Next-Token Prediction Learns Generalisable Representations of Sleep Physiology
Pith reviewed 2026-06-27 16:40 UTC · model grok-4.3
The pith
Next-token prediction on tokenized multi-modal sleep signals produces embeddings that match supervised baselines with 100 times less labeled data and generalize to daytime atrial fibrillation detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
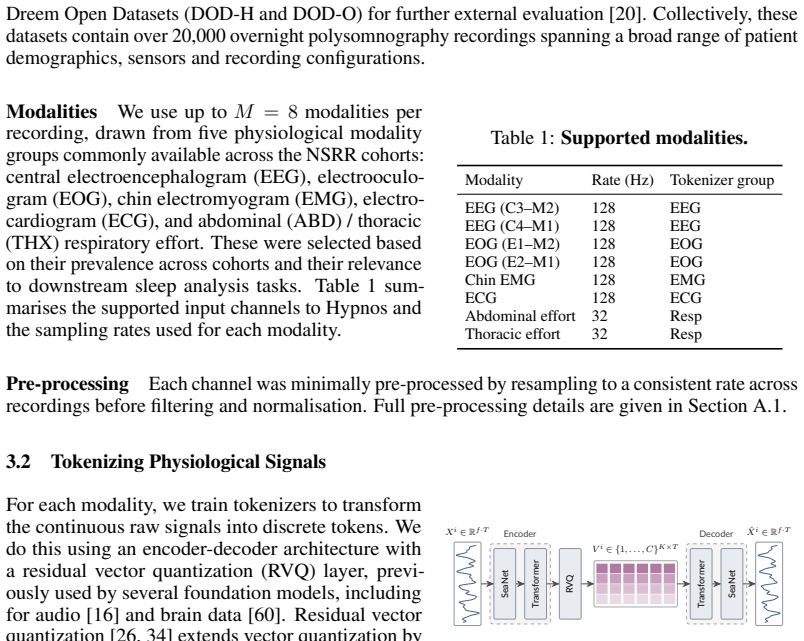
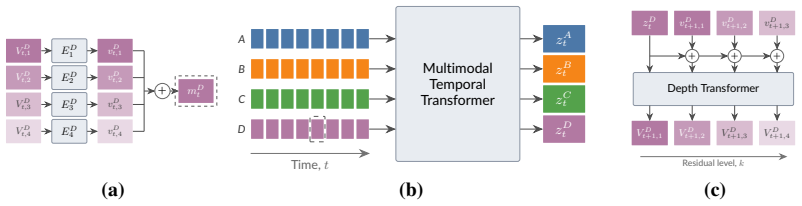
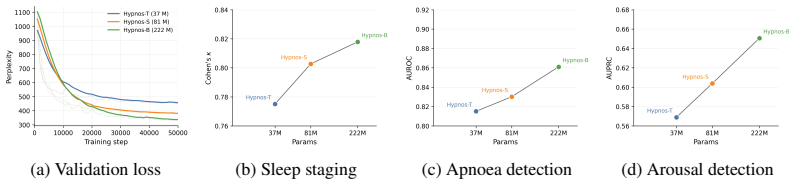
Hypnos tokenizes each of eight sensing modalities with residual vector quantization, then trains a large auto-regressive RQ-Transformer to predict the next token across all modalities in parallel. After pretraining, the model produces embeddings from any supported subset of modalities that match supervised sleep-stage baselines on held-out test sets while using 100 times less labeled data and that surpass a dedicated ECG foundation model at detecting atrial fibrillation in daytime physiology.
What carries the argument
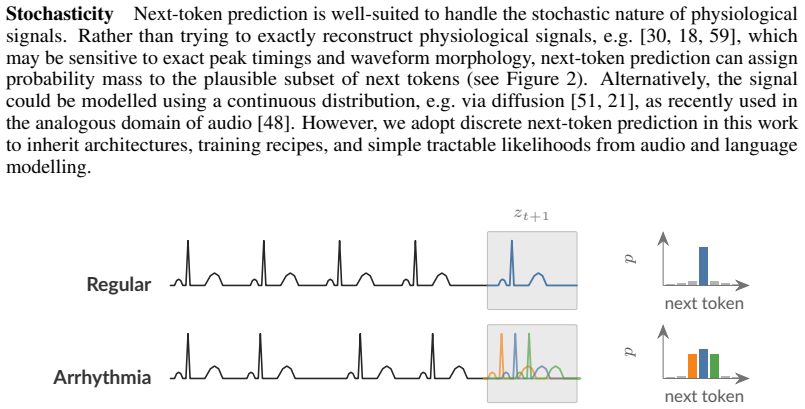
An auto-regressive RQ-Transformer trained with next-token prediction on parallel streams of residual-vector-quantized tokens drawn from multiple physiological modalities.
If this is right
- Sleep stage classification matches strong supervised baselines on held-out sets while using 100 times less labeled data.
- The same embeddings surpass a dedicated ECG foundation model at atrial fibrillation detection from daytime recordings.
- Embeddings can be generated from continuous streams of any supported subset of the eight modalities.
- Next-token prediction serves as a scalable self-supervised objective for multi-modal physiological signals where positive-pair definitions are difficult to specify.
- The approach outperforms existing foundation models across the reported benchmarks.
Where Pith is reading between the lines
- The method may transfer to other stochastic multi-modal medical signals where explicit invariance definitions are unavailable.
- Lower labeled-data requirements could accelerate model development for rare sleep or cardiac conditions.
- Joint next-token prediction across modalities may encode cross-signal relationships that single-modality pretraining misses.
- Further downstream tasks such as sleep-apnea event detection would provide additional tests of the claimed generality.
Load-bearing premise
That next-token prediction on tokenized physiological streams will automatically learn the semantic invariances required for downstream generalization without any explicit positive-pair or reconstruction targets.
What would settle it
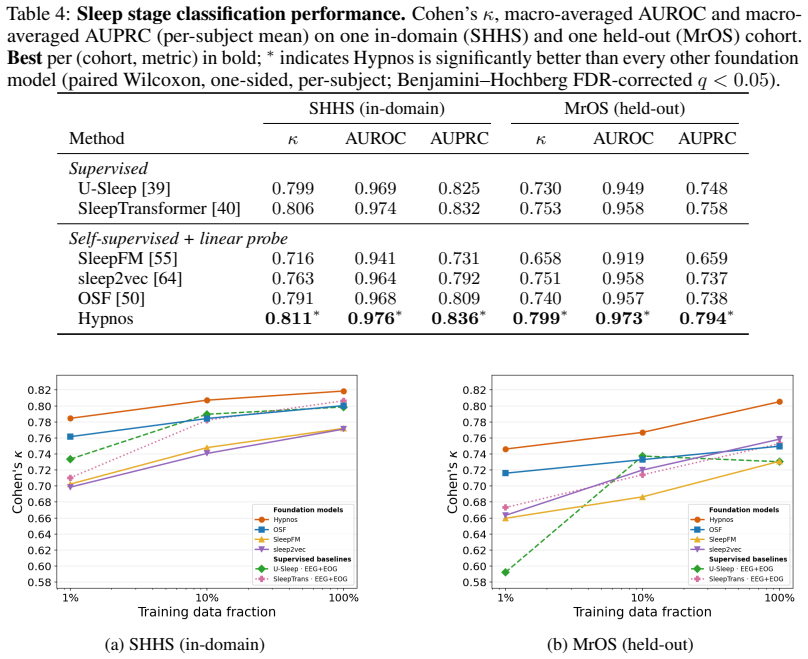
On a held-out sleep staging test set, embeddings from the next-token model fail to reach the accuracy of a supervised baseline trained on the full labeled set when only one percent of the labels are supplied, or the model underperforms the dedicated ECG foundation model on atrial fibrillation detection from daytime recordings.
Figures
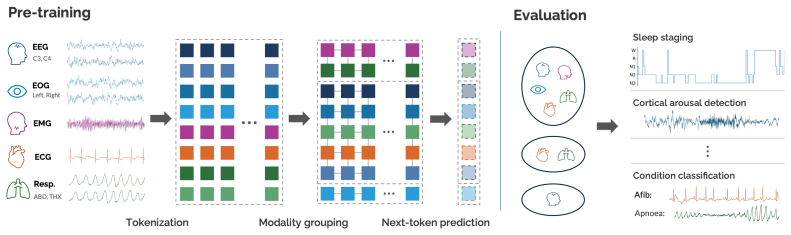


read the original abstract
Foundation models offer a promising route to compress multi-modal physiological signals into compact representations of human health, with broad applications across sleep medicine, cardiology, neurology and other healthcare domains. Existing models have typically been trained with masked-reconstruction or contrastive objectives. However, masked reconstruction may be poorly suited to the stochastic nature of these signals, while contrastive approaches rely on positive-pair definitions despite the semantic invariances of physiological signals being poorly understood. In this work, we show that next-token prediction is a simple and scalable alternative. We develop Hypnos, a multi-modal sleep foundation model trained using eight different sensing modalities (e.g. EEG, ECG, respiratory signals) drawn from over 20,000 overnight polysomnography recordings. We tokenize each modality into streams of discrete tokens using residual vector quantization, then train a large auto-regressive RQ-Transformer to jointly predict the next token across all modalities in parallel. After training, Hypnos can be applied to continuous streams of sensor data from any subset of supported modalities, generating embeddings for downstream tasks. Across a range of benchmarks, Hypnos significantly outperforms existing foundation models. In sleep stage classification, we match the performance of strong supervised baselines on held-out test sets whilst using \(100\times\) less labelled data. Hypnos even generalises to daytime physiology, surpassing a dedicated ECG foundation model at detecting atrial fibrillation. Our results demonstrate that next-token prediction is a strong self-supervised objective for representation learning from multi-modal physiological signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Hypnos, a multi-modal foundation model for sleep physiology trained via next-token prediction. It tokenizes eight sensing modalities (EEG, ECG, respiratory signals, etc.) from over 20,000 overnight PSG recordings using residual vector quantization, then trains a large auto-regressive RQ-Transformer to jointly predict the next token across modalities. The central claims are that this objective yields representations that (i) significantly outperform existing foundation models, (ii) match strong supervised baselines on held-out sleep-stage classification while using 100× less labeled data, and (iii) generalize to daytime single-channel ECG, surpassing a dedicated ECG foundation model on atrial-fibrillation detection.
Significance. If the empirical claims hold after proper controls, the result would be significant: it supplies concrete evidence that a simple autoregressive objective can induce useful invariances in stochastic physiological time series without requiring contrastive positive-pair definitions or masked reconstruction. The scale (20 k+ multi-modal recordings) and the reported data-efficiency gain in sleep staging would strengthen the case for next-token prediction as a scalable pre-training strategy in healthcare signal modeling.
major comments (1)
- [Abstract] Abstract (generalization claim): The assertion that Hypnos 'generalises to daytime physiology, surpassing a dedicated ECG foundation model at detecting atrial fibrillation' is load-bearing for the cross-domain claim. The manuscript provides no quantification of domain shift (circadian, activity, or recording-context differences), no statement on whether the daytime evaluation used zero-shot embeddings or fine-tuning, and no comparison of the dedicated ECG model's training data volume or diversity. Without these controls it is impossible to attribute outperformance to the next-token objective or multi-modal pre-training rather than architecture or data scale.
minor comments (1)
- [Abstract] Abstract: No experimental details (data splits, metrics, error bars, or whether results are from linear probing vs. fine-tuning) are supplied, making it difficult for readers to assess the strength of the reported gains at first reading.
Simulated Author's Rebuttal
We thank the referee for their careful review and for identifying areas where the generalization claim requires additional support. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (generalization claim): The assertion that Hypnos 'generalises to daytime physiology, surpassing a dedicated ECG foundation model at detecting atrial fibrillation' is load-bearing for the cross-domain claim. The manuscript provides no quantification of domain shift (circadian, activity, or recording-context differences), no statement on whether the daytime evaluation used zero-shot embeddings or fine-tuning, and no comparison of the dedicated ECG model's training data volume or diversity. Without these controls it is impossible to attribute outperformance to the next-token objective or multi-modal pre-training rather than architecture or data scale.
Authors: We agree that the abstract is too concise to convey these details and that the manuscript as submitted lacks explicit quantification of domain shift and direct comparisons of the baseline model's data. In revision we will (i) expand the abstract to state that daytime AF detection uses fine-tuned embeddings on a modest amount of labeled daytime ECG, (ii) add a dedicated paragraph or short subsection that reports basic distributional statistics (e.g., heart-rate variability, signal amplitude) between the overnight PSG and daytime recordings and discusses circadian/activity differences, and (iii) include a brief comparison of the published training scale and diversity of the dedicated ECG foundation model. These additions will make the attribution to the next-token objective clearer while remaining within the scope of the existing experiments. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper trains a multi-modal RQ-Transformer with a standard next-token prediction objective on tokenized overnight PSG recordings (eight modalities) and then extracts embeddings for separate downstream evaluations on held-out sleep staging and daytime ECG AF detection tasks. No equations or claims reduce the objective or results to the evaluation metrics by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems are invoked. The pretraining objective and downstream tasks remain independent, making the reported generalization a genuine empirical claim rather than a definitional tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Miller, Saba Emrani, Udhyakumar Nallasamy, and Ian Shapiro
Salar Abbaspourazad, Oussama Elachqar, Andrew C. Miller, Saba Emrani, Udhyakumar Nallasamy, and Ian Shapiro. Large-scale Training of Foundation Models for Wearable Biosignals. InThe Twelfth International Conference on Learning Representations, March 2024. doi: 10.48550/arXiv.2312.05409. 1
-
[2]
David J. Aldous. Exchangeability and related topics. In David J. Aldous, Illdar A. Ibragimov, Jean Jacod, and P. L. Hennequin, editors,École d’Été de Probabilités de Saint-Flour XIII — 1983, pages 1–198, Berlin, Heidelberg, 1985. Springer. ISBN 978-3-540-39316-0. doi: 10.1007/BFb0099421. 6
-
[3]
Behavioral Timescale Synaptic Plasticity: A Burst in the Field of Learning and Memory
Thomas Andrillon, Yuval Nir, Richard J. Staba, Fabio Ferrarelli, Chiara Cirelli, Giulio Tononi, and Itzhak Fried. Sleep Spindles in Humans: Insights from Intracranial EEG and Unit Recordings.The Journal of Neuroscience, 31(49):17821–17834, December 2011. ISSN 0270-6474. doi: 10.1523/JNEUROSCI. 2604-11.2011. 18
-
[4]
Self-Supervised Learning From Images With a Joint-Embedding Predictive Architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-Supervised Learning From Images With a Joint-Embedding Predictive Architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023. 17
2023
-
[5]
Uncovering the structure of clinical EEG signals with self-supervised learning.Journal of Neural Engineering, 18(4):046020, 2021
Hubert Banville, Omar Chehab, Aapo Hyvärinen, Denis-Alexander Engemann, and Alexandre Gram- fort. Uncovering the structure of clinical EEG signals with self-supervised learning.Journal of Neural Engineering, 18(4):046020, 2021. 1
2021
-
[6]
Peters, and Arman Cohan
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The Long-Document Transformer, December 2020. 5
2020
-
[7]
Audiolm: A language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31: 2523–2533, 2023
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, and Marco Tagliasacchi. Audiolm: A language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31: 2523–2533, 2023. 1, 2
2023
-
[8]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
2020
-
[9]
Emerging Properties in Self-Supervised Vision Transformers, May 2021
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformers, May 2021. 17
2021
-
[10]
Carter and Lionel Tarassenko
Jonathan F. Carter and Lionel Tarassenko. Wav2sleep: A Unified Multi-Modal Approach to Sleep Stage Classification from Physiological Signals. InProceedings of the 4th Machine Learning for Health Symposium, pages 186–202. PMLR, February 2025. 6
2025
-
[11]
Lutsey, Sogol Javaheri, Carmela Alcántara, Chandra L
Xiaoli Chen, Rui Wang, Phyllis Zee, Pamela L. Lutsey, Sogol Javaheri, Carmela Alcántara, Chandra L. Jackson, Michelle A. Williams, and Susan Redline. Racial/Ethnic Differences in Sleep Disturbances: The Multi-Ethnic Study of Atherosclerosis (MESA).Sleep, 38(6):877–888, June 2015. ISSN 1550-9109. doi: 10.5665/sleep.4732. 3
-
[12]
Xinlei Chen and Kaiming He. Exploring Simple Siamese Representation Learning. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15745–15753, Nashville, TN, USA, June 2021. IEEE. ISBN 978-1-6654-4509-2. doi: 10.1109/CVPR46437.2021.01549. 3
-
[13]
Simple and Controllable Music Generation.Advances in Neural Information Processing Systems, 36:47704–47720, December 2023
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Defossez. Simple and Controllable Music Generation.Advances in Neural Information Processing Systems, 36:47704–47720, December 2023. 2
2023
-
[14]
Imant Daunhawer, Alice Bizeul, Emanuele Palumbo, Alexander Marx, and Julia E. V ogt. Identifiability Results for Multimodal Contrastive Learning, March 2023. 3
2023
-
[15]
Shaun Davidson, Rachel Sharman, Simon D. Kyle, and Lionel Tarassenko. Is it time to revisit the scoring of slow wave (N3) sleep?Sleep, 48(10), October 2025. ISSN 0161-8105. doi: 10.1093/sleep/zsaf063. 24
-
[16]
Moshi: A speech-text foundation model for real-time dialogue, October 2024
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: A speech-text foundation model for real-time dialogue, October 2024. 1, 2, 4, 5, 15, 19 11
2024
-
[17]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations, October 2020. 5
2020
-
[18]
Benjamin Fox, Joy Jiang, Sajila Wickramaratne, Patricia Kovatch, Mayte Suarez-Farinas, Neomi A Shah, Ankit Parekh, and Girish N Nadkarni. A foundational transformer leveraging full night, multichannel sleep study data accurately classifies sleep stages.Sleep, 48(8):zsaf061, August 2025. ISSN 0161-8105. doi: 10.1093/sleep/zsaf061. 1, 3
-
[19]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. https://arxiv.org/abs/2403.05530v5, March 2024. 1
Pith/arXiv arXiv 2024
-
[20]
Antoine Guillot, Fabien Sauvet, Emmanuel H. During, and Valentin Thorey. Dreem Open Datasets: Multi-Scored Sleep Datasets to Compare Human and Automated Sleep Staging.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 28(9):1955–1965, September 2020. ISSN 1558-0210. doi: 10.1109/TNSRE.2020.3011181. 4
-
[21]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems (NeurIPS 2020). arXiv, December 2020. doi: 10.48550/arXiv. 2006.11239. 3
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2020
-
[22]
C. Iber. The AASM Manual for the Scoring of Sleep and Associated Events: Rules, Terminology, and Technical Specification. 2007. 3
2007
-
[23]
The Brain’s Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
Dulhan Jayalath, Gilad Landau, Brendan Shillingford, Mark Woolrich, and Oiwi Parker Jones. The Brain’s Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning. InProceedings of the 42nd International Conference on Machine Learning, June 2025. 3
2025
-
[24]
Jiarui Jin, Haoyu Wang, Hongyan Li, Jun Li, Jiahui Pan, and Shenda Hong
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large Brain Model for Learning Generic Representa- tions with Tremendous EEG Data in BCI. InInternational Conference on Learning Representations (ICLR 2024), May 2024. doi: 10.48550/arXiv.2405.18765. 2
-
[25]
NeuroLM: A Universal Multi-task Foun- dation Model for Bridging the Gap between Language and EEG Signals
Weibang Jiang, Yansen Wang, Bao-liang Lu, and Dongsheng Li. NeuroLM: A Universal Multi-task Foun- dation Model for Bridging the Gap between Language and EEG Signals. InThe Thirteenth International Conference on Learning Representations, October 2024. 2
2024
-
[26]
Biing-Hwang Juang and A. Gray. Multiple stage vector quantization for speech coding. InICASSP ’82. IEEE International Conference on Acoustics, Speech, and Signal Processing, volume 7, pages 597–600, May 1982. doi: 10.1109/ICASSP.1982.1171604. 4
-
[27]
Dani Kiyasseh, Tingting Zhu, and David A. Clifton. CLOCS: Contrastive Learning of Cardiac Signals Across Space, Time, and Patients, May 2021. 3
2021
-
[28]
Autoregressive Image Generation using Residual Quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive Image Generation using Residual Quantization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022). arXiv, March 2022. doi: 10.48550/arXiv.2203.01941. 2, 5
-
[29]
Splaingard, Yungui Huang, Yuejie Chi, and Simon L
Harlin Lee, Boyue Li, Shelly DeForte, Mark L. Splaingard, Yungui Huang, Yuejie Chi, and Simon L. Linwood. A large collection of real-world pediatric sleep studies.Scientific Data, 9(1):421, July 2022. ISSN 2052-4463. doi: 10.1038/s41597-022-01545-6. 3
-
[30]
Simon A. Lee, Cyrus Tanade, Hao Zhou, Juhyeon Lee, Megha Thukral, Minji Han, Rachel Choi, Md Saz- zad Hissain Khan, Baiying Lu, Migyeong Gwak, Mehrab Bin Morshed, Viswam Nathan, Md Mahbubur Rahman, Li Zhu, Subramaniam Venkatraman, and Sharanya Arcot Desai. HiMAE: Hierarchical Masked Autoencoders Discover Resolution-Specific Structure in Wearable Time Seri...
-
[31]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. In7th International Confer- ence on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019. 5
2019
-
[32]
BenchECG and xECG: A benchmark and baseline for ECG foundation models, September 2025
Riccardo Lunelli, Angus Nicolson, Samuel Martin Pröll, Sebastian Johannes Reinstadler, Axel Bauer, and Clemens Dlaska. BenchECG and xECG: A benchmark and baseline for ECG foundation models, September 2025. 8, 24 12
2025
-
[33]
Carole L. Marcus, Reneé H. Moore, Carol L. Rosen, Bruno Giordani, Susan L. Garetz, H. Gerry Taylor, Ron B. Mitchell, Raouf Amin, Eliot S. Katz, Raanan Arens, Shalini Paruthi, Hiren Muzumdar, David Gozal, Nina Hattiangadi Thomas, Janice Ware, Dean Beebe, Karen Snyder, Lisa Elden, Robert C. Sprecher, Paul Willging, Dwight Jones, John P. Bent, Timothy Hoban,...
-
[34]
Hoos, and James J
Julieta Martinez, Holger H. Hoos, and James J. Little. Stacked Quantizers for Compositional Vector Compression, November 2014. 4
2014
-
[35]
ECG-FM: An Open Electrocardiogram Foundation Model, May 2025
Kaden McKeen, Sameer Masood, Augustin Toma, Barry Rubin, and Bo Wang. ECG-FM: An Open Electrocardiogram Foundation Model, May 2025. 2
2025
-
[36]
P.E. McSharry, G.D. Clifford, L. Tarassenko, and L.A. Smith. A dynamical model for generating synthetic electrocardiogram signals.IEEE Transactions on Biomedical Engineering, 50(3):289–294, March 2003. ISSN 1558-2531. doi: 10.1109/TBME.2003.808805. 2
-
[37]
Lyle Muller, Frédéric Chavane, John Reynolds, and Terrence J. Sejnowski. Cortical travelling waves: Mechanisms and computational principles.Nature Reviews Neuroscience, 19(5):255–268, May 2018. ISSN 1471-0048. doi: 10.1038/nrn.2018.20. 10
-
[38]
Scaling Wearable Foundation Models
Girish Narayanswamy, Xin Liu, Kumar Ayush, Yuzhe Yang, Xuhai Xu, Shun Liao, Jake Garrison, Shyam Tailor, Jake Sunshine, Yun Liu, Tim Althoff, Shrikanth Narayanan, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Samy Abdel-Ghaffar, and Daniel McDuff. Scaling Wearable Foundation Models. InThe Thirteenth International Conference on Learning Repre...
2024
-
[39]
U- Sleep: Resilient high-frequency sleep staging.npj Digital Medicine, 4(1):72, April 2021
Mathias Perslev, Sune Darkner, Lykke Kempfner, Miki Nikolic, Poul Jørgen Jennum, and Christian Igel. U- Sleep: Resilient high-frequency sleep staging.npj Digital Medicine, 4(1):72, April 2021. ISSN 2398-6352. doi: 10.1038/s41746-021-00440-5. 6, 8, 22, 23
-
[40]
Chén, Philipp Koch, Alfred Mertins, and Maarten De V os
Huy Phan, Kaare Mikkelsen, Oliver Y . Chén, Philipp Koch, Alfred Mertins, and Maarten De V os. Sleep- Transformer: Automatic Sleep Staging With Interpretability and Uncertainty Quantification.IEEE Transactions on Biomedical Engineering, 69(8):2456–2467, August 2022. ISSN 1558-2531. doi: 10.1109/TBME.2022.3147187. 6, 7, 8, 22, 23
-
[41]
PaPaGei: Open Foundation Models for Optical Physiological Signals, February 2025
Arvind Pillai, Dimitris Spathis, Fahim Kawsar, and Mohammad Malekzadeh. PaPaGei: Open Foundation Models for Optical Physiological Signals, February 2025. 3
2025
-
[42]
S. F. Quan, B. V . Howard, C. Iber, J. P. Kiley, F. J. Nieto, G. T. O’Connor, D. M. Rapoport, S. Redline, J. Robbins, J. M. Samet, and P. W. Wahl. The Sleep Heart Health Study: Design, rationale, and methods. Sleep, 20(12):1077–1085, December 1997. ISSN 0161-8105. 3
1997
-
[43]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018. 1
2018
-
[44]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019. 1
2019
-
[45]
S. Redline, P. V . Tishler, T. D. Tosteson, J. Williamson, K. Kump, I. Browner, V . Ferrette, and P. Krejci. The familial aggregation of obstructive sleep apnea.American Journal of Respiratory and Critical Care Medicine, 151(3 Pt 1):682–687, March 1995. ISSN 1073-449X. doi: 10.1164/ajrccm/151.3_Pt_1.682. 3
-
[46]
Carol L. Rosen, Emma K. Larkin, H. Lester Kirchner, Judith L. Emancipator, Sarah F. Bivins, Susan A. Surovec, Richard J. Martin, and Susan Redline. Prevalence and risk factors for sleep-disordered breathing in 8- to 11-year-old children: Association with race and prematurity.The Journal of Pediatrics, 142(4): 383–389, April 2003. ISSN 0022-3476. doi: 10.1...
-
[47]
Schmidt, Claudio L
Alvise Dei Rossi, Matteo Metaldi, Michal Bechny, Irina Filchenko, Julia van der Meer, Markus H. Schmidt, Claudio L. A. Bassetti, Athina Tzovara, Francesca D. Faraci, and Luigi Fiorillo. SLEEPYLAND: Trust begins with fair evaluation of automatic sleep staging models.npj Digital Medicine, 9(1):55, December
-
[48]
doi: 10.1038/s41746-025-02237-2
ISSN 2398-6352. doi: 10.1038/s41746-025-02237-2. 6
-
[49]
Continuous Audio Language Models
Simon Rouard, Manu Orsini, Axel Roebel, Neil Zeghidour, and Alexandre Défossez. Continuous Audio Language Models. InThe Fourteenth International Conference on Learning Representations, January
-
[50]
doi: 10.48550/arXiv.2509.06926. 3
-
[51]
Improved Techniques for Training GANs, June 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved Techniques for Training GANs, June 2016. 19 13
2016
-
[52]
OSF: On pre-training and scaling of sleep foundation models.arXiv preprint arXiv:2603.00190, 2026
Zitao Shuai, Zongzhe Xu, David Yang, Wei Wang, and Yuzhe Yang. OSF: On Pre-training and Scaling of Sleep Foundation Models. InProceedings of the 43rd International Conference on Machine Learning, February 2026. doi: 10.48550/arXiv.2603.00190. 2, 3, 6, 8, 17, 22, 23
-
[53]
Weiss, Niru Maheswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep Unsupervised Learning using Nonequilibrium Thermodynamics, November 2015. 3
2015
-
[54]
Stone, and Osteoporotic Fractures in Men (MrOS) Study Group
Yeonsu Song, Terri Blackwell, Kristine Yaffe, Sonia Ancoli-Israel, Susan Redline, Katie L. Stone, and Osteoporotic Fractures in Men (MrOS) Study Group. Relationships between sleep stages and changes in cognitive function in older men: The MrOS Sleep Study.Sleep, 38(3):411–421, March 2015. ISSN 1550-9109. doi: 10.5665/sleep.4500. 3
-
[55]
RoFormer: Enhanced transformer with Rotary Position Embedding , journal =
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with Rotary Position Embedding.Neurocomputing, 568:127063, February 2024. ISSN 0925-2312. doi: 10.1016/j.neucom.2023.127063. 16
-
[56]
SEANet: A Multi-modal Speech Enhancement Network, October 2020
Marco Tagliasacchi, Yunpeng Li, Karolis Misiunas, and Dominik Roblek. SEANet: A Multi-modal Speech Enhancement Network, October 2020. 4
2020
-
[57]
Brandon Westover, Poul Jennum, Andreas Brink-Kjaer, Emmanuel Mignot, and James Zou
Rahul Thapa, Magnus Ruud Kjaer, Bryan He, Ian Covert, Hyatt Moore IV , Umaer Hanif, Gauri Ganjoo, M. Brandon Westover, Poul Jennum, Andreas Brink-Kjaer, Emmanuel Mignot, and James Zou. A multimodal sleep foundation model for disease prediction.Nature Medicine, 32(2):752–762, February
-
[58]
doi: 10.1038/s41591-025-04133-4
ISSN 1546-170X. doi: 10.1038/s41591-025-04133-4. 1, 2, 3, 6, 8, 16, 17, 22, 23, 24
-
[59]
WaveNet: A Generative Model for Raw Audio, September 2016
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio, September 2016. 4
2016
-
[60]
Neural Discrete Representation Learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural Discrete Representation Learning. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. 2
2017
-
[61]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need.arXiv:1706.03762 [cs], December 2017. 4, 5
Pith/arXiv arXiv 2017
-
[62]
Eegpt: Pretrained transformer for universal and reliable representation of eeg signals.Advances in Neural Information Processing Systems, 37:39249–39280, 2024
Guangyu Wang, Wenchao Liu, Yuhong He, Cong Xu, Lin Ma, and Haifeng Li. Eegpt: Pretrained transformer for universal and reliable representation of eeg signals.Advances in Neural Information Processing Systems, 37:39249–39280, 2024. 3
2024
-
[63]
BrainOmni: A Brain Foundation Model for Unified EEG and MEG Signals
Qinfan Xiao, Ziyun Cui, Chi Zhang, Siqi Chen, Wen Wu, Andrew Thwaites, Alexandra Woolgar, Bowen Zhou, and Chao Zhang. BrainOmni: A Brain Foundation Model for Unified EEG and MEG Signals. In Advances in Neural Information Processing Systems, volume 38, October 2025. doi: 10.48550/arXiv.2505. 18185. 2, 4, 10, 15, 16, 18
-
[64]
Xu, Girish Narayanswamy, Kumar Ayush, Dimitris Spathis, Shun Liao, Shyam A
Maxwell A. Xu, Girish Narayanswamy, Kumar Ayush, Dimitris Spathis, Shun Liao, Shyam A. Tailor, Ahmed Metwally, A. Ali Heydari, Yuwei Zhang, Jake Garrison, Samy Abdel-Ghaffar, Xuhai Xu, Ken Gu, Jacob Sunshine, Ming-Zher Poh, Yun Liu, Tim Althoff, Shrikanth Narayanan, Pushmeet Kohli, Mark Malhotra, Shwetak Patel, Yuzhe Yang, James M. Rehg, Xin Liu, and Dani...
2025
-
[65]
Peppard, F
Terry Young, Mari Palta, Jerome Dempsey, Paul E. Peppard, F. Javier Nieto, and K. Mae Hla. Burden of sleep apnea: Rationale, design, and major findings of the Wisconsin Sleep Cohort study.WMJ: official publication of the State Medical Society of Wisconsin, 108(5):246–249, August 2009. ISSN 1098-1861. 3
2009
-
[66]
Creagh, Catherine Tong, Aidan Acquah, David A
Hang Yuan, Shing Chan, Andrew P. Creagh, Catherine Tong, Aidan Acquah, David A. Clifton, and Aiden Doherty. Self-supervised learning for human activity recognition using 700,000 person-days of wearable data.npj Digital Medicine, 7(1):1–10, April 2024. ISSN 2398-6352. doi: 10.1038/s41746-024-01062-3. 1, 3
-
[67]
Sleep2vec: Unified Cross-Modal Alignment for Heterogeneous Nocturnal Biosignals
Weixuan Yuan, Zengrui Jin, Yichen Wang, Donglin Xie, Ziyi Ye, Chao Zhang, and Xuesong Chen. Sleep2vec: Unified Cross-Modal Alignment for Heterogeneous Nocturnal Biosignals. https://arxiv.org/abs/2602.13857v1, February 2026. 6, 8, 16, 17, 22, 23
arXiv 2026
-
[68]
Brant-X: A Unified Physiological Signal Alignment Framework
Daoze Zhang, Zhizhang Yuan, Junru Chen, Kerui Chen, and Yang Yang. Brant-X: A Unified Physiological Signal Alignment Framework. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4155–4166, Barcelona Spain, August 2024. ACM. ISBN 979-8-4007- 0490-1. doi: 10.1145/3637528.3671953. 3
-
[69]
The National Sleep Research Resource: Towards a sleep data commons.Journal of the American Medical Informatics Association: JAMIA, 25(10):1351–1358, October
Guo-Qiang Zhang, Licong Cui, Remo Mueller, Shiqiang Tao, Matthew Kim, Michael Rueschman, Sara Mariani, Daniel Mobley, and Susan Redline. The National Sleep Research Resource: Towards a sleep data commons.Journal of the American Medical Informatics Association: JAMIA, 25(10):1351–1358, October
-
[70]
Outcomes of Sleep Disorders in Older Men,
ISSN 1527-974X. doi: 10.1093/jamia/ocy064. 3 14 A Additional Implementation Details A.1 Preprocessing Referencing and filteringEEG and EOG channels were re-referenced against the contralateral mastoid (C3–M2, C4–M1 for EEG; E1–M2, E2–M1 for EOG). Chin EMG was derived bipolarly from the chin electrode pair. ECG and respiratory effort (ABD, THX) were used d...
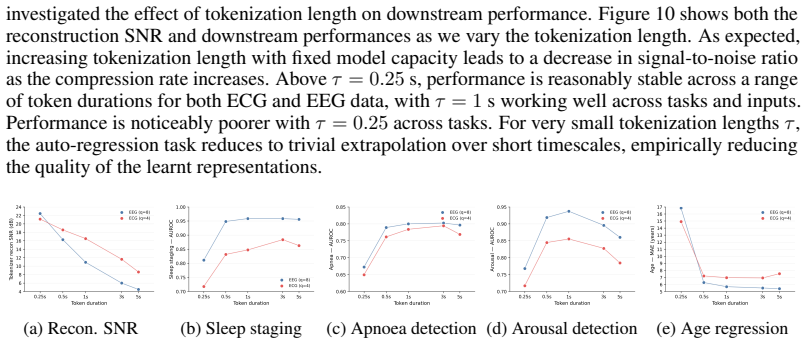
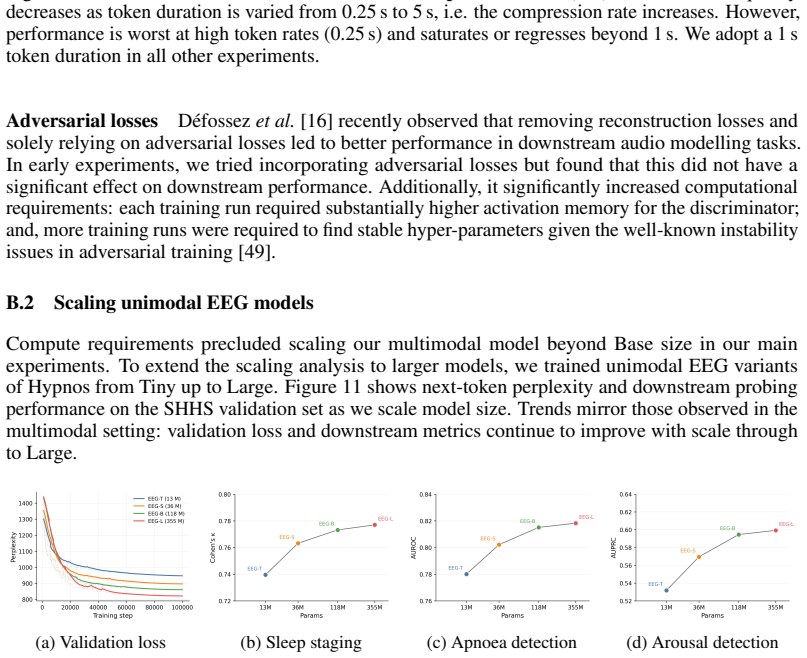
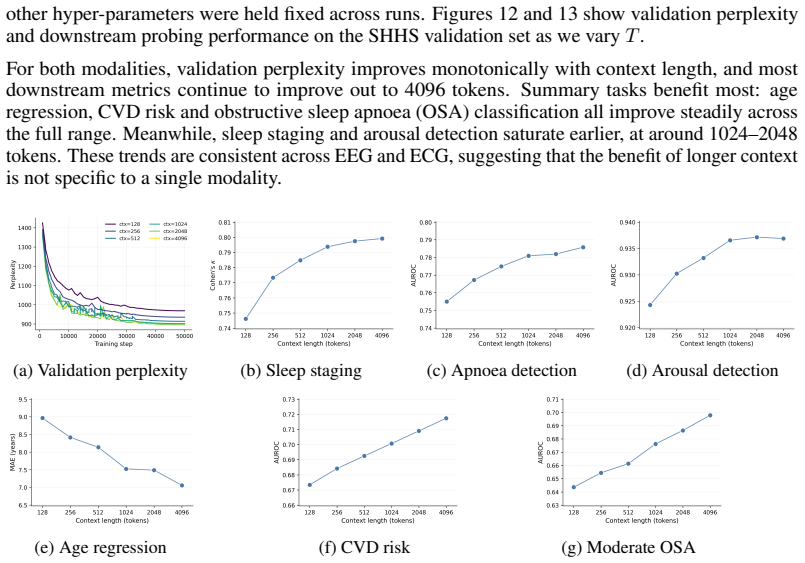
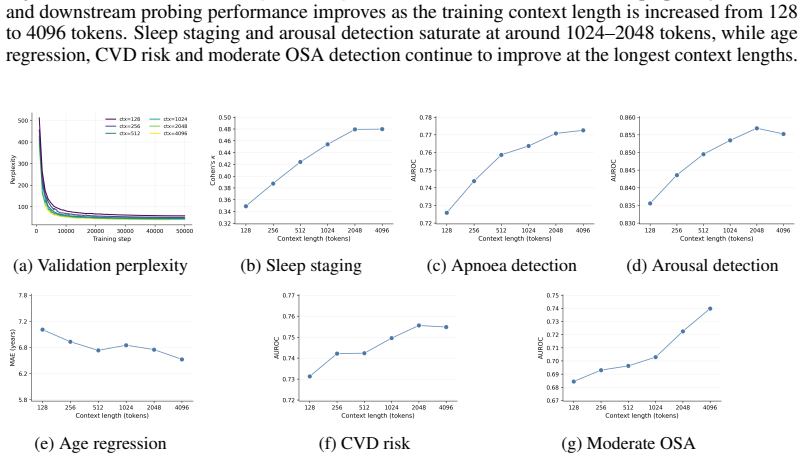
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.