and Ronghua Li. Does low rank adaptation lead to lower robustness against training-time attacks? InProceedings of the 42nd Inter- national Conference on Machine Learning, volume 267, pages 37181–37207. PMLR, 2025. arXiv:2505.12871
arXiv 2025
-
[11]
On the convergence rate of lora gradient descent, 2025
Siqiao Mu and Diego Klabjan. On the convergence rate of lora gradient descent, 2025. arXiv preprint arXiv:2512.18248
Pith/arXiv arXiv 2025
-
[12]
When pre-training hurts LoRA fine-tuning: A dynamical analysis via single-index models, 2026
Gibbs Nwemadji, Bruno Loureiro, and Jean Barbier. When pre-training hurts LoRA fine-tuning: A dynamical analysis via single-index models, 2026. arXiv:2602.02855
Pith/arXiv arXiv 2026
-
[13]
Brady Steele. Why LoRA resists label noise: A theoretical framework for noise-robust parameter-efficient fine-tuning, 2026. arXiv:2602.00084
arXiv 2026
-
[14]
Sharp generalization bounds for foundation models with asymmetric randomized low-rank adapters, 2025
Anastasis Kratsios, Tin Sum Cheng, Aurelien Lucchi, and Haitz Sáez de Ocáriz Borde. Sharp generalization bounds for foundation models with asymmetric randomized low-rank adapters, 2025. arXiv:2506.14530. 12
arXiv 2025
-
[15]
Uijeong Jang, Jason D. Lee, and Ernest K. Ryu. LoRA training in the NTK regime has no spurious local minima. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 21306–21328. PMLR, 2024. arXiv:2402.11867
arXiv 2024
-
[16]
Bayes optimal learning of attention-indexed models
Fabrizio Boncoraglio, Emanuele Troiani, Vittorio Erba, and Lenka Zdeborová. Bayes optimal learning of attention-indexed models. InAdvances in Neural Information Processing Systems, volume 38, pages 105029–105074, 2025. arXiv:2506.01582
arXiv 2025
-
[17]
Fabrizio Boncoraglio, Vittorio Erba, Emanuele Troiani, Yizhou Xu, Florent Krzakala, and Lenka Zdeborová. Single-head attention in high dimensions: A theory of generalization, weights spectra, and scaling laws. InInternational Conference on Machine Learning, 2026. arXiv:2509.24914
Pith/arXiv arXiv 2026
-
[18]
Online stochastic gradient descent on non-convex losses from high-dimensional inference.Journal of Machine Learning Research, 22(106):1–51, 2021
Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. Online stochastic gradient descent on non-convex losses from high-dimensional inference.Journal of Machine Learning Research, 22(106):1–51, 2021
2021
-
[19]
Alex Damian, Eshaan Nichani, Rong Ge, and Jason D. Lee. Smoothing the landscape boosts the signal for SGD: Optimal sample complexity for learning single index models. In Advances in Neural Information Processing Systems, volume 36, pages 752–784, 2023
2023
-
[20]
From high- dimensional and mean-field dynamics to dimensionless odes: A unifying approach to SGD in two-layer networks
Luca Arnaboldi, Ludovic Stephan, Florent Krzakala, and Bruno Loureiro. From high- dimensional and mean-field dynamics to dimensionless odes: A unifying approach to SGD in two-layer networks. InThe Thirty Sixth Annual Conference on Learning Theory, pages 1199–1227. PMLR, 2023
2023
-
[21]
Learning time-scales in two-layers neural networks.Foundations of Computational Mathematics, 25(5):1627–1710, 2025
Raphaël Berthier, Andrea Montanari, and Kangjie Zhou. Learning time-scales in two-layers neural networks.Foundations of Computational Mathematics, 25(5):1627–1710, 2025
2025
-
[22]
High-dimensional learning of narrow neural networks.Journal of Statistical Mechanics: Theory and Experiment, 2025(2):023402, 2025
Hugo Cui. High-dimensional learning of narrow neural networks.Journal of Statistical Mechanics: Theory and Experiment, 2025(2):023402, 2025
2025
-
[23]
A phase transition between positional and semantic learning in a solvable model of dot-product attention
Hugo Cui, Freya Behrens, Florent Krzakala, and Lenka Zdeborová. A phase transition between positional and semantic learning in a solvable model of dot-product attention. Advances in Neural Information Processing Systems, 37:36342–36389, 2024
2024
-
[24]
Fundamental limits of learning in sequence multi-index models and deep attention networks: high-dimensional asymptotics and sharp thresholds
Emanuele Troiani, Hugo Chao Cui, Yatin Dandi, Florent Krzakala, and Lenka Zdeborová. Fundamental limits of learning in sequence multi-index models and deep attention networks: high-dimensional asymptotics and sharp thresholds. InProceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[25]
Asymptotics of sgd in sequence-single index models and single-layer attention networks
Luca Arnaboldi, Bruno Loureiro, Ludovic Stephan, Florent Krzakala, and Lenka Zdeborová. Asymptotics of sgd in sequence-single index models and single-layer attention networks. In Advances in Neural Information Processing Systems, volume 38, pages 20611–20645, 2025
2025
-
[26]
O. Duranthon, P. Marion, C. Boyer, B. Loureiro, and L. Zdeborová. Statistical advantage of softmax attention: Insights from single-location regression. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. arXiv:2509.21936
arXiv 2026
-
[27]
Andrea Montanari and Basil N. Saeed. Universality of empirical risk minimization. In Proceedings of Thirty Fifth Conference on Learning Theory, volume 178 ofProceedings of Machine Learning Research, pages 4310–4312. PMLR, 2022
2022
-
[28]
Universality laws for gaussian mixtures in generalized linear models
Yatin Dandi, Ludovic Stephan, Florent Krzakala, Bruno Loureiro, and Lenka Zdeborová. Universality laws for gaussian mixtures in generalized linear models. InAdvances in Neural Information Processing Systems, volume 36, pages 54754–54768, 2023. 13
2023
-
[29]
Lu, and Subhabrata Sen
Rishabh Dudeja, Yue M. Lu, and Subhabrata Sen. Universality of approximate message passing with semirandom matrices.The Annals of Probability, 51(5):1616–1683, 2023
2023
-
[30]
Lu and Horng-Tzer Yau
Yue M. Lu and Horng-Tzer Yau. An equivalence principle for the spectrum of random inner-product kernel matrices with polynomial scalings.The Annals of Applied Probability, 35(4):2411–2470, 2025
2025
-
[31]
Asymptotics of non-convex generalized linear models in high dimensions: A proof of the replica formula,
Matteo Vilucchio, Yatin Dandi, Cedric Gerbelot, and Florent Krzakala. Asymptotics of non-convex generalized linear models in high dimensions: A proof of the replica formula,
-
[32]
Topological trivialization in non-convex empirical risk minimization, 2026
Andrea Montanari and Basil Saeed. Topological trivialization in non-convex empirical risk minimization, 2026. arxiv:2602.14969
arXiv 2026
-
[33]
A rank stabilization scaling factor for fine-tuning with lora, 2023
Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora, 2023. arXiv:2312.03732
Pith/arXiv arXiv 2023
-
[34]
Decoupling angles and strength in low-rank adaptation
Massimo Bini, Leander Girrbach, and Zeynep Akata. Decoupling angles and strength in low-rank adaptation. InInternational Conference on Learning Representations, volume 2025, pages 20216–20233, 2025
2025
-
[35]
Vicente Conde Mendes, Lorenzo Bardone, Cédric Koller, Jorge Medina Moreira, Vittorio Erba, Emanuele Troiani, and Lenka Zdeborová. A solvable high-dimensional model where nonlinear autoencoders learn structure invisible to PCA while test loss misaligns with generalization. InInternational Conference on Machine Learning, 2026. arXiv:2602.10680
Pith/arXiv arXiv 2026
-
[36]
Biased generalization in diffusion models, 2026
Jerome Garnier-Brun, Luca Biggio, Davide Beltrame, Marc Mézard, and Luca Saglietti. Biased generalization in diffusion models, 2026. arXiv:2603.03469
arXiv 2026
-
[37]
Fundamental limits of matrix sensing: Exact asymptotics, universality, and applications
Yizhou Xu, Antoine Maillard, Lenka Zdeborová, and Florent Krzakala. Fundamental limits of matrix sensing: Exact asymptotics, universality, and applications. InConference on Learning Theory, 2025
2025
-
[38]
without active fine-tuning
Vittorio Erba, Emanuele Troiani, Lenka Zdeborová, and Florent Krzakala. The nuclear route: Sharp asymptotics of erm in overparameterized quadratic networks. InAdvances in Neural Information Processing Systems, volume 38, pages 88862–88901, 2025. 14 A Derivation of the main results In this section we provide the derivation of the results on the asymptotic ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.