SwiftVR: Real-Time One-Step Generative Video Restoration
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
SwiftVR achieves real-time 1080p generative video restoration on consumer GPUs using mask-free attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
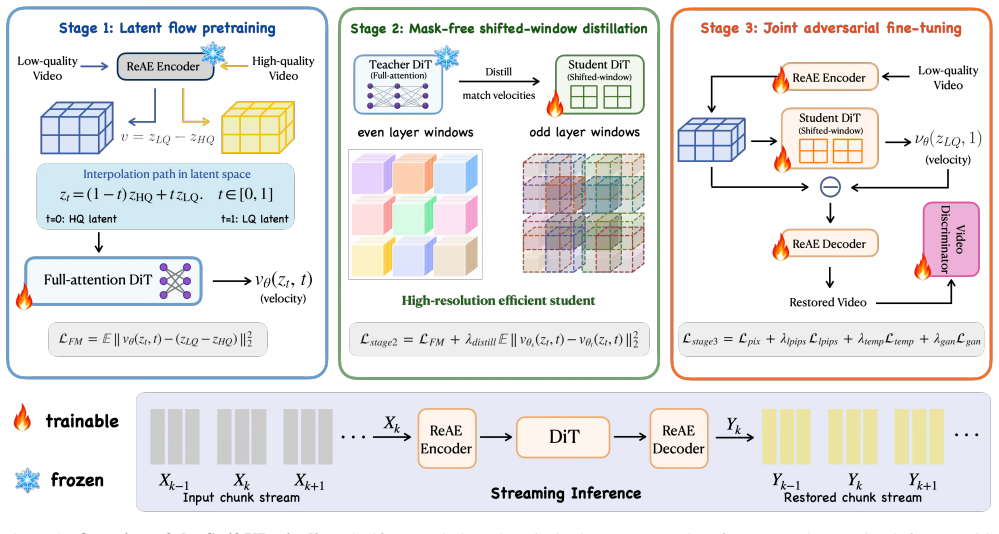
SwiftVR reduces attention and autoencoding bottlenecks in one-step diffusion video restoration under a causal chunk-wise protocol by implementing mask-free shifted-window self-attention via deterministic indexing that keeps every attention call on the dense scaled dot-product path, combined with a lightweight Restoration-aware Autoencoder, yielding real-time 1080p performance on consumer GPUs with strong perceptual quality.
What carries the argument
Mask-free shifted-window self-attention that gathers each spatial window into a dense tensor via deterministic indexing, so all calls use standard dense SDPA without masks, cyclic shifts, padding, or sparse kernels.
If this is right
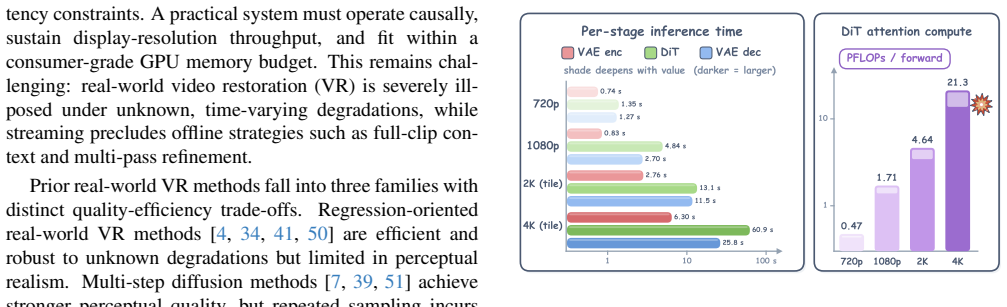
- Sustains 31 FPS at 2560x1440 and 14 FPS at 3840x2160 on a single H100 without exceeding memory limits.
- Reaches 26 FPS at 1920x1080 on an RTX 5090.
- The trained model runs on consumer GPUs using only standard dense operations, with no retraining or custom kernels required.
- Maintains strong no-reference perceptual quality at lower inference cost than compared diffusion baselines.
- Supports causal chunk-wise streaming while preserving reconstruction quality through the lightweight autoencoder.
Where Pith is reading between the lines
- The deterministic indexing approach could simplify efficient attention implementations in other high-resolution vision models that currently rely on masked or sparse operations.
- Real-time generative restoration at these speeds might enable live applications such as on-the-fly denoising or upscaling in consumer video pipelines.
- If chunk boundaries remain seamless across long streams, the causal protocol could extend to extended video sequences without additional boundary handling.
- The memory savings at 4K suggest the same design choices may help other generative tasks that hit similar resolution and latency walls.
Load-bearing premise
The deterministic indexing for window gathering produces attention outputs equivalent to or better than standard masked shifted-window attention without new artifacts.
What would settle it
A direct side-by-side run of SwiftVR and a masked shifted-window baseline on identical 1080p inputs that shows lower perceptual quality scores or visible artifacts in the mask-free version.
Figures




read the original abstract
Real-time video restoration (VR) for live streams requires high-resolution outputs under strict per-frame latency constraints. Existing one-step diffusion-based VR models remain difficult to deploy on consumer-grade GPUs due to two main bottlenecks: quadratic spatial attention at high resolutions and the latency-memory overhead of large video autoencoders. We present SwiftVR, a streaming one-step generative VR framework that reduces both bottlenecks under a causal chunk-wise protocol. For attention, mask-free shifted-window self-attention gathers each spatial window into a dense tensor via deterministic indexing, keeping all attention calls on the dense scaled dot-product attention path without masks, cyclic shifts, padding, or hardware-specific sparse kernels. Because SwiftVR uses only standard dense SDPA calls, the trained model transfers to consumer GPUs without retraining or custom kernels. For autoencoding, a lightweight Restoration-aware Autoencoder enables fast chunk-wise decoding while preserving reconstruction quality. On a single H100, SwiftVR sustains 31~FPS at 2560x1440 and 14~FPS at 3840x2160, whereas all compared diffusion-based VR baselines exceed the memory limit at 4K. On a consumer RTX~5090, SwiftVR reaches 26~FPS at 1920x1080. To our knowledge, SwiftVR is the first generative VR model to achieve real-time 1080p streaming on a consumer-grade GPU, while attaining strong no-reference perceptual quality with lower inference cost. Project is available at https://h-oliday.github.io/SwiftVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SwiftVR, a streaming one-step generative video restoration framework that addresses quadratic attention and autoencoder bottlenecks via mask-free shifted-window self-attention (implemented through deterministic indexing on dense SDPA) and a lightweight Restoration-aware Autoencoder under a causal chunk-wise protocol. It reports 31 FPS at 2560x1440 and 14 FPS at 3840x2160 on H100, plus 26 FPS at 1920x1080 on RTX 5090, claiming to be the first generative VR model to achieve real-time 1080p streaming on consumer GPUs with strong no-reference perceptual quality and lower inference cost.
Significance. If validated, the result would be significant for enabling practical deployment of generative video restoration in live-streaming scenarios on consumer hardware, as the reliance on standard dense SDPA calls supports portability without custom kernels or retraining. The public project link at https://h-oliday.github.io/SwiftVR is a strength that supports reproducibility of the reported FPS and quality numbers.
major comments (1)
- [§3.2] §3.2: The mask-free shifted-window self-attention is implemented via deterministic indexing to gather windows into dense tensors, but the section supplies neither a mathematical proof of equivalence to standard masked shifted-window attention (with cyclic shifts and relative-position biases) nor an ablation measuring perceptual metrics or attention-map differences when the indexing is replaced by a masked baseline. This equivalence is load-bearing for both the real-time performance numbers and the 'strong perceptual quality' claim.
minor comments (2)
- The abstract and experimental claims report specific FPS values (e.g., 26 FPS at 1080p) without error bars, number of runs, or dataset split details; adding these would strengthen the experimental design section.
- Notation for the Restoration-aware Autoencoder and chunk-wise protocol could be clarified with an explicit equation or diagram reference to avoid ambiguity in the causal streaming description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and will incorporate the requested clarifications in the revised version.
read point-by-point responses
-
Referee: [§3.2] §3.2: The mask-free shifted-window self-attention is implemented via deterministic indexing to gather windows into dense tensors, but the section supplies neither a mathematical proof of equivalence to standard masked shifted-window attention (with cyclic shifts and relative-position biases) nor an ablation measuring perceptual metrics or attention-map differences when the indexing is replaced by a masked baseline. This equivalence is load-bearing for both the real-time performance numbers and the 'strong perceptual quality' claim.
Authors: We acknowledge that Section 3.2 presents the deterministic indexing procedure but does not supply an explicit mathematical proof of equivalence or a dedicated ablation. The indexing computes per-window token offsets that exactly replicate the token groupings produced by a cyclic shift followed by non-overlapping window partitioning; the same relative-position bias matrix is then applied to each gathered window. Because the set of query-key pairs is identical to the standard masked formulation (with no extraneous tokens included), the attention output is mathematically equivalent while remaining on the dense SDPA path. Nevertheless, to strengthen the exposition we will add (i) a concise derivation in §3.2 showing that the indexing offsets are identical to the standard shift-and-partition steps and (ii) an ablation that reports no-reference perceptual metrics (NIQE, MUSIQ) together with attention-map cosine similarity on a held-out validation set when the mask-free path is replaced by an explicit masked baseline. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical performance claims rest on direct implementation and hardware measurements
full rationale
The paper describes a mask-free shifted-window attention implementation via deterministic indexing and a lightweight Restoration-aware Autoencoder, with real-time FPS and quality claims supported by reported measurements on H100 and RTX 5090 hardware. No equations, fitted parameters, or derivations are shown that reduce these outcomes to quantities defined inside the paper itself. No self-citations are invoked as load-bearing for the core technical claims, and the method is presented as an independent engineering change rather than a prediction derived from prior fitted results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deterministic indexing of spatial windows into dense tensors preserves the modeling capacity of masked or cyclically shifted attention.
Reference graph
Works this paper leans on
-
[1]
Taehv: Tiny autoencoder for hun- yuan video.https://github.com/madebyollin/ taehv, 2025
Ollin Boer Bohan. Taehv: Tiny autoencoder for hun- yuan video.https://github.com/madebyollin/ taehv, 2025. 4, 8
2025
-
[2]
Basicvsr: The search for essential compo- nents in video super-resolution and beyond
Kelvin CK Chan, Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. Basicvsr: The search for essential compo- nents in video super-resolution and beyond. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4947–4956, 2021. 2
2021
-
[3]
Basicvsr++: Improving video super- resolution with enhanced propagation and alignment
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. Basicvsr++: Improving video super- resolution with enhanced propagation and alignment. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5972–5981, 2022. 2
2022
-
[4]
Investigating tradeoffs in real-world video super-resolution
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. Investigating tradeoffs in real-world video super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5962–5971, 2022. 2, 3, 6, 7
2022
-
[5]
Dove: Efficient one- step diffusion model for real-world video super-resolution
Zheng Chen, Zichen Zou, Kewei Zhang, Xiongfei Su, Xin Yuan, Yong Guo, and Yulun Zhang. Dove: Efficient one- step diffusion model for real-world video super-resolution. arXiv preprint arXiv:2505.16239, 2025. 2, 3, 6, 7
-
[6]
Flashattention-2: Faster attention with better par- allelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better par- allelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024. 4, 2
2024
-
[7]
Jingwen He, Tianfan Xue, Dongyang Liu, Xinqi Lin, Peng Gao, Dahua Lin, Yu Qiao, Wanli Ouyang, and Ziwei Liu. Venhancer: Generative space-time enhancement for video generation.arXiv preprint arXiv:2407.07667, 2024. 2, 3
-
[8]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train- test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
xformers: A modular and hackable trans- former modelling library, 2022
Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, Daniel Haziza, Luca Wehrstedt, Jeremy Reizenstein, and Grigory Sizov. xformers: A modular and hackable trans- former modelling library, 2022. 4, 2
2022
-
[10]
Dis- trifusion: Distributed parallel inference for high-resolution diffusion models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Kai Li, and Song Han. Dis- trifusion: Distributed parallel inference for high-resolution diffusion models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 7183–7193, 2024. 3
2024
-
[11]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1833–1844,
-
[12]
Recurrent video restoration transformer with guided deformable attention
Jingyun Liang, Yuchen Fan, Xiaoyu Xiang, Rakesh Ranjan, Eddy Ilg, Simon Green, Jiezhang Cao, Kai Zhang, Radu Timofte, and Luc Van Gool. Recurrent video restoration transformer with guided deformable attention. InAdvances in Neural Information Processing Systems, 2022. 2
2022
-
[13]
Vrt: A video restoration transformer.IEEE Transactions on Image Processing, 33:2171–2182, 2024
Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, and Luc Van Gool. Vrt: A video restoration transformer.IEEE Transactions on Image Processing, 33:2171–2182, 2024. 2
2024
-
[14]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean Conference on Computer Vision, pages 430–448. Springer, 2024. 3
2024
-
[15]
Jingren Liu, Shuning Xu, Qirui Yang, Yun Wang, Xiangyu Chen, and Zhong Ji. Fape-ir: Frequency-aware planning and execution framework for all-in-one image restoration.arXiv preprint arXiv:2511.14099, 2025. 3
-
[16]
From reusing to forecasting: Accelerat- ing diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerat- ing diffusion models with taylorseers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15853–15863, 2025. 3
2025
-
[17]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 2, 4
2021
-
[20]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 5
2019
-
[21]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high- resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Zhengyao Lv, Chenyang Si, Junhao Song, Zhenyu Yang, Yu Qiao, Ziwei Liu, and Kwan-Yee K. Wong. Fastercache: Training-free video diffusion model acceleration with high quality. InInternational Conference on Learning Represen- tations, 2025. 3
2025
-
[23]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15762–15772, 2024. 3
2024
-
[24]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InProceedings of the Interna- tional Conference for High Performance Computing, Net- working, Storage and Analysis, 2020. 5
2020
-
[25]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. InAd- vances in Neural Information Processing Systems, 2024. 2
2024
-
[26]
Very deep convo- lutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition. InIn- ternational Conference on Learning Representations, 2015. 5 9
2015
-
[27]
Addsr: Accelerating diffusion- based blind super-resolution with adversarial diffusion dis- tillation.Pattern Recognition, page 113012, 2026
Ying Tai, Rui Xie, Chen Zhao, Kai Zhang, Zhenyu Zhang, Jun Zhou, and Jian Yang. Addsr: Accelerating diffusion- based blind super-resolution with adversarial diffusion dis- tillation.Pattern Recognition, page 113012, 2026. 3
2026
-
[28]
Detail-revealing deep video super-resolution
Xin Tao, Hongyun Gao, Renjie Liao, Jue Wang, and Jiaya Jia. Detail-revealing deep video super-resolution. InThe IEEE International Conference on Computer Vision (ICCV),
-
[29]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024. 3
2024
-
[31]
Seedvr: Seed- ing infinity in diffusion transformer towards generic video restoration
Jianyi Wang, Zhijie Lin, Meng Wei, Yang Zhao, Ceyuan Yang, Chen Change Loy, and Lu Jiang. Seedvr: Seed- ing infinity in diffusion transformer towards generic video restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2161– 2172, 2025. 2, 3, 5
2025
-
[32]
Seedvr2: One-step video restoration via diffusion adversarial post-training
Jianyi Wang, Shanchuan Lin, Zhijie Lin, Yuxi Ren, Meng Wei, Zongsheng Yue, Shangchen Zhou, Hao Chen, Yang Zhao, Ceyuan Yang, Xuefeng Xiao, Chen Change Loy, and Lu Jiang. Seedvr2: One-step video restoration via diffusion adversarial post-training. InICLR, 2026. 2, 3, 5, 6, 7
2026
-
[33]
Edvr: Video restoration with enhanced deformable convolutional networks
Xintao Wang, Kelvin CK Chan, Ke Yu, Chao Dong, and Chen Change Loy. Edvr: Video restoration with enhanced deformable convolutional networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2
-
[34]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
1905
-
[35]
Sinsr: diffusion-based image super- resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super- resolution in a single step. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25796–25805, 2024. 3
2024
-
[36]
Uformer: A gen- eral u-shaped transformer for image restoration
Zhendong Wang, Xiaodong Cun, Jianmin Bao, Wengang Zhou, Jianzhuang Liu, and Houqiang Li. Uformer: A gen- eral u-shaped transformer for image restoration. InCVPR, pages 17683–17693, 2022. 3
2022
-
[37]
One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024. 3
2024
-
[38]
Seesr: Towards semantics- aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics- aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25456–25467, 2024. 3
2024
-
[39]
Star: Spatial-temporal augmentation with text- to-video models for real-world video super-resolution
Rui Xie, Yinhong Liu, Penghao Zhou, Chen Zhao, Jun Zhou, Kai Zhang, Zhenyu Zhang, Jian Yang, Zhenheng Yang, and Ying Tai. Star: Spatial-temporal augmentation with text- to-video models for real-world video super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17108–17118, 2025. 2
2025
-
[40]
Ultravideo: High-quality uhd video dataset with comprehensive captions
Zhucun Xue, Jiangning Zhang, Teng Hu, Haoyang He, Yinan Chen, Yuxuan Cai, Yabiao Wang, Chengjie Wang, Yong Liu, Xiangtai Li, and Dacheng Tao. Ultravideo: High-quality uhd video dataset with comprehensive captions. InAdvances in Neural Information Processing Systems, 2025. Datasets and Benchmarks Track. 6
2025
-
[41]
Real- world video super-resolution: A benchmark dataset and a decomposition based learning scheme
Xi Yang, Wangmeng Xiang, Hui Zeng, and Lei Zhang. Real- world video super-resolution: A benchmark dataset and a decomposition based learning scheme. InProceedings of the IEEE/CVF international conference on computer vision, pages 4781–4790, 2021. 2, 3
2021
-
[42]
Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations
Peng Yi, Zhongyuan Wang, Kui Jiang, Junjun Jiang, and Ji- ayi Ma. Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations. In IEEE International Conference on Computer Vision (ICCV), pages 3106–3115, 2019. 6
2019
-
[43]
Im- proved distribution matching distillation for fast image syn- thesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Micha ¨el Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Im- proved distribution matching distillation for fast image syn- thesis.Advances in neural information processing systems, 37:47455–47487, 2024. 3
2024
-
[44]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6613–6623, 2024. 3
2024
-
[45]
From slow bidirectional to fast autoregressive video diffusion mod- els
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion mod- els. InCVPR, 2025. 3
2025
-
[46]
Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25669–25680, 2024. 3
2024
-
[47]
Sageattention: Accurate 8-bit attention for plug-and- play inference acceleration
Jintao Zhang, Jia Wei, Pengle Zhang, Jun Zhu, and Jianfei Chen. Sageattention: Accurate 8-bit attention for plug-and- play inference acceleration. InInternational Conference on Learning Representations (ICLR), 2025. 4, 2
2025
-
[48]
Jintao Zhang, Kai Jiang, Chendong Xiang, Weiqi Feng, Yuezhou Hu, Haocheng Xi, Jianfei Chen, and Jun Zhu. Spargeattention2: Trainable sparse attention via hybrid top- k+ top-p masking and distillation fine-tuning.arXiv preprint arXiv:2602.13515, 2026. 3
-
[49]
Vsa: Faster video diffusion with trainable sparse attention.arXiv preprint arXiv:2505.13389, 2025
Peiyuan Zhang, Yongqi Chen, Haofeng Huang, Will Lin, Zhengzhong Liu, Ion Stoica, Eric Xing, and Hao Zhang. Vsa: Faster video diffusion with trainable sparse attention. arXiv preprint arXiv:2505.13389, 2025. 3
-
[50]
Realviformer: Investigating attention for real-world video super-resolution
Yuehan Zhang and Angela Yao. Realviformer: Investigating attention for real-world video super-resolution. InEuropean 10 conference on computer vision, pages 412–428. Springer,
-
[51]
Upscale-A-video: Temporal- consistent diffusion model for real-world video super- resolution.IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2535–2545, 2024
Shangchen Zhou, Peiqing Yang, Jianyi Wang, Yihang Luo, and Chen Change Loy. Upscale-A-video: Temporal- consistent diffusion model for real-world video super- resolution.IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2535–2545, 2024. 2, 6
2024
-
[52]
Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, and Tianfan Xue. Flashvsr: Towards real- time diffusion-based streaming video super-resolution.arXiv preprint arXiv:2510.12747, 2025. 2, 3, 6, 7, 8
-
[53]
Accelerating diffusion transformers with token- wise feature caching
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Lin- feng Zhang. Accelerating diffusion transformers with token- wise feature caching. InInternational Conference on Learn- ing Representations, 2025. 3 11 SwiftVR: Real-Time One-Step Generative Video Restoration Supplementary Material This supplementary material provides details omitted from the main pap...
2025
-
[54]
This section completes the specifica- tion by describing boundary-clamped gathering and its re- dundant attention cost
MFSW A Design and Analysis The main paper introduces three components of MFSW A: spatial-only partitioning with full temporal visibility, dense- block pre-gathering, and half-window shifting with priority- coherent scattering. This section completes the specifica- tion by describing boundary-clamped gathering and its re- dundant attention cost. 6.1. Bound...
-
[55]
Evaluation and Deployment This section specifies the unified streaming protocol, addi- tional qualitative results, extended efficiency comparison at 2560×1440, and the cross-backend deployment results. 1 7.1. Unified Streaming Evaluation Protocol Table 1 requires a like-for-like streaming evaluation. Be- cause the baselines use different temporal strides ...
-
[56]
At3840×2160, it reaches13.84FPS with60.91GB peak memory on an H100
Limitations and Future Work Limitations.SwiftVR does not yet deliver real-time gen- erative 4K restoration on consumer GPUs. At3840×2160, it reaches13.84FPS with60.91GB peak memory on an H100. This fits a server GPU but exceeds consumer-GPU memory and remains below24FPS. Real-time 4K restora- tion on consumer GPUs remains future work. Future work.SwiftVR ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.