Towards Verifiable Transformers: Solver-Checkable Circuit Explanations
Pith reviewed 2026-06-30 17:44 UTC · model grok-4.3
The pith
A framework converts Transformer circuit explanations into solver-checkable formal claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
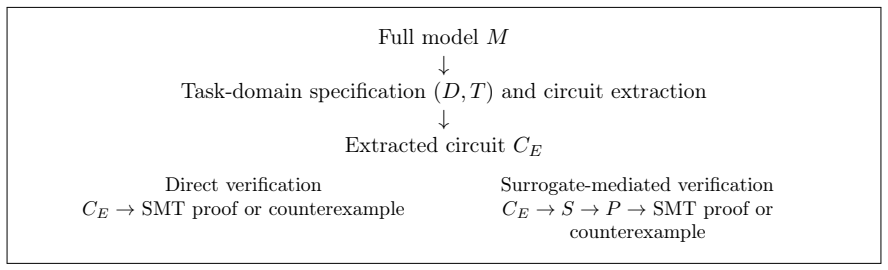
Given a behavior, a finite task domain, and a candidate-token projection, the authors extract a task circuit from a Transformer and verify properties such as projected functional equivalence, edge necessity, task-relevant invariance, and final-residual robustness using an SMT solver, either by direct encoding or via an SMT-encodable surrogate.
What carries the argument
The Verifiable Transformers framework, which extracts task circuits and encodes them for SMT verification of symbolic properties over a bounded domain.
If this is right
- On small symbolic sequence tasks, sparse circuits for quote closing and bracket type tracking can be exhaustively verified for projected functional equivalence, content invariance, edge necessity, and final-residual robustness.
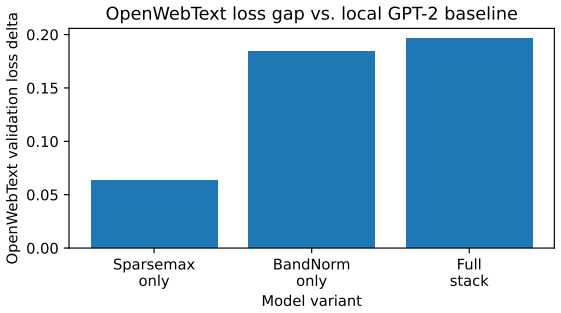
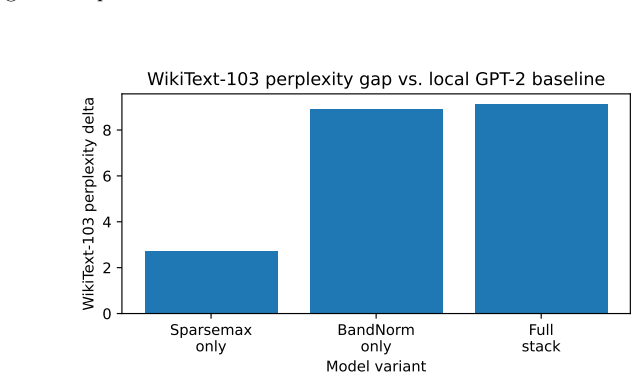
- The architecture with Signed L1 BandNorm, sparsemax attention, and LeakyReLU trains stably at GPT-2 scale on OpenWebText.
- Surrogate-mediated verification allows both verified symbolic explanations and solver-generated counterexamples for circuits containing hard-to-encode operators like attention.
- Direct SMT verification remains intractable for naive application at GPT-2 scale.
Where Pith is reading between the lines
- This method could be applied to verify safety-relevant behaviors in larger language models if suitable bounded task domains can be defined.
- Connections to formal methods in software verification might allow hybrid human-AI circuit analysis workflows.
- Future work could test whether verified circuits generalize beyond the specific task domain used for verification.
- It opens the possibility of automated refutation of incorrect circuit hypotheses via solver counterexamples.
Load-bearing premise
The bounded task domain and candidate-token projection are assumed to be sufficient to capture the relevant behavior of the circuit for exhaustive verification.
What would settle it
A case where the original model produces outputs on the task domain that differ from the extracted circuit in a manner violating one of the verified properties such as functional equivalence.
Figures
read the original abstract
Mechanistic interpretability often identifies circuits inside Transformer models, but explanations of those circuits are usually validated through examples, ablations, and manual reasoning. This leaves a gap between finding a plausible circuit and proving what the circuit does. We introduce Verifiable Transformers, a framework for converting task-localized Transformer circuits into bounded, solver-checkable claims. Given a behavior, a finite task domain, and a candidate-token projection, we extract a task circuit and verify properties such as projected functional equivalence, edge necessity, task-relevant invariance, and final-residual robustness. Direct verification encodes the extracted circuit itself into an SMT solver. When a circuit contains operators that are not exactly or tractably encodable, surrogate-mediated verification fits an SMT-encodable surrogate, validates it against the extracted circuit over the bounded domain, and verifies symbolic explanations against the surrogate. We instantiate direct verification with a GPT-style architecture using Signed L1 BandNorm, sparsemax attention, and LeakyReLU. On small symbolic sequence tasks, we train an SMT-representable Transformer, extract sparse circuits for quote closing and bracket type tracking, and exhaustively verify projected functional equivalence, content invariance, edge necessity, and final-residual robustness. At GPT-2 scale, the same operator stack trains stably on OpenWebText, although naive direct SMT verification remains intractable. We also demonstrate surrogate-mediated verification on task-localized circuits with hard-to-encode attention, showing both verified symbolic explanations and solver-generated counterexamples. The goal is not full-model verification, but a concrete path for turning mechanistic circuit explanations into formal propositions that can be proven or refuted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Verifiable Transformers framework for converting task-localized Transformer circuits into bounded, SMT-solver-checkable claims. Given a behavior, finite task domain, and candidate-token projection, it extracts a circuit and verifies properties including projected functional equivalence, edge necessity, task-relevant invariance, and final-residual robustness. Direct verification encodes the circuit into SMT when operators are tractable; otherwise, surrogate-mediated verification fits an SMT-encodable surrogate, validates it on the domain, and checks explanations against the surrogate. Demonstrations use a custom GPT-style model (Signed L1 BandNorm, sparsemax attention, LeakyReLU) on small symbolic tasks for direct exhaustive verification of quote-closing and bracket-tracking circuits, plus surrogate verification on task-localized circuits with hard-to-encode attention at larger scales. The stated goal is a concrete path toward formal propositions for circuit explanations, not full-model verification.
Significance. If the framework holds, it would meaningfully advance mechanistic interpretability by enabling formal verification (or refutation) of circuit claims via external solvers rather than informal ablations and examples. The small-task demonstrations provide concrete, exhaustive SMT support for the pipeline on bounded domains with a custom operator stack. Credit is due for the explicit separation of direct and surrogate paths and for producing solver-generated counterexamples. However, the significance is tempered by the acknowledged intractability of direct verification at GPT-2 scale and the limited detail on surrogate fidelity.
major comments (2)
- [Abstract] Abstract: the central claim of a 'concrete path' for turning explanations into verifiable propositions at scale rests on surrogate-mediated verification, yet the manuscript provides no quantitative bounds or reported validation error thresholds for how closely the surrogate must match the extracted circuit on the domain before symbolic properties are accepted as verified.
- [Abstract] Abstract / weakest assumption: the bounded task domain D and candidate-token projection P are treated as sufficient to make verified properties (projected equivalence, invariance, edge necessity, residual robustness) characterize the circuit's relevant behavior, but no argument or experiment demonstrates completeness of (D, P) pairs; if they systematically omit inputs involving unprojected tokens or longer contexts, the SMT results on (D, P) need not imply the claimed circuit behavior on the actual task.
minor comments (1)
- The description of the custom architecture (Signed L1 BandNorm, sparsemax, LeakyReLU) would benefit from an explicit statement of which operators are exactly encodable in SMT versus which require surrogates.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting aspects of the surrogate verification and domain assumptions that merit clarification. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 'concrete path' for turning explanations into verifiable propositions at scale rests on surrogate-mediated verification, yet the manuscript provides no quantitative bounds or reported validation error thresholds for how closely the surrogate must match the extracted circuit on the domain before symbolic properties are accepted as verified.
Authors: We agree that the absence of explicit quantitative bounds on surrogate fidelity weakens the presentation of the central claim. The manuscript describes validation of the surrogate against the circuit on the domain but does not report specific error metrics or acceptance thresholds. In the revised version we will add a subsection reporting maximum absolute error, mean error, and coverage statistics from the surrogate experiments, together with a discussion of how these values bound the soundness of subsequent SMT checks. revision: yes
-
Referee: [Abstract] Abstract / weakest assumption: the bounded task domain D and candidate-token projection P are treated as sufficient to make verified properties (projected equivalence, invariance, edge necessity, residual robustness) characterize the circuit's relevant behavior, but no argument or experiment demonstrates completeness of (D, P) pairs; if they systematically omit inputs involving unprojected tokens or longer contexts, the SMT results on (D, P) need not imply the claimed circuit behavior on the actual task.
Authors: The framework defines all verified properties explicitly with respect to a chosen finite D and projection P; the claims are therefore conditional on those choices rather than asserted to be complete over the full input distribution. The small-task experiments use exhaustive enumeration of the relevant symbolic domain. We will revise the introduction and methods to state this scope more explicitly and to supply guidance on constructing representative (D, P) pairs. A general demonstration that any chosen pair is complete for arbitrary real-world tasks lies outside the paper's stated goal of bounded, solver-checkable claims. revision: partial
Circularity Check
No circularity: verification uses external SMT solvers on explicit bounded domains
full rationale
The paper defines a pipeline that extracts a circuit from a Transformer given a behavior, finite task domain D, and candidate-token projection P, then encodes the circuit (or a validated surrogate) directly into an SMT solver to check properties such as projected functional equivalence and edge necessity. These checks are performed by an external solver on the supplied (D, P) pair; the result is not obtained by fitting a parameter to a subset of the target data and then relabeling the fit as a prediction, nor by any self-citation chain. The bounded-domain assumption is stated explicitly and the verification procedure remains independent of the circuit's internal weights once D and P are fixed. No load-bearing step reduces to a self-definitional equivalence or to a prior result authored by the same team.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math SMT solvers correctly decide the encoded properties over the finite domain
- domain assumption The finite task domain adequately represents the circuit behavior of interest
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer Normalization. arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Luca Baroni, Galvin Khara, Joachim Schaeffer, Marat Subkhankulov, and Stefan Heimersheim. Transformers Don’t Need LayerNorm at Inference Time: Scaling LayerNorm Removal to GPT-2 XL and the Implications for Mechanistic Interpretability. arXiv:2507.02559, 2025
-
[3]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards Automated Circuit Discovery for Mechanistic Interpretability. NeurIPS, 2023
2023
-
[4]
Correia, Vlad Niculae, and André F
Gonçalo M. Correia, Vlad Niculae, and André F. T. Martins. Adaptively Sparse Transformers. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 2174–2184, 2019
2019
-
[5]
Z3: An Efficient SMT Solver
Leonardo de Moura and Nikolaj Bjørner. Z3: An Efficient SMT Solver. TACAS, 2008
2008
-
[6]
Govande, Bowen Baker, and Dan Mossing
Leo Gao, Achyuta Rajaram, Jacob Coxon, Soham V. Govande, Bowen Baker, and Dan Mossing. Weight-Sparse Transformers Have Interpretable Circuits. arXiv:2511.13653, 2025
-
[7]
OpenWebText Corpus
Aaron Gokaslan and Vanya Cohen. OpenWebText Corpus. 2019
2019
-
[8]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian Error Linear Units (GELUs). arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Dill, Kyle Julian, and Mykel J
Guy Katz, Clark Barrett, David L. Dill, Kyle Julian, and Mykel J. Kochenderfer. Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks. CAV, 2017
2017
-
[10]
Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Aleksandar Zeljić, David L
Guy Katz, Derek A. Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Aleksandar Zeljić, David L. Dill, Mykel J. Kochen- derfer, and Clark Barrett. The Marabou Framework for Verification and Analysis of Deep Neural Networks. CAV, 2019
2019
-
[11]
André F. T. Martins and Ramón Fernandez Astudillo. From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. ICML, 2016
2016
-
[12]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer Sentinel Mixture Models. arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
Progress Measures for Grokking via Mechanistic Interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress Measures for Grokking via Mechanistic Interpretability. ICLR, 2023
2023
-
[14]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane 18 Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Language Models are Unsupervised Multitask Learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language Models are Unsupervised Multitask Learners. OpenAI blog, 1(8):9, 2019
2019
-
[16]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. NeurIPS, 2017
2017
-
[17]
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Ruslan Salakhutdinov, and Alexander J. Smola. Deep Sets. NeurIPS, 2017. 19
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.