CiteCheck: Retrieval-Grounded Detection of LLM Citation Hallucinations in Scientific Text
Pith reviewed 2026-06-29 13:55 UTC · model grok-4.3
The pith
CiteCheck detects LLM citation hallucinations by retrieving real publications and using a structured verifier to label them Exact, Minor, or Major.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
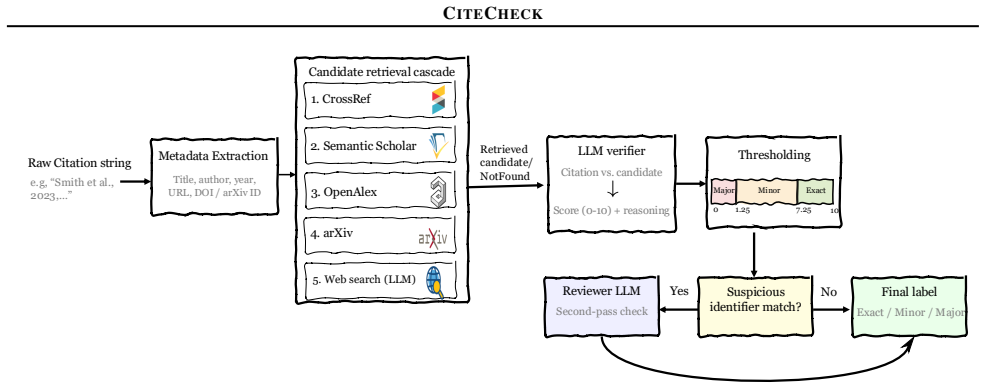
CiteCheck retrieves candidate publications from external scholarly sources, compares the citation against the retrieved candidate using a structured LLM verifier, and maps verifier scores into three labels: Exact, Minor, and Major. On the held-out test set of the 982-citation physics benchmark with controlled corruptions, CiteCheck achieves 88.7 macro-F1 and 88.9% accuracy, outperforming GPT, Claude, and Gemini baselines including web-search and few-shot variants.
What carries the argument
The hybrid framework of scholarly retrieval followed by structured LLM comparison that maps to Exact, Minor, and Major labels.
If this is right
- Citation hallucinations can be caught more reliably when external sources are used to ground the check rather than relying on model knowledge alone.
- Controlled corruptions in a benchmark provide a way to test for both subtle metadata errors and complete fabrications.
- Structured decision rules improve upon unstructured LLM judgments for citation verification.
Where Pith is reading between the lines
- The same retrieval-plus-verifier pattern could apply to citation checking in fields other than physics if suitable databases exist.
- Embedding the checker into LLM generation pipelines might prevent bad citations before they appear in output.
- Minor-issue detections could be used to suggest automatic fixes for metadata drift.
Load-bearing premise
The 982-citation physics benchmark with controlled corruptions sufficiently represents the citation hallucinations that LLMs produce when generating scientific text.
What would settle it
Evaluating CiteCheck on citations actually produced by LLMs during real scientific writing tasks and measuring agreement with verified ground-truth references.
Figures

read the original abstract
Large language models (LLMs) are increasingly used to generate scientific reports, but they can produce references that appear plausible while containing corrupted metadata or pointing to papers that do not exist. We introduce CiteCheck, a hybrid framework for citation hallucination detection that verifies whether a citation corresponds to a real scholarly work and whether its metadata is faithful to that work. CiteCheck retrieves candidate publications from external scholarly sources, compares the citation against the retrieved candidate using a structured LLM verifier, and maps verifier scores into three labels: Exact, Minor, and Major. We also construct a 982-citation physics benchmark with controlled corruptions that capture both subtle metadata drift and fully fabricated references. On the held-out test set, CiteCheck achieves 88.7 macro-F1 and 88.9% accuracy, outperforming GPT, Claude, and Gemini baselines, including web-search and few-shot variants. These results show that reliable citation verification benefits from combining scholarly retrieval, structured LLM-based comparison, and calibrated decision rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CiteCheck, a hybrid retrieval-plus-LLM framework that retrieves candidate publications from external scholarly sources, applies a structured LLM verifier to compare a citation against retrieved candidates, and maps the resulting scores to Exact/Minor/Major labels. The authors also construct a 982-citation physics benchmark whose positive and negative examples are generated by applying controlled corruptions (subtle metadata drift and fully fabricated references). On a held-out test split, CiteCheck reports 88.7 macro-F1 and 88.9% accuracy, outperforming GPT, Claude, and Gemini baselines (including web-search and few-shot variants). The central claim is that this combination yields reliable detection of citation hallucinations in scientific text.
Significance. If the benchmark distribution is representative, the work supplies a practical, retrieval-grounded method for citation verification that improves on pure LLM prompting. The explicit construction of a controlled benchmark and the head-to-head comparison against multiple LLM variants constitute a concrete, reproducible contribution that other researchers can extend.
major comments (2)
- [Benchmark Construction] Benchmark Construction (abstract and §4): the headline 88.7 macro-F1 is obtained on a held-out split of 982 synthetic examples created by a fixed set of controlled corruptions. The manuscript does not report any validation that these corruptions reproduce the error distribution of actual LLM-generated citations (e.g., citing a real but topically unrelated paper, fabricating plausible DOIs that survive retrieval, or mixing author lists across multiple real works). Without such validation the transfer claim to “scientific text” is not yet supported.
- [Evaluation] Evaluation (§5): the experimental setup, statistical tests, and potential selection biases in the 982-citation physics benchmark are not described in sufficient detail to allow independent verification of the reported macro-F1 and accuracy figures or to assess whether the held-out split preserves the corruption distribution.
minor comments (2)
- [Abstract] The abstract states performance numbers but does not mention the size of the held-out test set or the train/test split ratio; these details should be added for completeness.
- [Method] Notation for the three output labels (Exact, Minor, Major) is introduced without an explicit decision rule or threshold table; a small table or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction (abstract and §4): the headline 88.7 macro-F1 is obtained on a held-out split of 982 synthetic examples created by a fixed set of controlled corruptions. The manuscript does not report any validation that these corruptions reproduce the error distribution of actual LLM-generated citations (e.g., citing a real but topically unrelated paper, fabricating plausible DOIs that survive retrieval, or mixing author lists across multiple real works). Without such validation the transfer claim to “scientific text” is not yet supported.
Authors: We agree that the absence of direct validation against real LLM-generated citation errors is a limitation. Our controlled corruptions were designed to isolate specific failure modes (metadata drift and full fabrication), but we did not collect or compare against a corpus of actual LLM outputs with verified hallucinations. In the revised manuscript we will add an explicit discussion of this gap in §4 and the Limitations section, including why constructing such a real-world validation set is non-trivial and outlining it as future work. We do not claim the current benchmark fully replicates real distributions. revision: partial
-
Referee: [Evaluation] Evaluation (§5): the experimental setup, statistical tests, and potential selection biases in the 982-citation physics benchmark are not described in sufficient detail to allow independent verification of the reported macro-F1 and accuracy figures or to assess whether the held-out split preserves the corruption distribution.
Authors: We will expand §5 with the requested details: the precise splitting procedure and checks confirming preservation of corruption-type distributions; any statistical tests or confidence intervals computed for the metrics; and an analysis of domain-specific biases (physics-only corpus and synthetic generation). We will also release the benchmark dataset and code upon acceptance to support independent verification. revision: yes
Circularity Check
No circularity; evaluation uses external retrieval and held-out split of author-constructed benchmark
full rationale
The paper defines CiteCheck via external scholarly retrieval plus structured LLM comparison, then reports macro-F1 on a held-out test split of its 982-citation benchmark. No equations, parameters, or labels are fitted on the test data and then re-presented as predictions. No self-citations appear in the provided text, let alone load-bearing ones. The benchmark construction (controlled corruptions) is an input to evaluation rather than a derived output that loops back. The reported accuracy is a direct measurement on the held-out portion and does not reduce to any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t
doi: 10.1162/qss\ a\ 00022. Ho, X., Wu, Y .-A., Kumar, S., Xia, T. C., Boudin, F., Greiner-Petter, A., and Aizawa, A. SciClaimEval: Cross- modal Claim Verification in Scientific Papers.arXiv preprint arXiv:2602.07621, 2026. Huang, L., Feng, X., Ma, W., Gu, Y ., Zhong, W., Feng, X., Yu, W., Peng, W., Tang, D., Tu, D., et al. Learning fine- grained grounded...
work page doi:10.1162/qss 2026
-
[2]
Ignore display truncation: ‘‘...’’ at the end of titles is display formatting, not a difference .\par
-
[3]
‘‘et al.’’ is acceptable and should not be treated as an author mismatch.\par
-
[4]
Minor punctuation, capitalization, and spacing differences are not hallucinations.\par
-
[5]
Provide a score, brief reasoning, and any key differences found
Compare only the citation and retrieved source metadata; do not infer missing fields.\par\ vspace{3pt} Citation from report:\par - Authors: \{citation\_authors\}\par - Year: \{citation\_year\}\par - Title: \{citation\_title\}\par - ArXiv ID: \{citation\_arxiv\_id\}\par - URL: \{citation\_url\}\par\vspace{3pt} Best matching source, matched by \{match\_meth...
-
[6]
Your classification: one of exact\_match, minor\ _hallucination, or major\_hallucination.\par
-
[7]
Brief reasoning for your decision. C. Dataset Construction Details C.1. Physics Subdomain Coverage The citation pool is organized into 42 topically coherent collections across nine physics subdomains. Each collection corresponds to a specific theme within a subdomain, so that citations within the same collection share technical vocabu- lary and topical co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.