SilIF: Silhouette-Augmented Isolation Forest for Unsupervised Transaction Fraud Detection
Pith reviewed 2026-06-30 16:57 UTC · model grok-4.3
The pith
SilIF adds a silhouette score from clustered path length vectors to Isolation Forest and raises AUC-PR by 0.008 on real fraud data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
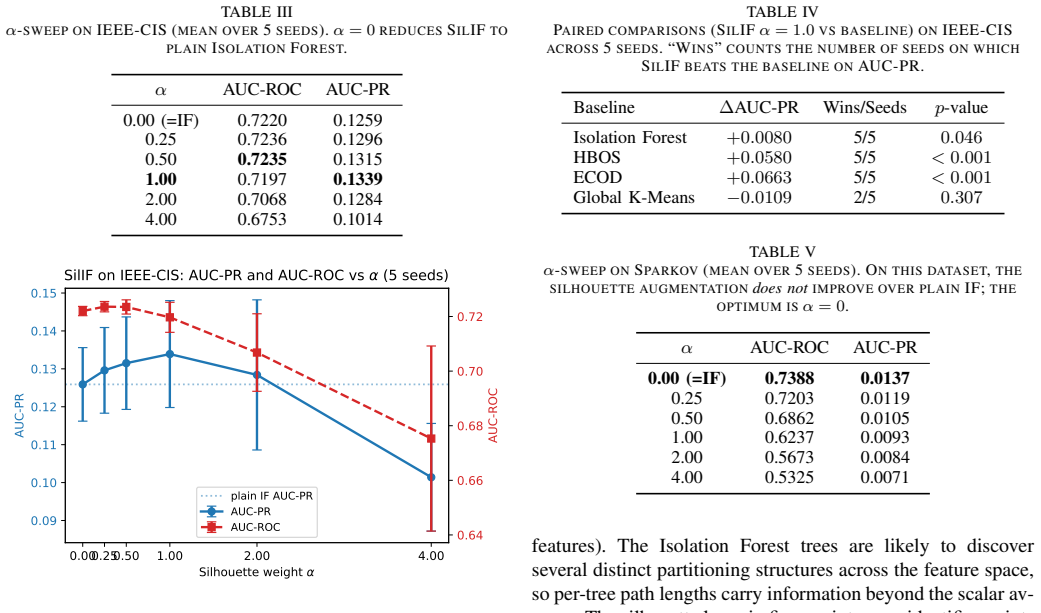
SilIF extracts a vector of per-tree path lengths for each transaction, clusters these fingerprints into structural groups, and computes a silhouette score measuring fit to the assigned group versus the nearest alternative. The silhouette signal is combined with the base Isolation Forest score via a hyperparameter alpha. On the IEEE-CIS Fraud Detection benchmark of approximately 590K transactions, alpha set to 1.0 yields an average AUC-PR gain of 0.0080 over plain Isolation Forest across five seeds, with SilIF ahead on every seed. The paper also reports no gain on a synthetic credit-card dataset and describes conditions that separate the two outcomes.
What carries the argument
silhouette score computed on clustered per-tree path length vectors, which supplies a structural-fit signal combined with the base isolation score
If this is right
- SilIF raises AUC-PR by 0.0080 on the IEEE-CIS benchmark and wins on all five seeds tested.
- The gain is statistically supported by a paired t-test p-value of 0.046.
- No improvement occurs on the synthetic Sparkov credit-card dataset.
- A single parameter alpha lets users control how much the silhouette signal contributes.
- The method stays as scalable and easy to deploy as standard Isolation Forest.
Where Pith is reading between the lines
- Real transaction data may contain more varied structural clusters than synthetic data, which is why the silhouette layer adds value only in the former case.
- Users can decide whether to apply SilIF by measuring its effect on a held-out portion of their own data.
- The same silhouette extraction from path-length vectors could be tested on other tree-based anomaly detectors.
Load-bearing premise
The per-tree path length vectors contain additional structural information that produces a silhouette signal meaningfully independent of the original isolation score.
What would settle it
If the silhouette scores correlate strongly with the base isolation scores or if the average AUC-PR gain disappears on several additional large real fraud datasets, the added layer would not be contributing independent value.
Figures
read the original abstract
Unsupervised anomaly detection is widely used in transaction fraud detection where labels are scarce. Isolation Forest (IF) is among the most popular classical methods due to its scalability and ease of deployment. We propose SilIF, an augmentation of Isolation Forest that adds a silhouette-based scoring layer computed in a representation space induced by the trees of the forest. For each point, we extract a vector of per-tree path lengths, cluster these "fingerprints" into structural groups, and compute a silhouette score that measures how well the point fits its assigned group versus the nearest alternative. The silhouette signal is combined with the base IF score via a single hyperparameter alpha. On the IEEE-CIS Fraud Detection benchmark (~590K transactions, 3.5% fraud), SilIF with alpha=1.0 improves over plain Isolation Forest by +0.0080 AUC-PR on average across five seeds, with SilIF winning on all five seeds (paired t-test p=0.046). We also report results on a synthetic credit-card dataset (Sparkov) where the silhouette augmentation does not improve over plain IF, and we characterize the conditions that distinguish the two outcomes. The paper presents SilIF as a tunable, easy-to-deploy enhancement to Isolation Forest with honest reporting of when it helps and when it does not. Code at https://github.com/venkat15vk/silif-anomaly-detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SilIF, an augmentation to Isolation Forest that adds a silhouette-based scoring layer from clustering per-tree path length vectors. The silhouette signal is linearly combined with the base IF score using hyperparameter alpha. On the IEEE-CIS Fraud Detection benchmark, SilIF with alpha=1.0 achieves an average +0.0080 improvement in AUC-PR over plain IF across five seeds, winning on all seeds (paired t-test p=0.046). No improvement is observed on the Sparkov dataset.
Significance. If the silhouette augmentation provides genuinely independent structural information, this represents a lightweight, deployable enhancement to a standard method in unsupervised fraud detection. The release of code and the honest characterization of when the method helps versus when it does not are positive features.
major comments (2)
- [Experimental evaluation on IEEE-CIS] The central claim that the silhouette layer augments the isolation score requires that the silhouette score carries information orthogonal to the base IF anomaly score. No correlation analysis between the two scores, nor an ablation study comparing SilIF to IF with a random or null silhouette component, is reported. This leaves open the possibility that the observed gain is due to the linear combination mechanics rather than added structural signal.
- [Statistical analysis] The paired t-test with p=0.046 is reported for five seeds. With such a small number of replicates and a modest effect size (+0.008 AUC-PR), the result is sensitive to seed choice; the manuscript should report the individual seed AUC-PR values or bootstrap confidence intervals to substantiate robustness.
minor comments (1)
- The abstract mentions 'characterize the conditions that distinguish the two outcomes' but the full text should ensure this characterization is detailed enough for readers to predict applicability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the evidence needed to support the contribution of the silhouette layer. We address each major comment below.
read point-by-point responses
-
Referee: [Experimental evaluation on IEEE-CIS] The central claim that the silhouette layer augments the isolation score requires that the silhouette score carries information orthogonal to the base IF anomaly score. No correlation analysis between the two scores, nor an ablation study comparing SilIF to IF with a random or null silhouette component, is reported. This leaves open the possibility that the observed gain is due to the linear combination mechanics rather than added structural signal.
Authors: We agree that explicit evidence of orthogonality would strengthen the central claim. In the revised manuscript we will add (i) a Pearson correlation analysis between the base Isolation Forest anomaly scores and the silhouette scores on the IEEE-CIS data and (ii) an ablation in which the silhouette component is replaced by random values sampled from the empirical distribution of silhouette scores. The absence of improvement on the Sparkov dataset already indicates that the gain is not an artifact of the linear combination alone, but we will make this argument explicit with the new experiments. revision: yes
-
Referee: [Statistical analysis] The paired t-test with p=0.046 is reported for five seeds. With such a small number of replicates and a modest effect size (+0.008 AUC-PR), the result is sensitive to seed choice; the manuscript should report the individual seed AUC-PR values or bootstrap confidence intervals to substantiate robustness.
Authors: We acknowledge that five replicates are modest and that reporting only the mean and p-value limits assessment of robustness. In the revision we will add a table of per-seed AUC-PR values for both methods and will report bootstrap confidence intervals (with 10,000 resamples) for the mean difference in AUC-PR. revision: yes
Circularity Check
No circularity: purely empirical method with no derivation reducing to inputs
full rationale
The paper introduces SilIF as an algorithmic augmentation to Isolation Forest: per-tree path lengths are extracted, clustered, and used to compute a silhouette score that is linearly combined with the base IF score via a single tunable hyperparameter alpha. All claims are empirical (AUC-PR gains on IEEE-CIS, no gain on Sparkov) with explicit reporting of tuning and negative results. No equations, predictions, or first-principles results are presented that reduce by construction to fitted parameters or self-citations. The central result is a benchmark comparison, not a derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (1)
- domain assumption Path-length vectors from the forest trees form clusters whose silhouette scores capture anomaly-relevant structure not already encoded in the isolation depth.
Reference graph
Works this paper leans on
-
[1]
Anomaly detection: A survey,
V . Chandola, A. Banerjee, and V . Kumar, “Anomaly detection: A survey,” ACM Computing Surveys, vol. 41, no. 3, pp. 1–58, 2009
2009
-
[2]
Fraud dataset benchmark and applications.arXiv preprint arXiv:2208.14417, 2022
P. Grover, J. Xu, J. Tittelfitz, A. Cheng, Z. Li, J. Zablocki, J. Liu, and H. Zhou, “Fraud dataset benchmark and applications,”arXiv preprint arXiv:2208.14417, 2022
-
[3]
Isolation forest,
F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation forest,” in2008 Eighth IEEE International Conference on Data Mining. IEEE, 2008, pp. 413– 422
2008
-
[4]
Isolation-based anomaly detection,
——, “Isolation-based anomaly detection,”ACM Transactions on Knowledge Discovery from Data, vol. 6, no. 1, pp. 1–39, 2012
2012
-
[5]
Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,”Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987
1987
-
[6]
IEEE- CIS fraud detection,
IEEE Computational Intelligence Society and Vesta Corporation, “IEEE- CIS fraud detection,” Kaggle Competition, 2019, https://www.kaggle. com/c/ieee-fraud-detection
2019
-
[7]
Credit card transactions fraud detection dataset,
K. Shenoy, “Credit card transactions fraud detection dataset,” Kaggle Dataset, generated with Sparkov simulator, 2020, https://www.kaggle. com/datasets/kartik2112/fraud-detection
2020
-
[8]
Sparkov data generation,
B. Harris, “Sparkov data generation,” GitHub repository, 2019, https: //github.com/namebrandon/Sparkov Data Generation
2019
-
[9]
Extended isolation for- est,
S. Hariri, M. Carrasco Kind, and R. J. Brunner, “Extended isolation for- est,”IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 4, pp. 1479–1489, 2021
2021
-
[10]
Deep isolation forest for anomaly detection,
H. Xu, G. Pang, Y . Wang, and Y . Wang, “Deep isolation forest for anomaly detection,” inIEEE Transactions on Knowledge and Data Engineering, 2023
2023
-
[11]
Improved anomaly detection by using the attention-based isolation forest,
L. Utkin, A. Ageev, A. Konstantinov, and V . Muliukha, “Improved anomaly detection by using the attention-based isolation forest,”Algo- rithms, vol. 16, no. 1, p. 19, 2022
2022
-
[12]
Robust random cut forest based anomaly detection on streams,
S. Guha, N. Mishra, G. Roy, and O. Schrijvers, “Robust random cut forest based anomaly detection on streams,” inInternational Conference on Machine Learning. PMLR, 2016, pp. 2712–2721
2016
-
[13]
Lof: Identifying density-based local outliers,
M. M. Breunig, H.-P. Kriegel, R. T. Ng, and J. Sander, “Lof: Identifying density-based local outliers,” inProceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 2000, pp. 93–104
2000
-
[14]
Discovering cluster-based local outliers,
Z. He, X. Xu, and S. Deng, “Discovering cluster-based local outliers,” Pattern Recognition Letters, vol. 24, no. 9-10, pp. 1641–1650, 2003
2003
-
[15]
Applied machine learning to anomaly detection in enterprise purchase processes,
A. Herreros-Mart ´ınez, R. Magdalena-Benedicto, J. Vila-Franc ´es, A. J. Serrano-L´opez, and S. P ´erez-D´ıaz, “Applied machine learning to anomaly detection in enterprise purchase processes,”arXiv preprint arXiv:2405.14754, 2024
-
[16]
Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm,
M. Goldstein and A. Dengel, “Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm,” inKI-2012: Poster and Demo Track, 2012, pp. 59–63
2012
-
[17]
Ecod: Unsupervised outlier detection using empirical cumulative distribution functions,
Z. Li, Y . Zhao, N. Botta, C. Ionescu, and X. Hu, “Ecod: Unsupervised outlier detection using empirical cumulative distribution functions,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 12, pp. 12 181–12 193, 2023
2023
-
[18]
Efficient algorithms for mining outliers from large data sets,
S. Ramaswamy, R. Rastogi, and K. Shim, “Efficient algorithms for mining outliers from large data sets,” inProceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 2000, pp. 427–438
2000
-
[19]
Deep learning for anomaly detection: A review,
G. Pang, C. Shen, L. Cao, and A. V . D. Hengel, “Deep learning for anomaly detection: A review,”ACM Computing Surveys, vol. 54, no. 2, pp. 1–38, 2021
2021
-
[20]
ADBench: Anomaly detection benchmark,
S. Han, X. Hu, H. Huang, M. Jiang, and Y . Zhao, “ADBench: Anomaly detection benchmark,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[21]
Web-scale k-means clustering,
D. Sculley, “Web-scale k-means clustering,” inProceedings of the 19th International Conference on World Wide Web, 2010, pp. 1177–1178
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.