Weight-space symmetry in deep networks gives rise to permutation saddles, connected by equal-loss valleys across the loss landscape
Pith reviewed 2026-05-25 02:09 UTC · model grok-4.3
The pith
Neuron permutation symmetry produces saddle points linked by constant-loss valleys in neural network loss landscapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
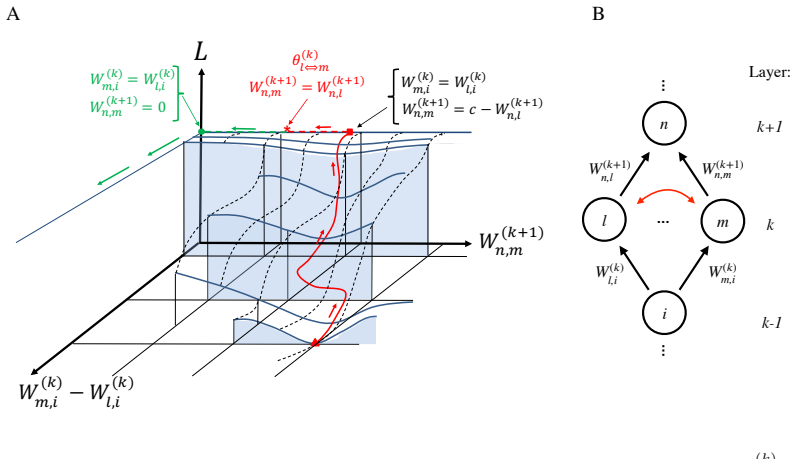
In a network with d-1 hidden layers, paths between equivalent minima transit through permutation points at which two neurons in layer k exchange their input and output weight vectors. These points are critical points of the loss with at least n_{k+1} zero Hessian eigenvalues. The point for neurons i and j continues into an extended plateau of n_{k+1} flat dimensions that accommodates every possible ordering of the n_k neurons at identical loss. The recursive structure further produces Kth-order permutation points whose number is at least larger than the number of minima by the factor sum_k 1/(2!^K) * binom(n_k - K, K).
What carries the argument
The permutation point, the configuration where two neurons in the same hidden layer have identical incoming and outgoing weights so that they can be continuously swapped while the network function stays unchanged.
Load-bearing premise
A differentiable path through weight space can be chosen that keeps the network output exactly constant while two neurons swap their weight vectors continuously.
What would settle it
In a small network construct an explicit permutation point and verify that the Hessian has at least n_{k+1} eigenvalues equal to zero.
Figures





read the original abstract
The permutation symmetry of neurons in each layer of a deep neural network gives rise not only to multiple equivalent global minima of the loss function, but also to first-order saddle points located on the path between the global minima. In a network of $d-1$ hidden layers with $n_k$ neurons in layers $k = 1, \ldots, d$, we construct smooth paths between equivalent global minima that lead through a `permutation point' where the input and output weight vectors of two neurons in the same hidden layer $k$ collide and interchange. We show that such permutation points are critical points with at least $n_{k+1}$ vanishing eigenvalues of the Hessian matrix of second derivatives indicating a local plateau of the loss function. We find that a permutation point for the exchange of neurons $i$ and $j$ transits into a flat valley (or generally, an extended plateau of $n_{k+1}$ flat dimensions) that enables all $n_k!$ permutations of neurons in a given layer $k$ at the same loss value. Moreover, we introduce high-order permutation points by exploiting the recursive structure in neural network functions, and find that the number of $K^{\text{th}}$-order permutation points is at least by a factor $\sum_{k=1}^{d-1}\frac{1}{2!^K}{n_k-K \choose K}$ larger than the (already huge) number of equivalent global minima. In two tasks, we illustrate numerically that some of the permutation points correspond to first-order saddles (`permutation saddles'): first, in a toy network with a single hidden layer on a function approximation task and, second, in a multilayer network on the MNIST task. Our geometric approach yields a lower bound on the number of critical points generated by weight-space symmetries and provides a simple intuitive link between previous mathematical results and numerical observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that neuron permutation symmetries in deep networks generate not only equivalent global minima but also 'permutation points' (where input/output weight vectors of two neurons in layer k collide) that are critical points with at least n_{k+1} vanishing Hessian eigenvalues, connected by flat valleys enabling all n_k! permutations at constant loss. It constructs smooth paths through these points between equivalent minima, introduces higher-order permutation points whose number exceeds the number of minima by a combinatorial factor, and numerically illustrates permutation saddles on a toy single-hidden-layer network and on MNIST.
Significance. If the identification of permutation points as critical points holds, the geometric construction supplies an explicit lower bound on symmetry-induced critical points, a concrete link between permutation invariance and the observed abundance of saddles/plateaus, and a mechanism for connected components of equal-loss minima; the numerical examples on toy and MNIST tasks provide direct evidence of the predicted flat directions.
major comments (2)
- [construction of permutation points and Hessian analysis (abstract and §3–4)] The central derivation that permutation points are critical points (i.e., have identically zero gradient) is not established by the symmetry argument alone. Symmetry under neuron-label swap forces the per-neuron gradient components to be identical, but places no constraint forcing the common gradient with respect to the shared input weights or the summed output direction to vanish; those components vanish only if the reduced (merged-neuron) network is itself at a critical point of the loss, which the path-construction between global minima does not enforce. This directly affects the claim that the points are saddles rather than merely points with a flat valley in certain directions.
- [Hessian eigenvalue claim (abstract and §3)] The lower bound of at least n_{k+1} vanishing Hessian eigenvalues is tied to the output-weight valley, but the full statement that these are zero eigenvalues of the Hessian at a stationary point requires the gradient to be zero first; without that, the eigenvalue count applies only to the restricted Hessian on the valley subspace.
minor comments (2)
- [higher-order points] Notation for the recursive definition of higher-order permutation points could be clarified with an explicit small example (e.g., K=2 on a two-layer network) to make the combinatorial factor ∑_{k=1}^{d-1} 1/(2!^K) binom(n_k - K, K) easier to verify.
- [numerical experiments on toy network and MNIST] The numerical sections would benefit from reporting the measured gradient norm at the identified permutation points (in addition to loss and Hessian eigenvalues) to allow direct checking of the stationarity claim.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments, which identify a substantive gap in the theoretical argument. We address the two major comments point by point below.
read point-by-point responses
-
Referee: The central derivation that permutation points are critical points (i.e., have identically zero gradient) is not established by the symmetry argument alone. Symmetry under neuron-label swap forces the per-neuron gradient components to be identical, but places no constraint forcing the common gradient with respect to the shared input weights or the summed output direction to vanish; those components vanish only if the reduced (merged-neuron) network is itself at a critical point of the loss, which the path-construction between global minima does not enforce. This directly affects the claim that the points are saddles rather than merely points with a flat valley in certain directions.
Authors: We agree with the referee's analysis. The symmetry argument establishes that the per-neuron gradient components are identical but does not force the common value to vanish; this requires the reduced (merged-neuron) network to itself be at a critical point. Our path construction between global minima does not automatically enforce the latter condition at the collision point. We will revise §3–4 and the abstract to state the additional condition explicitly, qualify the claim that permutation points are critical points/saddles, and note that the flat-valley property holds independently of criticality. revision: yes
-
Referee: The lower bound of at least n_{k+1} vanishing Hessian eigenvalues is tied to the output-weight valley, but the full statement that these are zero eigenvalues of the Hessian at a stationary point requires the gradient to be zero first; without that, the eigenvalue count applies only to the restricted Hessian on the valley subspace.
Authors: We concur. The stated lower bound on vanishing eigenvalues is rigorously a property of the restricted Hessian along the valley directions unless the point is first shown to be stationary. We will revise the abstract and §3 to make this distinction clear and to tie the full-Hessian claim to the corrected criticality condition introduced in response to the first comment. revision: yes
Circularity Check
No circularity: derivation is an explicit geometric construction from standard permutation invariance
full rationale
The paper constructs explicit smooth paths in weight space that interchange neurons while holding the network output (hence loss) constant, then computes the gradient and Hessian along those paths to identify critical points and flat directions. These steps rely only on the algebraic fact that the network function is invariant under neuron relabeling (a property true for any feed-forward architecture with the usual sum-and-activation structure) and on direct differentiation; no parameters are fitted to data, no result is renamed as a prediction, and no load-bearing premise is justified solely by self-citation. The counting arguments for higher-order permutation points follow recursively from the same invariance. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The loss function is exactly invariant under arbitrary permutations of neurons within each hidden layer.
- standard math The loss function is twice differentiable so that the Hessian exists at the permutation points.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that such permutation points are critical points with at least n_{k+1} vanishing eigenvalues of the Hessian matrix... transits into a flat valley that enables all n_k! permutations of neurons in a given layer k at the same loss value.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the number of Kth-order permutation points is at least by a factor ∑_{k=1}^{d-1} 1/2!^K (n_k - K choose K) larger than the number of equivalent global minima
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
A Theory of Saddle Escape in Deep Nonlinear Networks
Derives exact norm-imbalance identity for deep nonlinear nets, classifying activations into four classes and yielding escape time law τ★ = Θ(ε^{-(r-2)}) governed by bottleneck depth r.
-
A Theory of Saddle Escape in Deep Nonlinear Networks
An exact norm-imbalance identity classifies activations into four classes and reduces deep nonlinear training flow to a scalar ODE that predicts saddle escape time scaling as ε to the power of minus (r-2) for r bottle...
-
The Platonic Representation Hypothesis
Representations learned by large AI models are converging toward a shared statistical model of reality.
-
Nora: Normalized Orthogonal Row Alignment for Scalable Matrix Optimizer
Nora is a matrix optimizer that stabilizes weight norms and angular velocities through row-wise momentum projection onto the orthogonal complement of the weights while approximating structured preconditioning with O(m...
Reference graph
Works this paper leans on
- [1]
-
[2]
C. M. Bishop. Neural Networks for Pattern Recognition. Clarendon Press, 1995
work page 1995
-
[3]
Y . N. Dauphin, R. Pascanu, C. Gulcehre, K. Cho, S. Ganguli, and Y . Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In Advances in Neural Information Processing Systems, pages 2933–2941, 2014
work page 2014
-
[4]
I. J. Goodfellow, O. Vinyals, and A. M. Saxe. Qualitatively characterizing neural network optimization problems. arXiv preprint arXiv:1412.6544, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein. Visualizing the loss landscape of neural nets. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31 , pages 6389–6399. Curran Associates, Inc., 2018
work page 2018
-
[6]
Explorations on high dimensional landscapes
L. Sagun, V . U. Guney, G. B. Arous, and Y . LeCun. Explorations on high dimensional landscapes. arXiv preprint arXiv:1412.6615, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
L. Sagun, L. Bottou, and Y . LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond. arXiv preprint arXiv:1611.07476, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
A. Choromanska, M. Henaff, M. Mathieu, G. B. Arous, and Y . LeCun. The loss surfaces of multilayer networks. In Artificial Intelligence and Statistics, pages 192–204, 2015
work page 2015
-
[9]
C. E. Rasmussen. Gaussian processes in machine learning. In Summer School on Machine Learning, pages 63–71. Springer, 2003
work page 2003
-
[10]
C. D. Freeman and J. Bruna. Topology and geometry of half-rectified network optimization. arXiv preprint arXiv:1611.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
K. Fukumizu and S. Amari. Local minima and plateaus in hierarchical structures of multilayer perceptrons. Neural Networks, 13(3):317 – 327, 2000
work page 2000
-
[12]
D. Saad and S. A. Solla. On-line learning in soft committee machines. Physical Review E, 52 (4):4225, 1995
work page 1995
-
[13]
A. J. Ballard, R. Das, S. Martiniani, D. Mehta, L. Sagun, J. D. Stevenson, and D. J. Wales. Energy landscapes for machine learning. Physical Chemistry Chemical Physics, 19(20):12585– 12603, 2017
work page 2017
-
[14]
Understanding deep learning requires rethinking generalization
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning requires rethinking generalization. arXiv preprint arXiv:1611.03530, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
P. Baldi and K. Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural Networks, 2(1):53–58, 1989. 9
work page 1989
- [16]
-
[17]
Depth Creates No Bad Local Minima
H. Lu and K. Kawaguchi. Depth creates no bad local minima. arXiv preprint arXiv:1702.08580, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
No bad local minima: Data independent training error guarantees for multilayer neural networks
D. Soudry and Y . Carmon. No bad local minima: Data independent training error guarantees for multilayer neural networks. arXiv preprint arXiv:1605.08361, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Q. Nguyen and M. Hein. The loss surface of deep and wide neural networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 2603–2612. JMLR. org, 2017
work page 2017
-
[21]
T. Garipov, P. Izmailov, D. Podoprikhin, D. P. Vetrov, and A. G. Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns. In Advances in Neural Information Processing Systems, pages 8789–8798, 2018
work page 2018
-
[22]
Essentially No Barriers in Neural Network Energy Landscape
F. Draxler, K. Veschgini, M. Salmhofer, and F. A. Hamprecht. Essentially no barriers in neural network energy landscape. arXiv preprint arXiv:1803.00885, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
J. D. Lee, M. Simchowitz, M. I. Jordan, and B. Recht. Gradient descent converges to minimizers. arXiv preprint arXiv:1602.04915, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [24]
-
[25]
S. Spigler, M. Geiger, S. d’Ascoli, L. Sagun, G. Biroli, and M. Wyart. A jamming transition from under-to over-parametrization affects loss landscape and generalization. arXiv preprint arXiv:1810.09665, 2018
-
[26]
A. Engel and C. Van den Broeck. Statistical mechanics of learning. Cambridge University Press, 2001
work page 2001
- [27]
-
[28]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
L. Sagun, U. Evci, V . U. Guney, Y . Dauphin, and L. Bottou. Empirical analysis of the hessian of over-parametrized neural networks. arXiv preprint arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
M. Baity-Jesi, L. Sagun, M. Geiger, S. Spigler, G. B. Arous, C. Cammarota, Y . LeCun, M. Wyart, and G. Biroli. Comparing dynamics: Deep neural networks versus glassy systems.arXiv preprint arXiv:1803.06969, 2018. 10 A Supplementary Figures 𝑑𝑑0 * 𝑑𝑑0 * 𝑑𝑑0 * 𝑑𝑑0 * d(λ)0 A B DC S 𝑑𝑑0 * 𝑑𝑑0 * 𝑑𝑑0 * 𝑑𝑑0 * d(λ)0 A B DC S Figure 4: LossL (vertical axis) on the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.