Multilingual Reasoning Cascades Need More Context
Pith reviewed 2026-06-26 04:03 UTC · model grok-4.3
The pith
Adding the original question to the final translation step improves multilingual reasoning cascades.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
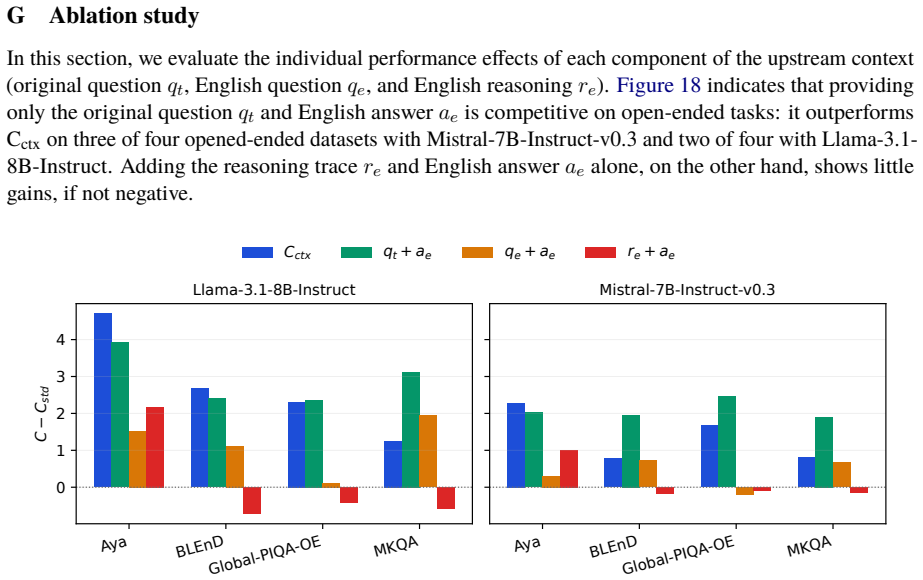
A context-aware translation cascade that supplies the original question, its English translation, and the reasoning trace to the final translation module produces strong performance gains on open-ended generation tasks across models and language resource levels, with the original question supplying the majority of the useful context.
What carries the argument
The context-aware translation cascade, which augments the input to the final translation module with the original question and prior reasoning trace to reduce information loss.
If this is right
- Gains appear consistently for open-ended generation across the tested models and resource regimes.
- The original-language question accounts for most of the observed benefit.
- Preserving the source question through the full pipeline offers a simple default strategy for reducing error propagation in cascades.
Where Pith is reading between the lines
- The same preservation tactic could be tested in other multi-stage translation or reasoning pipelines outside the nine benchmarks.
- If the original question is the dominant signal, future cascade designs might prioritize early-stage retention over later-stage additions.
- The approach might lower the need for model-specific fine-tuning when moving across languages.
Load-bearing premise
That the measured gains come from the added context itself rather than from longer prompts or other uncontrolled variables, and that results on the nine benchmarks will hold for broader real-world multilingual reasoning.
What would settle it
A controlled experiment that matches prompt length exactly while adding the original question and finds no remaining performance difference on the same benchmarks.
Figures
















read the original abstract
Translation cascades for reasoning translate the query from another language to English, reason in English, and translate the answer back to the original language. This is a competitive approach to multilingual reasoning, but structurally lossy, since each stage discards information later stages may need, including cues for cultural grounding, register, and disambiguation. We examine the benefits of a simple and training-free intervention: a context-aware translation cascade, which additionally provides the original question, the English translated question, and the reasoning trace to the context of the final translation module. We evaluate gains across nine multilingual benchmarks including various task types, three backbone models, and 285 high-, mid-, and low-resource languages, and demonstrate strong gains for open-ended generation across models and resource regimes. We show that the original language question carries most of the beneficial context. Our study emphasizes the need to better design information flow in machine translation cascades for mitigating error propagation, and provides a simple and actionable default strategy: preserve the original user question until the end of the pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard translation cascades for multilingual reasoning are structurally lossy because each stage discards information (e.g., cultural cues, register, disambiguation) needed later. It proposes a simple, training-free context-aware cascade that appends the original-language question, the English translated question, and the reasoning trace to the final translation module. Evaluation across nine multilingual benchmarks, three backbone models, and 285 high/mid/low-resource languages shows strong gains for open-ended generation tasks, with the original-language question supplying most of the benefit; the work recommends preserving the original question through the pipeline.
Significance. If the gains are robustly due to semantic context rather than prompt length or other factors, the work supplies a practical default strategy for reducing error propagation in multilingual MT cascades. The scale of the evaluation (285 languages, multiple models and task types) is a clear strength that would make the result broadly relevant if the attribution holds.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): the context-aware cascade necessarily lengthens the prompt to the final translation module, yet no length-matched control (padding with neutral tokens, repeated text, or random strings of equal token count) is described. This directly undermines the claim that 'the original language question carries most of the beneficial context,' because observed gains on open-ended generation could arise from changes in input length or attention distribution rather than informational content.
- [§5 (Results)] §5 (Results): the paper reports 'strong gains' across models and resource regimes but supplies limited statistical detail (variance, significance tests, or exact effect sizes) and no explicit controls for prompt-length confounds. This weakens support for the generalization claim over 285 languages and makes the attribution to context load-bearing for the central recommendation.
minor comments (1)
- [Abstract] The abstract lists 'nine multilingual benchmarks' without naming them or the task types; adding this would improve immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on potential confounds and statistical reporting. We address the two major comments point by point below, acknowledging where controls were missing and outlining revisions.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): the context-aware cascade necessarily lengthens the prompt to the final translation module, yet no length-matched control (padding with neutral tokens, repeated text, or random strings of equal token count) is described. This directly undermines the claim that 'the original language question carries most of the beneficial context,' because observed gains on open-ended generation could arise from changes in input length or attention distribution rather than informational content.
Authors: We agree this is a valid concern and a limitation of the current experiments: no length-matched controls were performed, so length or attention effects cannot be fully ruled out as alternative explanations for gains on open-ended tasks. Our existing ablations (comparing original-question context against English-question or reasoning-trace context) provide some evidence that content matters, as the original-question variant outperformed the others despite comparable or shorter added length in many languages. To strengthen attribution, we will add length-matched controls (padding with repeated neutral text of equal token count) in the revised manuscript and report the results. revision: yes
-
Referee: [§5 (Results)] §5 (Results): the paper reports 'strong gains' across models and resource regimes but supplies limited statistical detail (variance, significance tests, or exact effect sizes) and no explicit controls for prompt-length confounds. This weakens support for the generalization claim over 285 languages and makes the attribution to context load-bearing for the central recommendation.
Authors: We acknowledge the limited statistical detail in the current version. In revision we will add per-model variance, statistical significance tests (where sample sizes permit), and effect sizes, along with the length-matched controls described in response to the first comment. These changes will better support the generalization across 285 languages and the recommendation to preserve the original question. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations
full rationale
The paper describes an empirical intervention (context-aware translation cascade) and reports benchmark results across models, languages, and tasks. No equations, fitted parameters, predictions, or uniqueness theorems are present that could reduce to inputs by construction. Claims rest on direct comparisons to baselines, with no self-citation load-bearing steps or ansatzes smuggled in. This is the standard case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In2019 4th International Conference on Me- chanical, Control and Computer Engineering (ICM- CCE), pages 39–393
A survey of low resource neural machine trans- lation. In2019 4th International Conference on Me- chanical, Control and Computer Engineering (ICM- CCE), pages 39–393. IEEE. Shayne Longpre, Yi Lu, and Joachim Daiber. 2021. MKQA: A linguistically diverse benchmark for mul- tilingual open domain question answering. Transac- tions of the Association for Compu...
2021
-
[2]
mCSQA: Multilingual commonsense reason- ing dataset with unified creation strategy by language models and humans. In Findings of the Associa- tion for Computational Linguistics: ACL 2024 , pages 14182–14214, Bangkok, Thailand. Association for Computational Linguistics. Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, ...
arXiv 2024
-
[3]
In Proceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing , pages 13340–13358
How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark. In Proceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing , pages 13340–13358. Junnan Zhu, Qian Wang, Yining Wang, Yu Zhou, Jiajun Zhang, Shaonan Wang, and Chengqing Zong. 2019. NCLS: Neural cross-lingual summarization. In Pro...
2025
-
[5]
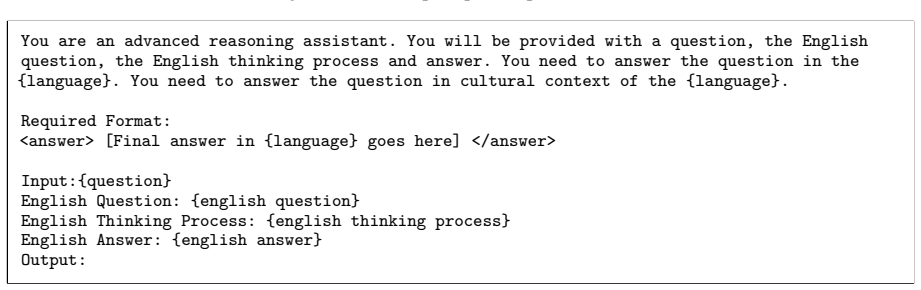
Final Output: Provide only the final, concise result in {language} within <answer> tags. Required Format: <think> [Detailed step-by-step logic and analysis in {language} goes here] </think> <answer> [Final answer in {language} goes here] </answer> Input: {question} Output: Figure 3: E2E prompt for Open-ended QA. Translate the following question to English...
-
[6]
Analyze the constraints, perform necessary calculations, or outline your arguments
Reasoning Process: Before answering, break down the problem logically. Analyze the constraints, perform necessary calculations, or outline your arguments. Enclose this entire thought process within <think> tags
-
[7]
Final Output: Provide only the final, concise result in English within <answer> tags. Required Format: <think> [Detailed step-by-step logic and analysis in English goes here] </think> <answer> [Final answer in English goes here] </answer> Input: {question} Output: Figure 5: LLM prompt for Open-ended QA. You are an advanced translation assistant. You will ...
-
[9]
Final Output: Provide only the letter of the correct option ({possible answer choice letters}) within <answer> tags. Required Format: <think> [Detailed step-by-step logic and analysis of each option in {language} goes here] </think> <answer> [{possible answer choice letters}] </answer> Input: {question} {options text} Output: Figure 8: E2E prompt for Mult...
-
[10]
Evaluate each option and explain why it is correct or incorrect
Reasoning Process: Before answering, break down the problem logically. Evaluate each option and explain why it is correct or incorrect. Enclose this entire thought process within <think> tags
-
[11]
Final Output: Provide only the letter of the correct option ({possible answer choice letters}) within <answer> tags. Required Format: <think> [Detailed step-by-step logic and analysis of each option in English goes here] </think> <answer> [{possible answer choice letters}] </answer> Input: {question} {options text} Output: Figure 10: LLM prompt for Multip...
-
[12]
Enclose this entire process within <think> tags
Reasoning Process: Solve the problem step-by-step in {language}, showing all calculations and logical deductions. Enclose this entire process within <think> tags
-
[13]
Required Format: <think> [Detailed step-by-step solution in {language} goes here] </think> \\boxed{{[Final answer]}} Input: {question} Output: Figure 12: E2E prompt for Math
Final Answer: Place only the final answer inside \\boxed{{}} immediately after the closing </think> tag. Required Format: <think> [Detailed step-by-step solution in {language} goes here] </think> \\boxed{{[Final answer]}} Input: {question} Output: Figure 12: E2E prompt for Math. Translate the following question to English: {question} Required Format: <tra...
-
[14]
Enclose this entire process within <think> tags
Reasoning Process: Solve the problem step-by-step in English, showing all calculations and logical deductions. Enclose this entire process within <think> tags
-
[15]
Required Format: <think> [Detailed step-by-step solution in English goes here] </think> \\boxed{{[Final answer]}} Input: {question} Output: Figure 14: LLM prompts for Math
Final Answer: Place only the final answer inside \\boxed{{}} immediately after the closing </think> tag. Required Format: <think> [Detailed step-by-step solution in English goes here] </think> \\boxed{{[Final answer]}} Input: {question} Output: Figure 14: LLM prompts for Math. You are an advanced mathematics reasoning assistant. You will be provided with ...
-
[16]
Source = `` 正确翻译 ( Cho tam giác ABCABC ABC nội tiếp trên đường tròn ωω ω
Structural / formatting error The output is not a clean translation --- it leaks annotation templates, repeats identical translations for distinct options, drops the question body, uses placeholders, outputs meta text, or leaves untranslated source-script text inside the English output. Source = `` 正确翻译 ( Cho tam giác ABCABC ABC nội tiếp trên đường tròn ω...
-
[17]
This includes person, team, place, organization, object, instrument, food item, artifact, or other central noun phrase
Referent / entity substitution The overall topic changes because a key referent is swapped for a different one. This includes person, team, place, organization, object, instrument, food item, artifact, or other central noun phrase. Source = `` ラムズはいつスーパーボウルでプレーしましたか'' Correct: ``When did the Rams play in the Super Bowl?'' Error: ``When was the Super Bowl ...
-
[18]
Event / constraint distortion The same core referents remain, but who-did-what, the key action/relation, negation, condition, comparison, or quantity is changed or dropped. Source = ``Akeredolu fofin de awọn ọlọkada l'Ondo.'' Correct: ``Akeredolu has given new motorcycles to the riders in Ondo.'' Error: ``Akeredolu appoints new Ondo commissioners'' --- th...
-
[19]
Cultural / local-term mistranslation A culture-specific food, idiom, institution, festival, clothing item, household item, or local artifact is translated literally or mapped to the wrong referent. Source = ``Um misto quente é um sanduíche feito com pão.'' Correct: `A ``misto quente'' is a sandwich made with bread.' Error: ``A hot mix is a sandwich made w...
-
[20]
Source (a math problem) = ``A group of 7 friends split a bill of $84 equally
Hallucination / over-answering The model invents content not in the source, replaces the source with an unrelated question or statement, or solves/explains the task instead of translating it. Source (a math problem) = ``A group of 7 friends split a bill of $84 equally. How much does each pay?'' Correct: preserves the question. Error: ``Each person pays $1...
-
[21]
question: the source-language text, copied verbatim. 2. translation: the candidate English translation, copied verbatim. 3. error type: one of 1, 2, 3, 4, 5, or OK if the translation is faithful. 4. For items with bundled options, a single dropped or merged option still counts as category 1. 5. A correct answer value does not make the translation correct;...
1945
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.