SICI: A Semantic-Pragmatic Complexity Index Reveals Regime Shifts in LLM Stance Detection
Pith reviewed 2026-06-27 06:44 UTC · model grok-4.3
The pith
As semantic-pragmatic complexity rises, LLM stance detection errors shift from over-attribution to abstention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
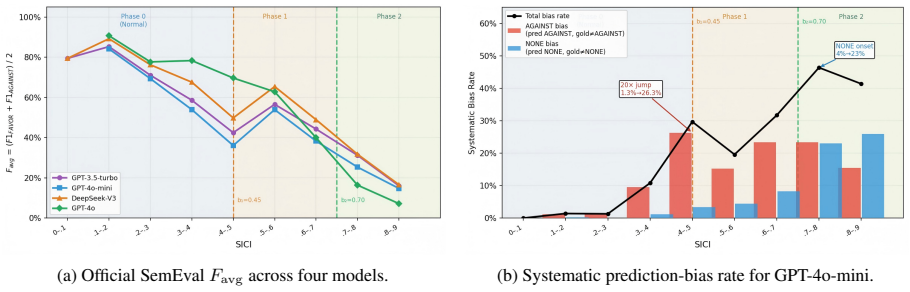
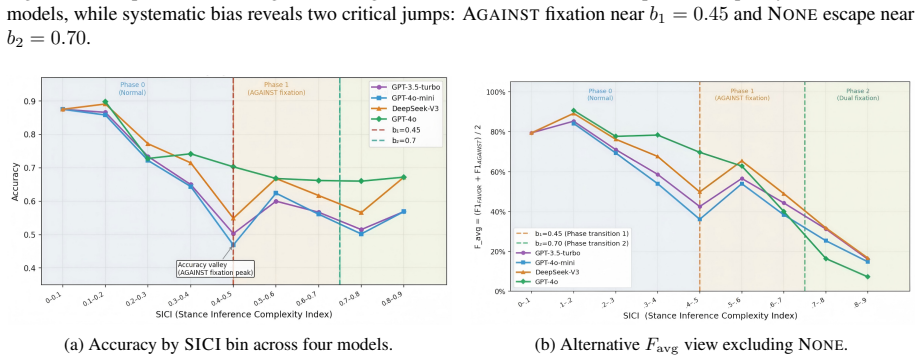
SICI reveals that LLM errors in stance detection undergo regime shifts with increasing complexity: low SICI examples prompt excessive Against attributions, intermediate ones create boundary instability, and high SICI examples lead to rapid concentration on None predictions. This phase-transition structure holds across GPT-3.5, GPT-4o-mini, DeepSeek-V3, and GPT-4o, with model strength shifting the transition points. SICI also outperforms surface features in predicting accuracy and exhibits reliable scoring.
What carries the argument
SICI, the Stance Inference Complexity Index, a seven-dimensional diagnostic of semantic-pragmatic burden on target-text pairs that predicts accuracy and error types.
If this is right
- LLM accuracy declines in phases aligned with SICI levels rather than gradually.
- Stronger models extend the low-error regime to higher SICI values.
- Interventions like retrieval and debate primarily alter the attribution-abstention balance instead of resolving complex cases.
- SICI provides a better predictor of performance than simple text features.
Where Pith is reading between the lines
- If SICI generalizes, it could guide the creation of more robust training data by balancing complexity levels.
- The intermediate unstable zone might be a target for specialized reasoning techniques.
- Future models could incorporate explicit complexity estimation to adjust confidence thresholds.
Load-bearing premise
The seven dimensions of SICI capture genuine semantic-pragmatic burden independent of specific model behaviors or dataset quirks.
What would settle it
Finding that error distributions remain uniform across SICI bins in a new model or that SICI correlates no better with accuracy than random features would disprove the regime-shift claim.
Figures
read the original abstract
Prompt-based LLMs are increasingly used for stance detection, but harder examples are not always repaired by clearer instructions, reasoning prompts, retrieval, or debate. We introduce SICI (Stance Inference Complexity Index), a seven-dimensional diagnostic measure of the semantic-pragmatic burden imposed by a target--text pair. Across SemEval-2016 and VAST, SICI predicts LLM accuracy better than surface proxies and shows substantial cross-scorer reliability ($\alpha=0.771$). More importantly, LLM errors change regime as SICI increases: low-complexity examples invite over-attribution, especially Against predictions; intermediate examples form an unstable boundary; and high-complexity examples rapidly concentrate on None. This phase-transition-like structure persists across GPT-3.5, GPT-4o-mini, DeepSeek-V3, and GPT-4o, although stronger models move the boundaries. A 15-method intervention study further shows that prompting, retrieval, and debate often shift models along the attribution--abstention axis rather than removing the high-complexity bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SICI, a seven-dimensional index of semantic-pragmatic complexity for target-text pairs in stance detection. It reports that SICI predicts LLM accuracy better than surface proxies, achieves cross-scorer reliability of α=0.771, and reveals regime shifts in errors: over-attribution (especially Against) at low SICI, instability at intermediate levels, and concentration on None at high SICI. This structure holds across GPT-3.5, GPT-4o-mini, DeepSeek-V3, and GPT-4o (with stronger models shifting boundaries), and a 15-method intervention study indicates that prompting, retrieval, and debate typically move models along the attribution-abstention axis without eliminating the high-complexity bottleneck.
Significance. If the seven dimensions prove to measure intrinsic burden independent of model artifacts or dataset biases, the work supplies a diagnostic tool for LLM limitations in stance detection that could inform targeted interventions. Credit is due for the multi-model consistency test, the scale of the 15-method intervention study, and the reported inter-rater reliability coefficient, all of which strengthen the empirical basis for the regime-shift observations.
major comments (3)
- [Abstract] Abstract: The seven dimensions of SICI are neither listed nor operationally defined. This is load-bearing for the regime-shift claim because the central assertion that low-SICI examples invite over-attribution and high-SICI examples concentrate on None requires that the dimensions isolate semantic-pragmatic burden rather than features already correlated with LLM abstention or label distributions in SemEval/VAST.
- [Results] Results (accuracy prediction and regime analysis): No error bars, confidence intervals, exclusion criteria, or sample sizes are supplied for the accuracy comparisons or the SICI-stratified error distributions. Without these, the statistical support for the phase-transition-like structure across models cannot be evaluated.
- [Methods] Methods (SICI construction): The cross-scorer reliability (α=0.771) is reported without details on scorer instructions, blinding to model outputs or gold labels, or how dimensions were selected. This leaves open the possibility that dimension scoring incorporates the same error patterns later used to identify regimes, rendering the index potentially circular.
minor comments (2)
- [Abstract] Abstract: The phrase 'phase-transition-like structure' is introduced without reference to a quantitative test or figure that defines the regime boundaries.
- Throughout: Surface proxies used for the superiority claim are not enumerated, reducing reproducibility of the comparative result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, with revisions indicated where the manuscript will be updated to improve clarity and statistical rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The seven dimensions of SICI are neither listed nor operationally defined. This is load-bearing for the regime-shift claim because the central assertion that low-SICI examples invite over-attribution and high-SICI examples concentrate on None requires that the dimensions isolate semantic-pragmatic burden rather than features already correlated with LLM abstention or label distributions in SemEval/VAST.
Authors: We agree that the abstract should list the seven dimensions with brief operational definitions to support the regime-shift claims. The full manuscript defines them in Section 3 based on semantic-pragmatic theory. We will revise the abstract to include this information. The dimensions were derived independently of model outputs or label distributions, as confirmed by their consistent predictive performance and regime patterns across four distinct LLMs. revision: yes
-
Referee: [Results] Results (accuracy prediction and regime analysis): No error bars, confidence intervals, exclusion criteria, or sample sizes are supplied for the accuracy comparisons or the SICI-stratified error distributions. Without these, the statistical support for the phase-transition-like structure across models cannot be evaluated.
Authors: The referee correctly identifies that the submitted version lacks these statistical details. We will revise the Results section to report bootstrap-derived 95% confidence intervals for accuracy predictions, exact sample sizes per SICI stratum, and explicit exclusion criteria (e.g., for low inter-rater agreement cases). This will allow proper evaluation of the regime-shift observations. revision: yes
-
Referee: [Methods] Methods (SICI construction): The cross-scorer reliability (α=0.771) is reported without details on scorer instructions, blinding to model outputs or gold labels, or how dimensions were selected. This leaves open the possibility that dimension scoring incorporates the same error patterns later used to identify regimes, rendering the index potentially circular.
Authors: We will expand the Methods section to include the full scorer instructions, explicit blinding procedures (scorers had no access to model outputs or gold labels), and the dimension selection process grounded in linguistic theory and pilot annotations conducted prior to LLM error analysis. This sequence was designed to prevent circularity, with reliability computed on independent scorings. revision: yes
Circularity Check
No circularity: SICI introduced without equations or self-referential derivation in abstract
full rationale
The provided abstract introduces SICI as a seven-dimensional measure, reports α=0.771 reliability and better prediction of LLM accuracy than surface proxies, and describes regime shifts in errors. No equations, derivation steps, parameter-fitting procedures, or citations are supplied that would permit inspection of self-definition, fitted-input-as-prediction, or load-bearing self-citation chains. Absent any quoted reduction of the claimed phase-transition structure to the index's own construction or to model error patterns used in its definition, the derivation is self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages=
Semeval-2016 task 6: Detecting stance in tweets , author=. Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages=
2016
-
[2]
Information Processing & Management , volume =
Stance detection on social media: State of the art and trends , author =. Information Processing & Management , volume =. 2021 , doi =
2021
-
[3]
Tree-of-Counterfactual Prompting for Zero-Shot Stance Detection
Weinzierl, Maxwell and Harabagiu, Sanda. Tree-of-Counterfactual Prompting for Zero-Shot Stance Detection. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.49
-
[4]
Stance Reasoner: Zero-Shot Stance Detection on Social Media with Explicit Reasoning
Taranukhin, Maksym and Shwartz, Vered and Milios, Evangelos. Stance Reasoner: Zero-Shot Stance Detection on Social Media with Explicit Reasoning. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[5]
LLM -Driven Knowledge Injection Advances Zero-Shot and Cross-Target Stance Detection
Zhang, Zhao and Li, Yiming and Zhang, Jin and Xu, Hui. LLM -Driven Knowledge Injection Advances Zero-Shot and Cross-Target Stance Detection. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.naacl-short.32
-
[6]
Zhang, ZhaoDan and Zhang, Jin and Xu, Hui and Guo, Jiafeng and Cheng, Xueqi , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.24 , pages =
-
[7]
Ji, Yanxu and Ning, Jinzhong and Zhang, Yijia and Liu, Zhi and Lin, Hongfei , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.299 , pages =
-
[8]
Dubreuil, Anthony and Gourru, Antoine and Largeron, Christine and Trabelsi, Amine , booktitle =. Are Stereotypes Leading. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.1605 , pages =
-
[9]
McKeown , title =
Emily Allaway and Kathleen R. McKeown , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
2020
-
[10]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
P-stance: A large dataset for stance detection in political domain , author=. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
2021
-
[11]
Multi-target stance detection via a dynamic memory-augmented network , Year =
Wei, Penghui and Lin, Junjie and Mao, Wenji , Booktitle =. Multi-target stance detection via a dynamic memory-augmented network , Year =
-
[12]
IEEE Transactions on Computational Social Systems , year=
Improved target-specific stance detection on social media platforms by delving into conversation threads , author=. IEEE Transactions on Computational Social Systems , year=
-
[13]
Li, Yupeng and Wen, Dacheng and He, Haorui and Guo, Jianxiong and Ning, Xuan and Lau, Francis C. M. , booktitle=. Contextual Target-Specific Stance Detection on Twitter: Dataset and Method , year=
-
[14]
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence,
Jiachen Du and Ruifeng Xu and Yulan He and Lin Gui , title =. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence,
-
[15]
Modeling Transferable Topics for Cross-Target Stance Detection , Year =
Wei, Penghui and Mao, Wenji , Booktitle =. Modeling Transferable Topics for Cross-Target Stance Detection , Year =
-
[16]
Proceedings of the Web Conference 2021 , pages=
Target-adaptive graph for cross-target stance detection , author=. Proceedings of the Web Conference 2021 , pages=
2021
-
[17]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Enhancing cross-target stance detection with transferable semantic-emotion knowledge , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[18]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019
2019
-
[19]
Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations,. 2020 , url =. doi:10.18653/v1/2020.emnlp-demos.2 , timestamp =
-
[20]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
Enhancing zero-shot and few-shot stance detection with commonsense knowledge graph , author=. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
2021
-
[21]
Stance Detection on Social Media with Background Knowledge
Li, Ang and Liang, Bin and Zhao, Jingqian and Zhang, Bowen and Yang, Min and Xu, Ruifeng. Stance Detection on Social Media with Background Knowledge. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.972
-
[22]
Mathematics , VOLUME =
Ding, Daijun and Fu, Xianghua and Peng, Xiaojiang and Fan, Xiaomao and Huang, Hu and Zhang, Bowen , TITLE =. Mathematics , VOLUME =. 2024 , NUMBER =
2024
-
[23]
Proceedings of the ACM Web Conference 2022 , pages=
Zero-Shot Stance Detection via Contrastive Learning , author=. Proceedings of the ACM Web Conference 2022 , pages=
2022
-
[24]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Adversarial Learning for Zero-Shot Stance Detection on Social Media , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2021
-
[25]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
IEEE Transactions on Computational Social Systems , year=
Knowledge-augmented interpretable network for zero-shot stance detection on social media , author=. IEEE Transactions on Computational Social Systems , year=
-
[27]
Information Fusion , volume=
Logic Augmented Multi-Decision Fusion framework for stance detection on social media , author=. Information Fusion , volume=. 2025 , publisher=
2025
-
[28]
Proceedings of the 29th international conference on computational linguistics , pages=
Sentiment interpretable logic tensor network for aspect-term sentiment analysis , author=. Proceedings of the 29th international conference on computational linguistics , pages=
-
[29]
Chain-of-Thought Embeddings for Stance Detection on Social Media
Gatto, Joseph and Sharif, Omar and Preum, Sarah. Chain-of-Thought Embeddings for Stance Detection on Social Media. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.273
-
[30]
Mathematics , VOLUME =
Ding, Daijun and Dai, Genan and Peng, Cheng and Peng, Xiaojiang and Zhang, Bowen and Huang, Hu , TITLE =. Mathematics , VOLUME =. 2024 , NUMBER =
2024
-
[31]
arXiv preprint arXiv:2206.07682 , year=
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.