POTracker: Optimizing Large Language Models for Standard-Compliant Power Outage Report Generation
Pith reviewed 2026-06-26 08:35 UTC · model grok-4.3
The pith
POTracker fine-tunes an LLM using a loss that matches both text and report tags to reach 86.47 percent structural accuracy on power outage reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
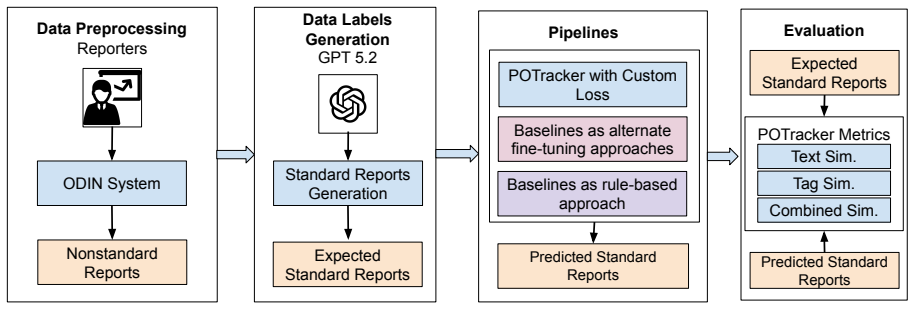
The central claim is that POTrackerLoss, which adds structural tag similarity to ordinary textual similarity during fine-tuning, enables the model to generate power outage reports that are both semantically accurate and compliant with regulatory standards, outperforming five other fine-tuning methods by up to 51 percent overall accuracy while reaching 86.47 percent structural accuracy on a dataset of one thousand reports.
What carries the argument
POTrackerLoss, a training objective that sums textual similarity with structural tag similarity between the generated report and the ground-truth report.
If this is right
- Power utilities could automate the creation of machine-readable outage reports that already satisfy regulatory formatting without manual post-processing.
- The same training approach would reduce the rate at which generated reports need correction for missing or incorrect tags.
- Fine-tuning with explicit structural penalties would generalize better than standard text-only objectives when outputs must follow fixed schemas.
- Human-rated ground-truth data at 4.03 out of 5 indicates the training set itself meets expert standards for use in further model development.
Where Pith is reading between the lines
- The loss design could transfer to other regulated document types that require both narrative accuracy and rigid tag structures, such as medical discharge summaries.
- Deploying the model in real-time outage management systems would let utilities produce compliant reports during active events rather than after the fact.
- Future work could test whether adding explicit regulatory-rule constraints to the loss produces even higher compliance rates than tag similarity alone.
Load-bearing premise
The one thousand power outage reports used for training and testing are representative of all U.S. utility standards, and the combined loss is enough by itself to guarantee full compliance.
What would settle it
Generate reports from the model on a fresh collection of outage data drawn from a different utility region and have independent regulators score whether the outputs satisfy the required machine-readable format and content rules.
Figures

read the original abstract
Recent large language models (LLMs) are good at general text generation, but it is still hard to use them for domain-specific data generation because the output must follow strict formatting and structural rules. Unlike open-ended tasks such as question answering or translation, domain-specific generation must be both semantically correct and compliant with existing guidelines and standards. In this work, we study the nationwide interoperability problem of utility power outage reports in the United States. In practice, outage reports need to be machine-readable (e.g., JSON or XML) and must strictly follow requirements from energy-sector regulatory bodies. To address this problem, we propose POTracker, an optimized LLM for power outage report generation. We fine-tune Qwen2.5-7B-Instruct using our proposed objective. The key contribution is a new loss function, POTrackerLoss, that considers both textual similarity and structural (tag) similarity between the generated report and the ground-truth report. We evaluate POTracker on a dataset of 1,000 power outage reports and compare it with five well-known fine-tuning methods and one rule-based XML conversion method. Results show that POTracker outperforms other fine-tuning approaches, improving overall accuracy by up to 51% and reaching 86.47% structural accuracy for generated power outage reports. In addition, we conduct a human study to assess the quality of the ground-truth standard reports, where domain experts assign the generated labels an average score of 4.03 on a 0--5 scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes POTracker, a fine-tuned Qwen2.5-7B-Instruct model using a novel POTrackerLoss that combines textual similarity and structural (tag) similarity. Evaluated on a dataset of 1,000 power outage reports against five fine-tuning baselines and one rule-based method, it claims up to 51% improvement in overall accuracy and 86.47% structural accuracy, supported by a human study in which domain experts rate outputs at 4.03/5 on a 0-5 scale.
Significance. If the quantitative claims hold after full methodological disclosure, the work would provide a concrete example of loss-augmented fine-tuning for generating machine-readable outputs under regulatory constraints in the energy sector. The dual textual-structural loss could be reusable for other structured generation tasks. The human study adds a useful qualitative dimension, but the absence of loss definitions, training details, and constraint-validation procedures limits immediate assessment of broader impact or reproducibility.
major comments (2)
- [Abstract] Abstract: the central claims of up to 51% accuracy improvement and 86.47% structural accuracy cannot be evaluated because the abstract supplies neither the formula for POTrackerLoss nor any description of how structural accuracy is computed, what the five baseline fine-tuning methods are, or whether statistical significance or error bars were used.
- [Abstract] Abstract: the evaluation assumes that textual-plus-tag similarity is sufficient to guarantee full regulatory compliance, yet the abstract provides no evidence of explicit checks for field-specific formats, value ranges, inter-field logical consistency, required vs. optional elements, or machine-parseability rules that are standard in utility reporting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and will revise the manuscript accordingly to improve self-containment and clarity of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of up to 51% accuracy improvement and 86.47% structural accuracy cannot be evaluated because the abstract supplies neither the formula for POTrackerLoss nor any description of how structural accuracy is computed, what the five baseline fine-tuning methods are, or whether statistical significance or error bars were used.
Authors: We agree the abstract should be more self-contained for evaluating the central claims. The full manuscript provides the POTrackerLoss formula (Section 3), structural accuracy definition (Section 4.2), descriptions of the five fine-tuning baselines (Section 4.1), and reports statistical significance with error bars in the results tables. We will revise the abstract to include concise descriptions of POTrackerLoss, the baselines, and a note on the statistical analysis. revision: yes
-
Referee: [Abstract] Abstract: the evaluation assumes that textual-plus-tag similarity is sufficient to guarantee full regulatory compliance, yet the abstract provides no evidence of explicit checks for field-specific formats, value ranges, inter-field logical consistency, required vs. optional elements, or machine-parseability rules that are standard in utility reporting.
Authors: POTrackerLoss is designed to jointly optimize textual and structural (tag) similarity precisely to enforce the regulatory formatting and structural rules for power outage reports. The 86.47% structural accuracy and domain-expert human ratings provide supporting evidence. We acknowledge the abstract does not explicitly list additional post-generation validation steps; we will revise it to briefly summarize the constraint-validation procedures (field formats, ranges, logical consistency, and parseability) that are detailed in the evaluation section of the full manuscript. revision: yes
Circularity Check
No circularity; empirical fine-tuning and held-out evaluation with no derivations or self-referential reductions
full rationale
The paper describes a standard empirical ML workflow: fine-tuning Qwen2.5-7B-Instruct with a proposed POTrackerLoss (textual + structural similarity) and reporting accuracy gains on a 1,000-report dataset versus baselines. No equations, derivations, uniqueness theorems, or self-citations are invoked as load-bearing steps in the abstract or described claims. Results are direct performance comparisons on held-out data, not reductions of outputs to inputs by construction. The skeptic concern about regulatory constraints is a correctness issue, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large Language Models for Automated Data Science: Introducing
Noah Hollmann and Samuel M. Large Language Models for Automated Data Science: Introducing. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[2]
2024 , eprint=
Examining Long-Context Large Language Models for Environmental Review Document Comprehension , author=. 2024 , eprint=
2024
-
[3]
2024 , eprint=
Data Science with LLMs and Interpretable Models , author=. 2024 , eprint=
2024
-
[4]
Danilo Bzdok and Andrew Thieme and Oleksiy Levkovskyy and Paul Wren and Thomas Ray and Siva Reddy , abstract =. Data science opportunities of large language models for neuroscience and biomedicine , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.neuron.2024.01.016 , url =
-
[5]
2024 , eprint=
LLM4DS: Evaluating Large Language Models for Data Science Code Generation , author=. 2024 , eprint=
2024
-
[6]
2023 , eprint=
Benchmarking Large Language Models for News Summarization , author=. 2023 , eprint=
2023
-
[7]
2023 , eprint=
Evaluating Open-Domain Question Answering in the Era of Large Language Models , author=. 2023 , eprint=
2023
-
[8]
2024 , eprint=
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
Domain Specialization as the Key to Make Large Language Models Disruptive: A Comprehensive Survey , author=. 2024 , eprint=
2024
-
[10]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[11]
2024 , howpublished =
The Claude 3 Model Family: Opus, Sonnet, Haiku , author =. 2024 , howpublished =
2024
-
[12]
2023 , eprint=
Large Language Models for Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering , author=. 2023 , eprint=
2023
-
[13]
2025 , eprint=
AutoParLLM: GNN-guided Context Generation for Zero-Shot Code Parallelization using LLMs , author=. 2025 , eprint=
2025
-
[14]
2023 , howpublished =
Outage Data Initiative Nationwide (ODIN) , author =. 2023 , howpublished =
2023
-
[15]
2023 , url =
Oak Ridge National Laboratory , title =. 2023 , url =
2023
-
[16]
2024 , journal =
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts , author =. 2024 , journal =
2024
-
[17]
History of Programming Languages—II , year =
A History of SQL , author =. History of Programming Languages—II , year =
-
[18]
2025 , eprint=
From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems , author=. 2025 , eprint=
2025
-
[19]
2024 , url =
Hugging Face , title =. 2024 , url =
2024
-
[20]
2024 , howpublished =
HumanSignal , title =. 2024 , howpublished =
2024
-
[21]
2024 , eprint=
Uncertainty Estimation and Quantification for LLMs: A Simple Supervised Approach , author=. 2024 , eprint=
2024
-
[22]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year =
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year =
2019
-
[23]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[24]
2024 , eprint=
The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities , author=. 2024 , eprint=
2024
-
[25]
2024 , eprint=
Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning , author=. 2024 , eprint=
2024
-
[26]
Cognitive Science , volume =
Finding structure in time , author =. Cognitive Science , volume =. 1990 , publisher =
1990
-
[27]
2024 , eprint =
A Technical Note on the Architectural Effects on Maximum Dependency Lengths of Recurrent Neural Networks , author =. 2024 , eprint =
2024
-
[28]
arXiv preprint arXiv:2305.18290 , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. arXiv preprint arXiv:2305.18290 , year =
-
[29]
2010 , isbn =
Preference Learning , author =. 2010 , isbn =
2010
-
[30]
Enhancing XML-based Compiler Construction with Large Language Models: A Novel Approach , volume=. 2024 , month=. doi:10.58496/MJBD/2024/003 , journal=
-
[31]
2023 , note =
Christoph Hack , title =. 2023 , note =
2023
-
[32]
arXiv preprint arXiv:2302.13971 , year =
LLaMA: Open and Efficient Foundation Language Models , author =. arXiv preprint arXiv:2302.13971 , year =
-
[33]
arXiv preprint arXiv:2203.02155 , year =
Training language models to follow instructions with human feedback , author =. arXiv preprint arXiv:2203.02155 , year =
-
[34]
arXiv preprint arXiv:2309.13078 , year =
LPML: LLM-Prompting Markup Language for Mathematical Reasoning , author =. arXiv preprint arXiv:2309.13078 , year =
-
[35]
arXiv preprint arXiv:2110.08518 , year =
MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding , author =. arXiv preprint arXiv:2110.08518 , year =
-
[36]
2025 , month = dec, url =
Introducing. 2025 , month = dec, url =
2025
-
[37]
2008 , publisher =
Introduction to Information Retrieval , author =. 2008 , publisher =
2008
-
[38]
difflib --- Helpers for computing deltas , author =
-
[39]
International Conference on Learning Representations (ICLR) , year =
Finetuned Language Models are Zero-Shot Learners , author =. International Conference on Learning Representations (ICLR) , year =
-
[40]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle =. Parameter-Efficient Transfer Learning for. 2019 , volume =
2019
-
[41]
arXiv preprint arXiv:2106.09685 , year =
LoRA: Low-Rank Adaptation of Large Language Models , author =. arXiv preprint arXiv:2106.09685 , year =
-
[42]
2018 , eprint=
Focal Loss for Dense Object Detection , author=. 2018 , eprint=
2018
-
[43]
2019 , eprint=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
2019
-
[44]
2020 , eprint=
SpanBERT: Improving Pre-training by Representing and Predicting Spans , author=. 2020 , eprint=
2020
-
[45]
2019 , eprint=
Learning to Reweight Examples for Robust Deep Learning , author=. 2019 , eprint=
2019
-
[46]
2019 , eprint=
Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting , author=. 2019 , eprint=
2019
-
[47]
Minimum Risk Training for Neural Machine Translation , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =. doi:10.18653/v1/P16-1159 , url =
-
[48]
B leu: a Method for Automatic Evaluation of Machine Translation
Bleu: a Method for Automatic Evaluation of Machine Translation , author =. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , year =. doi:10.3115/1073083.1073135 , url =
-
[49]
Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics , year =
Minimum Error Rate Training in Statistical Machine Translation , author =. Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics , year =. doi:10.3115/1075096.1075117 , url =
-
[50]
Rule-Based Generation of XML DTDs from UML Class Diagrams
Kudrass, Thomas and Krumbein, Tobias. Rule-Based Generation of XML DTDs from UML Class Diagrams. Advances in Databases and Information Systems. 2003
2003
-
[51]
Berdaguer, Pablo and Cunha, Alcino and Pacheco, Hugo and Visser, Joost , title =. Proceedings of the 9th International Conference on Practical Aspects of Declarative Languages , pages =. 2007 , isbn =. doi:10.1007/978-3-540-69611-7_19 , abstract =
-
[52]
2025 , eprint =
Qwen2.5 Technical Report , author =. 2025 , eprint =
2025
-
[53]
2024 , howpublished =
Qwen/Qwen2.5-7B-Instruct (Model Card) , author =. 2024 , howpublished =
2024
-
[54]
2024 , howpublished =
Qwen2.5: A Party of Foundation Models! , author =. 2024 , howpublished =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.