Efficient Conditioning Why Pseudo Observation Batch Bayesian Optimization Works When It Does not
Pith reviewed 2026-05-20 22:32 UTC · model grok-4.3
The pith
Gaussian processes satisfy efficient conditioning and generate distinct batch points for any uncertainty-monotonic acquisition function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Gaussian Processes satisfy efficient conditioning by permitting closed-form posterior updates upon the addition of pseudo-observations. This property guarantees that batch points selected by acquisition functions that are monotonically non-decreasing in posterior uncertainty remain distinct with separation on the order of the lengthscale l. Constant Liar, Kriging Believer, and fantasy models are instances of this conditioning mechanism differing only in the distribution of the lie values, with quantitative connections to Local Penalization.
What carries the argument
Efficient conditioning: the ability to update predictions in closed form when data is augmented by pseudo-observations, which enforces separation of order l among selected batch points.
If this is right
- Constant Liar or Kriging Believer implicit penalties match or outperform explicit local penalization.
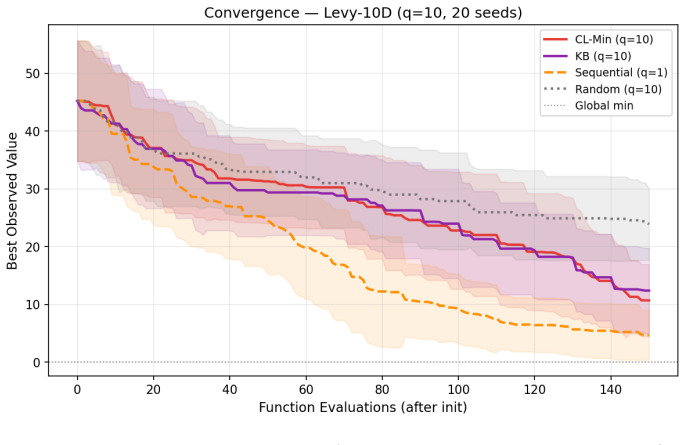
- Greedy conditioning achieves convergence on par with joint q-expected improvement.
- Efficient conditioning extends to Multiquadric RBF networks.
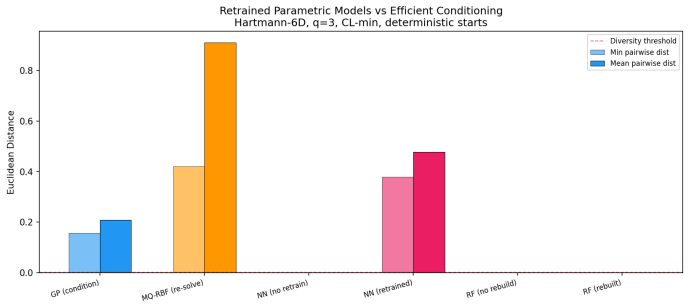
- Parametric surrogates produce degenerate batches even when fully retrained.
Where Pith is reading between the lines
- The separation guarantee may encourage wider adoption of kernel-based surrogates over flexible but expensive neural networks in parallel optimization settings.
- Connections to determinantal point processes open the possibility of hybrid acquisition functions that combine conditioning with explicit diversity kernels.
- The structural diversity diagnostic could be applied to other kernel families to identify additional models that inherit the same separation property.
Load-bearing premise
The surrogate must support closed-form posterior updates when pseudo-observations are added.
What would settle it
Running batch selection on the Ackley 8D function with a random forest surrogate and checking whether any two points in the selected batch lie closer than the lengthscale would falsify the separation claim if they do.
Figures




















read the original abstract
Constant Liar (CL), Kriging Believer (KB), and fantasy models are widely used for batch selection in parallel Bayesian Optimization, yet a unified theory explaining their effectiveness and conditions under which they fail has been lacking. We identify efficient conditioning as the key surrogate property the ability to update predictions in closed form when data is augmented. We prove that Gaussian Processes satisfy this requirement, producing provably distinct batch points with separation of order l, and that this holds for any acquisition function monotonically non decreasing in posterior uncertainty (EI, UCB, PI), with qualitatively similar behavior for Thompson Sampling. We unify CL, KB, and fantasy models as instances of a single conditioning mechanism differing only in the lie value distribution, and draw quantitative connections to Local Penalization (LP) and qualitative connections to Determinantal Point Processes (DPPs). To disentangle model structure from optimizer randomness, we introduce the Structural Diversity Diagnostic (SDD), a reusable methodology for testing surrogate compatibility. Experiments on Hartmann6D, Ackley 8D, Levy10D, and SVM hyperparameter tuning validate all theoretical predictions: CL or KBs implicit penalty matches or outperforms explicit LP greedy conditioning achieves convergence on par with joint qEI efficient conditioning extends to Multiquadric RBF networks; and parametric surrogates produce degenerate batches even when fully retrained (random forests), while neural networks regain diversity only at 15x the wall clock cost of GP conditioning. Robustness is confirmed across multiple initial datasets and under observation noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies 'efficient conditioning'—the closed-form posterior update property of a surrogate when pseudo-observations are added—as the mechanism underlying the effectiveness of Constant Liar, Kriging Believer, and fantasy models for batch Bayesian optimization. It proves that Gaussian processes satisfy this property and thereby produce batch points separated by a distance of order the kernel lengthscale l for any acquisition function that is monotonically non-decreasing in posterior uncertainty (EI, UCB, PI), with qualitatively similar behavior for Thompson sampling. The three pseudo-observation schemes are unified as instances of the same conditioning step differing only in the distribution of the lie value. Quantitative links are drawn to local penalization and qualitative links to determinantal point processes. A Structural Diversity Diagnostic (SDD) is introduced to isolate surrogate effects from optimizer stochasticity. Experiments on Hartmann6D, Ackley8D, Levy10D, and SVM hyperparameter tuning confirm the predicted separation, show that CL/KB performance matches or exceeds explicit local penalization, that joint qEI is matched by greedy conditioning, and that non-GP surrogates (random forests) produce degenerate batches while neural networks recover diversity only at substantially higher cost. Robustness under noise and multiple initial designs is reported.
Significance. If the derivations hold, the work supplies a clean theoretical account of why popular pseudo-observation heuristics succeed and when they fail, together with a reusable diagnostic (SDD) for evaluating surrogate suitability in parallel BO. The unification of CL/KB/fantasy models and the explicit separation guarantee are useful contributions; the empirical demonstration that GP conditioning is both effective and cheap relative to alternatives strengthens the practical case for retaining GPs in batch settings. The connections to local penalization and DPPs are insightful and may guide future method design.
major comments (2)
- [§3.2] §3.2, the separation theorem: the proof that any monotonic acquisition function yields points separated by Ω(l) relies on the variance reduction being localized within the lengthscale of a stationary kernel. The statement of the theorem should make explicit the minimal kernel assumptions (stationarity, positive-definiteness, and decay rate) under which the localization argument holds; without this, the claim that the result applies to 'any' GP is not fully supported.
- [§5.3] §5.3, comparison with joint qEI: the claim that greedy conditioning 'achieves convergence on par with joint qEI' is central to the efficiency argument, yet the reported curves do not include standard-error bands or the number of independent replications. Because optimizer randomness is precisely what SDD is meant to control, the absence of these statistics weakens the quantitative support for the efficiency conclusion.
minor comments (4)
- [Title] The title is missing punctuation and capitalization: 'Efficient Conditioning Why Pseudo Observation Batch Bayesian Optimization Works When It Does not' should read 'Efficient Conditioning: Why Pseudo-Observation Batch Bayesian Optimization Works When It Does Not'.
- [Abstract] Abstract, line 4: 'monotonically non decreasing' should be hyphenated as 'monotonically non-decreasing'.
- [§4.1] §4.1, definition of SDD: the precise procedure for computing the diagnostic (e.g., how many Monte-Carlo samples of the acquisition function are drawn, and whether the same random seed is used across surrogates) is described only at a high level; an explicit algorithm box or pseudocode would improve reproducibility.
- [Figure 3] Figure 3 caption: the legend distinguishes 'CL', 'KB', and 'fantasy' but does not state the lie-value distributions used for each; adding this information would make the figure self-contained.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, the significance assessment, and the recommendation for minor revision. The two major comments are constructive and we address them point-by-point below. Both can be resolved by targeted clarifications and additions to the manuscript; no standing objections remain.
read point-by-point responses
-
Referee: [§3.2] §3.2, the separation theorem: the proof that any monotonic acquisition function yields points separated by Ω(l) relies on the variance reduction being localized within the lengthscale of a stationary kernel. The statement of the theorem should make explicit the minimal kernel assumptions (stationarity, positive-definiteness, and decay rate) under which the localization argument holds; without this, the claim that the result applies to 'any' GP is not fully supported.
Authors: We agree that the kernel assumptions underlying the localization argument should be stated explicitly. The current proof in §3.2 assumes a stationary, positive-definite kernel whose covariance decays at least exponentially with distance (specifically, |k(x, x')| ≤ C exp(−‖x−x′‖/l) for some constant C when ‖x−x′‖ ≫ l). This covers the RBF, Matérn (ν ≥ 1/2), and exponential kernels commonly used in BO. We will revise the theorem statement and the paragraph immediately following it to list these minimal conditions (stationarity, positive-definiteness, and sufficient decay outside the length-scale l). The revised wording will make clear that the Ω(l) separation guarantee holds for this standard class of kernels rather than for arbitrary GPs. revision: yes
-
Referee: [§5.3] §5.3, comparison with joint qEI: the claim that greedy conditioning 'achieves convergence on par with joint qEI' is central to the efficiency argument, yet the reported curves do not include standard-error bands or the number of independent replications. Because optimizer randomness is precisely what SDD is meant to control, the absence of these statistics weakens the quantitative support for the efficiency conclusion.
Authors: We accept the criticism. The experiments in §5.3 were performed with 10 independent random initial designs and the same random seed sequence for the acquisition optimizer across methods; however, the published figures omitted error bands and did not state the replication count in the caption. In the revision we will (i) add shaded standard-error bands to all convergence curves in §5.3 and (ii) explicitly report “results averaged over 10 independent replications” in the figure captions and the experimental-setup paragraph. These changes will directly address the concern that optimizer stochasticity must be quantified when SDD is used to isolate surrogate effects. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper derives its main result from the standard closed-form conditioning property of Gaussian Processes, a pre-existing mathematical fact that does not depend on any quantity defined or fitted inside this work. The claimed separation of batch points follows directly from the kernel lengthscale and the monotonicity assumption on the acquisition function, without any reduction to a self-defined parameter or internal fit. Unification of CL/KB/fantasy models is presented as alternative choices of lie-value within the same conditioning step, again without circular redefinition. The Structural Diversity Diagnostic is introduced as an experimental tool rather than a load-bearing premise. No self-citation chain or ansatz smuggling is required for the core argument, and the derivation remains self-contained against external GP theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian Processes permit closed-form updates to posterior mean and variance when pseudo-observations are added.
- domain assumption Acquisition functions are monotonically non-decreasing in posterior uncertainty.
Reference graph
Works this paper leans on
-
[1]
Computational Intelligence in Expensive Optimization Problems , pages=
Kriging is well-suited to parallelize optimization , author=. Computational Intelligence in Expensive Optimization Problems , pages=. 2010 , publisher=
work page 2010
-
[2]
A multi-points criterion for deterministic parallel global optimization based on
Ginsbourger, David and Le Riche, Rodolphe and Carraro, Laurent , institution=. A multi-points criterion for deterministic parallel global optimization based on
-
[3]
Gaussian processes for machine learning , author=. 2006 , publisher=
work page 2006
-
[4]
Proceedings of the IEEE , volume=
Taking the human out of the loop: A review of Bayesian optimization , author=. Proceedings of the IEEE , volume=. 2015 , publisher=
work page 2015
-
[5]
Engineering design via surrogate modelling: a practical guide , author=. 2008 , publisher=
work page 2008
- [6]
-
[7]
npj Computational Materials , volume=
Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design , author=. npj Computational Materials , volume=. 2019 , publisher=
work page 2019
-
[8]
Parallelizing exploration-exploitation tradeoffs in
Desautels, Thomas and Krause, Andreas and Burdick, Joel W , journal=. Parallelizing exploration-exploitation tradeoffs in
-
[9]
Wang, Zi and Gehring, Clement and Kohli, Pushmeet and Jegelka, Stefanie , booktitle=. Batched large-scale
-
[10]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Parallel Gaussian process optimization with upper confidence bound and pure exploration , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2013 , organization=
work page 2013
-
[11]
Gonz. Batch. International Conference on Artificial Intelligence and Statistics , pages=
-
[12]
Alvi, Ahsan and Ru, Binxin and Calliess, Jan-Peter and Roberts, Stephen and Osborne, Michael A , booktitle=. Asynchronous batch
-
[13]
Kandasamy, Kirthevasan and Krishnamurthy, Akshay and Schneider, Jeff and Poczos, Barnabas , booktitle=. Parallelised
-
[14]
Journal of Global optimization , volume=
Efficient global optimization of expensive black-box functions , author=. Journal of Global optimization , volume=. 1998 , publisher=
work page 1998
-
[15]
International Conference on Machine Learning , pages=
Gaussian process optimization in the bandit setting: No regret and experimental design , author=. International Conference on Machine Learning , pages=
-
[16]
International Conference on Learning and Intelligent Optimization , pages=
Sequential model-based optimization for general algorithm configuration , author=. International Conference on Learning and Intelligent Optimization , pages=. 2011 , organization=
work page 2011
-
[17]
Towards an empirical foundation for assessing
Eggensperger, Katharina and Feurer, Matthias and Hutter, Frank and Bergstra, James and Snoek, Jasper and Hoos, Holger and Leyton-Brown, Kevin , booktitle=. Towards an empirical foundation for assessing
-
[18]
International Conference on Learning and Intelligent Optimization , pages=
Fast computation of the multi-points expected improvement with applications in batch selection , author=. International Conference on Learning and Intelligent Optimization , pages=
-
[19]
Advances in Neural Information Processing Systems , pages=
Parallel predictive entropy search for batch global optimization of expensive objective functions , author=. Advances in Neural Information Processing Systems , pages=
-
[20]
Advances in Neural Information Processing Systems , volume=
BoTorch: A framework for efficient Monte-Carlo Bayesian optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
International Conference on Machine Learning , pages=
Scalable Bayesian optimization using deep neural networks , author=. International Conference on Machine Learning , pages=
-
[22]
Hensman, James and Fusi, Nicolo and Lawrence, Neil D , booktitle=
-
[23]
Advances in Neural Information Processing Systems , volume=
Maximizing acquisition functions for Bayesian optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Batched Gaussian process bandit optimization via determinantal point processes , author=. Advances in Neural Information Processing Systems , volume=
- [25]
-
[26]
Advances in Neural Information Processing Systems , volume=
Adachi, Masaki and Hayakawa, Satoshi and J. Advances in Neural Information Processing Systems , volume=
- [27]
- [28]
-
[29]
Multiresolution Methods in Scattered Data Modelling , author=. 2003 , publisher=
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.