ML-Powered LDAP Reconnaissance Detection using Weak Supervision
Pith reviewed 2026-06-30 09:56 UTC · model grok-4.3
The pith
Correlating LDAP queries with endpoint detections supplies weak labels that train a classifier to flag malicious reconnaissance at up to 65 percent true positive rate on holdout data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating endpoint detections as noisy but abundant labels, the authors construct a large training set of LDAP queries and train a classifier that reaches 65 percent true positive rate on a held-out set while constraining false positives. The same weak-supervision pipeline feeds a hypothesis-testing procedure that mines new malicious LDAP signatures; these signatures are validated at 81.48 percent field precision by operational security analysts.
What carries the argument
Weak supervision pipeline that correlates LDAP queries with endpoint detections to generate training labels, followed by statistical hypothesis testing to extract malicious query signatures.
If this is right
- Security teams can label and train on orders of magnitude more LDAP data than manual methods allow.
- The mined signatures can be turned into production detection rules without further model training.
- Early reconnaissance activity becomes detectable before the attacker moves to later attack stages.
- The same correlation technique can be reused for other directory or authentication protocols that lack labeled attack data.
Where Pith is reading between the lines
- If endpoint detections themselves contain systematic bias, the learned classifier may overfit to whatever behaviors those detections already catch rather than discovering new reconnaissance patterns.
- The method could be extended by adding a small amount of human review on the highest-uncertainty queries to reduce label noise without losing scale.
- Similar weak-supervision pipelines might apply to other high-volume log sources such as DNS or PowerShell where ground-truth labels are scarce.
Load-bearing premise
Linking LDAP queries to endpoint detections produces labels whose noise and bias remain small enough that the resulting classifier and signatures still generalize.
What would settle it
Run the trained classifier on a fresh set of LDAP queries that have been independently labeled by human analysts and measure whether true positive rate falls substantially below 65 percent or signature precision falls substantially below 81 percent.
Figures



read the original abstract
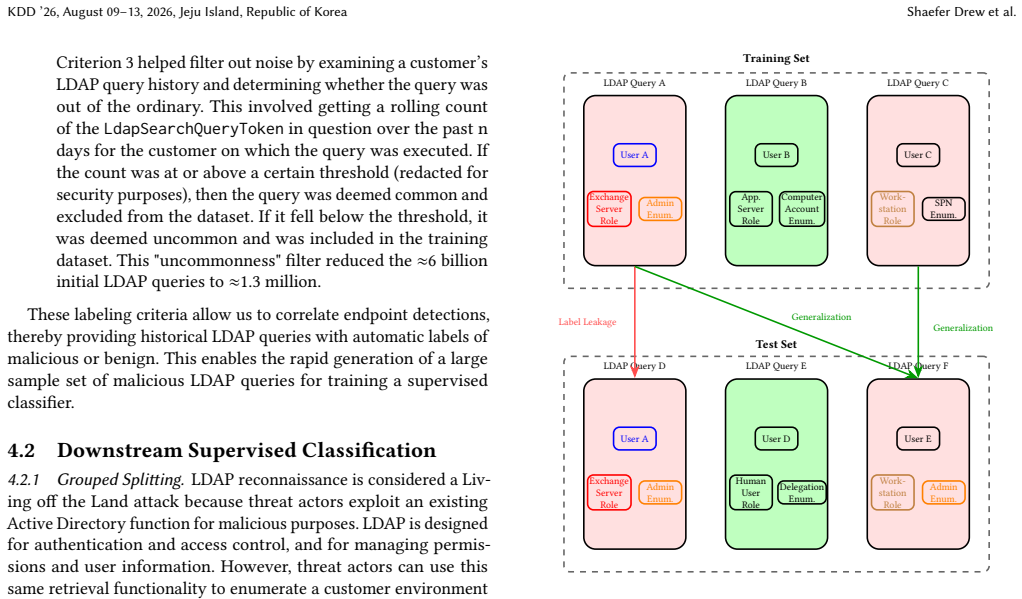
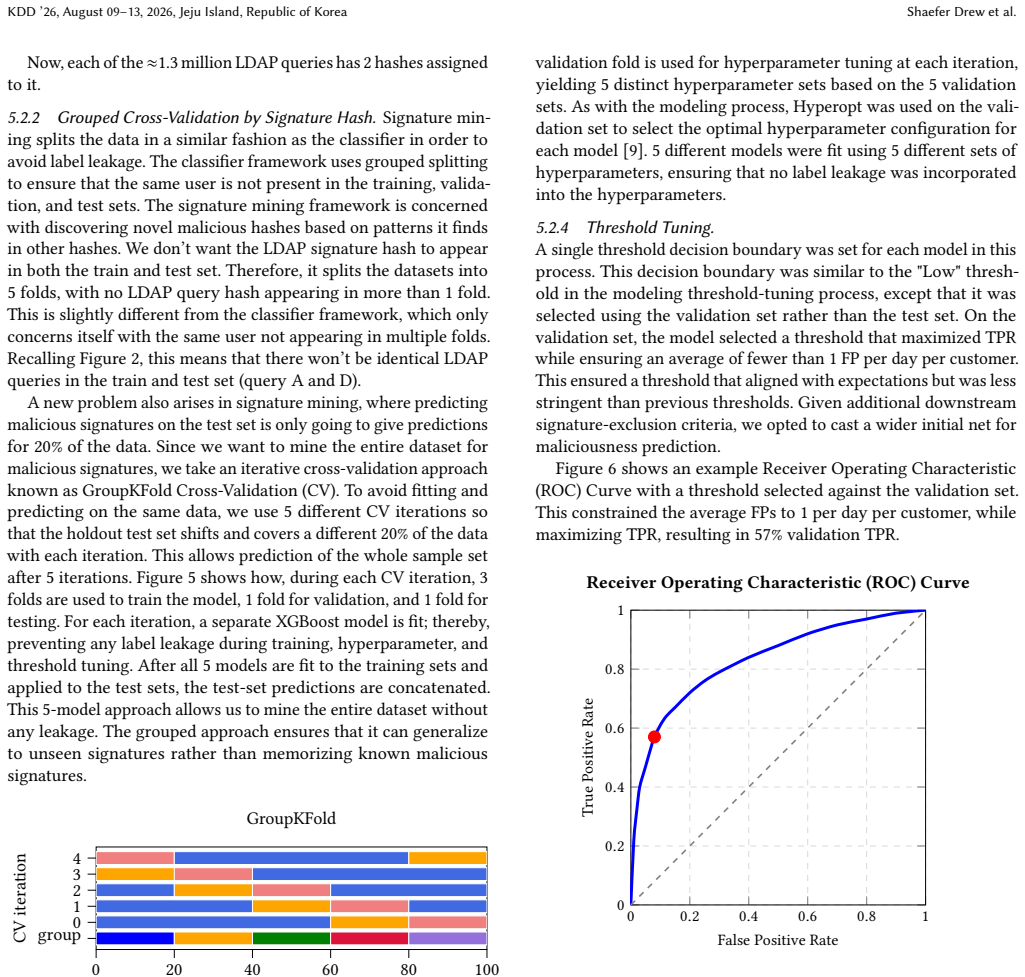
Lightweight Directory Access Protocol (LDAP) is a protocol that allows users to query and modify Active Directory (AD) data. By default, all users have read access to all AD data through LDAP, making it a common initial tool for reconnaissance when a threat actor first compromises an identity. To capture threat actors early in the reconnaissance phase, we developed two machine learning frameworks to detect LDAP reconnaissance: an ML classifier to predict malicious LDAP queries and an ML-based data-mining method to extract malicious query signatures. By correlating LDAP queries with endpoint detections, the first framework uses weak supervision to label a massive dataset and classify LDAP queries as malicious or benign. For immediate deployment, a second technique was developed on top of this approach to employ a rigorous statistical hypothesis-testing framework for mining novel, malicious LDAP signatures. While this weakly supervised approach is limited compared with manual human labeling, it is more practical for this use case because it leverages large-scale automated corpus construction, reducing costs and time. Ultimately, both the LDAP classifier and the ML-based LDAP signature mining method achieved performance benchmarks, with the classifier achieving up to a 65\% True Positive Rate (TPR) on the holdout set while limiting false positives, and mined signatures demonstrating 81.48\% field precision with CrowdStrike's Managed Detection and Response team.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents two ML frameworks for detecting LDAP reconnaissance in Active Directory: a classifier trained via weak supervision by correlating LDAP queries with external endpoint detections to label a large dataset (reporting up to 65% TPR on holdout while limiting false positives), and a statistical hypothesis-testing approach to mine malicious query signatures (reporting 81.48% field precision validated by CrowdStrike MDR). The work emphasizes the practicality of weak supervision for scalable, low-cost labeling over manual annotation.
Significance. If the weak labels are shown to be sufficiently accurate and unbiased, the approach could enable practical, large-scale early detection of identity reconnaissance without heavy manual effort, which is a genuine operational need in enterprise security. The real-world field validation of mined signatures is a concrete strength that supports deployability.
major comments (3)
- [Abstract] Abstract: The central performance claims (65% TPR for the classifier; 81.48% precision for signatures) rest on labels produced by correlating LDAP queries with endpoint detections. No correlation rule, label-error estimate, or expert validation of the resulting labels is described, so it is impossible to determine whether the reported metrics reflect genuine malicious patterns or artifacts of the labeling heuristic.
- [Methods/Results] Methods/Results: No details are supplied on model architecture, feature engineering for LDAP queries, holdout-set construction, or the exact statistical hypothesis tests and multiple-testing corrections used for signature mining. These omissions are load-bearing because they prevent assessment of whether the 65% TPR is reproducible or statistically supported.
- [Abstract/Results] Abstract/Results: The statement that weak supervision is 'limited compared with manual human labeling' but 'more practical' requires quantitative support on label quality; absent any reported validation (e.g., precision of the correlation step on a held-out expert-labeled subset), the performance numbers cannot be interpreted as evidence of effective detection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (65% TPR for the classifier; 81.48% precision for signatures) rest on labels produced by correlating LDAP queries with endpoint detections. No correlation rule, label-error estimate, or expert validation of the resulting labels is described, so it is impossible to determine whether the reported metrics reflect genuine malicious patterns or artifacts of the labeling heuristic.
Authors: We agree that the correlation rules and any assessment of label quality require more explicit description. In the revised manuscript we will add the exact correlation heuristic (including matching criteria between LDAP queries and endpoint detections), a discussion of observed label noise, and potential sources of bias. Expert validation on a held-out subset was not performed, as the scale of the data makes this impractical—the core motivation for weak supervision. We will note the 81.48% field precision on mined signatures as downstream validation of the pipeline. These additions will appear in the Methods section. revision: yes
-
Referee: [Methods/Results] Methods/Results: No details are supplied on model architecture, feature engineering for LDAP queries, holdout-set construction, or the exact statistical hypothesis tests and multiple-testing corrections used for signature mining. These omissions are load-bearing because they prevent assessment of whether the 65% TPR is reproducible or statistically supported.
Authors: We acknowledge that these methodological specifics were insufficiently detailed. The revised manuscript will include the model architecture, the complete feature engineering process applied to LDAP queries, the holdout-set construction procedure, and the precise statistical hypothesis tests together with the multiple-testing correction method used for signature mining. These additions will allow readers to evaluate reproducibility and statistical support for the reported metrics. revision: yes
-
Referee: [Abstract/Results] Abstract/Results: The statement that weak supervision is 'limited compared with manual human labeling' but 'more practical' requires quantitative support on label quality; absent any reported validation (e.g., precision of the correlation step on a held-out expert-labeled subset), the performance numbers cannot be interpreted as evidence of effective detection.
Authors: We agree the statement would be strengthened by quantitative context on label quality. However, an expert-labeled subset for direct precision estimation of the correlation step is not available, as creating one would require the manual effort the weak-supervision approach was designed to avoid. We will revise the abstract and discussion to qualify the claim more precisely, emphasize the independent 81.48% field precision on signatures, and report any available proxy indicators of label quality from our analysis. revision: partial
- Direct quantitative validation of weak-label precision on an expert-labeled held-out subset (such a subset does not exist in our data).
Circularity Check
No circularity: labeling uses external endpoint detections; performance measured on independent holdout
full rationale
The paper constructs weak labels by correlating LDAP queries with endpoint detections from an external source and then trains an ML classifier on those labels, reporting TPR on a holdout set. This is a standard weak-supervision pipeline with no equations, self-citations, or fitted parameters that reduce the reported performance metric to the labeling rule by construction. The derivation chain remains self-contained against the external detections and does not invoke any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Endpoint detections accurately indicate malicious activity that can be reliably correlated with LDAP queries
Reference graph
Works this paper leans on
-
[1]
Dirk-jan . 2018. BloodHound.py. https://github.com/dirkjanm/BloodHound.py Accessed 2026-02-05
2018
-
[2]
FalconForce . 2024. SOAPHound. https://github.com/FalconForceTeam/SOAPH ound Accessed 2026-02-05
2024
-
[3]
GhostPack . 2018. Rubeus. https://github.com/GhostPack/Rubeus Accessed 2026-02-05
2018
-
[4]
SpecterOps . 2021. SharpHound. https://github.com/SpecterOps/SharpHound Accessed 2026-02-05
2021
-
[5]
SpecterOps . 2023. BloodHound. https://github.com/SpecterOps/BloodHound Accessed 2026-02-05
2023
-
[6]
Dor Agron, Michael Avraham Brautbar, Shaefer Drew, Avraham Kama, Asaf Lavi, Sagi Sheinfeld, and Yaron Zinar. 2025. Machine-Learned Suspicious Query Detection. US Patent App. 18/630,106
2025
-
[7]
Sylvain Arlot and Alain Celisse. 2010. A survey of cross-validation procedures for model selection.Statistics Surveys4 (2010), 40–79
2010
-
[8]
Prasasthy Balasubramanian, Tarek Ali, Mohammad Salmani, Danial KhoshKholgh, and Panos Kostakos. 2024. Hex2Sign: Automatic IDS Signature Generation from Hexadecimal Data using LLMs. In2024 IEEE International Confer- ence on Big Data (BigData). 4524–4532. doi:10.1109/BigData62323.2024.10825710 ISSN: 2573-2978
-
[9]
James Bergstra, Brent Komer, Chris Eliasmith, Dan Yamins, and David Cox. 2015. Hyperopt: A Python library for model selection and hyperparameter optimization. Computational Science & Discovery8 (07 2015), 014008. doi:10.1088/1749-4699/8 /1/014008
-
[10]
2008.Automatisierte Signaturgenerierung für Malware- Stämme
Christian Blichmann. 2008.Automatisierte Signaturgenerierung für Malware- Stämme. Ph. D. Dissertation. Technical University of Dortmund
2008
-
[11]
Carlo Bonferroni. 1936. Teoria statistica delle classi e calcolo delle probabilita. Pubblicazioni del R Istituto Superiore di Scienze Economiche e Commericiali di Firenze8 (1936), 3–62. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Shaefer Drew et al
1936
-
[12]
Ju Chen, Jinghan Wang, Chengyu Song, and Heng Yin. 2022. JIGSAW: Efficient and Scalable Path Constraints Fuzzing. In2022 IEEE Symposium on Security and Privacy (SP). 18–35. doi:10.1109/SP46214.2022.9833796 ISSN: 2375-1207
-
[13]
Tianqi Chen. 2016. XGBoost: A Scalable Tree Boosting System.Cornell University (2016)
2016
-
[14]
1988.Statistical Power Analysis for the Behavioral Sciences(2nd ed.)
Jacob Cohen. 1988.Statistical Power Analysis for the Behavioral Sciences(2nd ed.). Lawrence Erlbaum Associates, Hillsdale, NJ
1988
-
[15]
Shaefer Drew, Mickey Brautbar, and Yaron Zinar. 2025. Caught in the Act: CrowdStrike’s New ML-Powered LDAP Reconnaissance Detections. CrowdStrike Blog. https://www.crowdstrike.com/en-us/blog/inside-crowdstrike-ml- powered-ldap-reconnaissance-detections/ Accessed: 2025-12-01
2025
-
[16]
Min Du, Wenjun Hu, and William Hewlett. 2021. AutoCombo: Automatic Mal- ware Signature Generation Through Combination Rule Mining. InProceedings of the 30th ACM International Conference on Information & Knowledge Manage- ment (CIKM ’21). Association for Computing Machinery, New York, NY, USA, 3777–3786. doi:10.1145/3459637.3481896
-
[17]
Jerome H. Friedman. 2001. Greedy function approximation: A gradient boosting machine.The Annals of Statistics29, 5 (2001), 1189 – 1232. doi:10.1214/aos/1013 203451
-
[18]
Sture Holm. 1979. A simple sequentially rejective multiple test procedure.Scan- dinavian Journal of Statistics6, 2 (1979), 65–70
1979
-
[19]
Maya Kapoor, Garrett Fuchs, and Jonathan Quance. 2021. RExACtor: Automatic Regular Expression Signature Generation for Stateless Packet Inspection. In2021 IEEE 20th International Symposium on Network Computing and Applications (NCA). 1–9. doi:10.1109/NCA53618.2021.9685959 ISSN: 2643-7929
-
[20]
Hyang-Ah Kim and Brad Karp. 2004. Autograph: toward automated, distributed worm signature detection. InProceedings of the 13th conference on USENIX Security Symposium - Volume 13. 19. doi:10.1.1.94.5342
2004
-
[21]
Shijia Li, Jiang Ming, Pengda Qiu, Qiyuan Chen, Lanqing Liu, Huaifeng Bao, Qiang Wang, and Chunfu Jia. 2023. PackGenome: Automatically Generating Robust YARA Rules for Accurate Malware Packer Detection. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (CCS ’23). Association for Computing Machinery, New York, NY, USA,...
-
[22]
James Newsome, Brad Karp, and Dawn Song. 2005. Polygraph: Automatically Generating Signatures for Polymorphic Worms. InProceedings of the 2005 IEEE Symposium on Security and Privacy. IEEE Computer Society, Washington, DC, USA, 226–241. doi:10.1109/SP.2005.15 Series Title: SP ’05
-
[23]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cour- napeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research12 (2011), 2825–2830
2011
-
[24]
Sayan Putatunda and Dr Kiran R. 2018. A Comparative Analysis of Hyperopt as Against Other Approaches for Hyper-Parameter Optimization of XGBoost. SPML ’18: Proceedings of the 2018 International Conference on Signal Processing and Machine Learning, 6–10. doi:10.1145/3297067.3297080
-
[25]
An- derson, Bobby Filar, Charles Nicholas, and James Holt
Edward Raff, Richard Zak, Gary Lopez Munoz, William Fleming, Hyrum S. An- derson, Bobby Filar, Charles Nicholas, and James Holt. 2020. Automatic Yara Rule Generation Using Biclustering. In13th ACM Workshop on Artificial Intelligence and Security (AISec’20). doi:10.1145/3411508.3421372 arXiv: 2009.03779
-
[26]
M Zubair Rafique and Juan Caballero. 2013. FIRMA: Malware Clustering and Network Signature Generation with Mixed Network Behaviors. InProceedings of the 16th International Symposium on Research in Attacks, Intrusions, and Defenses - Volume 8145. Springer-Verlag New York, Inc., New York, NY, USA, 144–163. doi:10.1007/978-3-642-41284-4_8 Series Title: RAID 2013
-
[27]
H., Ehrenberg, H., Fries, J., Wu, S., and Ré, C
Alexander Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. 2017. Snorkel: rapid training data creation with weak supervision.Proceedings of the VLDB Endowment11, 3 (Nov. 2017), 269–282. doi:10.14778/3157794.3157797
-
[28]
Team Snorkel. 2022. Weak Supervision Modeling with Fred Sala. https://snorke l.ai/blog/weak-supervision-modeling/
2022
-
[29]
Shobha Venkataraman, Avrim Blum, and Dawn Song. 2008. Limits of Learning- based Signature Generation with Adversaries. InNDSS. http://repository.cmu.e du/ece
2008
-
[30]
1993.Resampling-based multiple testing: Examples and methods for p-value adjustment
Peter H Westfall and S Stanley Young. 1993.Resampling-based multiple testing: Examples and methods for p-value adjustment. John Wiley & Sons
1993
-
[31]
Edwin B. Wilson. 1927. Probable Inference, the Law of Succession, and Statistical Inference.J. Amer. Statist. Assoc.22, 158 (1927), 209–212. doi:10.1080/01621459.1 927.10502953
-
[32]
Vinod Yegneswaran, Jonathon T Giffin, Paul Barford, and Somesh Jha. 2005. An Architecture for Generating Semantics-aware Signatures. InProceedings of the 14th Conference on USENIX Security Symposium - Volume 14. USENIX Association, Berkeley, CA, USA, 7. http://dl.acm.org/citation.cfm?id=1251398.1251405 Series Title: SSYM’05
-
[33]
XiangRui Zhang, XueJie Du, HaoYu Chen, Yongzhong He, Wenjia Niu, and Qiang Li. 2025. Automatically Generating Rules of Malicious Software Packages via Large Language Model. In2025 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 734–747. doi:10.1109/DSN64029.2025. 00072 ISSN: 2158-3927. A LDAP Tutorial The dataset c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.