NanoCP: Request-Level Dynamic Context Parallelism for Data-Expert Parallel Decoding
Pith reviewed 2026-05-21 01:47 UTC · model grok-4.3
The pith
NanoCP uses request-level dynamic context parallelism to balance KV cache and batch sizes in MoE serving, achieving higher request rates and lower tail latency under strict SLOs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
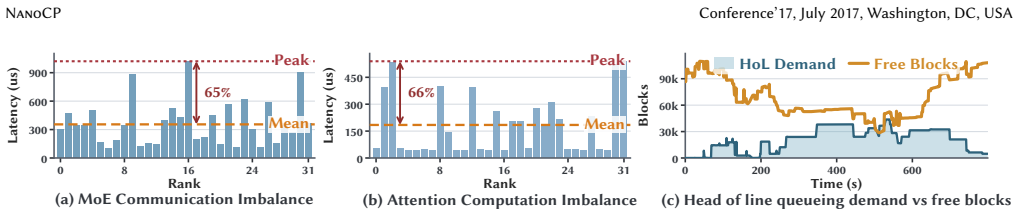
By decoupling MoE communication from KV cache placement via dynamic context parallelism, where each request receives a context-parallel degree sized to its KV footprint, NanoCP balances per-instance KV occupancy and batch sizes. Long requests distribute attention across multiple instances and short requests stay local. This is enabled by an ahead-of-time graph engine paired with a custom routing-based communication backend that bridges the dynamic parallelism to static execution without prohibitive overheads.
What carries the argument
Dynamic context parallelism (DCP) that assigns each request a variable context-parallel degree based on its KV cache size to balance attention computation and expert communication across the cluster.
If this is right
- Maintains up to 1.88×–3.27× higher request rates under strict TPOT SLOs.
- Reduces P99 tail latency by up to 1.79×–2.12× by mitigating EP stragglers.
- Balances KV cache occupancy and batch sizes across instances without additional load-balancing costs.
- Effectively liquefies the KV cache across the cluster for long-context requests.
Where Pith is reading between the lines
- Applying this per-request dynamic parallelism could improve serving efficiency for other large language models with varying context lengths.
- Future systems might integrate similar decoupling mechanisms to handle memory fragmentation in distributed inference setups.
- Testing DCP on different hardware configurations could reveal scalability limits of the AOT graph engine.
Load-bearing premise
That an ahead-of-time graph engine paired with a custom routing-based communication backend can bridge per-request dynamic context parallelism to static execution without introducing prohibitive overheads that would erase the reported gains.
What would settle it
A direct measurement of the communication and execution overhead introduced by the AOT graph engine and custom backend when DCP is active, compared against a baseline without dynamic parallelism.
Figures













read the original abstract
Modern serving systems for Mixture-of-Experts (MoE) models adopt hybrid data-expert parallelism: expert parallelism (EP) shards experts across GPUs to scale capacity, while data parallelism (DP) replicates attention layers across instances to process independent requests. Existing systems bind each request's attention, MoE communication, and KV cache to a single instance. Because attention latency scales with KV cache size while MoE communication latency scales with batch size, this binding cannot balance both simultaneously, producing EP stragglers; it also fragments KV memory across instances, inflating tail latency under long contexts. While existing context parallelism (CP) mitigates these constraints, its uniform parallelism degree incurs prohibitive communication and attention-side overheads. We present \work, which decouples MoE communication from KV cache placement and achieves dual balance through dynamic context parallelism (DCP). DCP assigns each request a context-parallel degree sized to its KV footprint: long requests distribute attention across multiple instances; short requests remain local. This dynamic parallelism effectively liquefies the KV cache across the cluster, balancing both the per-instance KV cache occupancy and batch sizes without unnecessary load-balancing costs. To bridge DCP with static execution, \work introduces an ahead-of-time (AOT) graph engine paired with a custom routing-based communication backend. Experimental results show that \work maintains up to $1.88\times$--$3.27\times$ higher request rates under strict time-per-output-token (TPOT) service level objectives (SLOs). Furthermore, \work significantly mitigates stragglers, reducing P99 tail latency by up to $1.79\times$--$2.12\times$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NanoCP for serving Mixture-of-Experts models under hybrid data-expert parallelism. It proposes request-level dynamic context parallelism (DCP) that assigns per-request context-parallel degrees based on KV footprint, decoupling MoE communication from KV cache placement. An ahead-of-time graph engine and custom routing-based communication backend are used to map dynamic assignments to static execution. The central claims are up to 1.88×–3.27× higher request rates under strict TPOT SLOs and up to 1.79×–2.12× reduction in P99 tail latency.
Significance. If validated, the result would be significant for large-scale MoE inference serving. It directly targets the tension between attention latency (scaling with KV size) and MoE communication latency (scaling with batch size) that produces stragglers and fragmented KV memory in existing systems. The dynamic, request-granular approach to context parallelism, combined with the AOT engine to preserve static execution, offers a concrete path to better cluster-wide balance without uniform parallelism overheads.
major comments (2)
- [Evaluation] Evaluation section: the central performance claims (1.88×–3.27× request-rate improvement and 1.79×–2.12× P99 reduction) rest on the premise that the AOT graph engine and routing backend add negligible overhead relative to the DCP gains. No isolated latency breakdown (routing decision time, graph instantiation cost, or per-component communication volume) is reported that would allow attribution of the measured improvements specifically to DCP rather than to unstated factors or baseline differences.
- [System Design] Section describing the AOT graph engine: the claim that dynamic per-request context-parallel assignments can be bridged to static execution without prohibitive overhead is load-bearing for the entire contribution. The manuscript provides no quantitative characterization of recompilation or routing costs under varying request lengths and arrival patterns, leaving open whether these costs remain small when KV-cache placement and attention topology change on a per-request basis.
minor comments (3)
- [Abstract] Abstract: the experimental claims would be easier to assess if the abstract briefly stated the model sizes, number of GPUs, workload characteristics (context lengths, batch sizes), and the exact baselines against which the 1.88×–3.27× and 1.79×–2.12× numbers are measured.
- Notation: the phrase 'liquefies the KV cache' is informal; a precise description of how DCP redistributes KV occupancy and attention communication across instances would improve clarity.
- [Evaluation] Figure captions and tables: ensure that all reported speedups include error bars or confidence intervals and explicitly state the number of runs or statistical significance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major comment point by point below and have revised the manuscript to strengthen the evaluation and system characterization as suggested.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central performance claims (1.88×–3.27× request-rate improvement and 1.79×–2.12× P99 reduction) rest on the premise that the AOT graph engine and routing backend add negligible overhead relative to the DCP gains. No isolated latency breakdown (routing decision time, graph instantiation cost, or per-component communication volume) is reported that would allow attribution of the measured improvements specifically to DCP rather than to unstated factors or baseline differences.
Authors: We agree that an isolated latency breakdown is necessary to rigorously attribute gains to DCP. In the revised manuscript we have added a new microbenchmark subsection (Section 5.4) with measurements of routing decision time (0.15–0.3 ms per request), AOT graph instantiation cost (0.4–1.2 ms depending on request length), and per-component communication volume. These results confirm that the combined overhead remains below 4 % of end-to-end latency and does not explain the reported speedups. revision: yes
-
Referee: [System Design] Section describing the AOT graph engine: the claim that dynamic per-request context-parallel assignments can be bridged to static execution without prohibitive overhead is load-bearing for the entire contribution. The manuscript provides no quantitative characterization of recompilation or routing costs under varying request lengths and arrival patterns, leaving open whether these costs remain small when KV-cache placement and attention topology change on a per-request basis.
Authors: We acknowledge the importance of quantifying these costs under realistic dynamics. The revised evaluation (Section 5.5) now includes experiments with request-length distributions drawn from production traces and Poisson arrivals at varying rates. The new data show average recompilation cost below 1.8 % of inference time and routing overhead that scales sub-linearly with context-parallel degree changes, remaining under 3 ms even at the highest measured dynamism. revision: yes
Circularity Check
No significant circularity: claims rest on experimental measurements, not derivations or self-referential definitions
full rationale
The paper presents a systems contribution for MoE serving via dynamic context parallelism (DCP), an AOT graph engine, and routing backend. All performance claims (1.88×–3.27× request rates, 1.79×–2.12× P99 latency reduction) are stated as outcomes of experimental evaluation under TPOT SLOs. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central mechanism (decoupling MoE communication from KV placement via per-request DCP) is described as an engineering design choice whose benefits are measured directly rather than derived by construction from prior results or inputs. This is a standard empirical systems paper; the derivation chain is absent, so no reduction to inputs occurs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention latency scales with KV cache size while MoE communication latency scales with batch size.
invented entities (2)
-
Dynamic Context Parallelism (DCP)
no independent evidence
-
Ahead-of-time (AOT) graph engine
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DCP assigns each request a context-parallel degree sized to its KV footprint: long requests distribute attention across multiple instances; short requests remain local.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.equivNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NanoCP introduces an ahead-of-time (AOT) graph engine paired with a custom routing-based communication backend.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 117–134.https://www.usenix...
work page 2024
-
[2]
2025.No Request Left Behind: Tackling Heterogeneity in Long-Context LLM Inference with Medha
Amey Agrawal, Haoran Qiu, Junda Chen, Íñigo Goiri, Chaojie Zhang, Rayyan Shahid, Ramachandran Ramjee, Alexey Tumanov, and Esha Choukse. 2025.No Request Left Behind: Tackling Heterogeneity in Long-Context LLM Inference with Medha. arXiv:2409.17264 [cs.LG] https://arxiv.org/abs/2409.17264
-
[3]
2026.State of AI: An Empirical 100 Trillion Token Study with OpenRouter
Malika Aubakirova, Alex Atallah, Chris Clark, Justin Summerville, and Anjney Midha. 2026.State of AI: An Empirical 100 Trillion Token Study with OpenRouter. arXiv:2601.10088 doi:10.48550/arXiv.2601.10088
-
[4]
Nidhi Bhatia, Ankit More, Ritika Borkar, Tiyasa Mitra, Ramon Matas, Ritchie Zhao, Maximilian Golub, Dheevatsa Mudigere, Brian Phar- ris, and Bita Darvish Rouhani. 2025.Helix Parallelism: Rethinking Sharding Strategies for Interactive Multi-Million-Token LLM Decoding. arXiv:2507.07120 doi:10.48550/arXiv.2507.07120
- [5]
-
[6]
Chang Chen, Min Li, Zhihua Wu, Dianhai Yu, and Chao Yang. 2022. TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training. In Advances in Neural Information Processing Systems 35: Annual Con- ference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, Sanmi Koyejo, S. Mohamed, A. Agarwal, ...
work page 2022
-
[7]
Hongtao Chen, Weiyu Xie, Boxin Zhang, Jingqi Tang, Jiahao Wang, Jianwei Dong, Shaoyuan Chen, Ziwei Yuan, Chen Lin, Chengyu Qiu, Yuening Zhu, Qingliang Ou, Jiaqi Liao, Xianglin Chen, Zhiyuan Ai, Yongwei Wu, and Mingxing Zhang. 2025. KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models. In Proceedings of the ACM SIGOPS 31s...
- [8]
-
[9]
LMDeploy Contributors. 2023. LMDeploy: A Toolkit for Compressing, Deploying, and Serving LLM.https://github.com/InternLM/lmdeploy
work page 2023
-
[10]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. MSCCLang: Microsoft Collective Communication Language. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada)(ASPLOS 2023). ACM, New York, NY, USA, 502–514. doi:10....
-
[11]
Tri Dao, Daniel Haziza, Francisco Massa, and Grigory Sizov. 2023. Flash-Decoding for long-context inference. PyTorch Blog
work page 2023
-
[12]
DeepSeek-AI. 2024.DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL]https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
DeepSeek-AI. 2024. EPLB: Expert Parallelism Load Balancer.https: //github.com/deepseek-ai/EPLB
work page 2024
-
[14]
DeepSeek-AI. 2025. DeepGEMM: Clean and Efficient FP8 GEMM Kernels with Fine-Grained Scaling.https://github.com/deepseek-ai/ DeepGEMM. GitHub repository
work page 2025
-
[15]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zi- fan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. 2025.SWE-Bench Pro: Can AI Agents Solve ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch trans- formers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
-
[17]
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. 2023. Megablocks: Efficient sparse training with mixture-of-experts.Pro- ceedings of Machine Learning and Systems5 (2023), 288–304
work page 2023
-
[18]
Hao Ge, Fangcheng Fu, Haoyang Li, Xuanyu Wang, Sheng Lin, Yujie Wang, Xiaonan Nie, Hailin Zhang, Xupeng Miao, and Bin Cui. 2024. Enabling parallelism hot switching for efficient training of large lan- guage models. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 178–194
work page 2024
-
[19]
Abhishek Ghosh, Ajay Nayak, Ashish Panwar, and Arkaprava Basu
-
[20]
arXiv:2503.19779 [cs.LG]https://arxiv.org/abs/2503.19779
PyGraph: Robust Compiler Support for CUDA Graphs in PyTorch. arXiv:2503.19779 [cs.LG]https://arxiv.org/abs/2503.19779
-
[21]
MoETuner: Optimized mixture of expert serving with balanced expert placement and token routing,
Seokjin Go and Divya Mahajan. 2025.MoETuner: Optimized Mixture of Expert Serving with Balanced Expert Placement and Token Routing. arXiv:2502.06643 [cs.LG]https://arxiv.org/abs/2502.06643
-
[22]
Amos Goldman, Nimrod Boker, Maayan Sheraizin, Nimrod Ad- moni, Artem Polyakov, Subhadeep Bhattacharya, Fan Yu, Kai Sun, Georgios Theodorakis, Hsin-Chun Yin, Peter-Jan Gootzen, Aamir Shafi, Assaf Ravid, Salvatore Di Girolamo, James Dinan, Xiaofan Li, Manjunath Gorentla Venkata, and Gil Bloch. 2026. NCCL EP: Towards a Unified Expert Parallel Communication A...
-
[23]
Shwai He, Weilin Cai, Jiayi Huang, and Ang Li. 2026. Capacity- Aware Inference: Mitigating the Straggler Effect in Mixture of Experts. arXiv:2503.05066 [cs.LG]https://arxiv.org/abs/2503.05066
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Junhao Hu, Jiang Xu, Zhixia Liu, Yulong He, Yuetao Chen, Hao Xu, Jiang Liu, Jie Meng, Baoquan Zhang, Shining Wan, Gengyuan Dan, Zhiyu Dong, Zhihao Ren, Changhong Liu, Tao Xie, Dayun Lin, Qin Zhang, Yue Yu, Hao Feng, Xusheng Chen, and Yizhou Shan. 2025. DEEPSERVE: serverless large language model serving at scale. In Proceedings of the 2025 USENIX Conferenc...
work page 2025
-
[25]
Changho Hwang, Peng Cheng, Roshan Dathathri, Abhinav Jangda, Saeed Maleki, Madan Musuvathi, Olli Saarikivi, Aashaka Shah, Ziyue Yang, Binyang Li, Caio Rocha, Qinghua Zhou, Mahdieh Ghazimir- saeed, Sreevatsa Anantharamu, and Jithin Jose. 2026. MSCCL++: Rethinking GPU Communication Abstractions for AI Inference. In Conference’17, July 2017, Washington, DC, ...
-
[26]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Reza Yazdani Aminadabi, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. 2024. System optimizations for enabling training of extreme long sequence transformer models. InProceedings of the 43rd ACM Symposium on Principles of Distributed Computing. 121–130
work page 2024
-
[27]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al . 2024. Mixtral of experts.ArXiv preprintabs/2401.04088 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Chenyu Jiang, Zhenkun Cai, Ye Tian, Zhen Jia, Yida Wang, and Chuan Wu. 2025. DCP: Addressing Input Dynamism In Long-Context Training via Dynamic Context Parallelism. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 221–236
work page 2025
-
[29]
Shengyu Liu Jiashi Li. 2025. FlashMLA: Efficient Multi-head Latent Attention Kernels.https://github.com/deepseek-ai/FlashMLA
work page 2025
-
[30]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
work page 2024
-
[31]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[32]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
- [33]
-
[34]
2026.Semantic Parallelism: Redefining Efficient MoE Inference via Model-Data Co-Scheduling
Yan Li, Zhenyu Zhang, Zhengang Wang, Pengfei Chen, and Pengfei Zheng. 2026.Semantic Parallelism: Redefining Efficient MoE Inference via Model-Data Co-Scheduling. arXiv:2503.04398 [cs.LG]https://arxiv. org/abs/2503.04398
-
[35]
Nandor Licker, Kevin Hu, Vladimir Zaytsev, and Lequn Chen
-
[36]
fabric-lib: RDMA Point-to-Point Communication for LLM Systems
RDMA Point-to-Point Communication for LLM Systems. arXiv:2510.27656 [cs.DC]https://arxiv.org/abs/2510.27656
work page internal anchor Pith review Pith/arXiv arXiv
- [37]
-
[38]
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2024. RingAttention with Blockwise Transformers for Near-Infinite Context. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
work page 2024
-
[39]
2025.Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving
Ziming Liu, Boyu Tian, Guoteng Wang, Zhen Jiang, Peng Sun, Zhenhua Han, Tian Tang, Xiaohe Hu, Yanmin Jia, Yan Zhang, He Liu, Mingjun Zhang, Yiqi Zhang, Qiaoling Chen, Shenggan Cheng, Mingyu Gao, Yang You, and Siyuan Feng. 2025.Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving. arXiv:2509.17863 [cs.DC] https://arxiv.org/a...
-
[40]
Jinming Ma, Jiefei Chen, Xiuhong Li, Jiangfei Duan, Haojie Duanmu, Xingcheng Zhang, Chao Yang, and Dahua Lin. 2025. Tropical: Enhanc- ing SLO Attainment in Disaggregated LLM Serving via SLO-Aware Multiplexing. In2025 62nd ACM/IEEE Design Automation Conference (DAC). 1–7. doi:10.1109/DAC63849.2025.11132617
- [41]
-
[42]
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applications. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). USENIX Association, Carlsbad, CA, 561–57...
work page 2018
-
[43]
NVIDIA Corporation. 2026. NVIDIA NCCL Source Code.https:// github.com/NVIDIA/nccl
work page 2026
-
[44]
Gabriele Oliaro, Xupeng Miao, Xinhao Cheng, Vineeth Kada, Mengdi Wu, Ruohan Gao, Yingyi Huang, Remi Delacourt, April Yang, Yingcheng Wang, Colin Unger, and Zhihao Jia. 2025. FlexLLM: Token- Level Co-Serving of LLM Inference and Finetuning with SLO Guaran- tees. arXiv:2402.18789 [cs.DC]https://arxiv.org/abs/2402.18789
-
[45]
OpenAI. 2026. GPT-5.4 Model.https://developers.openai.com/api/ docs/models/gpt-5.4. Official model documentation for GPT-5.4, including snapshotgpt-5.4-2026-03-05; accessed 2026-04-16
work page 2026
-
[46]
OpenRouter. 2026. OpenRouter Rankings: Model Usage Statistics. https://openrouter.ai/rankings. Accessed: February 23, 2026
work page 2026
-
[47]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
work page 2024
-
[48]
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. 2025. A New Era of Intelligence with Gemini 3.https://blog.google/products- and-platforms/products/gemini/gemini-3/. Google Blog, accessed 2026-04-16
work page 2025
-
[49]
PyTorch Foundation. 2023. Accelerating Generative AI with PyTorch II: GPT, Fast.https://pytorch.org/blog/accelerating-generative-ai-2/. Accessed: 2026-04-16
work page 2023
-
[50]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Moon- cake: Trading More Storage for Less Computation — A KVCache- centric Architecture for Serving LLM Chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 155–170.https://w...
work page 2025
-
[51]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5
work page 2026
-
[52]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. DeepSpeed-MoE: Advancing Mixture-of-Experts Infer- ence and Training to Power Next-Generation AI Scale. InInternational Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Proceedings o...
work page 2022
-
[53]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic scheduling for large lan- guage model serving. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 173–191
work page 2024
-
[54]
Xinru Tang, Jingxiang Hou, Dingcheng Jiang, Taiquan Wei, Jiaxin Liu, Jinyi Deng, Huizheng Wang, Qize Yang, Haoran Shang, Chao Li, et al
- [55]
-
[56]
Xiaojuan Tang, Fanxu Meng, Pingzhi Tang, Yuxuan Wang, Di Yin, Xing Sun, and Muhan Zhang. 2026. TPLA: Tensor Parallel Latent Attention for Efficient Disaggregated Prefill & Decode Inference. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (USA)(ASPLOS ’26). Associati...
-
[57]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.ArXiv preprintabs/2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. 2026. Kimi K2. 5: Visual Agentic Intelligence.ArXiv preprintabs/2602.02276 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chen- zhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, ...
-
[60]
Kimi K2: Open Agentic Intelligence
Kimi K2: Open Agentic Intelligence. arXiv:2507.20534 [cs.LG] https://arxiv.org/abs/2507.20534
work page internal anchor Pith review Pith/arXiv arXiv
- [61]
-
[62]
Jian Tian, Shuailong Li, Yang Cao, Wenbo Cui, Minghan Zhu, Wenkang Wu, Jianming Zhang, Yanpeng Wang, Zhiwen Xiao, Zhenyu Hou, and Dou Shen. 2025.Staggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference. arXiv:2512.16134 [cs.DC]https://arxiv.org/abs/2512.16134
-
[63]
Ilyas Turimbetov, Mohamed Wahib, and Didem Unat. 2025. A Device- Side Execution Model for Multi-GPU Task Graphs. InProceedings of the 39th ACM International Conference on Supercomputing (ICS ’25). Association for Computing Machinery, New York, NY, USA, 384–396. doi:10.1145/3721145.3730426
-
[64]
Hulin Wang, Yaqi Xia, Donglin Yang, Xiaobo Zhou, and Dazhao Cheng. 2025. Harnessing inter-gpu shared memory for seamless moe communication-computation fusion. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Pro- gramming. 170–182
work page 2025
-
[65]
Ne Wang, Wenxiang Lin, Lin Zhang, Shaohuai Shi, Ruiting Zhou, and Bo Li. 2025. SP-MoE: Expediting Mixture-of-Experts Training with Optimized Pipelining Planning. InIEEE INFOCOM 2025-IEEE Conference on Computer Communications. IEEE, 1–10
work page 2025
-
[66]
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xue- feng Xiao, Huixia Li, Jiashi Li, Faming Wu, and Bin Cui. 2025. Flexsp: Accelerating large language model training via flexible sequence par- allelism. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Sys- tems, Volume 2...
work page 2025
-
[67]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 640–654
work page 2024
- [68]
-
[69]
Yueru Yan, Tuc Nguyen, Bo Su, Melissa Lieffers, and Thai Le. 2025. ShareChat: A Dataset of Chatbot Conversations in the Wild.ArXiv preprintabs/2512.17843 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.ArXiv preprintabs/2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jongsoo Park, and Jianyu Huang. 2025. Context par- allelism for scalable million-token inference.Proceedings of Machine Learning and Systems7 (2025)
work page 2025
-
[72]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Asso- ciation, Carlsbad, CA, 521–538.https://www.usenix.org/conference/ osdi22/presentation/yu
work page 2022
-
[73]
Xingkai Yu. [n. d.]. Nano-vLLM: A lightweight vLLM implementation built from scratch.https://github.com/GeeeekExplorer/nano-vllm. GitHub repository
-
[74]
Zhexiang Zhang, Ye Wang, Xiangyu Wang, Yumiao Zhao, Jingzhe Jiang, Qizhen Weng, Shaohuai Shi, Yin Chen, and Minchen Yu. 2025. Janus: Disaggregating Attention and Experts for Scalable MoE Inference. arXiv:2512.13525 [cs.DC]https://arxiv.org/abs/2512.13525
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Huazuo Gao, Jiashi Li, Liyue Zhang, Panpan Huang, Shangyan Zhou, Shirong Ma, et al . 2025. Insights into deepseek-v3: Scaling challenges and reflections on hardware for ai architectures. InProceedings of the 52nd Annual International Symposium on Computer Architecture. 1731–1745
work page 2025
-
[76]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library.https://github.com/ deepseek-ai/DeepEP
work page 2025
-
[77]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. WildChat: 1M ChatGPT Interaction Logs in the Wild. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
work page 2024
-
[78]
Bojian Zheng, Cody Hao Yu, Jie Wang, Yaoyao Ding, Yizhi Liu, Yida Wang, and Gennady Pekhimenko. 2023. Grape: Practical and Efficient Graphed Execution for Dynamic Deep Neural Networks on GPUs. In Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture(Toronto, ON, Canada)(MICRO ’23). Association for Computing Machinery, New Yo...
-
[79]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric P. Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. 2024. LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, ...
work page 2024
-
[80]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark W. Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InAd- vances in Neural Information Processing Systems 38: Annual Conference on Neural Information Process...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.