Learning Where and When: Patch-Based Spatiotemporal Localization in Weakly Supervised Video Anomaly Detection
Pith reviewed 2026-06-30 07:02 UTC · model grok-4.3
The pith
A patch-based framework with proximity-aware selection localizes anomalies in both space and time from video-level labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
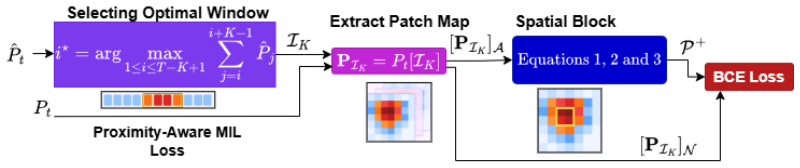
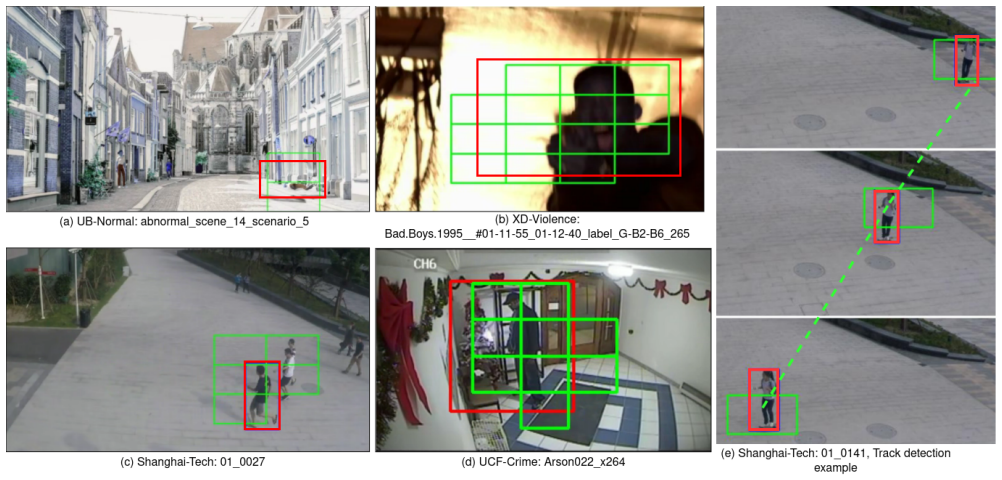
The central discovery is that operating on grid-level patch features and applying a Proximity-Aware Top-k spatiotemporal selection strategy under a multiple instance learning paradigm allows the generation of fine-grained spatial anomaly maps without bounding-box supervision, leading to improved spatiotemporal localization accuracy over existing approaches on multiple benchmarks.
What carries the argument
The Proximity-Aware Top-k spatiotemporal selection strategy, which selects anomalous regions while accounting for spatial proximity to produce accurate fine-grained maps from weak labels.
If this is right
- The model jointly identifies the spatial extent and temporal occurrence of anomalies.
- It achieves substantial gains in spatiotemporal localization accuracy across benchmarks.
- Region-level anomaly scores are learned without requiring spatial annotations during training.
- New frame-level bounding-box annotations are provided for test sets of two datasets to support further research.
Where Pith is reading between the lines
- Similar patch-based approaches could extend to other video understanding tasks that currently rely on weak supervision.
- If the method scales to longer videos, it might enable real-time spatial monitoring in security systems.
- The released annotations could serve as a benchmark for developing fully supervised spatial localization methods.
- Combining this with temporal modeling improvements might further enhance detection of complex anomaly sequences.
Load-bearing premise
That the top-k selection based on proximity can reliably produce accurate spatial maps solely from video-level supervision without additional spatial cues.
What would settle it
Evaluating the generated spatial anomaly maps against ground-truth bounding boxes on the released annotations and finding no improvement over existing weakly supervised methods or random selection would disprove the effectiveness of the approach.
Figures

read the original abstract
Weakly supervised video anomaly detection (WSVAD) has predominantly focused on temporal localization, identifying when anomalies occur while largely neglecting their spatial extent within frames. Yet, spatial localization is essential for interpretability and practical deployment in real-world settings. We introduce a patch-based spatiotemporal framework for weakly supervised anomaly localization that jointly models where and when anomalies occur. Our approach operates on grid-level patch features and learns region-level anomaly scores under a multiple instance learning paradigm. We further propose a Proximity-Aware Top-k spatiotemporal selection strategy that enables the model to generate fine-grained spatial anomaly maps without requiring bounding-box supervision during training. Our method surpasses existing state-of-the-art approaches across multiple benchmarks, yielding substantial gains in spatiotemporal localization accuracy. In addition, we release frame-level bounding-box annotations for the test sets of two widely used datasets, along with our code and pretrained models, providing new resources to facilitate future research in spatially grounded WSVAD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a patch-based spatiotemporal framework for weakly supervised video anomaly detection (WSVAD) that jointly models anomaly location and timing using grid-level patch features under a multiple instance learning (MIL) paradigm. It proposes a Proximity-Aware Top-k spatiotemporal selection strategy to produce fine-grained spatial anomaly maps without bounding-box supervision during training. The work claims to surpass existing state-of-the-art methods across multiple benchmarks with substantial gains in spatiotemporal localization accuracy and releases frame-level bounding-box annotations for the test sets of two datasets along with code and pretrained models.
Significance. If the reported gains in spatiotemporal localization accuracy are robust and reproducible, the work would meaningfully advance WSVAD by addressing the spatial localization gap that has received limited attention, improving interpretability for practical applications. The release of new annotations, code, and models is a clear strength supporting community progress and reproducibility.
minor comments (1)
- [Abstract] The abstract states substantial gains without any quantitative numbers, dataset names, or baseline comparisons; adding these would improve immediate assessment of the central claim.
Simulated Author's Rebuttal
We thank the referee for their summary and for recognizing the significance of addressing spatial localization in WSVAD, as well as the value of the released annotations, code, and models. The recommendation is noted as uncertain, but no specific major comments or concerns were provided in the report for us to address point by point.
Circularity Check
No significant circularity
full rationale
The provided abstract and context contain no equations, fitted parameters, self-citations, or derivation steps that could be inspected for reduction to inputs by construction. The central claim of SOTA gains on spatiotemporal localization is presented as an empirical result from a patch-based MIL framework and Proximity-Aware Top-k strategy, with no indication that any prediction or uniqueness result is defined in terms of itself or forced by prior self-work. The paper releases new annotations and code, which further supports external verifiability. No load-bearing self-definitional, fitted-input, or ansatz-smuggling patterns are present in the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ub- normal: New benchmark for supervised open-set video anomaly detection
Andra Acsintoae, Andrei Florescu, Mariana-Iuliana Georgescu, Tudor Mare, Paul Sumedrea, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. Ub- normal: New benchmark for supervised open-set video anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20143–20153, 2022. 2
2022
-
[2]
Learning temporal reg- ularity in video sequences
Mahmudul Hasan, Jonghyun Choi, Jan Neumann, Amit K Roy-Chowdhury, and Larry S Davis. Learning temporal reg- ularity in video sequences. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 733–742, 2016. 2
2016
-
[3]
Clip-tsa: Clip-assisted temporal self-attention for weakly-supervised video anomaly detection
Hyekang Kevin Joo, Khoa V o, Kashu Yamazaki, and Ngan Le. Clip-tsa: Clip-assisted temporal self-attention for weakly-supervised video anomaly detection. In2023 IEEE International Conference on Image Processing (ICIP), pages 3230–3234. IEEE, 2023. 1, 2
2023
-
[4]
Real-time weakly supervised video anomaly detection
Hamza Karim, Keval Doshi, and Yasin Yilmaz. Real-time weakly supervised video anomaly detection. InProceedings of the IEEE/CVF winter conference on applications of com- puter vision, pages 6848–6856, 2024. 1
2024
-
[5]
Multi-instance learning algo- rithm based on lstm for chinese painting image classification
Daxiang Li and Yue Zhang. Multi-instance learning algo- rithm based on lstm for chinese painting image classification. IEEE Access, 8:179336–179345, 2020. 5
2020
-
[6]
Uniformer: Unifying convolution and self-attention for visual recogni- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):12581–12600, 2023
Kuncheng Li, Yali Wang, Junhao Zhang, Peng Gao, Guan- glu Song, Yu Liu, Hongsheng Li, and Yu Qiao. Uniformer: Unifying convolution and self-attention for visual recogni- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):12581–12600, 2023. 3
2023
-
[7]
Exploring background-bias for anomaly detection in surveillance videos
Kun Liu and Huadong Ma. Exploring background-bias for anomaly detection in surveillance videos. InProceedings of the 27th ACM International Conference on Multimedia, pages 1490–1499, 2019. 2, 5, 7
2019
-
[8]
Learning prompt-enhanced context features for weakly- supervised video anomaly detection.IEEE Transactions on Image Processing, 33:4923–4936, 2024
Yujiang Pu, Xiaoyu Wu, Lulu Yang, and Shengjin Wang. Learning prompt-enhanced context features for weakly- supervised video anomaly detection.IEEE Transactions on Image Processing, 33:4923–4936, 2024. 5, 8
2024
-
[9]
Street scene: A new dataset and evaluation protocol for video anomaly detection
Bharathkumar Ramachandra and Michael Jones. Street scene: A new dataset and evaluation protocol for video anomaly detection. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2569– 2578, 2020. 5
2020
-
[10]
Video anomaly detection with ntcn-ml: A novel tcn for multi-instance learning.Pattern Recognition, 143:109765,
Wenhao Shao, Ruliang Xiao, Praboda Rajapaksha, Mengzhu Wang, Noel Crespi, Zhigang Luo, and Roberto Minerva. Video anomaly detection with ntcn-ml: A novel tcn for multi-instance learning.Pattern Recognition, 143:109765,
-
[11]
Real-world anomaly detection in surveillance videos
Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 6479–6488, 2018. 1, 2, 8
2018
-
[12]
Weakly-supervised video anomaly detection with robust temporal feature magni- tude learning
Yu Tian, Guansong Pang, Yuanhong Chen, Rajvinder Singh, Johan W Verjans, and Gustavo Carneiro. Weakly-supervised video anomaly detection with robust temporal feature magni- tude learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 4975–4986, 2021. 1, 2
2021
-
[13]
Weakly-supervised spatio-temporal anomaly detection in surveillance video
Jie Wu, Wei Zhang, Guanbin Li, Wenhao Wu, Xiao Tan, Yingying Li, Errui Ding, and Liang Lin. Weakly-supervised spatio-temporal anomaly detection in surveillance video. arXiv preprint arXiv:2108.03825, 2021. 2, 5
-
[14]
Not only look, but also listen: Learning multimodal violence detection under weak supervision
Peng Wu, Jing Liu, Yujia Shi, Yujia Sun, Fangtao Shao, Zhaoyang Wu, and Zhiwei Yang. Not only look, but also listen: Learning multimodal violence detection under weak supervision. InEuropean conference on computer vision, pages 322–339. Springer, 2020. 2
2020
-
[15]
Weakly supervised video anomaly detection and localization with spatio-temporal prompts
Peng Wu, Xuerong Zhou, Guansong Pang, Zhiwei Yang, Qingsen Yan, Peng Wang, and Yanning Zhang. Weakly supervised video anomaly detection and localization with spatio-temporal prompts. InProceedings of the 32nd ACM International Conference on Multimedia, pages 9301–9310,
-
[16]
Vadclip: Adapting vision-language models for weakly supervised video anomaly detection
Peng Wu, Xuerong Zhou, Guansong Pang, Lingru Zhou, Qingsen Yan, Peng Wang, and Yanning Zhang. Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. InProceedings of the AAAI con- ference on artificial intelligence, pages 6074–6082, 2024. 1, 2, 5, 8
2024
-
[17]
Vera: Explainable video anomaly detection via verbalized learning of vision- language models
Muchao Ye, Weiyang Liu, and Pan He. Vera: Explainable video anomaly detection via verbalized learning of vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 8679– 8688, 2025. 2
2025
-
[18]
Learning to tell apart: Weakly supervised video anomaly detection via disentangled semantic align- ment
Wenti Yin, Huaxin Zhang, Xiang Wang, Yuqing Lu, Yicheng Zhang, Bingquan Gong, Jialong Zuo, Li Yu, Changxin Gao, and Nong Sang. Learning to tell apart: Weakly supervised video anomaly detection via disentangled semantic align- ment. InProceedings of the AAAI Conference on Artificial Intelligence, 2026. 2
2026
-
[19]
Single-image crowd counting via multi-column convolutional neural network
Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma. Single-image crowd counting via multi-column convolutional neural network. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 589–597, 2016. 2
2016
-
[20]
Spatio-temporal autoencoder for video anomaly detection
Yiru Zhao, Bing Deng, Chen Shen, Yao Liu, Hongtao Lu, and Xian-Sheng Hua. Spatio-temporal autoencoder for video anomaly detection. InProceedings of the 25th ACM interna- tional conference on Multimedia, pages 1933–1941, 2017. 2
1933
-
[21]
Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection
Jia-Xing Zhong, Nannan Li, Weijie Kong, Shan Liu, Thomas H Li, and Ge Li. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1237–1246,
-
[22]
Bidirectional spatio-temporal feature learn- ing with multiscale evaluation for video anomaly detection
Yuanhong Zhong, Xia Chen, Yongting Hu, Panliang Tang, and Fan Ren. Bidirectional spatio-temporal feature learn- ing with multiscale evaluation for video anomaly detection. IEEE Transactions on Circuits and Systems for Video Tech- nology, 32(12):8285–8296, 2022. 2
2022
-
[23]
Dual memory units with uncertainty regulation for weakly supervised video anomaly detection
Hang Zhou, Junqing Yu, and Wei Yang. Dual memory units with uncertainty regulation for weakly supervised video anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3769–3777, 2023. 2, 8
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.