The Trustworthy Pal: Controlling the False Discovery Rate in Boolean Matrix Factorization
Pith reviewed 2026-05-25 12:20 UTC · model grok-4.3
The pith
Boolean matrix factorization can bound the probability that its patterns arise from random noise by using properties of the error-minimizing factorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes two probabilistic bounds on the chance that a pattern found by Boolean matrix factorization is generated by pure random Bernoulli noise. Each bound exploits a different property that is true precisely when the factorization is an exact minimizer of the Boolean approximation error, thereby giving new insight into the structure of such minimizers and enabling FDR control without labeled data.
What carries the argument
Two bounds on the probability that a pattern is pure noise, each derived from a distinct optimality property of the Boolean approximation error minimizer.
If this is right
- Rank selection in BMF can be performed by retaining only patterns whose noise probability falls below a chosen FDR threshold.
- Different candidate factorizations can be compared by the tightness of the noise bounds they achieve.
- BMF algorithms can be redesigned to search directly for factorizations whose patterns satisfy the derived probability bounds.
- The same optimality properties used for the bounds may yield further analytic results on the geometry of Boolean matrix factorizations.
Where Pith is reading between the lines
- The bounds could be adapted to other discrete matrix factorization problems that minimize an approximation error.
- In streaming or online settings the bounds might serve as a stopping criterion once additional patterns no longer improve the FDR-controlled quality.
- Empirical checks on synthetic noise data would directly test whether the minimizer property holds tightly enough for the bounds to be useful in practice.
Load-bearing premise
Observed data entries are independent Bernoulli random variables under the null model of pure noise, and the returned factorization is an exact minimizer of the Boolean approximation error.
What would settle it
Generate purely random Bernoulli data, run the BMF algorithm to its claimed minimum error, and check whether the fraction of patterns declared significant exceeds the bound-predicted rate.
Figures


read the original abstract
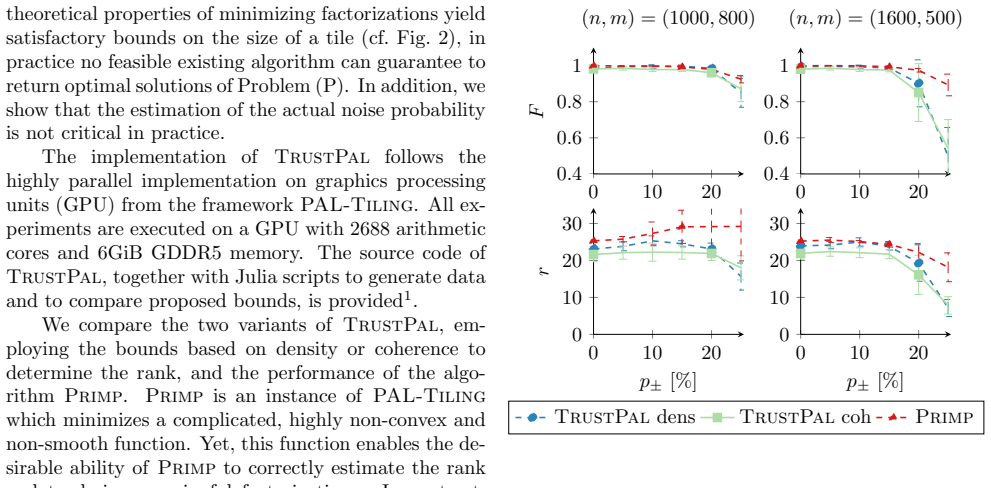
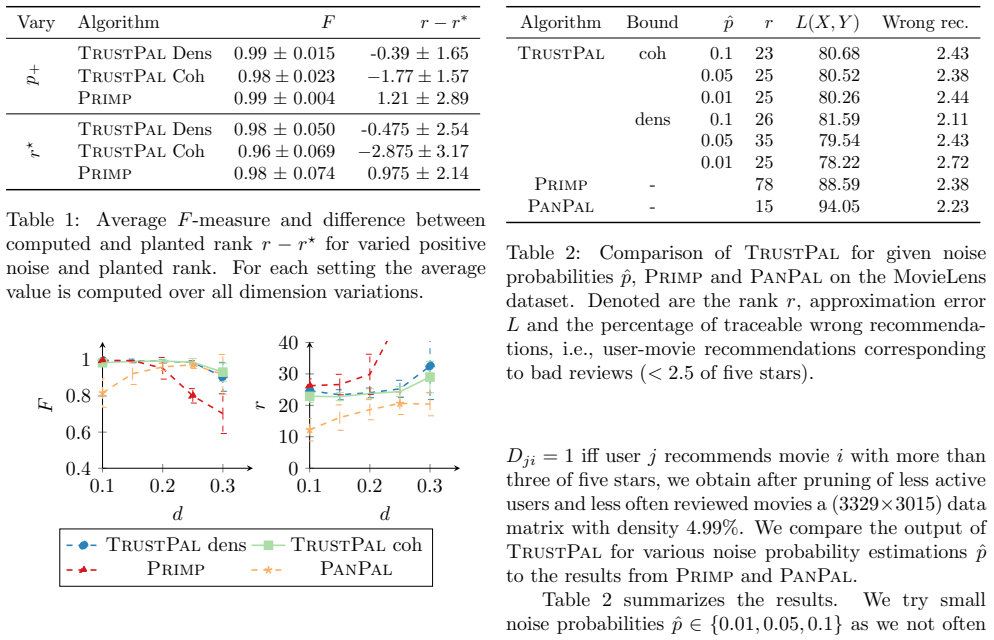
Boolean matrix factorization (BMF) is a popular and powerful technique for inferring knowledge from data. The mining result is the Boolean product of two matrices, approximating the input dataset. The Boolean product is a disjunction of rank-1 binary matrices, each describing a feature-relation, called pattern, for a group of samples. Yet, there are no guarantees that any of the returned patterns do not actually arise from noise, i.e., are false discoveries. In this paper, we propose and discuss the usage of the false discovery rate in the unsupervised BMF setting. We prove two bounds on the probability that a found pattern is constituted of random Bernoulli-distributed noise. Each bound exploits a specific property of the factorization which minimizes the approximation error---yielding new insights on the minimizers of Boolean matrix factorization. This leads to improved BMF algorithms by replacing heuristic rank selection techniques with a theoretically well-based approach. Our empirical demonstration shows that both bounds deliver excellent results in various practical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to prove two bounds on the probability that a pattern discovered by Boolean matrix factorization (BMF) arises purely from independent Bernoulli noise. Each bound exploits a property of the factorization that exactly minimizes the Boolean approximation error. These bounds are proposed as a theoretically grounded replacement for heuristic rank selection in BMF, enabling control of the false discovery rate, and are supported by empirical demonstrations across practical settings.
Significance. If the bounds apply to the factorizations actually returned by algorithms, the work supplies a principled, non-heuristic method for assessing pattern reliability in unsupervised BMF and yields new characterizations of error-minimizing factorizations. This would strengthen trustworthiness of BMF results in data-mining applications.
major comments (1)
- [Abstract and proof sections] The two probability bounds are derived by exploiting properties that hold specifically for a factorization that exactly minimizes the Boolean approximation error under the independent Bernoulli null model (see abstract and the sections presenting the proofs). Exact BMF is NP-hard, yet the paper does not supply a guarantee that any practical algorithm returns a globally optimal factorization, nor does it demonstrate that the bounds continue to hold (even approximately) for the heuristic outputs used in the empirical section. This directly affects the central claim that the bounds enable improved, theoretically well-based BMF algorithms.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the important distinction between exact and heuristic factorizations. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and proof sections] The two probability bounds are derived by exploiting properties that hold specifically for a factorization that exactly minimizes the Boolean approximation error under the independent Bernoulli null model (see abstract and the sections presenting the proofs). Exact BMF is NP-hard, yet the paper does not supply a guarantee that any practical algorithm returns a globally optimal factorization, nor does it demonstrate that the bounds continue to hold (even approximately) for the heuristic outputs used in the empirical section. This directly affects the central claim that the bounds enable improved, theoretically well-based BMF algorithms.
Authors: We agree that the two bounds are derived under the assumption of an exact minimizer of the Boolean approximation error, as stated in the abstract and proof sections. The manuscript does not provide any guarantee that practical (heuristic) algorithms return globally optimal factorizations, nor does it include a formal or empirical demonstration that the bounds hold approximately for heuristic outputs. This is a substantive limitation for the claim that the bounds directly enable improved, theoretically grounded BMF algorithms in practice. In the revision we will add an explicit discussion of this scope limitation in the introduction and conclusions, clarifying that the bounds apply to exact minimizers and may be used conservatively with near-optimal heuristics; we will also report any relevant observations from the existing experiments on how close the employed heuristics came to optimality. revision: partial
Circularity Check
No circularity; bounds derived from external Bernoulli model and minimizer properties
full rationale
The paper states it proves two bounds on false-discovery probability by exploiting properties of an exact error-minimizing factorization under an independent Bernoulli noise model. No equations reduce a claimed prediction to a fitted input by construction, no self-citations are load-bearing for the central claim, and no ansatz or uniqueness result is smuggled in via prior work. The derivation is therefore self-contained against the stated external statistical assumptions and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data matrix entries are independent Bernoulli random variables under the null hypothesis of pure noise.
- domain assumption The returned factorization is an exact minimizer of the Boolean approximation error.
Reference graph
Works this paper leans on
-
[1]
Y. Benjamini and Y. Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the royal statistical society. Series B (Methodological) , pages 289–300, 1995
work page 1995
- [2]
-
[3]
W. Duivesteijn and A. Knobbe. Exploiting false discoveries — statistical validation of patterns and quality measures in subgroup discovery. In Proc. ICDM, pages 151–160, 2011
work page 2011
-
[4]
S. Foucart and H. Rauhut. A mathematical intro- duction to compressive sensing , volume 1. Birkh¨ auser Basel, 2013
work page 2013
-
[5]
S. Hess, K. Morik, and N. Piatkowski. The PRIMPING routine - tiling through proximal alternating linearized minimization. Data Min. Knowl. Discov. , 31(4):1090– 1131, 2017
work page 2017
-
[6]
J. Komiyama, M. Ishihata, H. Arimura, T. Nishibayashi, and S. Minato. Statistical emerging pattern mining with multiple testing correction. In Proc. KDD, pages 897–906, 2017
work page 2017
-
[7]
F. Llinares-L´ opez, M. Sugiyama, L. Papaxanthos, and K. M. Borgwardt. Fast and memory-efficient signifi- cant pattern mining via permutation testing. In Proc. KDD, pages 725–734, 2015
work page 2015
-
[8]
P. Miettinen, T. Mielikainen, A. Gionis, G. Das, and H. Mannila. The discrete basis problem. TKDE, 20(10):1348–1362, 2008
work page 2008
-
[9]
P. Miettinen and J. Vreeken. Model order selection for boolean matrix factorization. In Proc. KDD, pages 51–59. ACM, 2011
work page 2011
-
[10]
M. P. Pacifico, C. Genovese, I. Verdinelli, and L. Wasserman. Scan clustering: A false discovery ap- proach. Journal of Multivariate Analysis , 98(7):1441 – 1469, 2007
work page 2007
-
[11]
Y.-X. Wang and Y.-J. Zhang. Nonnegative ma- trix factorization: A comprehensive review. TKDE, 25(6):1336–1353, 2013
work page 2013
-
[12]
G. I. Webb. Discovering significant patterns. Mach. Learn., 68(1):1–33, 2007
work page 2007
- [13]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.