"Skill issues'': data-centric optimization of lakehouse agents
Pith reviewed 2026-06-28 17:24 UTC · model grok-4.3
The pith
A data-centric pipeline optimizes skills for branching lakehouse agents and raises accuracy by 31.9 percent on 25 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
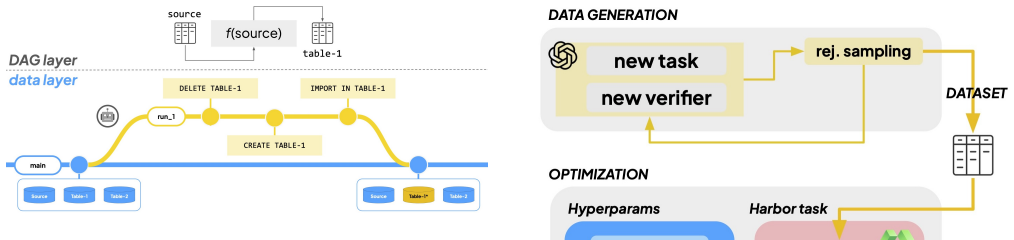
The central claim is that a branching lakehouse converts data-agent evaluation into a state-verification problem. This enables a data-centric optimization pipeline that generates task-verifier pairs, executes candidate skills inside isolated sandboxes, and scores trajectories with both trace-level signals and programmatic checks over lakehouse state. When applied to 25 tasks the optimized skills improve accuracy by 31.9 percent. The results indicate that write-path data workflows provide a useful substrate for optimizing agent skills beyond read-only tasks.
What carries the argument
The data-centric optimization pipeline that generates task-verifier pairs, executes candidate skills in isolated sandboxes, and scores trajectories using trace-level signals and programmatic checks over lakehouse state.
If this is right
- Agent evaluation on a branching lakehouse becomes a state-verification problem instead of output matching.
- Optimized skills raise accuracy by 31.9 percent on the 25 evaluated tasks.
- Write-path data workflows supply a substrate for skill optimization that read-only tasks lack.
Where Pith is reading between the lines
- The same pipeline could be tested on other data systems that expose branching or commit primitives to agents.
- Skill optimization might allow smaller models to reach comparable performance when the environment files are tuned.
- Extending the sandbox checks to include merge-conflict detection or branch-history queries would test the approach on more complex workflows.
Load-bearing premise
The 25 tasks and generated task-verifier pairs are representative of real data workflows and sandbox execution faithfully measures production lakehouse behavior without post-hoc selection effects.
What would settle it
Run the optimized skills on a larger collection of tasks drawn from actual production lakehouse environments and measure whether the accuracy gain holds.
Figures




read the original abstract
Coding agents are becoming users of data infrastructure, but their success depends not only on model quality: it also depends on the skills and environment files that teach agents how to use a system. We study how to optimize these artifacts for agents operating on a branching lakehouse, Bauplan. In our setting, headless APIs and Git-like data primitives expose data workflows through code, branches, commits, and merges. Our central observation is that a branching lakehouse turns data-agent evaluation from an output-matching problem into a state-verification problem: agent-generated pipeline code induces concrete, inspectable lakehouse changes. We present a data-centric optimization pipeline that generates task-verifier pairs, executes candidate skills in isolated sandboxes, and scores trajectories using both trace-level signals and programmatic checks over lakehouse state. In a preliminary evaluation on 25 tasks, optimized skills improve accuracy by 31.9%. These results suggest that write-path data workflows provide a useful substrate for optimizing agent skills beyond read-only tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a data-centric optimization pipeline for agent 'skills' in a branching lakehouse (Bauplan) that exposes data workflows via headless APIs and Git-like primitives. The central observation is that branching lakehouses convert agent evaluation from output-matching to state-verification. The pipeline generates task-verifier pairs, executes candidate skills in isolated sandboxes, and scores trajectories using trace-level signals plus programmatic checks on lakehouse state. A preliminary evaluation on 25 tasks reports that optimized skills improve accuracy by 31.9%, suggesting write-path data workflows as a useful substrate for skill optimization beyond read-only tasks.
Significance. If the empirical result can be substantiated with independent tasks, proper controls, and production-fidelity sandboxes, the work would offer a concrete method for improving coding-agent performance on data infrastructure by optimizing skills and environments rather than models alone. It identifies a novel evaluation substrate (branching lakehouse state changes) that could generalize to other write-heavy agent settings. The preliminary status and absence of baseline comparisons currently constrain the significance to a proof-of-concept level.
major comments (2)
- [Abstract] Abstract: the headline claim of a 31.9% accuracy improvement on 25 tasks is presented without baselines, error bars, control conditions, or any description of how the optimization was performed; this directly undermines assessment of the central empirical result.
- [Evaluation] Evaluation section (implied by the preliminary results paragraph): the 25 task-verifier pairs are generated by the pipeline itself, yet no evidence is supplied that they are drawn from an independent distribution of real lakehouse workloads or that sandbox state checks replicate production behavior (concurrency, scale, schema evolution); this selection/measurement bias risk is load-bearing for the generalization claim.
minor comments (2)
- [Introduction] The manuscript would benefit from an explicit early definition of 'skills' and 'environment files' and how they differ from standard prompt engineering or tool-use setups.
- [Pipeline description] Figure or table captions describing the optimization pipeline should include the exact scoring formula that combines trace signals and lakehouse state checks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the preliminary nature of our evaluation. We address each major comment below and will revise the manuscript accordingly to better contextualize the results and limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a 31.9% accuracy improvement on 25 tasks is presented without baselines, error bars, control conditions, or any description of how the optimization was performed; this directly undermines assessment of the central empirical result.
Authors: We agree the abstract is too terse. The 31.9% figure reflects the lift from initial to optimized skills on the identical 25 task-verifier pairs generated and scored by the pipeline; no external baselines or error bars are reported because the study is framed as a proof-of-concept. We will revise the abstract to (1) briefly describe the optimization loop (task generation, sandbox execution, state-verification scoring), (2) state that the comparison is against unoptimized skills on the same tasks, and (3) qualify the result as preliminary. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the preliminary results paragraph): the 25 task-verifier pairs are generated by the pipeline itself, yet no evidence is supplied that they are drawn from an independent distribution of real lakehouse workloads or that sandbox state checks replicate production behavior (concurrency, scale, schema evolution); this selection/measurement bias risk is load-bearing for the generalization claim.
Authors: The tasks are indeed produced by the same pipeline under study, and the sandboxes are isolated rather than production-scale. The manuscript already labels the evaluation “preliminary” and does not assert generalization. We will expand the evaluation section to (a) describe the task-generation procedure, (b) explicitly note the risk of distribution shift and lack of independent real-world workloads, and (c) list the sandbox limitations (no concurrency, scale, or schema-evolution testing) as open constraints on the current claims. revision: yes
Circularity Check
No significant circularity; empirical result with no derivation chain
full rationale
The paper reports an empirical accuracy improvement of 31.9% on 25 tasks via a pipeline that generates task-verifier pairs and evaluates skills in sandboxes. No equations, derivations, or mathematical reductions are present in the provided text. The central claim does not reduce to its inputs by construction, nor does it rely on self-citations for uniqueness, ansatzes, or load-bearing premises. The evaluation is presented as preliminary without any self-definitional or fitted-input patterns that would force the result. This is a standard empirical study whose validity rests on external questions of task representativeness rather than internal circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alex Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2025. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. InFirst Workshop on Foun...
2025
-
[2]
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. 2026. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766(2026)
Pith/arXiv arXiv 2026
-
[3]
Anthropic. 2025. The Complete Guide to Building Skills for Claude. https://resources.anthropic.com/hubfs/The-Complete-Guide-to-Building- Skill-for-Claude.pdf
2025
-
[4]
Apache. 2024. Iceberg. https://github.com/apache/iceberg
2024
-
[5]
Chris L Baker, Rebecca Saxe, and Joshua B Tenenbaum. 2009. Action understand- ing as inverse planning.Cognition113, 3 (2009), 329–349
2009
-
[6]
Ke Chen, Peiran Wang, Yaoning Yu, Xianyang Zhan, and Haohan Wang
-
[7]
arXiv:2508.02744 [cs.AI] https://arxiv.org/abs/2508.02744
Large Language Model-based Data Science Agent: A Survey. arXiv:2508.02744 [cs.AI] https://arxiv.org/abs/2508.02744
-
[8]
Lingjiao Chen, Jared Quincy Davis, Boris Hanin, Peter Bailis, Matei Zaharia, James Zou, and Ion Stoica. 2025. Optimizing Model Selection for Compound AI 6 Systems. arXiv:2502.14815 [cs.AI] https://arxiv.org/abs/2502.14815
arXiv 2025
-
[9]
Ruirui Chen, Weifeng Jiang, Chengwei Qin, and Cheston Tan. 2025. The- ory of Mind in Large Language Models: Assessment and Enhancement. arXiv:2505.00026 [cs.CL] https://arxiv.org/abs/2505.00026
arXiv 2025
-
[10]
Davidson, Benoit Seguin, Enrico Bacis, Cesar Ilharco, and Hamza Harkous
Tim R. Davidson, Benoit Seguin, Enrico Bacis, Cesar Ilharco, and Hamza Harkous. 2026. Reasoning-Driven Synthetic Data Generation and Evaluation. arXiv:2603.29791 [cs.AI] https://arxiv.org/abs/2603.29791
arXiv 2026
-
[11]
Yudong Gao, Zongjie Li, Zimo Ji, Pingchuan Ma, Shuai Wang, et al . 2026. Skillreducer: Optimizing llm agent skills for token efficiency.arXiv preprint arXiv:2603.29919(2026)
Pith/arXiv arXiv 2026
-
[12]
Gelpí, Eric Xue, and William A
Rebekah A. Gelpí, Eric Xue, and William A. Cunningham. 2025. Towards Ma- chine Theory of Mind with Large Language Model-Augmented Inverse Planning. arXiv:2507.03682 [cs.AI] https://arxiv.org/abs/2507.03682
arXiv 2025
-
[13]
Jingzhi Gong, Ruizhen Gu, Zhiwei Fei, Yazhuo Cao, Lukas Twist, Alina Geiger, Shuo Han, Dominik Sobania, Federica Sarro, and Jie M Zhang. 2026. SkillMOO: Multi-Objective Optimization of Agent Skills for Software Engineering.arXiv preprint arXiv:2604.09297(2026)
Pith/arXiv arXiv 2026
-
[14]
2026.Harbor: A framework for evaluating and opti- mizing agents and models in container environments
Harbor Framework Team. 2026.Harbor: A framework for evaluating and opti- mizing agents and models in container environments. https://github.com/harbor- framework/harbor
2026
-
[15]
Chenyi Huang, Haoting Zhang, Jingxu Xu, Zeyu Zheng, and Yunduan Lin. 2026. Bilevel Optimization of Agent Skills via Monte Carlo Tree Search.arXiv preprint arXiv:2604.15709(2026)
Pith/arXiv arXiv 2026
-
[16]
Ruanqianqian Huang, Avery Reyna, Sorin Lerner, Haijun Xia, and Brian Hempel
-
[17]
arXiv:2512.14012 [cs.SE] https://arxiv.org/abs/2512.14012
Professional Software Developers Don’t Vibe, They Control: AI Agent Use for Coding in 2025. arXiv:2512.14012 [cs.SE] https://arxiv.org/abs/2512.14012
arXiv 2025
-
[18]
Hyunmin Hwang, Jaemin Kim, Choonghan Kim, Hangeol Chang, and Jong Chul Ye. 2026. AgentPSO: Evolving Agent Reasoning Skill via Multi-agent Particle Swarm Optimization.arXiv preprint arXiv:2605.08704(2026)
Pith/arXiv arXiv 2026
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InThe Twelfth International Conference on Learning Representations
2024
-
[20]
Pan, Guilin Qi, Haofen Wang, and Huajun Chen
Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Xin Xu, Tongtong Wu, Kun Wang, Yang Liu, Zhen Bi, Jungang Lou, Yuchen Eleanor Jiang, Hangcheng Zhu, Gang Yu, Haiwen Hong, Longtao Huang, Hui Xue, Chenxi Wang, Yijun Wang, Zifei Shan, Xi Chen, Zhaopeng Tu, Feiyu Xiong, X...
-
[21]
arXiv:2603.04448 [cs.AI] https://arxiv.org/abs/2603.04448
SkillNet: Create, Evaluate, and Connect AI Skills. arXiv:2603.04448 [cs.AI] https://arxiv.org/abs/2603.04448
-
[22]
Jiacheng Liu, Xiaohan Zhao, Xinyi Shang, and Zhiqiang Shen. 2026. Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems. arXiv:2604.14228 [cs.SE] https://arxiv.org/abs/2604.14228
Pith/arXiv arXiv 2026
-
[23]
Pan, Alexander Du, Kurt Keutzer, Alvin Cheung, Alexandros G
Shu Liu, Shubham Agarwal, Monishwaran Maheswaran, Mert Cemri, Zhifei Li, Qiuyang Mang, Ashwin Naren, Ethan Boneh, Audrey Cheng, Melissa Z. Pan, Alexander Du, Kurt Keutzer, Alvin Cheung, Alexandros G. Dimakis, Koushik Sen, Matei Zaharia, and Ion Stoica. 2026. EvoX: Meta-Evolution for Automated Discovery. arXiv:2602.23413 [cs.LG] https://arxiv.org/abs/2602.23413
arXiv 2026
-
[24]
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. 2025. Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First. arXiv:2509.00997 [cs.AI] https://arxiv.org/a...
arXiv 2025
-
[25]
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, and Yuyu Luo. 2025. A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going? arXiv:2408.05109 [cs.DB] https://arxiv.org/abs/2408.05109
arXiv 2025
-
[26]
Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. 2025. AlphaEvolve: A coding agent for scientific an...
Pith/arXiv arXiv 2025
-
[27]
Weiming Sheng, Jinlang Wang, Manuel Barros, Aldrin Montana, Jacopo Tagli- abue, and Luca Bigon. 2026. Building a Correct-by-Design Lakehouse. Data Contracts, Versioning, and Transactional Pipelines for Humans and Agents. arXiv:2602.02335 [cs.DC] https://arxiv.org/abs/2602.02335
arXiv 2026
-
[28]
Jacopo Tagliabue, Tyler Caraza-Harter, and Ciro Greco. 2024. Bauplan: Zero-copy, Scale-up FaaS for Data Pipelines. InProceedings of the 10th International Workshop on Serverless Computing(Hong Kong, Hong Kong)(WoSC10 ’24). Association for Computing Machinery, New York, NY, USA, 31–36. https://doi.org/10.1145/ 3702634.3702955
arXiv 2024
-
[29]
Jacopo Tagliabue, Ryan Curtin, and Ciro Greco. 2024. FaaS and Furious: abstrac- tions and differential caching for efficient data pre-processing . In2024 IEEE Inter- national Conference on Big Data (BigData). IEEE Computer Society, Los Alamitos, CA, USA, 3562–3567. https://doi.org/10.1109/BigData62323.2024.10825377
-
[30]
Jacopo Tagliabue and Ciro Greco. 2024. Reproducible data science over data lakes: replayable data pipelines with Bauplan and Nessie. InProceedings of the Eighth Workshop on Data Management for End-to-End Machine Learning(Santiago, AA, Chile)(DEEM ’24). Association for Computing Machinery, New York, NY, USA, 67–71. https://doi.org/10.1145/3650203.3663335
-
[31]
Yash Vishe, Rohan Surana, Xunyi Jiang, Zihan Huang, Xintong Li, Nikki Li- jing Kuang, Tong Yu, Ryan A Rossi, Jingbo Shang, Julian McAuley, et al. 2026. Skill-R1: Agent Skill Evolution via Reinforcement Learning.arXiv preprint arXiv:2605.09359(2026)
Pith/arXiv arXiv 2026
-
[32]
On the calibration of large language models and alignment
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-Instruct: Aligning Language Mod- els with Self-Generated Instructions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. https://doi.org/10.18653/v1/2023. acl-long.754
-
[33]
Jiaxin Wen, Ruiqi Zhong, Akbir Khan, Ethan Perez, Jacob Steinhardt, Minlie Huang, Samuel R. Bowman, He He, and Shi Feng. 2024. Language Models Learn to Mislead Humans via RLHF. arXiv:2409.12822 [cs.CL] https://arxiv.org/abs/ 2409.12822
arXiv 2024
-
[34]
Renjun Xu and Yang Yan. 2026. Agent Skills for Large Language Models: Archi- tecture, Acquisition, Security, and the Path Forward. arXiv:2602.12430 [cs.MA] https://arxiv.org/abs/2602.12430
Pith/arXiv arXiv 2026
-
[35]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2025. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. InThe Thirteenth International Conference on Learning Representations
2025
-
[36]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[37]
Zaharia, Ali Ghodsi, Reynold Xin, and Michael Armbrust
Matei A. Zaharia, Ali Ghodsi, Reynold Xin, and Michael Armbrust. 2021. Lake- house: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. InConference on Innovative Data Systems Research
2021
-
[38]
Daochen Zha, Zaid Pervaiz Bhat, Kwei-Herng Lai, Fan Yang, Zhimeng Jiang, Shaochen Zhong, and Xia Hu. 2023. Data-centric Artificial Intelligence: A Survey. arXiv:2303.10158 [cs.LG] https://arxiv.org/abs/2303.10158
arXiv 2023
-
[39]
task_name
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems. A EXAMPLES OF TASKS We reproduce here some task entries from ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.