DeRA-MOS: Optimizing Text-to-Music Evaluation via Decoupled Listwise Ranking and Modality Alignment
Pith reviewed 2026-06-27 14:48 UTC · model grok-4.3
The pith
DeRA-MOS replaces point-wise training with listwise ranking and anchored alignment to better match human rank correlations in text-to-music evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
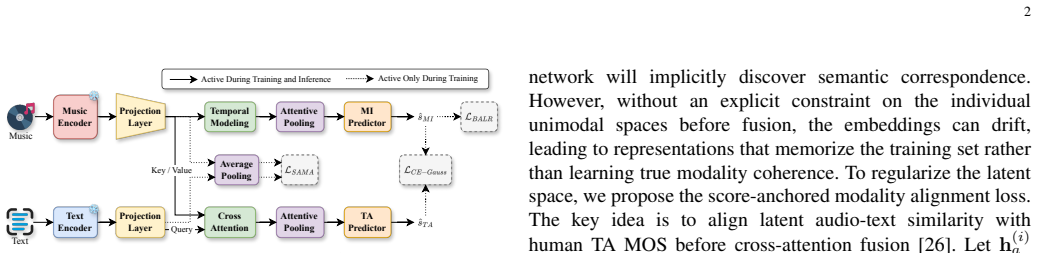
By decoupling the optimization, the batch-aware listwise ranking loss for music impression models relative order within each mini-batch to align training directly with Spearman's rank correlation coefficient, while the score-anchored modality alignment loss for text alignment maps human scores to target audio-text similarity and regularizes the latent space before fusion; together these steps mitigate point-wise training mismatch and modality drift, producing substantial improvements in both MI and TA ranking metrics on the MusicEval dataset.
What carries the argument
Decoupled framework with batch-aware listwise ranking loss for relative order modeling in music impression and score-anchored modality alignment loss for regularizing audio-text latent space in text alignment.
If this is right
- The listwise ranking loss directly targets relative ordering within batches to reduce mismatch with Spearman's coefficient for music impression.
- The modality alignment loss regularizes the latent space by anchoring to human scores, reducing drift between audio and text representations.
- The overall decoupled structure yields measurable gains on both MI and TA ranking metrics in experiments.
- The approach supplies a training paradigm that can support evaluation of large numbers of text-to-music systems without proportional increases in human ratings.
Where Pith is reading between the lines
- The same separation of ranking and alignment objectives could be tested on other audio generation tasks where rank correlation is the primary evaluation measure.
- If the batch listwise loss proves stable across different batch sizes, it might allow training on very large unlabeled music collections before fine-tuning on scored data.
- Future work could replace the fixed anchor scores with learned targets to see whether further gains in cross-modal coherence are possible.
Load-bearing premise
The assumption that modeling relative orders inside each mini-batch with a listwise loss will improve alignment with global Spearman's rank correlation without creating batch-dependent artifacts.
What would settle it
Running the framework on a held-out music evaluation set and finding that the resulting SRCC scores for music impression or text alignment are no higher than those from standard point-wise regression baselines would falsify the improvement claim.
Figures
read the original abstract
Evaluating text-to-music (TTM) systems remains expensive because music impression (MI) and text alignment (TA) scores rely on human mean opinion scores (MOS). Most automatic MOS estimators are trained with point-wise regression or distributional classification. These objectives do not directly optimize rank-based metrics and provide weak geometric constraints for cross-modal coherence. To address these gaps, we propose DeRA-MOS, a decoupled optimization framework for TTM evaluation. For MI, we introduce a batch-aware listwise ranking loss that models relative order within each mini-batch and better aligns with evaluation based on Spearman's rank correlation coefficient (SRCC). For TA, we introduce a score-anchored modality alignment loss that maps human scores to target audio-text similarity and regularizes the latent space before fusion. By effectively mitigating the point-wise training mismatch and modality drift, experiments on MusicEval demonstrate that our decoupled framework yields substantial improvements in both MI and TA ranking metrics, establishing a robust paradigm for large-scale TTM evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeRA-MOS, a decoupled optimization framework for automatic evaluation of text-to-music (TTM) systems. For music impression (MI), it introduces a batch-aware listwise ranking loss intended to better align training with Spearman's rank correlation coefficient (SRCC). For text alignment (TA), it introduces a score-anchored modality alignment loss to map human scores to audio-text similarity and regularize the latent space. The central claim is that this framework mitigates point-wise training mismatch and modality drift, yielding substantial improvements in MI and TA ranking metrics on the MusicEval dataset.
Significance. If the reported gains hold under rigorous evaluation, the work could advance automatic TTM evaluation by shifting from point-wise regression to objectives that more directly target rank-based metrics and cross-modal coherence. The decoupled design and explicit handling of batch-wise ranking are conceptually promising for large-scale evaluation pipelines.
major comments (2)
- [Abstract] Abstract: the claim of 'substantial improvements in both MI and TA ranking metrics' on MusicEval is presented without any numerical results, baseline comparisons, ablation studies, error bars, or dataset statistics. This absence makes the central empirical claim impossible to assess and is load-bearing for the paper's contribution.
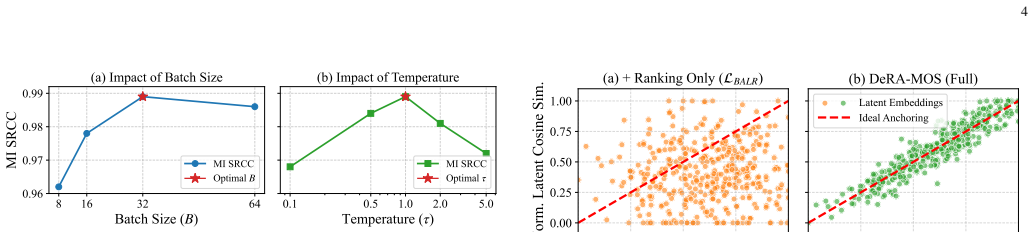
- [Abstract] Abstract (MI loss paragraph): the batch-aware listwise ranking loss is asserted to model relative order within each mini-batch and thereby improve alignment with global SRCC. No description is given of loss aggregation across batches, temperature scaling, regularization, or cross-batch consistency mechanisms. Without these, per-batch permutations may not aggregate to a consistent global ranking on the full MusicEval test set, directly undermining the SRCC improvement claim.
minor comments (1)
- [Abstract] Abstract: the acronym 'DeRA-MOS' is used without expansion or definition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract requires strengthening to better support its central claims and will revise accordingly. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'substantial improvements in both MI and TA ranking metrics' on MusicEval is presented without any numerical results, baseline comparisons, ablation studies, error bars, or dataset statistics. This absence makes the central empirical claim impossible to assess and is load-bearing for the paper's contribution.
Authors: We acknowledge that the abstract's empirical claim would be more assessable with supporting numbers. In the revised manuscript we will incorporate concise quantitative results (e.g., SRCC deltas versus baselines), a brief reference to the main baselines, and dataset size, while preserving abstract length. Full experimental details, ablations, and error bars remain in Sections 4 and 5. revision: yes
-
Referee: [Abstract] Abstract (MI loss paragraph): the batch-aware listwise ranking loss is asserted to model relative order within each mini-batch and thereby improve alignment with global SRCC. No description is given of loss aggregation across batches, temperature scaling, regularization, or cross-batch consistency mechanisms. Without these, per-batch permutations may not aggregate to a consistent global ranking on the full MusicEval test set, directly undermining the SRCC improvement claim.
Authors: The abstract is space-constrained and therefore high-level. The full manuscript (Section 3.2) specifies the listwise loss formulation, its temperature scaling, the per-batch application, and the epoch-wise aggregation that produces a consistent global ranking. We will add a short clause to the abstract mentioning temperature scaling and cross-batch consistency via stochastic optimization over the training set. This directly addresses the aggregation concern while the empirical SRCC results on the held-out test set serve as validation. revision: yes
Circularity Check
No circularity: new losses are independent of evaluation metrics
full rationale
The paper introduces two new training objectives (batch-aware listwise ranking loss for MI and score-anchored modality alignment loss for TA) that are optimized against human MOS labels on training data. Evaluation uses standard ranking metrics (SRCC, etc.) on the MusicEval test set. No quoted equations or self-citations show the claimed improvements reducing by construction to the inputs; the listwise loss models per-batch order but is not mathematically identical to global SRCC, and modality alignment is a separate regularizer. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AudioLDM: Text-to-audio generation with latent diffusion models,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “AudioLDM: Text-to-audio generation with latent diffusion models,” inProc. ICML, 2023, pp. 21 450–21 474
2023
-
[2]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchi, M. Sharifi, N. Zeghidour, and C. Frank, “MusicLM: Generating music from text,” 2023, arXiv:2301.11325. [Online]. Available: https://arxiv.org/abs/2301.11325
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. Defossez, “Simple and controllable music generation,” inProc. NeurIPS, 2023, pp. 47 704–47 720
2023
-
[4]
Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models,
R. Huang, J. Huang, D. Yang, Y . Ren, L. Liu, M. Li, Z. Ye, J. Liu, X. Yin, and Z. Zhao, “Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models,” inProc. ICML, 2023, pp. 13 916– 13 932
2023
-
[5]
MusicEval: A generative music dataset with expert ratings for automatic text-to-music evaluation,
C. Liu, H. Wang, J. Zhao, S. Zhao, H. Bu, X. Xu, J. Zhou, H. Sun, and Y . Qin, “MusicEval: A generative music dataset with expert ratings for automatic text-to-music evaluation,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[6]
NISQA: A deep CNN- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A deep CNN- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,” inProc. Interspeech, 2021, pp. 2127–2131
2021
-
[7]
UTMOS: UTokyo-SaruLab system for V oiceMOS chal- lenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab system for V oiceMOS chal- lenge 2022,” inProc. Interspeech, 2022, pp. 4521–4525
2022
-
[8]
MOSNet: Deep learning-based objective assessment for voice conversion,
C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi, Y . Tsao, and H.-M. Wang, “MOSNet: Deep learning-based objective assessment for voice conversion,” inProc. Interspeech, 2019, pp. 1541–1545
2019
-
[9]
MBNET: MOS prediction for synthesized speech with mean-bias network,
Y . Leng, X. Tan, S. Zhao, F. Soong, X.-Y . Li, and T. Qin, “MBNET: MOS prediction for synthesized speech with mean-bias network,” in Proc. ICASSP, 2021, pp. 391–395
2021
-
[10]
Modelling inter-rater uncertainty in spoken language assessment,
J. H. M. Wong, H. Zhang, and N. F. Chen, “Modelling inter-rater uncertainty in spoken language assessment,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2886–2898, 2023
2023
-
[11]
LDNet: Unified listener dependent modeling in MOS prediction for synthetic speech,
W.-C. Huang, E. Cooper, J. Yamagishi, and T. Toda, “LDNet: Unified listener dependent modeling in MOS prediction for synthetic speech,” inProc. ICASSP, 2022, pp. 896–900
2022
-
[12]
DeePMOS-B: Deep posterior mean-opinion-score Using beta distribution,
X. Liang, F. Cumlin, V . Ungureanu, C. K. A. Reddy, C. Sch ¨uldt, and S. Chatterjee, “DeePMOS-B: Deep posterior mean-opinion-score Using beta distribution,” inProc. EUSIPCO, 2024, pp. 416–420
2024
-
[13]
Rank consistent ordinal regres- sion for neural networks with application to age estimation,
W. Cao, V . Mirjalili, and S. Raschka, “Rank consistent ordinal regres- sion for neural networks with application to age estimation,”Pattern Recognition Letters, vol. 140, pp. 325–331, 2020
2020
-
[14]
ASTAR-NTU solution to AudioMOS challenge 2025 track1,
F. Ritter-Gutierrez, Y .-C. Lin, J.-C. Wei, J. H. M. Wong, N. F. Chen, and H.-y. Lee, “ASTAR-NTU solution to AudioMOS challenge 2025 track1,” inProc. IEEE ASRU, 2025
2025
-
[15]
Fr ´echet audio distance: A reference-free metric for evaluating music enhancement algorithms,
K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi, “Fr ´echet audio distance: A reference-free metric for evaluating music enhancement algorithms,” inProc. Interspeech, 2019, pp. 2350–2354
2019
-
[16]
Adapting frechet audio distance for generative music evaluation,
A. Gui, H. Gamper, S. Braun, and D. Emmanouilidou, “Adapting frechet audio distance for generative music evaluation,” inProc. ICASSP, 2024, pp. 1331–1335
2024
-
[17]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[18]
MuQ: Self-supervised music representation learning with mel residual vector quantization,
H. Zhu, Y . Zhou, H. Chen, J. Yu, Z. Ma, R. Gu, Y . Luo, W. Tan, and X. Chen, “MuQ: Self-supervised music representation learning with mel residual vector quantization,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 3653–3664, 2025
2025
-
[19]
Label distribution learning,
X. Geng, “Label distribution learning,”IEEE Transactions on Knowl- edge and Data Engineering, vol. 28, no. 7, pp. 1734–1748, 2016
2016
-
[20]
Soft labels for ordinal regression,
R. Diaz and A. Marathe, “Soft labels for ordinal regression,” inProc. CVPR, 2019, pp. 4738–4747
2019
-
[21]
Learning to rank: From pairwise approach to listwise approach,
Z. Cao, T. Qin, T.-Y . Liu, M.-F. Tsai, and H. Li, “Learning to rank: From pairwise approach to listwise approach,” inProc. ICML, 2007, pp. 129–136
2007
-
[22]
Listwise approach to learning to rank: Theory and algorithm,
F. Xia, T.-Y . Liu, J. Wang, W. Zhang, and H. Li, “Listwise approach to learning to rank: Theory and algorithm,” inProc. ICML, 2008, pp. 1192–1199
2008
-
[23]
Audioclip: Extending clip to image, text and audio,
A. Guzhov, F. Raue, J. Hees, and A. Dengel, “Audioclip: Extending clip to image, text and audio,” inProc. ICASSP, 2022, pp. 976–980
2022
-
[24]
Learning to rank with nonsmooth cost functions,
C. Burges, R. Ragno, and Q. Le, “Learning to rank with nonsmooth cost functions,” inProc. NeurIPS, vol. 19, 2006
2006
-
[25]
QAMRO: Quality-aware adaptive margin ranking optimiza- tion for human-aligned assessment of audio generation systems,
C.-C. Wang, K.-T. Huang, C.-Y . Yang, H.-S. Lee, H.-M. Wang, and B. Chen, “QAMRO: Quality-aware adaptive margin ranking optimiza- tion for human-aligned assessment of audio generation systems,” in Proc. IEEE ASRU, 2025
2025
-
[26]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inProc. ICML, 2020, pp. 1597–1607
2020
-
[27]
DRASP: A dual-resolution attentive statistics pooling frame- work for automatic MOS prediction,
C.-Y . Yang, K.-T. Huang, C.-C. Wang, H.-S. Lee, H.-M. Wang, and B. Chen, “DRASP: A dual-resolution attentive statistics pooling frame- work for automatic MOS prediction,” inProc. APSIPA ASC, 2025, pp. 2038–2043
2025
-
[28]
The AudioMOS challenge 2025,
W.-C. Huang, H. Wang, C. Liu, Y .-C. Wu, A. Tjandra, W.-N. Hsu, E. Cooper, Y . Qin, and T. Toda, “The AudioMOS challenge 2025,” in Proc. IEEE ASRU, 2025
2025
-
[29]
A New Measure of Rank Correlation,
M. G. Kendall, “A New Measure of Rank Correlation,”Biometrika, 1938
1938
-
[30]
Generalization ability of MOS prediction networks,
E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Generalization ability of MOS prediction networks,” inProc. ICASSP, 2022, pp. 8442– 8446
2022
-
[31]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “RoBERTa: A robustly optimized BERT pretraining approach,” 2019, arXiv:1907.11692. [Online]. Available: http://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[33]
Wilcoxon signed-rank test,
R. F. Woolson, “Wilcoxon signed-rank test,” inWiley Encyclopedia of Clinical Trials, 2008, pp. 1–3
2008
-
[34]
Gradient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gradient surgery for multi-task learning,” inProc. NeurIPS, vol. 33, 2020, pp. 5824–5836
2020
-
[35]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inProc. ICML, 2021, pp. 5530–5540
2021
-
[36]
HiFi-GAN: Generative adversarial net- works for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial net- works for efficient and high fidelity speech synthesis,” inProc. NeurIPS, vol. 33, 2020, pp. 17 022–17 033
2020
-
[37]
Maximum likelihood estimation of observer error-rates using the EM algorithm,
A. P. Dawid and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the EM algorithm,”Journal of the Royal Statistical Society: Series C (Applied Statistics), vol. 28, no. 1, pp. 20– 28, 1979
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.