HANCLIP: A Family of Hyperbolic Angular Negation Vision Language Models
Pith reviewed 2026-06-26 08:47 UTC · model grok-4.3
The pith
HANCLIP restructures vision-language embeddings with hyperbolic geometry and angular separation to encode negation without overwriting pretrained knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HANCLIP restructures the embedding space of vision-language models with a hyperbolic formulation that models hierarchical semantic relations and asymmetries, together with an angular triplet objective that drives systematic separation between negated descriptions and their corresponding positives, allowing the model to encode what an image is not alongside what it is using only 20,000 quadruplets.
What carries the argument
Hyperbolic embedding space combined with an angular triplet loss that separates negated from positive descriptions.
If this is right
- Consistent gains appear on the negation-focused NegBench benchmark.
- Performance stays competitive or improves on standard classification and image-text retrieval benchmarks.
- The same training procedure attaches to CLIP, LongCLIP, SmartCLIP, and HiMo-CLIP without large-scale retraining.
Where Pith is reading between the lines
- Targeted geometric objectives may prove more data-efficient than additional scale for adding specific reasoning skills to existing models.
- The same hyperbolic-plus-angular pattern could extend to other logical constructs such as conjunction or quantification in vision-language settings.
- Incremental geometric fine-tuning offers a route for extending model capabilities without full retraining cycles.
Load-bearing premise
The hyperbolic formulation and angular triplet objective strengthen negation sensitivity while preserving the global structure of pretrained representations rather than overwriting them.
What would settle it
A clear drop in performance on standard classification or retrieval benchmarks after the 20k-quadruplet training would show that the preservation of pretrained structure does not hold.
Figures
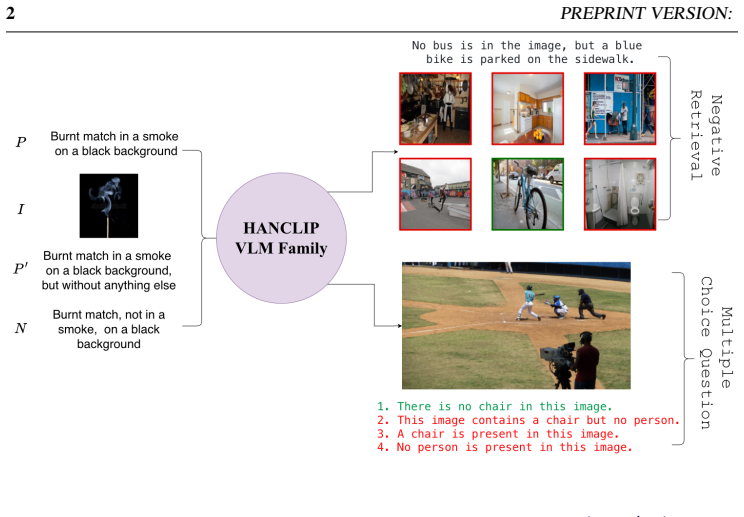
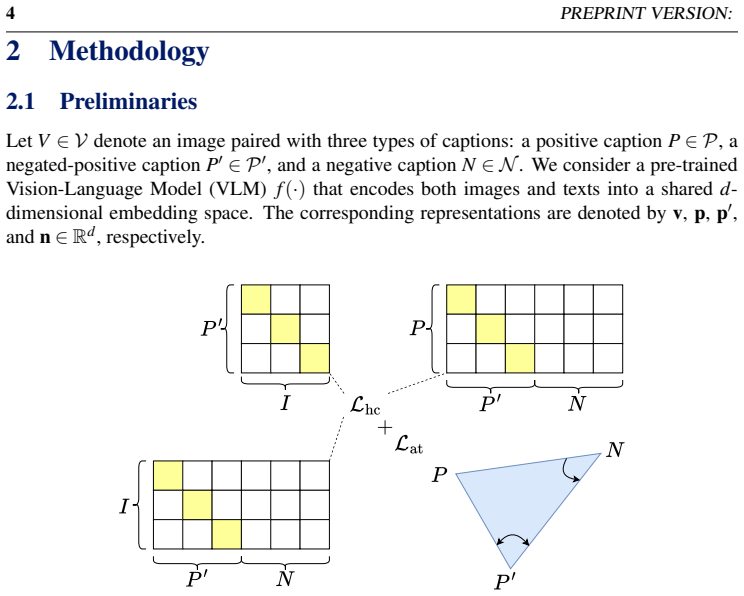
read the original abstract
Vision-Language Models (VLMs) are typically pre-trained on large-scale image-text datasets to capture semantic correspondences between visual content and natural language. However, they remain surprisingly brittle to negation: models often rely on shallow word co-occurrence and are easily distracted by misleading or irrelevant textual cues, even when their overall retrieval or classification performance is strong. Moreover, directly finetuning on negation data can interfere with previously acquired knowledge, causing noticeable degradation on standard vision-language benchmarks. To tackle these issues, this work introduces HANCLIP (Hyperbolic + Angular + Negation), a family of VLMs that explicitly restructures the embedding space to encode "what an image is not" alongside "what it is." HANCLIP is trained on a compact set of 20,000 image-text quadruplets and combines a hyperbolic formulation, which models hierarchical semantic relations and asymmetries, with an angular triplet objective that drives systematic separation between negated descriptions and their corresponding positives. This geometry-aware design strengthens negation sensitivity while preserving the global structure of pretrained representations, rather than overwriting them. Extensive experiments across multiple vision-language tasks show that HANCLIP delivers consistent gains on the negation-focused NegBench benchmark, while maintaining competitive or improved performance on standard classification and image-text retrieval benchmarks. The framework is model-agnostic and can be plugged into CLIP, LongCLIP, SmartCLIP, and HiMo-CLIP without large-scale retraining, demonstrating that a carefully designed geometric objective can substantially extend the reasoning capabilities of existing VLMs using only modest additional data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HANCLIP, a family of vision-language models that augment pretrained VLMs (CLIP, LongCLIP, etc.) with a hyperbolic embedding formulation and an angular triplet loss. Trained on only 20k image-text quadruplets, the method is claimed to improve negation sensitivity on NegBench while preserving or improving performance on standard classification and retrieval benchmarks, without the degradation typically seen from direct fine-tuning on negation data. The framework is presented as model-agnostic and geometry-aware.
Significance. If the central empirical claims hold under controlled conditions, the work would be significant for demonstrating that a compact, geometry-specific objective can address a known limitation (negation brittleness) in VLMs without large-scale retraining or catastrophic forgetting. The model-agnostic plug-in design and modest data requirement would be practically useful if the hyperbolic-plus-angular combination is shown to be necessary rather than incidental.
major comments (2)
- [Experiments] Experiments section: the central attribution—that the combination of hyperbolic geometry and angular triplet objective (rather than either component alone or standard fine-tuning) produces the reported NegBench gains while preserving global structure—requires controlled ablations. The manuscript reports only the joint HANCLIP model; no Euclidean angular-triplet baseline or hyperbolic contrastive-loss baseline on the identical 20k quadruplets and base models is described. This leaves the synergy claim untested and the preservation argument resting on absence of degradation rather than a direct demonstration.
- [§3] §3 (method) and Table X (results): the claim that the approach is 'parameter-free' or that the hyperbolic component specifically enables preservation of pretrained structure is not supported by any quantitative isolation of the curvature parameter or the angular margin; if these quantities are fitted or chosen post-hoc on the same data used for evaluation, the reported improvements risk circularity with respect to the NegBench test distribution.
minor comments (2)
- [Abstract] Abstract: the phrase 'without large-scale retraining' is repeated but the exact training regime (optimizer, learning rate schedule, number of epochs, whether the backbone is frozen) is not stated; this detail belongs in §4 or the appendix for reproducibility.
- [§3] Notation: the definition of the angular triplet loss and its hyperbolic counterpart should be given explicitly with all symbols (e.g., margin, curvature) before the experimental claims; the current description is high-level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger attribution of the reported gains and clarification on parameter handling. We address each major comment below and commit to revisions that directly strengthen the empirical claims without overstating the current manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central attribution—that the combination of hyperbolic geometry and angular triplet objective (rather than either component alone or standard fine-tuning) produces the reported NegBench gains while preserving global structure—requires controlled ablations. The manuscript reports only the joint HANCLIP model; no Euclidean angular-triplet baseline or hyperbolic contrastive-loss baseline on the identical 20k quadruplets and base models is described. This leaves the synergy claim untested and the preservation argument resting on absence of degradation rather than a direct demonstration.
Authors: We agree that the current manuscript lacks the requested controlled ablations, which limits the strength of the attribution to the specific combination of components. In the revised version we will add results for an Euclidean angular-triplet baseline and a hyperbolic contrastive-loss baseline, each trained on the exact same 20k quadruplets and base models (CLIP, LongCLIP, etc.). These additional experiments will allow direct comparison of the joint HANCLIP objective against its constituent parts and against standard fine-tuning, thereby testing the claimed synergy and providing positive evidence for preservation of global structure rather than relying solely on lack of degradation. revision: yes
-
Referee: [§3] §3 (method) and Table X (results): the claim that the approach is 'parameter-free' or that the hyperbolic component specifically enables preservation of pretrained structure is not supported by any quantitative isolation of the curvature parameter or the angular margin; if these quantities are fitted or chosen post-hoc on the same data used for evaluation, the reported improvements risk circularity with respect to the NegBench test distribution.
Authors: The manuscript does not claim the method is strictly parameter-free; the curvature is fixed at the conventional value of −1 and the angular margin is selected via a small held-out validation split drawn from the 20k quadruplets that does not overlap with NegBench. Nevertheless, we acknowledge that the current text provides insufficient quantitative isolation of these choices. In revision we will add a dedicated sensitivity analysis (new table or figure) reporting performance across a range of curvature values and margin settings on the validation split, together with explicit confirmation that no test-set information from NegBench was used for selection. This will remove any appearance of circularity and directly support the claim that the hyperbolic formulation aids preservation. revision: yes
Circularity Check
No circularity: empirical training objective with no self-referential derivations
full rationale
The paper presents HANCLIP as an additive training framework (hyperbolic formulation + angular triplet objective on 20k quadruplets) that is plugged into existing VLMs. No equations, fitted parameters, or first-principles derivations appear in the provided text that would reduce any claimed result to a definition or input by construction. Performance gains on NegBench and preservation on standard benchmarks are reported as experimental outcomes rather than mathematical identities. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in a way that collapses the central claim. The derivation chain is therefore self-contained as a new objective function whose effects are measured externally.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hyperbolic geometry models hierarchical semantic relations and asymmetries in vision-language embeddings.
- domain assumption An angular triplet objective produces systematic separation between negated descriptions and positives without destroying pretrained global structure.
Reference graph
Works this paper leans on
-
[1]
Lorenzo Agnolucci, Alberto Baldrati, Alberto Del Bimbo, and Marco Bertini. iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval .IEEE Transactions on Pattern Analysis & Machine Intelligence, 47, 2025. doi: 10.1109/TPAMI.2025.3593539
-
[2]
Vision-language models do not understand nega- tion
Kumail Alhamoud, Shaden Alshammari, Yonglong Tian, Guohao Li, Philip HS Torr, Yoon Kim, and Marzyeh Ghassemi. Vision-language models do not understand nega- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29612–29622, 2025
2025
-
[3]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision, pages 370–387. Springer, 2024
2024
-
[4]
Hyperbolic image-text representations
Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, and Shan- mukha Ramakrishna Vedantam. Hyperbolic image-text representations. InInterna- tional Conference on Machine Learning, pages 7694–7731. PMLR, 2023
2023
-
[5]
Doodle to search: Practical zero-shot sketch-based image retrieval
Sounak Dey, Pau Riba, Anjan Dutta, Josep Llados, and Yi-Zhe Song. Doodle to search: Practical zero-shot sketch-based image retrieval. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2179–2188, 2019
2019
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- 16PREPRINT VERSION: vain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2020
2020
-
[7]
Teaching structured vision & language concepts to vision & language models
Sivan Doveh, Assaf Arbelle, Sivan Harary, Eli Schwartz, Roei Herzig, Raja Giryes, Rogerio Feris, Rameswar Panda, Shimon Ullman, and Leonid Karlinsky. Teaching structured vision & language concepts to vision & language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2657– 2668, 2023
2023
-
[8]
Sugarcrepe++ dataset: Vision-language model sensi- tivity to semantic and lexical alterations.Advances in Neural Information Processing Systems, 37:17972–18018, 2024
Sri Harsha Dumpala, Aman Jaiswal, Chandramouli Shama Sastry, Evangelos Milios, Sageev Oore, and Hassan Sajjad. Sugarcrepe++ dataset: Vision-language model sensi- tivity to semantic and lexical alterations.Advances in Neural Information Processing Systems, 37:17972–18018, 2024
2024
-
[9]
Hyperbolic vision transformers: Combining improvements in metric learning
Aleksandr Ermolov, Leyla Mirvakhabova, Valentin Khrulkov, Nicu Sebe, and Ivan Os- eledets. Hyperbolic vision transformers: Combining improvements in metric learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 7409–7419, 2022
2022
-
[10]
Mitigate the gap: Improving cross-modal align- ment in CLIP
Sedigheh Eslami and Gerard de Melo. Mitigate the gap: Improving cross-modal align- ment in CLIP. InThe Thirteenth International Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=aPTGvFqile
2025
-
[11]
SimCSE: Simple contrastive learn- ing of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learn- ing of sentence embeddings. InEmpirical Methods in Natural Language Processing (EMNLP), pages 6894–6910, Online and Punta Cana, Dominican Republic, 2021. As- sociation for Computational Linguistics
2021
-
[12]
Cyclip: Cyclic contrastive language-image pretraining
Shashank Goel, Hritik Bansal, Sumit Bhatia, Ryan Rossi, Vishwa Vinay, and Aditya Grover. Cyclip: Cyclic contrastive language-image pretraining. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 6704–6719, 2022
2022
-
[13]
Haochen Han, Alex Jinpeng Wang, Fangming Liu, and Jun Zhu. Negation-aware test- time adaptation for vision-language models.arXiv preprint arXiv:2507.19064, 2025
arXiv 2025
-
[14]
Nguyen Binh, Zhou Liting, and Gurrin Cathal
Le Hoang-Bao, Tran Allie, T. Nguyen Binh, Zhou Liting, and Gurrin Cathal. Union: A lightweight target representation for efficient image-guided retrieval with optional textual queries. In2025 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, 2025
2025
-
[15]
Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality
Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kembhavi, and Ranjay Krishna. Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. In Thirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[16]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. PREPRINT VERSION:17
2022
-
[17]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
2021
-
[18]
Learning multiple layers of features from tiny images.(2009), 2009
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images.(2009), 2009
2009
-
[19]
Nguyen, Liting Zhou, and Cathal Gurrin
Hoang-Bao Le, Allie Tran, Binh T. Nguyen, Liting Zhou, and Cathal Gurrin. Figrotd: A friendly-to-handle dataset for image guided retrieval with optional text. InMultiMedia Modeling, pages 117–132, Singapore, 2026. Springer Nature Singapore
2026
-
[20]
Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InICML, 2022
2022
-
[21]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[22]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. URLhttps://arxiv.org/ abs/1405.0312
Pith/arXiv arXiv 2015
-
[23]
Deep sketch hash- ing: Fast free-hand sketch-based image retrieval
Li Liu, Fumin Shen, Yuming Shen, Xianglong Liu, and Ling Shao. Deep sketch hash- ing: Fast free-hand sketch-based image retrieval. InProceedings of the IEEE confer- ence on computer vision and pattern recognition, pages 2862–2871, 2017
2017
-
[24]
C-clip: Multimodal continual learning for vision-language model
Wenzhuo Liu, Fei Zhu, Longhui Wei, and Qi Tian. C-clip: Multimodal continual learning for vision-language model. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
Zero- shot composed text-image retrieval
Yikun Liu, Jiangchao Yao, Ya Zhang, Yan-Feng Wang, and Weidi Xie. Zero- shot composed text-image retrieval. InBMVC, page 381, 2023. URLhttp: //proceedings.bmvc2023.org/381/
2023
-
[26]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[27]
Compositional entailment learning for hyperbolic vision-language models
Avik Pal, Max van Spengler, Guido Maria D’Amely di Melendugno, Alessandro Fla- borea, Fabio Galasso, and Pascal Mettes. Compositional entailment learning for hyperbolic vision-language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025. URL https://openreview.net/forum?id=3i13Gev2hV
2025
-
[28]
Cross- domain adversarial feature learning for sketch re-identification
Lu Pang, Yaowei Wang, Yi-Zhe Song, Tiejun Huang, and Yonghong Tian. Cross- domain adversarial feature learning for sketch re-identification. InProceedings of the 26th ACM international conference on Multimedia, pages 609–617, 2018. 18PREPRINT VERSION:
2018
-
[29]
Know ”no” better: A data-driven approach for enhancing negation awareness in clip
Junsung Park, Jungbeom Lee, Jongyoon Song, Sangwon Yu, Dahuin Jung, and Sungroh Yoon. Know ”no” better: A data-driven approach for enhancing negation awareness in clip. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2825–2835, October 2025
2025
-
[30]
Ins- detclip: Aligning detection model to follow human-language instruction
Renjie Pi, Lewei Yao, Jianhua Han, Xiaodan Liang, Wei Zhang, and Hang Xu. Ins- detclip: Aligning detection model to follow human-language instruction. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational confer- ence on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[32]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115 (3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115 (3):211–252, 2015
2015
-
[33]
Learning the power of ”no”: Foundation models with negations
Jaisidh Singh, Ishaan Shrivastava, Mayank Vatsa, Richa Singh, and Aparna Bharati. Learning the power of ”no”: Foundation models with negations. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), pages 7991–8001, February 2025
2025
-
[34]
Hypervlm: Hyperbolic space guided vision language modeling for hierarchical multi-modal understanding
Sarthak Srivastava and Kathy Wu. Hypervlm: Hyperbolic space guided vision language modeling for hierarchical multi-modal understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2347–2358, 2025
2025
-
[35]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. Alpha-clip: A clip model focusing on wherever you want. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13019–13029, 2024. doi: 10.1109/CVPR52733.2024.01237
-
[36]
On the brittleness of clip text encoders.arXiv preprint arXiv:2511.04247, 2025
Allie Tran and Luca Rossetto. On the brittleness of clip text encoders.arXiv preprint arXiv:2511.04247, 2025
arXiv 2025
-
[37]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision-language encoders with improved semantic understand- ing, localization, and dense features.a...
Pith/arXiv arXiv 2025
-
[38]
Springer Na- ture, 2022
Abraham Ungar.A gyrovector space approach to hyperbolic geometry. Springer Na- ture, 2022
2022
-
[39]
The fashion iq dataset: Retrieving images by combining side information and relative natural language feedback.CVPR, 2021
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grau- man, and Rogerio Feris. The fashion iq dataset: Retrieving images by combining side information and relative natural language feedback.CVPR, 2021
2021
-
[40]
Himo-clip: Modeling semantic hierarchy and monotonicity in vision-language alignment
Ruijia Wu, Ping Chen, Fei Shen, Shaoan Zhao, Qiang Hui, Huanlin Gao, Ting Lu, Zhaoxiang Liu, Fang Zhao, Kai Wang, et al. Himo-clip: Modeling semantic hierarchy and monotonicity in vision-language alignment. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 26974–26982, 2026. PREPRINT VERSION:19
2026
-
[41]
Smartclip: Modular vision-language alignment with identifi- cation guarantees
Shaoan Xie, Lingjing Lingjing, Yujia Zheng, Yu Yao, Zeyu Tang, Eric P Xing, Guangyi Chen, and Kun Zhang. Smartclip: Modular vision-language alignment with identifi- cation guarantees. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29780–29790, 2025
2025
-
[42]
Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection.Advances in Neural Information Processing Systems, 35:9125–9138, 2022
Lewei Yao, Jianhua Han, Youpeng Wen, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, Chunjing Xu, and Hang Xu. Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection.Advances in Neural Information Processing Systems, 35:9125–9138, 2022
2022
-
[43]
Detclipv2: Scalable open-vocabulary object detection pre-training via word-region alignment
Lewei Yao, Jianhua Han, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, and Hang Xu. Detclipv2: Scalable open-vocabulary object detection pre-training via word-region alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 23497–23506, 2023
2023
-
[44]
Detclipv3: Towards versatile generative open-vocabulary object de- tection
Lewei Yao, Renjie Pi, Jianhua Han, Xiaodan Liang, Hang Xu, Wei Zhang, Zhenguo Li, and Dan Xu. Detclipv3: Towards versatile generative open-vocabulary object de- tection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27391–27401, 2024
2024
-
[45]
A zero-shot framework for sketch based image retrieval
Sasi Kiran Yelamarthi, Shiva Krishna Reddy, Ashish Mishra, and Anurag Mittal. A zero-shot framework for sketch based image retrieval. InProceedings of the European Conference on Computer Vision (ECCV), pages 300–317, 2018
2018
-
[46]
Phyclip:ℓ 1-product of hyperbolic fac- tors unifies hierarchy and compositionality in vision-language representation learning,
Daiki Yoshikawa and Takashi Matsubara. Phyclip:ℓ 1-product of hyperbolic fac- tors unifies hierarchy and compositionality in vision-language representation learning,
-
[47]
URLhttps://arxiv.org/abs/2510.08919
-
[48]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descrip- tions to visual denotations: New similarity metrics for semantic inference over event descriptions.Transactions of the association for computational linguistics, 2:67–78, 2014
2014
-
[49]
When and why vision-language models behave like bags-of-words, and what to do about it? InThe Eleventh International Conference on Learning Representations,
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it? InThe Eleventh International Conference on Learning Representations,
-
[50]
URLhttps://openreview.net/forum?id=KRLUvxh8uaX
-
[51]
Low-rank few-shot adaptation of vision- language models
Maxime Zanella and Ismail Ben Ayed. Low-rank few-shot adaptation of vision- language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 1593–1603, 2024
2024
-
[52]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 11975–11986, 2023
2023
-
[53]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. InEuropean conference on computer vision, pages 310–325. Springer, 2024. 20PREPRINT VERSION:
2024
-
[54]
Sketchnet: Sketch classification with web images
Hua Zhang, Si Liu, Changqing Zhang, Wenqi Ren, Rui Wang, and Xiaochun Cao. Sketchnet: Sketch classification with web images. InProceedings of the IEEE confer- ence on computer vision and pattern recognition, pages 1105–1113, 2016
2016
-
[55]
Magiclens: Self-supervised image retrieval with open-ended instructions
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. Magiclens: Self-supervised image retrieval with open-ended instructions. InThe Forty-first International Conference on Machine Learning (ICML), page to appear, 2024
2024
-
[56]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Le Zhang, Rabiul Awal, and Aishwarya Agrawal. Contrasting intra-modal and ranking cross-modal hard negatives to enhance visio-linguistic compositional understanding. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13774–13784, 2024. doi: 10.1109/CVPR52733.2024.01307
-
[57]
Rankclip: Ranking-consistent language-image pretraining
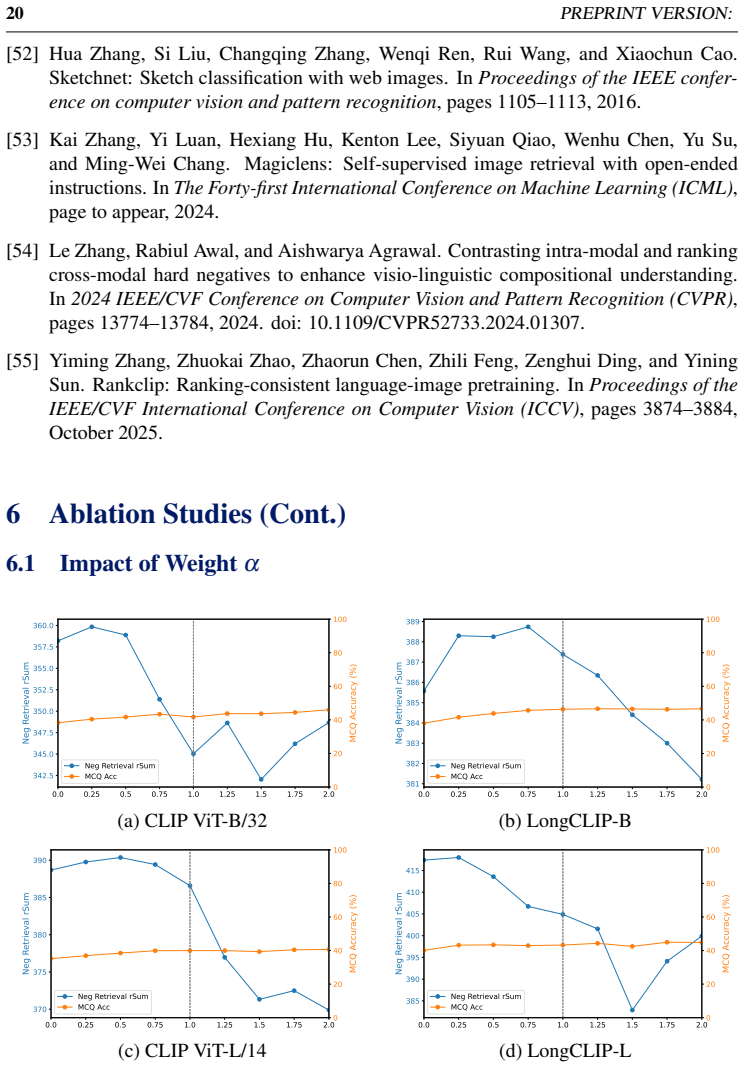
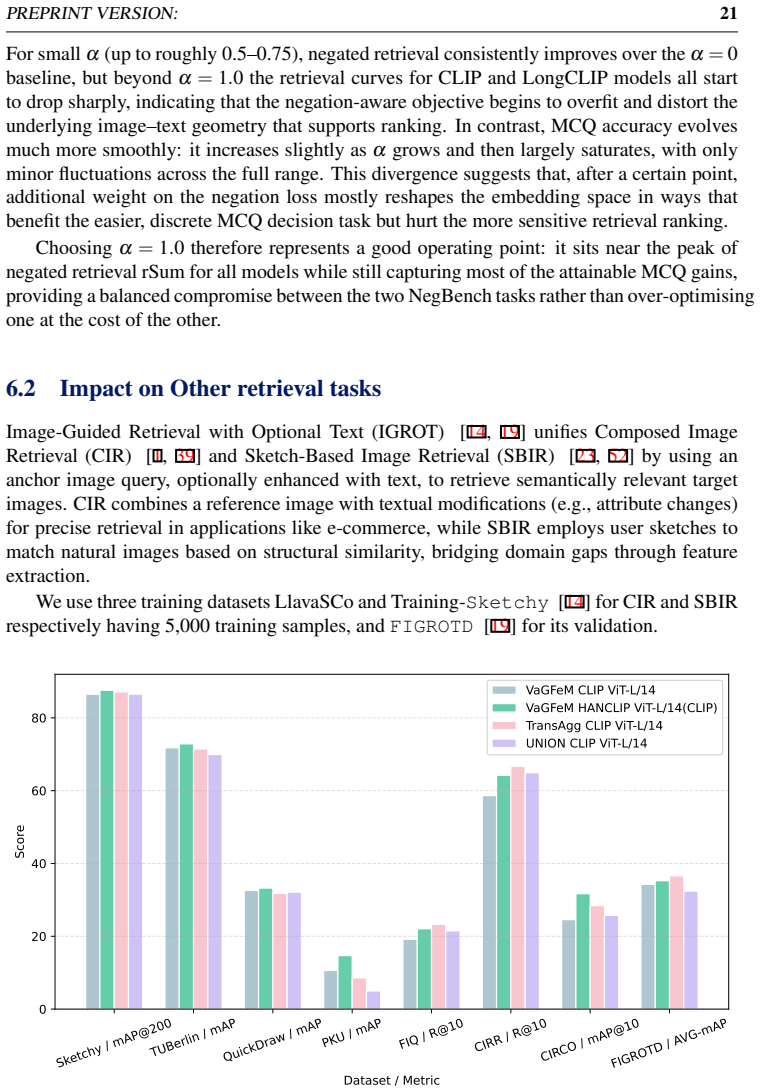
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, and Yining Sun. Rankclip: Ranking-consistent language-image pretraining. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3874–3884, October 2025. 6 Ablation Studies (Cont.) 6.1 Impact of Weightα 0.0 0.25 0.5 0.75 1.0 1.25 1.5 1.75 2.0 342.5 345.0 34...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.