Predicting Mergeability of Parameter-Efficient Fine-Tuning Updates
Pith reviewed 2026-06-26 20:59 UTC · model grok-4.3
The pith
Mergeability of low-rank adapters can be predicted from signals available after the first few percent of training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
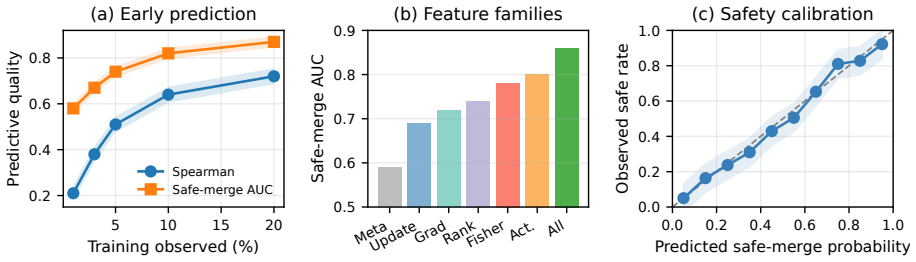
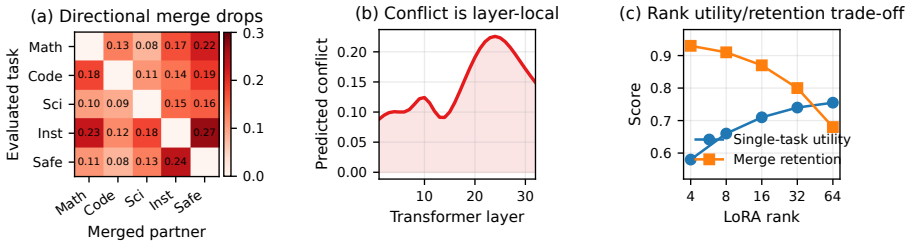
We formalize adapter mergeability as the degree to which an adapter preserves its single-task utility after merging, and show that it can be forecast from signals measured in the first few percent of training—chiefly how the low-rank updates and their gradients align across tasks and how much they disturb shared representations. We package these signals into MergeProbe, a lightweight predictor that estimates pairwise and set-level retention and turns the estimate into a concrete decision: merge directly, reweight, prune, or route.
What carries the argument
MergeProbe, a predictor constructed from early-training measurements of low-rank update alignment, gradient alignment across tasks, and disturbance to shared representations.
If this is right
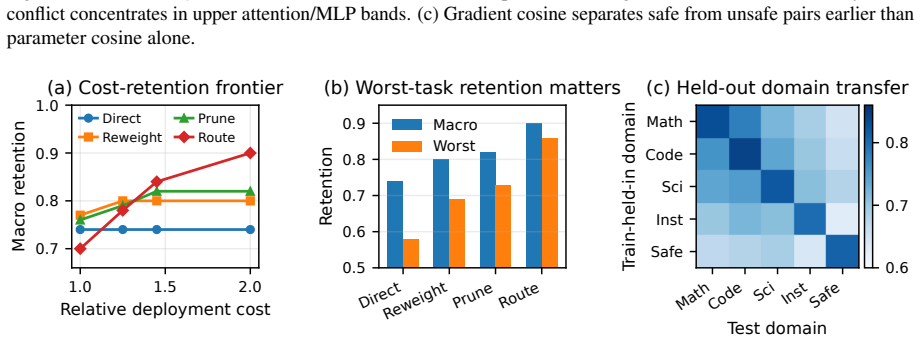
- MergeProbe attains the best average and worst-case retention among strong interference-aware merge baselines on the five-domain benchmark.
- It adds far less deployment overhead than full task routing while still avoiding destructive interference.
- Adapter merging changes from a post-hoc trial-and-error step into an anticipatory measurement problem solved before training finishes.
- The predictor supports decisions at both pairwise and set-level granularity.
Where Pith is reading between the lines
- If the early signals generalize, MergeProbe could be inserted into multi-task training loops to decide on the fly which new adapters are worth completing.
- The same alignment measurements might be used to adjust learning rates or regularization during training itself to increase later mergeability.
- Applying identical early-signal collection to other parameter-efficient methods besides LoRA would test whether the approach is specific to low-rank updates.
Load-bearing premise
The early-training alignment and disturbance signals remain predictive of final merged utility even when the full training trajectories, task distributions, or base-model scale differ from the five-domain benchmark used to tune MergeProbe.
What would settle it
Train separate adapters on a new collection of tasks outside the original five domains, run MergeProbe on the first few percent of each training run, then compare its retention predictions against the actual single-task versus merged performance after training completes.
Figures
read the original abstract
Low-rank adaptation (LoRA) makes it cheap to train many domain- and task-specific language model adapters, but whether two adapters can be merged is usually discovered only after both have been fully trained and evaluated. This late feedback is costly: adapters that are strong in isolation can interfere destructively once their updates are combined. We ask whether this outcome can be anticipated. We formalize adapter mergeability as the degree to which an adapter preserves its single-task utility after merging, and show that it can be forecast from signals measured in the first few percent of training -- chiefly how the low-rank updates and their gradients align across tasks and how much they disturb shared representations. We package these signals into MergeProbe, a lightweight predictor that estimates pairwise and set-level retention and turns the estimate into a concrete decision: merge directly, reweight, prune, or route. On MERGE-PEFT, a five-domain benchmark spanning math, code, science, instruction following, and safety, MergeProbe attains the best average and worst-case retention among strong interference-aware merge baselines while adding far less deployment overhead than full task routing. This turns LoRA merging from a post-hoc engineering step into an anticipatory measurement problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes adapter mergeability as the retention of single-task utility after merging LoRA updates and claims that it can be predicted from early-training signals (primarily alignment of low-rank updates/gradients across tasks and disturbance to shared representations). These signals are packaged into MergeProbe, a lightweight predictor that outputs decisions (merge, reweight, prune, route) and is shown on the five-domain MERGE-PEFT benchmark to achieve the best average and worst-case retention among interference-aware baselines while incurring lower overhead than full routing.
Significance. If the early signals prove transferable, the work would convert an expensive post-training search into an inexpensive anticipatory measurement, with direct implications for multi-task deployment of parameter-efficient adapters. The manuscript supplies no machine-checked proofs or parameter-free derivations, but the empirical framing on a concrete benchmark is a strength if the reported retention numbers are reproducible.
major comments (2)
- [Evaluation section] Evaluation (MERGE-PEFT benchmark description): the central claim that the chosen signals remain predictive when task distributions, training horizons, or base-model scales change is load-bearing, yet the predictor is constructed and evaluated exclusively on the five-domain collection with no explicit OOD splits (new domains, different LoRA ranks, or larger base models) reported; this leaves open whether the retention numbers reflect benchmark-specific correlations rather than a general forecasting mechanism.
- [Abstract and §3] Abstract and §3 (signal definitions): the abstract asserts superior retention on MERGE-PEFT but supplies no quantitative results, error bars, baseline definitions, or exact formulas for how the alignment and disturbance signals are computed; without these, it is impossible to judge whether the data support the forecasting claim or whether the signals are measured quantities versus quantities optimized to the target.
minor comments (2)
- Notation for the retention metric and the MergeProbe output decision rule should be introduced with explicit equations rather than prose descriptions.
- Figure captions for any retention plots should state the number of runs, random seeds, and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on evaluation scope and result presentation. We respond to each major point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation (MERGE-PEFT benchmark description): the central claim that the chosen signals remain predictive when task distributions, training horizons, or base-model scales change is load-bearing, yet the predictor is constructed and evaluated exclusively on the five-domain collection with no explicit OOD splits (new domains, different LoRA ranks, or larger base models) reported; this leaves open whether the retention numbers reflect benchmark-specific correlations rather than a general forecasting mechanism.
Authors: We agree that explicit OOD testing would strengthen claims of generalizability. The five domains were selected for diversity (math, code, science, instruction following, safety), but this does not substitute for held-out domains or scale variations. We will add a limitations subsection acknowledging this gap and outlining future work on OOD splits, without claiming broader transferability beyond the reported benchmark. No new experiments are feasible in the current revision cycle. revision: partial
-
Referee: [Abstract and §3] Abstract and §3 (signal definitions): the abstract asserts superior retention on MERGE-PEFT but supplies no quantitative results, error bars, baseline definitions, or exact formulas for how the alignment and disturbance signals are computed; without these, it is impossible to judge whether the data support the forecasting claim or whether the signals are measured quantities versus quantities optimized to the target.
Authors: We accept this criticism. The abstract will be revised to include key quantitative retention figures (average and worst-case), baseline comparisons, and overhead metrics, with error bars where available in the full results. In §3 we will insert the exact formulas for the alignment (update/gradient cosine similarities) and disturbance (representation shift) signals, making clear they are computed directly from early-training checkpoints rather than tuned to the retention target. revision: yes
Circularity Check
No load-bearing circularity; early signals treated as independent measurements
full rationale
The paper formalizes mergeability via post-merge utility preservation and extracts early-training alignment/disturbance signals as direct observables to forecast it via MergeProbe. No equations reduce the forecast to a quantity fitted directly to final retention, no self-citation chain supplies the uniqueness of the signals, and no ansatz or renaming is smuggled in. The construction remains a measurement-to-prediction pipeline whose validity is benchmark-dependent rather than tautological by definition, producing only a minor score for possible dataset-specific tuning.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[2]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[3]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[4]
Prefix-tuning: Optimizing continuous prompts for generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[5]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
The power of scale for parameter-efficient prompt tuning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[6]
arXiv preprint arXiv:2212.04089 , year=
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
-
[7]
International conference on machine learning , pages=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[8]
Advances in Neural Information Processing Systems , volume=
Merging models with fisher-weighted averaging , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Ties-merging: Resolving interference when merging models , author=. Advances in neural information processing systems , volume=
-
[10]
International Conference on Learning Representations , volume=
Merging loras like playing lego: Pushing the modularity of lora to extremes through rank-wise clustering , author=. International Conference on Learning Representations , volume=
-
[11]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unraveling lora interference: Orthogonal subspaces for robust model merging , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Zou, Heming and Zang, Yunliang and Xu, Wutong and Zhu, Yao and Ji, Xiangyang , booktitle=
-
[13]
Heming Zou and Yunliang Zang and Wutong Xu and Xiangyang Ji , booktitle=. Fly-
-
[14]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[15]
Advances in neural information processing systems , volume=
Gradient episodic memory for continual learning , author=. Advances in neural information processing systems , volume=
-
[16]
Neural networks , volume=
Continual lifelong learning with neural networks: A review , author=. Neural networks , volume=. 2019 , publisher=
2019
-
[17]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[18]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[19]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[20]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[21]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[22]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[23]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[24]
International Conference on Learning Representations , volume=
Alpagasus: Training a better alpaca with fewer data , author=. International Conference on Learning Representations , volume=
-
[25]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[26]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[27]
arXiv preprint arXiv:2212.08073 , year=
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[28]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[29]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Dataset cartography: Mapping and diagnosing datasets with training dynamics , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[30]
arXiv preprint arXiv:1812.05159 , year=
An empirical study of example forgetting during deep neural network learning , author=. arXiv preprint arXiv:1812.05159 , year=
-
[31]
Advances in neural information processing systems , volume=
Deep learning on a data diet: Finding important examples early in training , author=. Advances in neural information processing systems , volume=
-
[32]
International Conference on Machine Learning , pages=
Coresets for data-efficient training of machine learning models , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[33]
Proceedings of the 16th conference of the European chapter of the association for computational linguistics: main volume , pages=
Adapterfusion: Non-destructive task composition for transfer learning , author=. Proceedings of the 16th conference of the European chapter of the association for computational linguistics: main volume , pages=
-
[34]
arXiv preprint arXiv:2303.10512 , year=
Adalora: Adaptive budget allocation for parameter-efficient fine-tuning , author=. arXiv preprint arXiv:2303.10512 , year=
-
[35]
Forty-first International Conference on Machine Learning , year=
Dora: Weight-decomposed low-rank adaptation , author=. Forty-first International Conference on Machine Learning , year=
-
[36]
International Conference on Learning Representations , volume=
Vera: Vector-based random matrix adaptation , author=. International Conference on Learning Representations , volume=
-
[37]
arXiv preprint arXiv:2307.13269 , year=
Lorahub: Efficient cross-task generalization via dynamic lora composition , author=. arXiv preprint arXiv:2307.13269 , year=
-
[38]
Forty-first International Conference on Machine Learning , year=
Language models are super mario: Absorbing abilities from homologous models as a free lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[39]
arXiv preprint arXiv:2212.09849 , year=
Dataless knowledge fusion by merging weights of language models , author=. arXiv preprint arXiv:2212.09849 , year=
-
[40]
International Conference on Learning Representations , volume=
Adamerging: Adaptive model merging for multi-task learning , author=. International Conference on Learning Representations , volume=
-
[41]
International Conference on Learning Representations , volume=
Zipit! merging models from different tasks without training , author=. International Conference on Learning Representations , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
Greats: Online selection of high-quality data for llm training in every iteration , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Utility-Diversity Aware Online Batch Selection for
Zou, Heming and Mao, Yixiu and Qu, Yun and Wang, Qi and Ji, Xiangyang , journal=. Utility-Diversity Aware Online Batch Selection for
-
[44]
arXiv preprint arXiv:2209.04836 , year=
Git re-basin: Merging models modulo permutation symmetries , author=. arXiv preprint arXiv:2209.04836 , year=
-
[45]
Advances in neural information processing systems , volume=
Gradient surgery for multi-task learning , author=. Advances in neural information processing systems , volume=
-
[46]
International conference on machine learning , pages=
Linear mode connectivity and the lottery ticket hypothesis , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[47]
arXiv preprint arXiv:2307.06290 , year=
Instruction mining: Instruction data selection for tuning large language models , author=. arXiv preprint arXiv:2307.06290 , year=
-
[48]
International Conference on Learning Representations , volume=
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning , author=. International Conference on Learning Representations , volume=
-
[49]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Superfiltering: Weak-to-strong data filtering for fast instruction-tuning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
arXiv preprint arXiv:2402.04333 , year=
Less: Selecting influential data for targeted instruction tuning , author=. arXiv preprint arXiv:2402.04333 , year=
-
[51]
Advances in Neural Information Processing Systems , volume=
Ranpac: Random projections and pre-trained models for continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Inflora: Interference-free low-rank adaptation for continual learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
arXiv preprint arXiv:2603.12378 , year=
NeuroLoRA: Context-Aware Neuromodulation for Parameter-Efficient Multi-Task Adaptation , author=. arXiv preprint arXiv:2603.12378 , year=
-
[54]
arXiv preprint arXiv:2601.07935 , year=
Towards Specialized Generalists: A Multi-Task MoE-LoRA Framework for Domain-Specific LLM Adaptation , author=. arXiv preprint arXiv:2601.07935 , year=
-
[55]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Arcee's mergekit: A toolkit for merging large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2024
-
[56]
arXiv e-prints , pages=
Fusionbench: A comprehensive benchmark of deep model fusion , author=. arXiv e-prints , pages=
-
[57]
arXiv preprint arXiv:2406.11617 , year=
Della-merging: Reducing interference in model merging through magnitude-based sampling , author=. arXiv preprint arXiv:2406.11617 , year=
-
[58]
arXiv preprint arXiv:2404.15159 , year=
Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts , author=. arXiv preprint arXiv:2404.15159 , year=
-
[59]
International Conference on Learning Representations , volume=
Conformal language modeling , author=. International Conference on Learning Representations , volume=
-
[60]
Transactions of the Association for Computational Linguistics , volume=
Conformal prediction for natural language processing: A survey , author=. Transactions of the Association for Computational Linguistics , volume=
-
[61]
European Conference on Computer Vision , pages=
Model breadcrumbs: Scaling multi-task model merging with sparse masks , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.