Pixel-Level Residual Diffusion Transformer: Scalable 3D CT Volume Generation
Pith reviewed 2026-06-26 18:29 UTC · model grok-4.3
The pith
PRDiT generates high-resolution 3D CT volumes directly at voxel level by splitting low-frequency structures into a local MLP denoiser and high-frequency residuals into a global transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
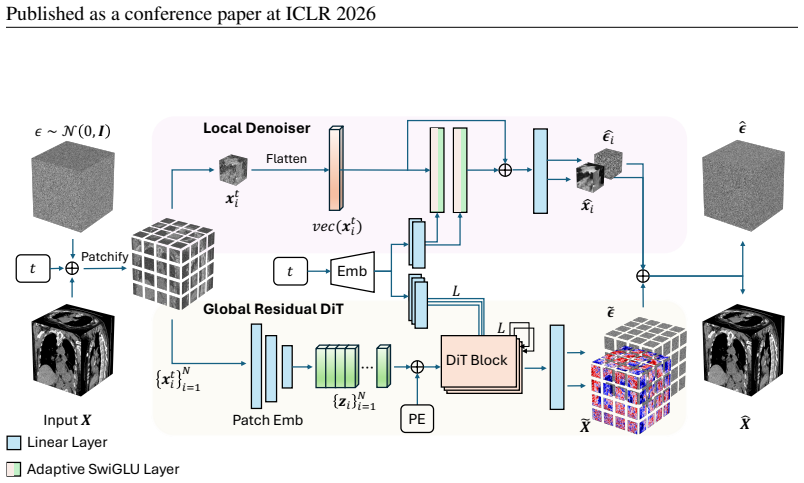
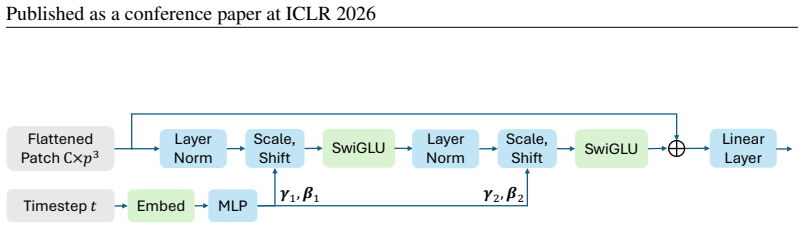
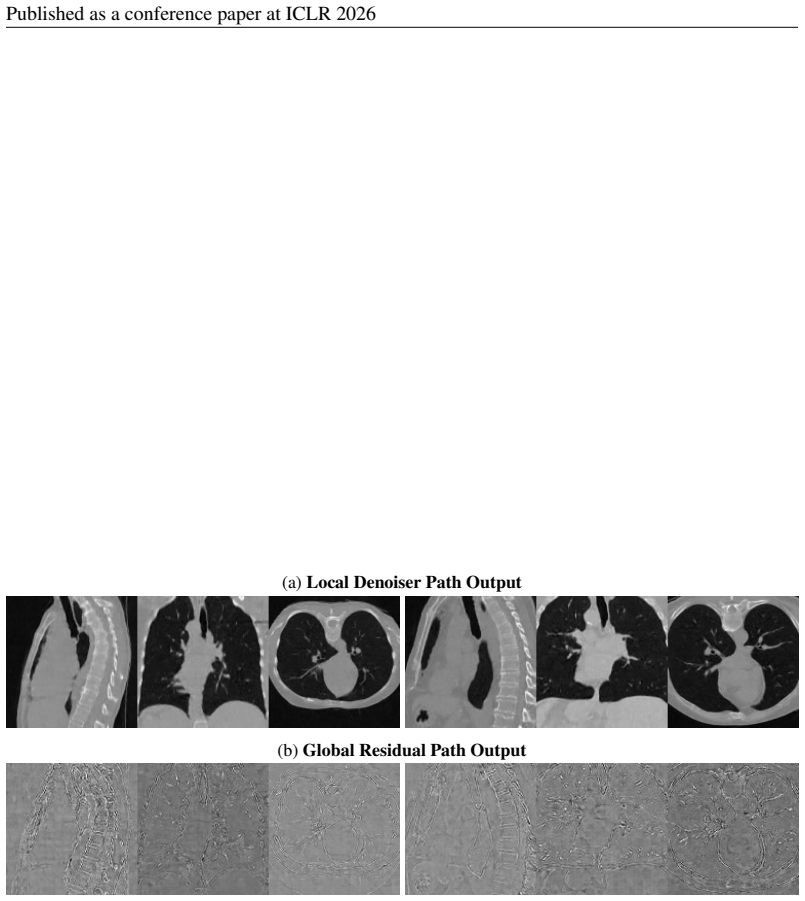
PRDiT synthesizes high-quality 3D CT volumes directly at voxel-level through a two-stage coarse-to-fine architecture: an MLP-based blind estimator on overlapping patches separates low-frequency structures, and a global residual diffusion transformer with memory-efficient attention models and refines high-frequency residuals across entire volumes. This approach simplifies optimization, improves training stability, and avoids autoencoder bottlenecks while preserving subtle structures.
What carries the argument
Two-stage Pixel-Level Residual Diffusion Transformer (PRDiT) architecture that uses a local MLP denoiser for low-frequency content and a global residual transformer for high-frequency residuals.
If this is right
- High-resolution 3D volumes can be generated without the information bottleneck of an autoencoder.
- Training stability improves because the local stage handles coarse structures before the global stage refines details.
- Subtle anatomical features remain intact because the model operates at native voxel resolution.
- The framework scales to larger volumes through memory-efficient attention in the residual stage.
Where Pith is reading between the lines
- The patch-based local stage could be adapted to other 3D modalities such as MRI or PET where frequency separation is useful.
- If the residual modeling generalizes, similar two-stage designs might reduce compute for 3D generative tasks outside medicine.
- Direct voxel-level output removes the need for a separate decoder, which could simplify deployment pipelines.
Load-bearing premise
The separation of low-frequency content into local MLP patches and high-frequency residuals into a global transformer actually preserves all necessary anatomical detail without information loss.
What would settle it
Running the same evaluation protocol on LIDC-IDRI or RAD-ChestCT and finding that PRDiT does not produce lower 3D FID, MMD, or Wasserstein distances than HA-GAN, 3D LDM, or WDM-3D.
Figures

read the original abstract
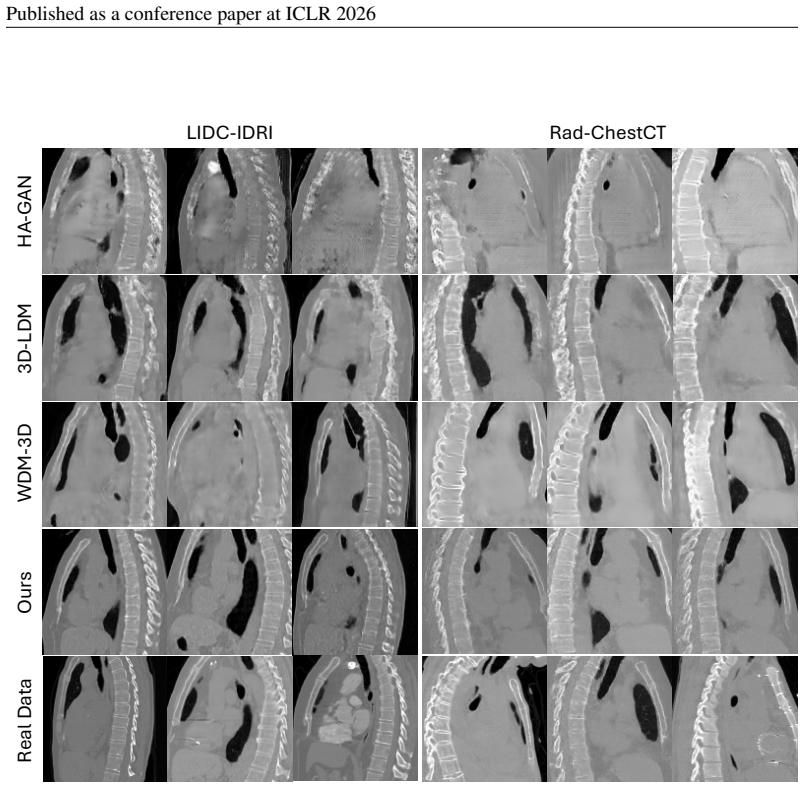
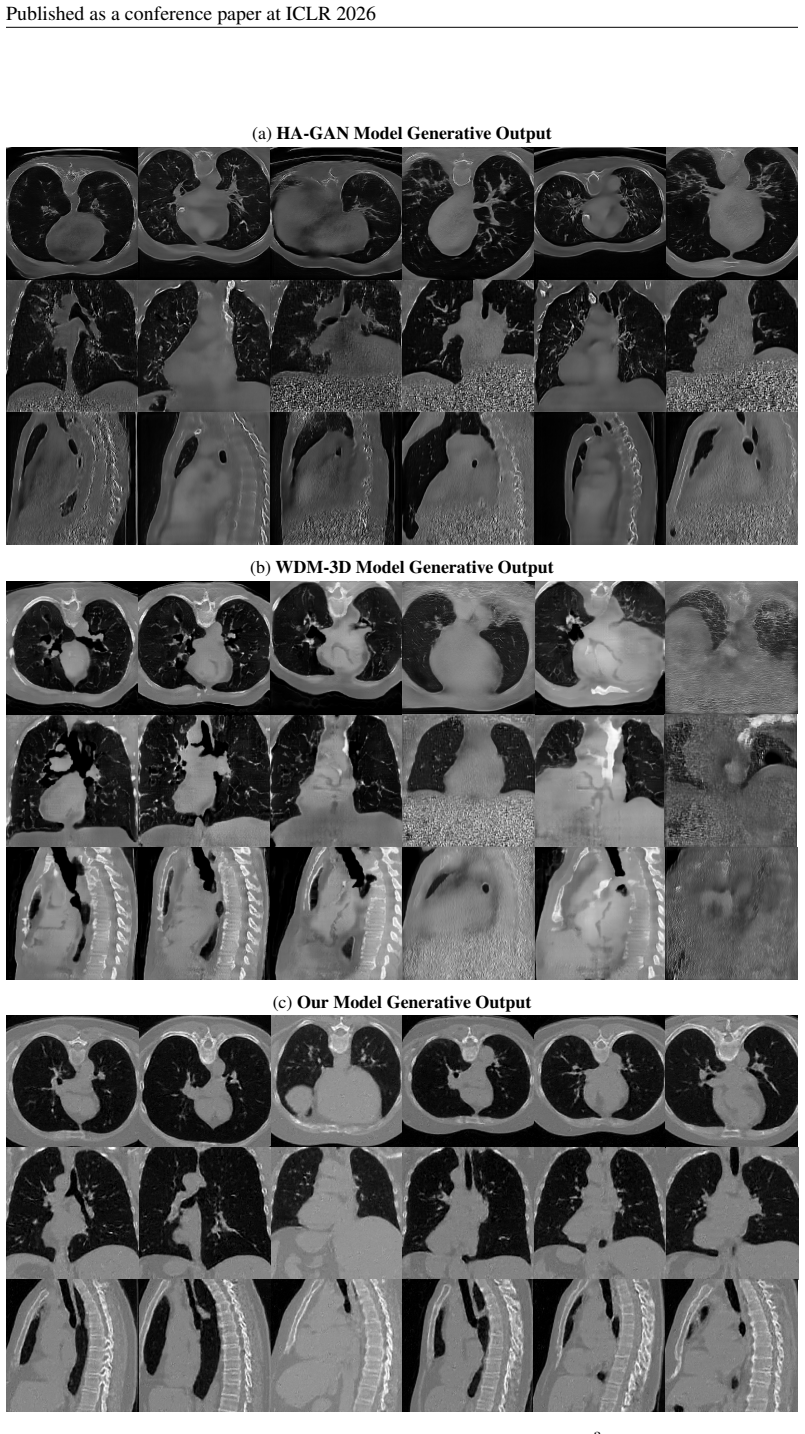
Generating high-resolution 3D CT volumes with fine details remains challenging due to substantial computational demands and optimization difficulties inherent to existing generative models. In this paper, we propose the Pixel-Level Residual Diffusion Transformer (PRDiT), a scalable generative framework that synthesizes high-quality 3D medical volumes directly at voxel-level. PRDiT introduces a two-stage training architecture comprising 1) a local denoiser in the form of an MLP-based blind estimator operating on overlapping 3D patches to separate low-frequency structures efficiently, and 2) a global residual diffusion transformer employing memory-efficient attention to model and refine high-frequency residuals across entire volumes. This coarse-to-fine modeling strategy simplifies optimization, enhances training stability, and effectively preserves subtle structures without the limitations of an autoencoder bottleneck. Extensive experiments conducted on the LIDC-IDRI and RAD-ChestCT datasets demonstrate that PRDiT consistently outperforms state-of-the-art models, such as HA-GAN, 3D LDM and WDM-3D, achieving significantly lower 3D FID, MMD and Wasserstein distance scores.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Pixel-Level Residual Diffusion Transformer (PRDiT), a two-stage generative model for direct voxel-level synthesis of high-resolution 3D CT volumes. Stage 1 employs an MLP-based local denoiser on overlapping patches to capture low-frequency structures; stage 2 uses a global residual diffusion transformer with memory-efficient attention to model high-frequency residuals. Experiments on LIDC-IDRI and RAD-ChestCT are said to show consistent outperformance over HA-GAN, 3D LDM, and WDM-3D on 3D FID, MMD, and Wasserstein distance.
Significance. If the reported empirical gains prove robust and reproducible, the coarse-to-fine residual strategy could offer a practical route to high-resolution 3D medical volume generation that sidesteps autoencoder bottlenecks, with potential utility in data augmentation and simulation tasks.
major comments (2)
- [Abstract] Abstract and Experiments section: the central claim that PRDiT 'consistently outperforms' the listed baselines with 'significantly lower' 3D FID, MMD, and Wasserstein scores is stated without any numerical values, confidence intervals, table references, or dataset-split details, rendering the primary empirical result unverifiable from the manuscript text.
- [Experiments] §4 (Experiments): no implementation details, hyper-parameter settings, training schedules, or hardware requirements are supplied, which are load-bearing for assessing whether the two-stage architecture indeed 'simplifies optimization' and 'enhances stability' as asserted.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. We agree that the current manuscript text does not make the primary empirical claims immediately verifiable and lacks the implementation details needed to evaluate the claimed benefits of the two-stage design. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the central claim that PRDiT 'consistently outperforms' the listed baselines with 'significantly lower' 3D FID, MMD, and Wasserstein scores is stated without any numerical values, confidence intervals, table references, or dataset-split details, rendering the primary empirical result unverifiable from the manuscript text.
Authors: We agree that the abstract and the opening of §4 should contain explicit numerical results rather than qualitative statements alone. In the revision we will insert the key 3D FID, MMD and Wasserstein values (with standard deviations) achieved on both LIDC-IDRI and RAD-ChestCT, reference the corresponding tables, and state the train/validation/test splits used. This will allow readers to verify the “consistently outperforms” claim directly from the text. revision: yes
-
Referee: [Experiments] §4 (Experiments): no implementation details, hyper-parameter settings, training schedules, or hardware requirements are supplied, which are load-bearing for assessing whether the two-stage architecture indeed 'simplifies optimization' and 'enhances stability' as asserted.
Authors: We acknowledge that the absence of these details prevents independent assessment of the optimization and stability claims. The revised §4 will include a new subsection listing all hyper-parameters (learning rates, patch sizes, diffusion steps, attention configurations), the exact training schedule (epochs, batch sizes, optimizer), and the hardware (GPU model and memory) used for each stage. We will also report wall-clock training times to support the stability argument. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper proposes a two-stage PRDiT architecture (local MLP denoiser + global residual transformer) and validates it via direct empirical comparison against prior external models (HA-GAN, 3D LDM, WDM-3D) on public datasets (LIDC-IDRI, RAD-ChestCT) using standard metrics (3D FID, MMD, Wasserstein). No load-bearing derivation, fitted parameter renamed as prediction, self-citation chain, or uniqueness theorem is invoked; the central claims are falsifiable performance numbers on held-out data and do not reduce to the model's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Med3d: Transfer learning for 3d medical image analysis
Sihong Chen, Kai Ma, and Yefeng Zheng. Med3d: Transfer learning for 3d medical image analysis. arXiv preprint arXiv:1904.00625,
Pith/arXiv arXiv 1904
-
[2]
Paul Friedrich, Julia Wolleb, Florentin Bieder, Alicia Durrer, and Philippe C Cattin
URLhttps://doi.org/ 10.5281/zenodo.6406114. Paul Friedrich, Julia Wolleb, Florentin Bieder, Alicia Durrer, and Philippe C Cattin. Wdm: 3d wavelet diffusion models for high-resolution medical image synthesis. InMICCAI Workshop on Deep Generative Models, pp. 11–21. Springer,
-
[3]
Generation of 3d brain mri using auto-encoding generative adversarial networks
11 Published as a conference paper at ICLR 2026 Gihyun Kwon, Chihye Han, and Dae-shik Kim. Generation of 3d brain mri using auto-encoding generative adversarial networks. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 118–126. Springer,
2026
-
[4]
Zhenkai Zhang, Krista A Ehinger, and Tom Drummond. Improving denoising diffusion models via simultaneous estimation of image and noise.arXiv preprint arXiv:2310.17167,
-
[5]
We used the LLM to refine language and improve clarity across the Introduction, Related Work and Conclusion sections
12 Published as a conference paper at ICLR 2026 A APPENDIX A.1 LLM USAGE In this paper, Large Language Models (LLMs) were utilized as a general-purpose assist tool to aid and polish the writing process. We used the LLM to refine language and improve clarity across the Introduction, Related Work and Conclusion sections. A.2 HALLUCINATIONRISKS ANDPOTENTIALM...
2026
-
[6]
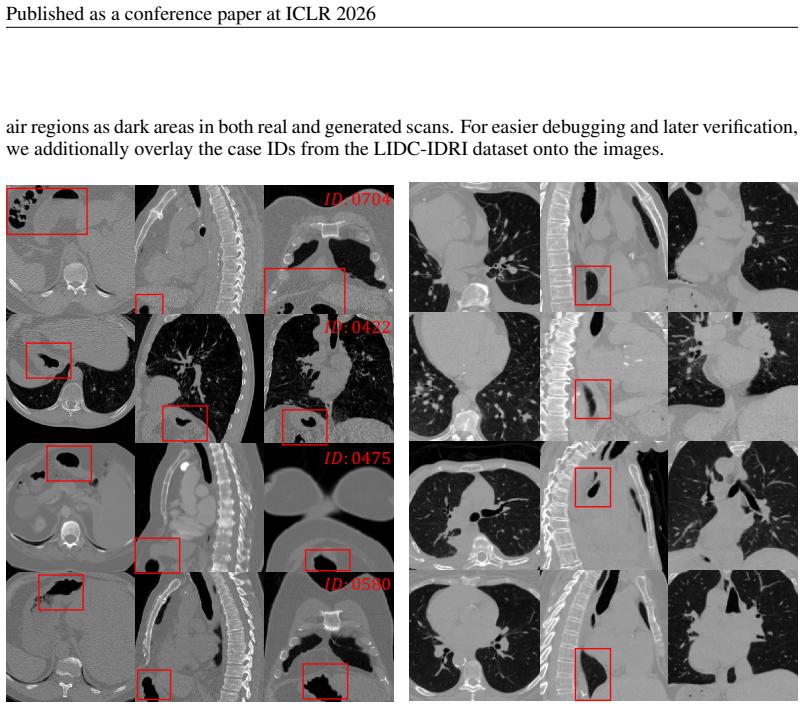
For easier debugging and later verification, we additionally overlay the case IDs from the LIDC-IDRI dataset onto the images
In addition, following standard practice in prior works, our pre-processing clamps HU values to a fixed window, which further accentuates such 13 Published as a conference paper at ICLR 2026 air regions as dark areas in both real and generated scans. For easier debugging and later verification, we additionally overlay the case IDs from the LIDC-IDRI datas...
2026
-
[7]
, T} and compute vt i = cos( t T π 2 )v i + sin( t T π 2 )ϵ i,ϵ i ∼ N(0, I)
To follow the forward diffusion process (Zhang et al., 2023), we sample a timestept∈ {1, . . . , T} and compute vt i = cos( t T π 2 )v i + sin( t T π 2 )ϵ i,ϵ i ∼ N(0, I). Given a diffusion timestept, we first compute a shared base embedding c= TimeEmbed(t)∈R h. 14 Published as a conference paper at ICLR 2026 We then projectcinto a stage-specific time emb...
2023
-
[8]
The conventional ancestral ’hot’ sampler performs a single stochastic update fromxt tox t−1 using only the predicted noiseϵ
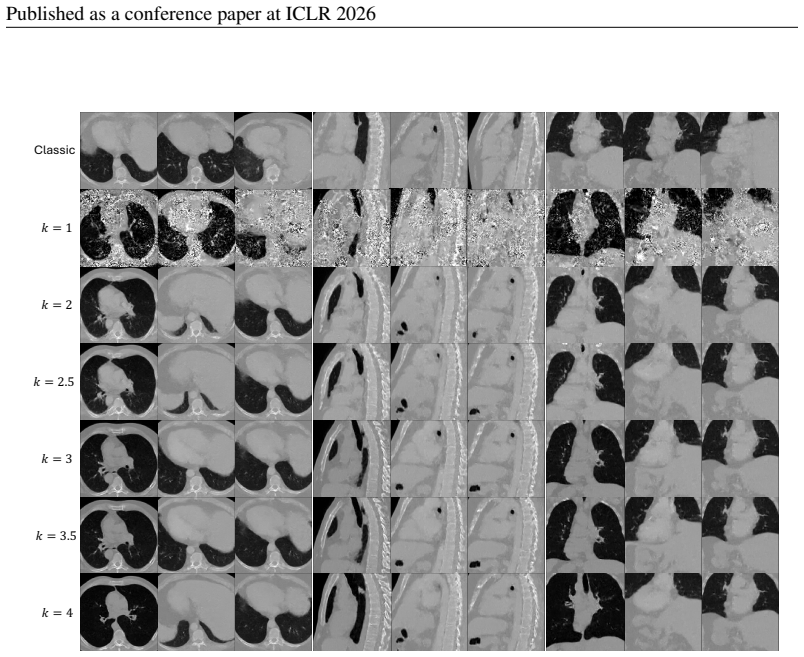
and lets us inject a controlled amount of extra stochasticity per step, which we show empirically improves FID/MMD over both deterministic sampling (k= 1, Table 4 (b), main paper) as well as previous methods (following). The conventional ancestral ’hot’ sampler performs a single stochastic update fromxt tox t−1 using only the predicted noiseϵ. Our sampler...
2026
-
[9]
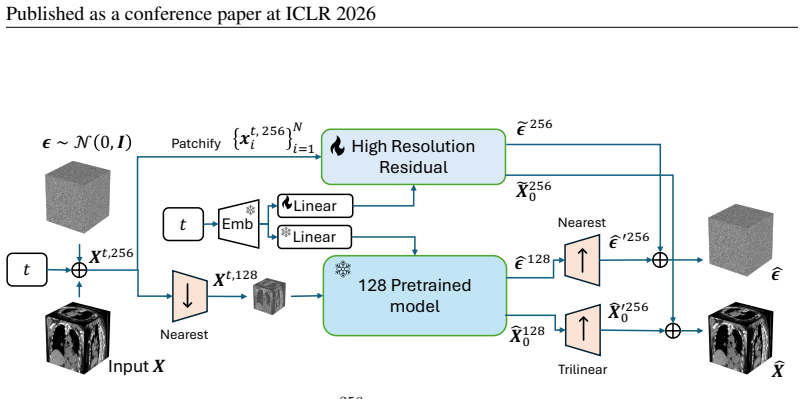
In this section, we additionally provide insights on the difference in image quality between our efficient high-resolution variant and expensive from-scratch training of PRDiT directly on higher-resolution images. Results are provided in Table 7 and demon- strate that while training from scratch does indeed lead to slightly improved performance across FID...
2026
-
[10]
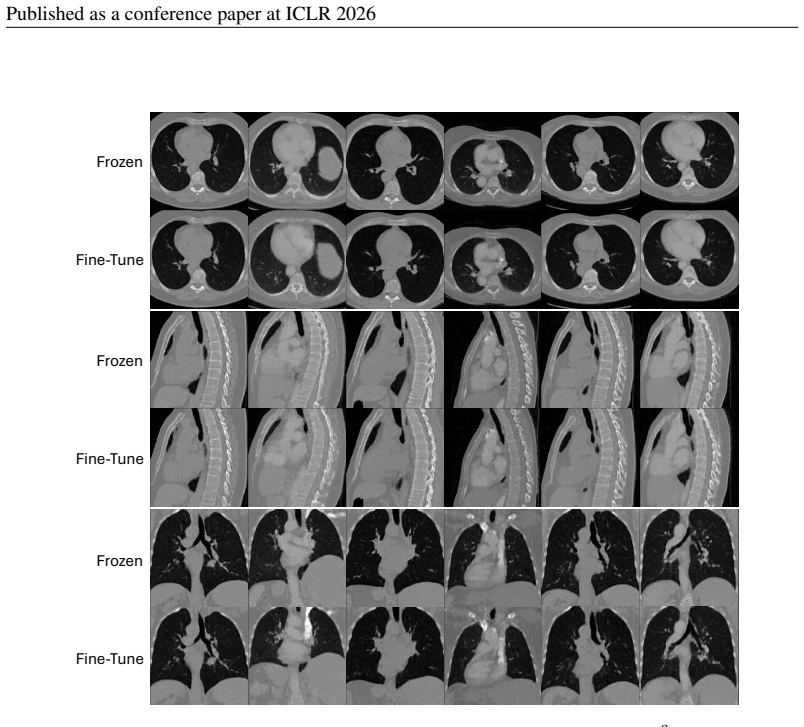
Method FID↓MMD↓Training Cost PRDiT scratch 128 2.04 0.1853 80 GPUh PRDiT64 ↑128 2.89 0.1893 12 GPUh In our high-resolution PRDiT↑ 256 model experiments, we freeze the entire low-resolution back- bone, which includes both Local Denoiser and the Global Residual DiT modules, and only train a lightweight high-resolution refinement module. We made this choice ...
2026
-
[11]
In addition, we use the FlashAttention-v2 included with Pytorch version 2.2
Model FID↓MMD↓ Frozen128 3 2.280 0.1370 Fine-tuned128 3 1.702 0.1315 A.9 MODELCONFIGURATIONS IN DETAIL In this section, we describe the network architecture, training setup and evaluation protocol to enable full reproducibility. In addition, we use the FlashAttention-v2 included with Pytorch version 2.2. 19 Published as a conference paper at ICLR 2026 Fro...
2026
-
[12]
Parameter Value Input Channels (Cin) 1 Patch Size (P×P×P)12×12×12 Stride 8 Padding 2 MLP Structure Two-layer SwiGLU Hidden SizeC in ·P 3 = 1·12 3 = 1728 MLP Ratio (Rmlp) 1.0 Output Channels (Cout) 2 Normalization LayerNorm Conditioning AdaLN modulation with TimeEmbedding Activation SwiGLU Dropout 0.0 Weight Initialization Zero-initialized for AdaLN and fi...
2026
-
[13]
A.9.2 TRAININGSETUP We provide the details of how to train the methods
All models share the same pretrainedLocalDenoisermodel from Stage 1 training. A.9.2 TRAININGSETUP We provide the details of how to train the methods. •Optimization Function: AdamW withβ 1 = 0.9,β 2 = 0.999, and weight decay 0.0. The objective is mean squared error (MSE) loss. •Learning Rate: –Stage 1 (LocalDenoiser):10 −4. –Stage 2 (GlobalResidual DiT): *...
2024
-
[14]
For every model pair(i, j), we reportµ±σof the log ratio between the WGAN critic scores for samples from modeliand modelj(averaged over 4 evaluations)
22 Published as a conference paper at ICLR 2026 HA- GAN 3D- LDM WDM- 3D PRDiT- 4L PRDiT- 8L PRDiT- 12L HA-GAN 0 (±0) -0.302 (±0.002) -1.950 (±0.055) -0.969 (±0.036) -1.199 (±0.095) -1.433 (±0.051) 3D-LDM 0.302 (±0.002) 0 (±0) -1.602 (±0.069) -0.753 (±0.043) -0.963 (±0.031) -1.045 (±0.068) WDM-3D 1.950 (±0.055) 1.602 (±0.069) 0 (±0) -0.142 (±0.055) -0.208 ...
2026
-
[15]
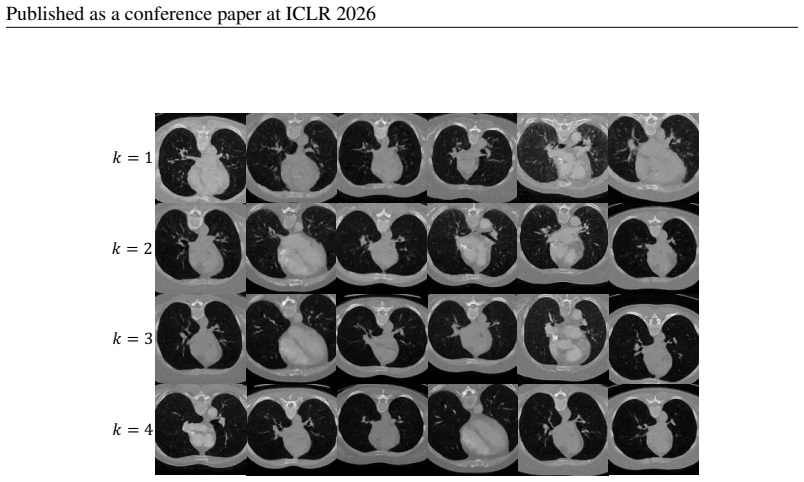
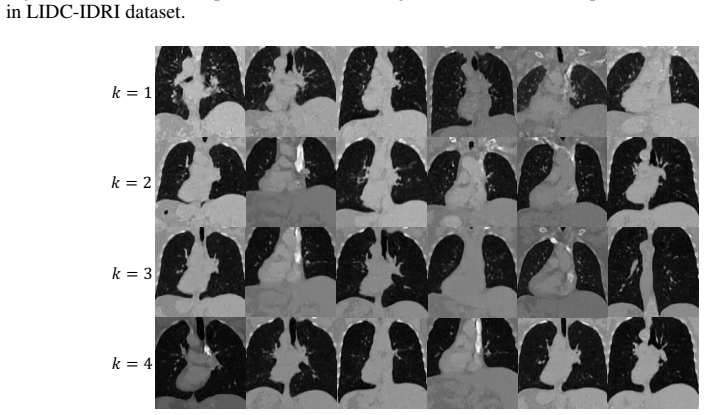
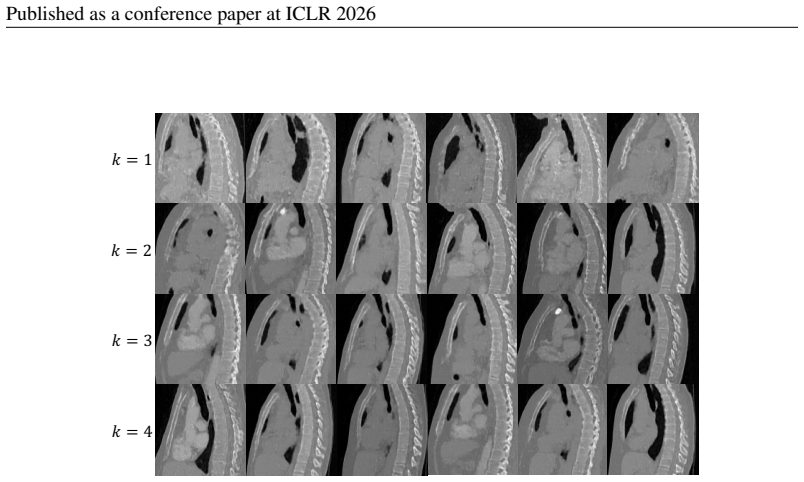
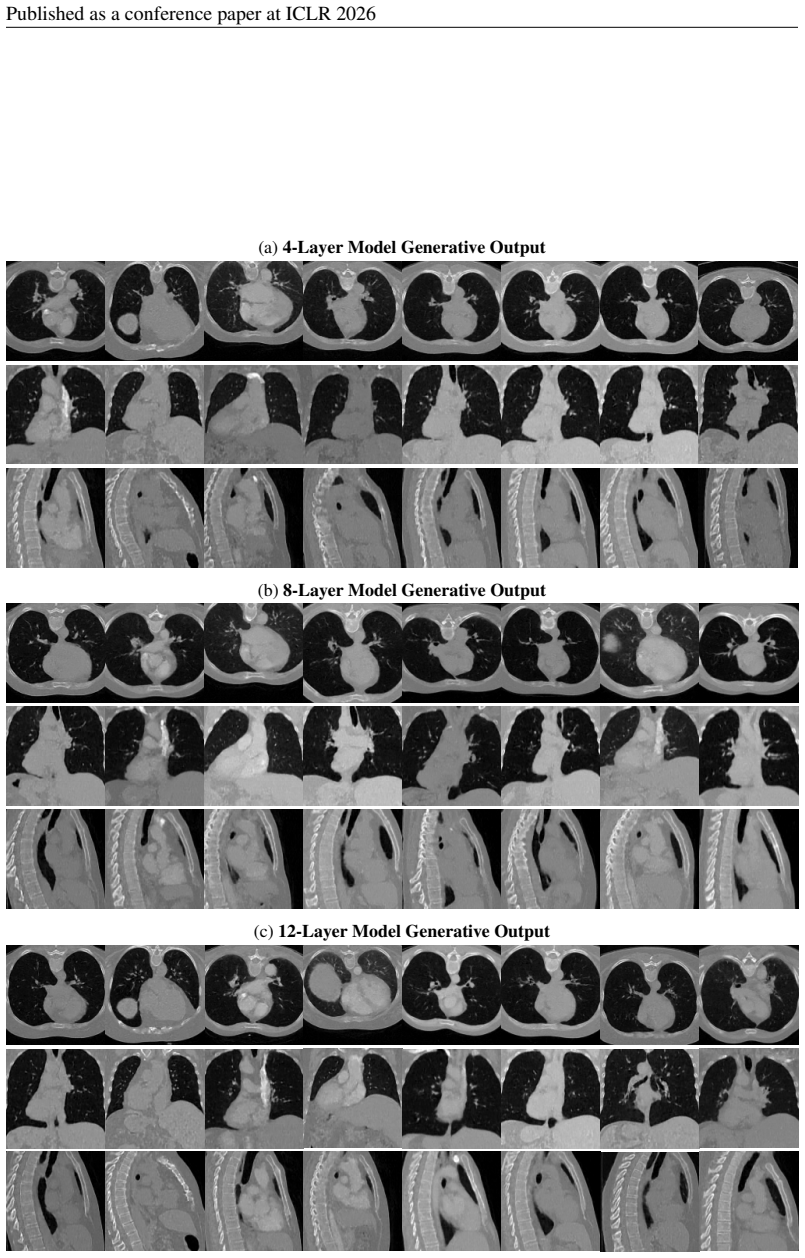
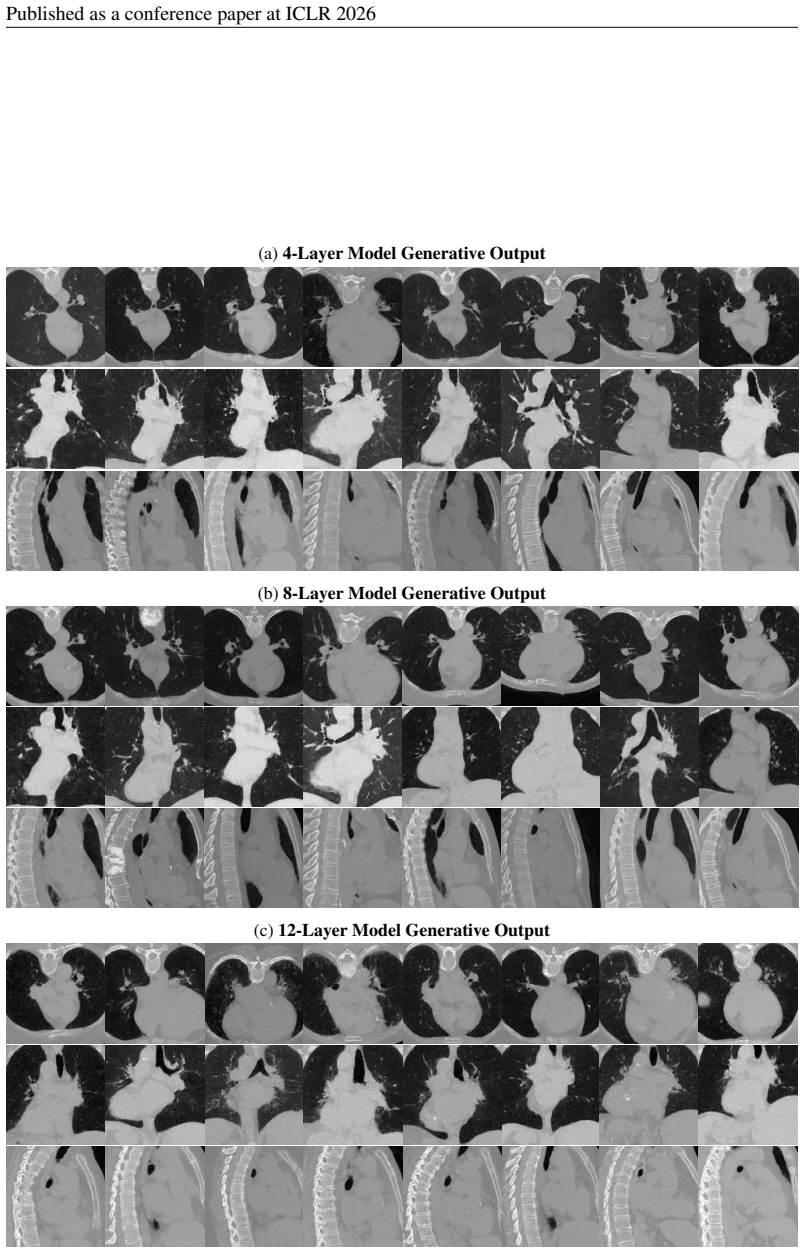
23 Published as a conference paper at ICLR 2026 (a)4-Layer Model Generative Output (b)8-Layer Model Generative Output (c)12-Layer Model Generative Output Figure 12: Extended qualitative results for different model within LIDC-IDRI dataset. 24 Published as a conference paper at ICLR 2026 (a)4-Layer Model Generative Output (b)8-Layer Model Generative Output...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.