Merging of Bayes and quasi-Bayes empirical Bayes procedures for Poisson compound decisions
Pith reviewed 2026-07-03 07:24 UTC · model grok-4.3
The pith
Bayesian and quasi-Bayesian empirical Bayes procedures merge in frequentist sense for Poisson compound decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
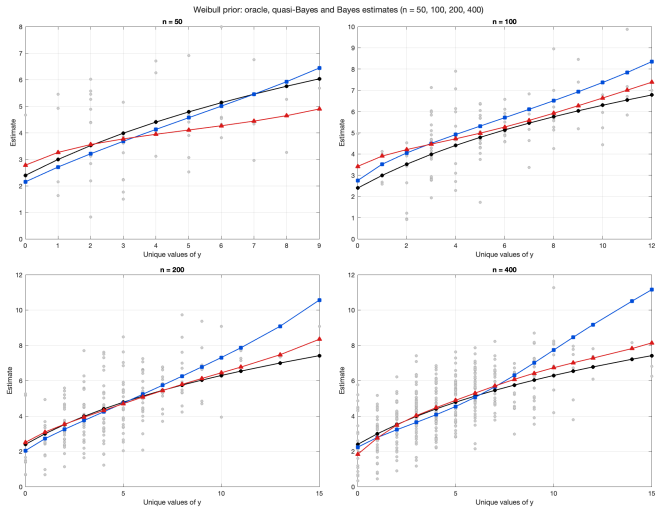
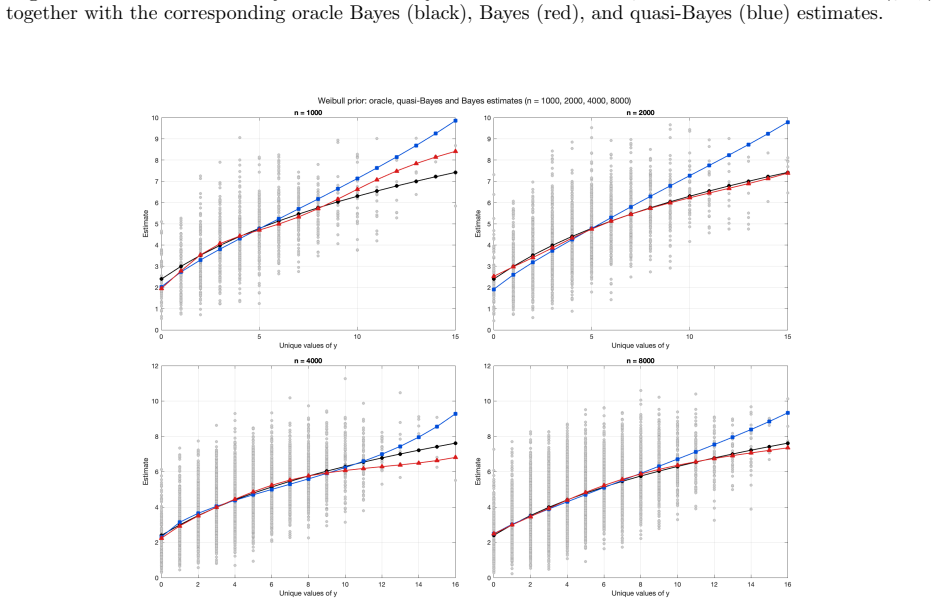
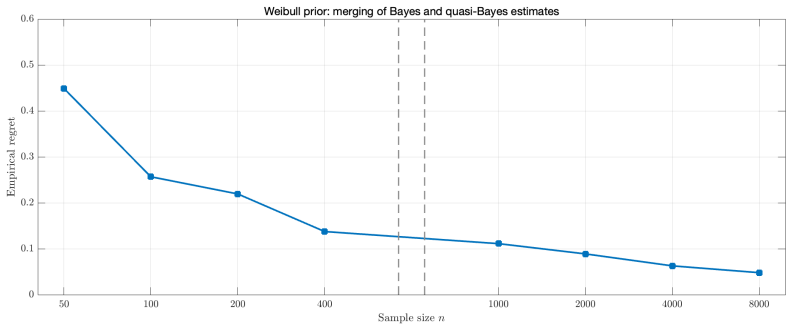
Under a Poisson mixture model with a true or oracle mixing distribution, concentration rates for the marginal probability mass functions induced by the Bayesian and quasi-Bayesian estimates translate into rates of decay for the corresponding regrets and prove a frequentist merging result between the Bayesian and quasi-Bayesian empirical Bayes strategies. The analysis is extended to the multidimensional Poisson compound decision problem.
What carries the argument
Concentration rates of the marginal probability mass functions induced by the Dirichlet process posterior and by Newton's algorithm estimates, translated into rates of decay for the corresponding regrets.
If this is right
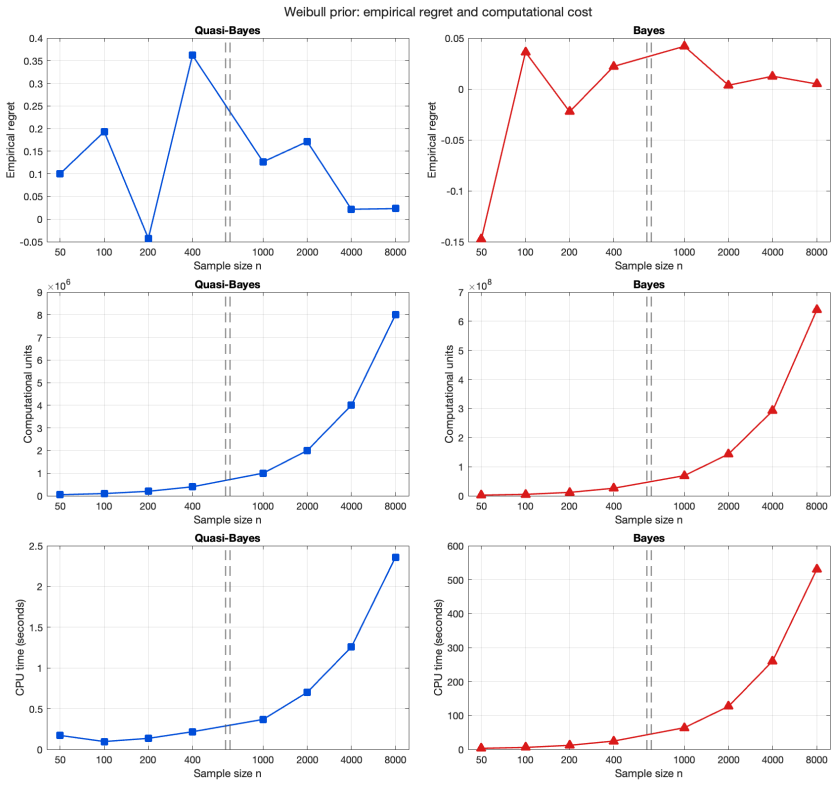
- The quasi-Bayesian strategy achieves accuracy comparable to the Bayesian strategy while using substantially fewer computational resources.
- The frequentist merging result extends directly to the multidimensional Poisson compound decision problem.
- Regret decay rates are determined by the concentration behavior of the induced marginal probability mass functions.
- Numerical experiments on synthetic data confirm that the quasi-Bayesian strategy matches the Bayesian one in practice.
Where Pith is reading between the lines
- If the merging holds, the faster quasi-Bayesian method can replace the Dirichlet process approach for large-scale Poisson compound decisions without asymptotic performance loss.
- The same concentration-to-regret translation may apply to other mixture models once comparable concentration rates are available.
- The result supplies a theoretical justification for preferring Newton's algorithm in settings where computational cost grows with dimension.
Load-bearing premise
The data are generated from a Poisson mixture model that possesses a fixed true or oracle mixing distribution.
What would settle it
Repeated simulations drawn from a known fixed mixing distribution in which the difference between the two regrets fails to decay at the established rate would falsify the merging result.
Figures
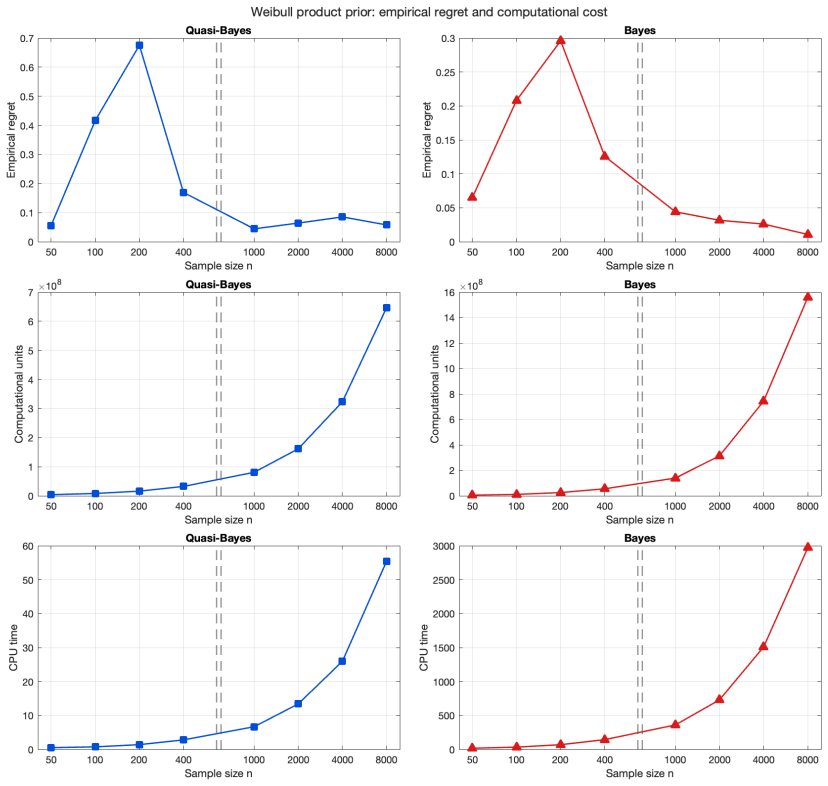
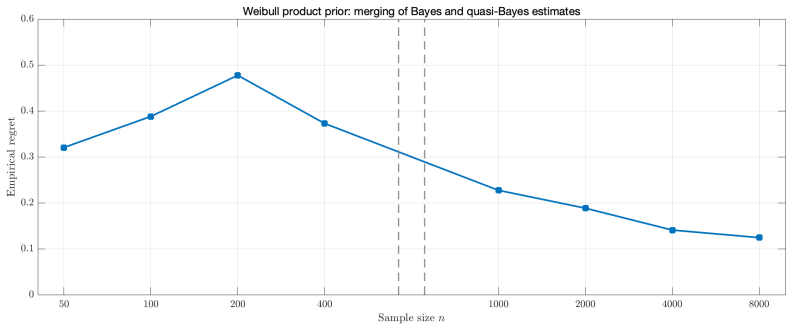
read the original abstract
The Poisson compound decision problem is a long-standing problem in statistics, in which empirical Bayes methods are used to estimate Poisson means under a mixture model. We study this problem from the viewpoint of $g$-modeling, comparing two nonparametric strategies for estimating the unknown mixing distribution: a Bayesian empirical Bayes strategy, based on the Dirichlet process posterior, and a quasi-Bayesian empirical Bayes strategy, based on Newton's algorithm. The latter is computationally attractive, but its relationship with the Bayesian strategy requires theoretical justification. Under a Poisson mixture model with a ``true'', or oracle, mixing distribution, we establish concentration rates for the marginal probability mass functions induced by the Bayesian and quasi-Bayesian estimates. These rates are then translated into rates of decay for the corresponding regrets, interpreted as excess Bayes risks, and used to prove a frequentist merging result between the Bayesian and quasi-Bayesian empirical Bayes strategies. We also extend the analysis to the multidimensional Poisson compound decision problem. Numerical experiments on synthetic data illustrate that the quasi-Bayesian strategy achieves accuracy comparable to the Bayesian strategy, while requiring substantially fewer computational resources, especially in the multidimensional setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the Poisson compound decision problem under g-modeling, comparing a Bayesian empirical Bayes estimator based on the Dirichlet process posterior with a quasi-Bayesian estimator based on Newton's algorithm. Under a Poisson mixture model with a fixed true mixing distribution, it derives concentration rates for the induced marginal PMFs, translates these into rates for the corresponding regrets (excess Bayes risk), and proves a frequentist merging result between the two procedures. The analysis is extended to the multidimensional Poisson compound decision problem, with numerical experiments on synthetic data showing comparable accuracy for the quasi-Bayesian method at lower computational cost.
Significance. If the concentration and merging results hold, the work supplies a rigorous frequentist justification for preferring the computationally lighter quasi-Bayesian procedure in empirical Bayes applications to Poisson data. The multidimensional extension and the explicit translation from PMF concentration to regret decay are valuable contributions. The manuscript includes reproducible numerical experiments that directly illustrate the practical performance comparison.
major comments (3)
- [§3.2] §3.2 (concentration rates for the quasi-Bayesian estimator): the claimed rate for the marginal PMF induced by Newton's algorithm is stated without an explicit derivation of the n^{-1/4} term or the dependence on the smoothness of the true mixing distribution; this step is load-bearing for the subsequent regret and merging claims.
- [§4] §4 (translation to regret decay): the argument invokes standard risk bounds for Bayes rules under Poisson mixtures, but does not verify that the identifiability constants remain uniform over the class of mixing distributions considered; this uniformity is required for the merging rate to hold uniformly.
- [§5.1] §5.1 (multidimensional extension): the extension assumes that the concentration rates carry over without additional logarithmic factors in dimension d, yet no explicit dependence on d is derived or bounded; this affects the practical scope of the merging result.
minor comments (3)
- [Table 1] Table 1: the reported CPU times lack standard errors or number of replications, making it difficult to assess variability of the computational advantage.
- [§2] Notation: the symbol G_n for the quasi-Bayesian estimate is introduced without an explicit algorithmic definition in the main text (only referenced to Newton 2002); a short pseudocode box would improve readability.
- [References] References: the citation list omits recent work on concentration of Dirichlet process mixtures for discrete data (e.g., papers post-2018 on posterior contraction for Poisson mixtures).
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments, which help clarify the presentation of our concentration and merging results. We address each major comment below and will incorporate the suggested clarifications and derivations in a revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (concentration rates for the quasi-Bayesian estimator): the claimed rate for the marginal PMF induced by Newton's algorithm is stated without an explicit derivation of the n^{-1/4} term or the dependence on the smoothness of the true mixing distribution; this step is load-bearing for the subsequent regret and merging claims.
Authors: We agree that an explicit derivation strengthens the argument. In the revision we will add a self-contained lemma deriving the n^{-1/4} rate for the marginal PMF under Newton's algorithm, making the dependence on the Hölder smoothness index of the true mixing distribution fully explicit and citing the relevant empirical-process bounds used. revision: yes
-
Referee: [§4] §4 (translation to regret decay): the argument invokes standard risk bounds for Bayes rules under Poisson mixtures, but does not verify that the identifiability constants remain uniform over the class of mixing distributions considered; this uniformity is required for the merging rate to hold uniformly.
Authors: We will add a short paragraph in Section 4 verifying uniformity of the identifiability constants over the compact class of mixing distributions used in the paper (or over the slightly restricted subclass needed for uniformity). This will be stated as a standing assumption with a brief justification based on the continuity of the Poisson mixture map. revision: yes
-
Referee: [§5.1] §5.1 (multidimensional extension): the extension assumes that the concentration rates carry over without additional logarithmic factors in dimension d, yet no explicit dependence on d is derived or bounded; this affects the practical scope of the merging result.
Authors: We acknowledge the omission. The revision will include an explicit bound on the d-dependence (including possible logarithmic factors) for the multidimensional concentration rates, together with a brief discussion of the resulting restriction on the merging rate when d grows with n. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper derives concentration rates for marginal PMFs induced by Dirichlet process and Newton's algorithm estimators under an assumed Poisson mixture model with fixed oracle mixing distribution, then translates those rates into regret decay and a frequentist merging result. This follows standard frequentist asymptotic arguments relying on identifiability of Poisson mixtures and risk bounds for Bayes rules; no parameters are fitted to the same data used for evaluation, no self-definitional loops appear in the equations, and no load-bearing self-citations or ansatzes are invoked. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of a true or oracle mixing distribution under the Poisson mixture model
Reference graph
Works this paper leans on
-
[1]
and Jordan, M.I
Blei, D.M. and Jordan, M.I. (2006). Variational inference for Dirichlet process mixtures. Bayesian Anal. 1, 121--144
2006
-
[2]
and Farrell, R.H
Brown, L.D. and Farrell, R.H. (1985). Complete class theorems for estimation of multivariate Poisson means and related problems. Ann. Statist. 13, 706--726
1985
-
[3]
and Ritov, Y
Brown, L.D., Greenshtein, E. and Ritov, Y. (2013). The Poisson compound decision problem revisited. J. Am. Statist. Assoc. 108, 741--749
2013
-
[4]
Universal priors: solving empirical Bayes via Bayesian inference and pretraining
Cannella, N., Teh, A., Han Y. and Polyanskiy, Y. (2026). Universal priors: solving empirical Bayes via Bayesian inference and pretraining. Preprint arXiv:2602.15136
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
and Lindley, D.V
Deely, J.J. and Lindley, D.V. (1981). Bayes empirical Bayes. J. Am. Statist. Assoc. 76, 833--841
1981
-
[6]
Efron, B. (2014). Two modeling strategies for empirical Bayes estimation. Statist. Sci. 29, 285--301
2014
-
[7]
Efron, B. (2019). Bayes, oracle Bayes and empirical Bayes. Statist. Sci. 34, 177--201
2019
-
[8]
and Fortini, S
Favaro, S. and Fortini, S. (2026). Quasi-Bayes empirical Bayes: a sequential approach to the Poisson compound decision problem. Biometrika, to appear
2026
-
[9]
Ferguson, T.S. (1973). A Bayesian analysis of some nonparametric problems. Ann. Statist. 1, 209--230
1973
-
[10]
and Petrone, S
Fortini, S. and Petrone, S. (2020). Quasi-Bayesian properties of a procedure for sequential learning in mixture models. J. R. Statist. Soc. B 82, 1087--1114
2020
-
[11]
and van der Vaart, A.W
Ghosal, S. and van der Vaart, A.W. (2001). Entropies and rates of convergence for maximum likelihood and Bayes estimation for mixtures of normal densities. Ann. Statist. 29, 1233--1263
2001
-
[12]
Ignatiadis, N. and Kankanala, S. (2026). Compound decisions and empirical Bayes via Bayesian nonparametrics. Preprint arXiv:2602.20115
-
[13]
and James, L.F
Ishwaran, H. and James, L.F. (2001). Gibbs sampling methods for stick-breaking priors. J. Amer. Statist. Assoc. 96, 161--173
2001
-
[14]
and Wu, Y
Jana, S., Polyanskiy, Y., Teh, A. and Wu, Y. (2023). Empirical Bayes via ERM and Rademacher complexities: the Poisson model. P. Mach. Learn. Res. 195, 1--37
2023
-
[15]
and Wu, Y
Jana, S., Polyanskiy, Y. and Wu, Y. (2025). Optimal empirical Bayes estimation for the Poisson model via minimum-distance methods. Inf. Inference 14, 1--42
2025
-
[16]
Johnstone, I. (1986). Admissible estimation, Dirichlet principles and recurrence of birth-death chains on Z _ + ^ p . Probab. Theory Related Fields 71, 231--269
1986
-
[17]
Lo, A.Y. (1984). On a class of Bayesian nonparametric estimates. I. Density estimates Ann. Statist. 12, 351--357
1984
-
[18]
and Ghosh, J.K
Martin, R. and Ghosh, J.K. (2008). Stochastic approximation and Newton’s estimate of a mixing distribution. Statist. Sci. 23, 365--382
2008
-
[19]
and Tokdar, S.T
Martin, R. and Tokdar, S.T. (2009) Asymptotic properties of predictive recursion: robustness and rate of convergence. Electron. J. Stat. 3, 1455--1472
2009
-
[20]
Neal, R. M. (2000). Markov chain sampling methods for Dirichlet process mixture models. J. Comput. Graph. Statist. 9, 249--265
2000
-
[21]
and Zhang, Y
Newton, M.A., Quintana, F.A. and Zhang, Y. (1998). Nonparametric Bayes methods using predictive updating. In Practical Nonparametric and Semiparametric Bayesian Statistics, Springer
1998
-
[22]
and Roberts, G.O
Papaspiliopoulos, O. and Roberts, G.O. (2008). Retrospective Markov chain Monte Carlo methods for Dirichlet process hierarchical models. Biometrika 95, 169--186
2008
-
[23]
Sharp regret bounds for empirical
Polyanskiy, Y. and Wu, Y (2021). Sharp regret bounds for empirical Bayes and compound decision problems. Preprint arXiv: 2109.03943
-
[24]
Robbins, H. (1951). Asymptotically subminimax solutions of compound decision problems. In Proc. Second Berkeley Symp 2, 131--148
1951
-
[25]
Robbins, H. (1956). An empirical Bayes approach to statistics. In Proc. Third Berkeley Symp. 3, 157--164
1956
-
[26]
and Wu, Y
Shen, Y. and Wu, Y. (2026). Poisson empirical Bayes estimation: When does g -modeling beat f -modeling in theory (and in practice)? Ann. Statist. 54, 146--175
2026
-
[27]
and Makov, U.E
Smith, A.F.M. and Makov, U.E. (1978). A quasi-Bayes sequential procedure for mixtures. J. R. Statist. Soc. B 40, 106--112
1978
-
[28]
Teh, A., Jabbour, M. and Polyanskiy, Y. (2025). Solving empirical Bayes via transformers. Preprint arXiv:2502.09844
-
[29]
Walker, S.G. (2007). Sampling the Dirichlet mixture model with slices. Comm. Statist. Simulation Comput. 36, 45--54
2007
-
[30]
Zhang, C.-H. (2003). Compound decision theory and empirical Bayes methods. Ann. Statist. 31, 379--390
2003
-
[31]
Zhang, C.-H. (2005). Estimation of sums of random variables: examples and information bounds. Ann. Statist. 33, 2022--2041
2005
-
[32]
and Shen, X
Wong, H.W. and Shen, X. (1995). Probability inequalities for likelihood ratios and convergence rates of sieve MLES Ann. Statist. 23, 339--362
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.