DCD-PFN: A Decoupling-Aware Foundation Model for Causal Discovery
Pith reviewed 2026-06-26 14:23 UTC · model grok-4.3
The pith
DCD-PFN pre-trains on synthetic SCMs to learn sample-wise decoupling weights for Markov boundary identification and zero-shot global graph reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through pre-training on diverse synthetic Structural Causal Models, DCD-PFN learns sample-wise decoupling weights that enable Markov boundary identification and efficient reconstruction of global causal graphs while achieving robust zero-shot generalization.
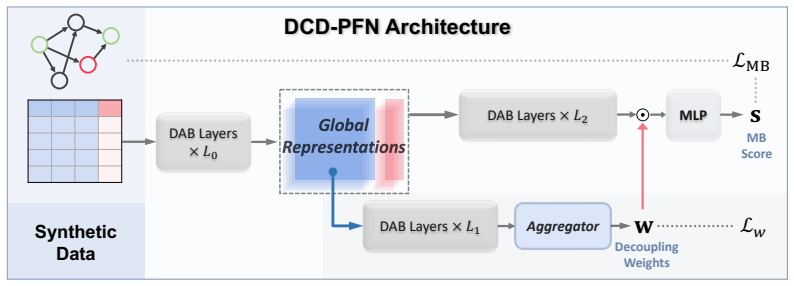
What carries the argument
The decoupling-aware PFN that outputs sample-wise decoupling weights to identify Markov boundaries.
If this is right
- Parallel local discovery removes the computational bottleneck of global search methods.
- Zero-shot operation removes the need to retrain or fine-tune on target data.
- The method stays consistent with the theoretical guarantees of decoupling-based causal discovery.
- Performance holds across highly nonlinear and noisy data-generating processes.
Where Pith is reading between the lines
- If the synthetic-to-real transfer holds, the same pre-training recipe could be applied to other local structure-learning tasks.
- The approach suggests a route to amortize causal discovery across many scientific domains that currently lack large labeled graphs.
- Future work could test whether the learned weights also support downstream tasks such as intervention prediction.
Load-bearing premise
Patterns learned from synthetic SCMs transfer to real-world data and the learned weights recover true Markov boundaries without further safeguards.
What would settle it
Run the trained model on real-world datasets that have independently verified ground-truth causal graphs and measure whether the recovered Markov boundaries match the known structure at rates exceeding standard baselines.
Figures
read the original abstract
Causal discovery is critical for understanding complex data-generating mechanisms, yet traditional algorithms often struggle with highly non-linear and noisy systems, or suffer from severe computational bottlenecks. Recent tabular foundation models based on Prior-Data Fitted Networks (PFNs) have demonstrated remarkable zero-shot inference capabilities, but their potential for explicit structural causal discovery remains underexplored. To bridge this gap, we propose DCD-PFN, a decoupling-aware foundation model for causal discovery. Instead of directly amortizing global graph reconstruction, DCD-PFN focuses on local causal discovery through a decoupling-based paradigm. Through pre-training on diverse synthetic Structural Causal Models (SCMs), the model learns sample-wise decoupling weights that enable Markov boundary (MB) identification. Furthermore, by leveraging parallelized local discovery, DCD-PFN efficiently reconstructs global causal graphs while remaining grounded in the theoretical foundations of decoupling-based causal discovery. Experiments demonstrate that our foundation model achieves robust zero-shot generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DCD-PFN, a decoupling-aware Prior-Data Fitted Network (PFN) foundation model for causal discovery. It pre-trains on diverse synthetic Structural Causal Models to learn sample-wise decoupling weights that enable Markov boundary identification, then leverages parallelized local discovery to reconstruct global causal graphs while remaining grounded in decoupling theory, claiming robust zero-shot generalization to non-linear and noisy systems.
Significance. If the zero-shot results hold, the work offers a promising direction for scalable causal discovery by combining PFN-style pre-training with established decoupling-based local discovery; the explicit grounding in decoupling theory and use of synthetic SCM diversity for pre-training are strengths that distinguish it from purely empirical tabular foundation models.
minor comments (2)
- [Abstract] Abstract: the claim of 'robust zero-shot generalization' would be strengthened by including at least one concrete performance metric, dataset, or baseline comparison rather than leaving the empirical support implicit.
- [Method] The manuscript would benefit from a short explicit statement (e.g., in §3 or §4) of how the learned decoupling weights differ in form or training objective from a standard PFN, to make the 'decoupling-aware' contribution easier to isolate.
Simulated Author's Rebuttal
We thank the referee for their positive summary of DCD-PFN, recognition of its grounding in decoupling theory, and recommendation of minor revision. We appreciate the assessment that the combination of PFN pre-training with local discovery offers a promising direction.
Circularity Check
No significant circularity identified
full rationale
The manuscript presents an empirical pre-training pipeline on synthetic SCMs to learn decoupling weights for local MB identification followed by parallel global reconstruction. No derivation chain, equations, or first-principles claims are exhibited that reduce any output to the inputs by construction. The work explicitly positions itself as grounded in prior decoupling theory rather than deriving that theory internally, and the zero-shot generalization results are reported as falsifiable empirical outcomes rather than tautological predictions. No self-citation load-bearing steps, fitted-input renamings, or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aliferis, Alexander Statnikov, Ioannis Tsamardinos, Subramani Mani, and Xeno- fon D
Constantin F. Aliferis, Alexander Statnikov, Ioannis Tsamardinos, Subramani Mani, and Xeno- fon D. Koutsoukos. Local causal and markov blanket induction for causal discovery and feature selection for classification part i: Algorithms and empirical evaluation.Journal of Machine Learning Research, 11(7):171–234, 2010
2010
-
[2]
Amortized active causal induction with deep reinforcement learning
Yashas Annadani, Panagiotis Tigas, Stefan Bauer, and Adam Foster. Amortized active causal induction with deep reinforcement learning. InICML 2024 Workshop on Structured Probabilistic Inference & Generative Modeling, 2024
2024
-
[3]
Realistic evaluation of tabpfn v2 in open environments, 2025
Zi-Jian Cheng, Zi-Yi Jia, Zhi Zhou, Yu-Feng Li, and Lan-Zhe Guo. Realistic evaluation of tabpfn v2 in open environments, 2025. 8
2025
-
[4]
Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
2002
-
[5]
A meta-learning approach to bayesian causal discovery
Anish Dhir, Matthew Ashman, James Requeima, and Mark van der Wilk. A meta-learning approach to bayesian causal discovery. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[6]
On the robustness of tabular foundation models: Test-time attacks and in-context defenses, 2025
Mohamed Djilani, Thibault Simonetto, Karim Tit, Florian Tambon, Paul Récamier, Salah Ghamizi, Maxime Cordy, and Mike Papadakis. On the robustness of tabular foundation models: Test-time attacks and in-context defenses, 2025
2025
-
[7]
Amortized conditional independence testing
Bao Duong, Nu Hoang, and Thin Nguyen. Amortized conditional independence testing. In Xintao Wu, Myra Spiliopoulou, Can Wang, Vipin Kumar, Longbing Cao, Yanqiu Wu, Yu Yao, and Zhangkai Wu, editors,Advances in Knowledge Discovery and Data Mining, pages 410–423, Singapore, 2025. Springer Nature Singapore. ISBN 978-981-96-8170-9
2025
-
[8]
Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2025
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, Mihir Manium, Rosen Yu, Felix Jablon- ski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vladyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schö...
2025
-
[9]
Decoupled causal discovery, 2026
Zhengkang Guan and Kun Kuang. Decoupled causal discovery, 2026. Manuscript in preparation
2026
-
[10]
Efficient ensemble conditional independence test framework for causal discovery
Zhengkang Guan and Kun Kuang. Efficient ensemble conditional independence test framework for causal discovery. InInternational Conference on Learning Representations, 2026
2026
-
[11]
Drift-resilient tabpfn: In-context learning temporal distribution shifts on tabular data
Kai Helli, David Schnurr, Noah Hollmann, Samuel Müller, and Frank Hutter. Drift-resilient tabpfn: In-context learning temporal distribution shifts on tabular data. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 98742–98781. Curran Associates,...
2024
-
[12]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[13]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January 2025. ISSN 1476-4687
2025
-
[14]
Learning to induce causal structure
Nan Rosemary Ke, Silvia Chiappa, Jane X Wang, Jorg Bornschein, Anirudh Goyal, Melanie Rey, Theophane Weber, Matthew Botvinick, Michael Curtis Mozer, and Danilo Jimenez Rezende. Learning to induce causal structure. InInternational Conference on Learning Representations, 2023
2023
-
[15]
Self- attention between datapoints: Going beyond individual input-output pairs in deep learning
Jannik Kossen, Neil Band, Clare Lyle, Aidan Gomez, Tom Rainforth, and Yarin Gal. Self- attention between datapoints: Going beyond individual input-output pairs in deep learning. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
2021
-
[16]
Gradient- based neural dag learning.ArXiv, abs/1906.02226, 2019
Sébastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient- based neural dag learning.ArXiv, abs/1906.02226, 2019
arXiv 1906
-
[17]
Bamb: A balanced markov blanket discovery approach to feature selection.ACM Trans
Zhaolong Ling, Kui Yu, Hao Wang, Lin Liu, Wei Ding, and Xindong Wu. Bamb: A balanced markov blanket discovery approach to feature selection.ACM Trans. Intell. Syst. Technol., 10 (5):52:1–52:25, 2019
2019
-
[18]
Amortized inference for causal structure learning
Lars Lorch, Scott Sussex, Jonas Rothfuss, Andreas Krause, and Bernhard Schölkopf. Amortized inference for causal structure learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 13104–13118. Curran Associates, Inc., 2022. 9
2022
-
[19]
Foundation models for causal inference via prior-data fitted networks
Yuchen Ma, Dennis Frauen, Emil Javurek, and Stefan Feuerriegel. Foundation models for causal inference via prior-data fitted networks. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Bayesian network induction via local neighborhoods
Dimitris Margaritis and Sebastian Thrun. Bayesian network induction via local neighborhoods. In S. Solla, T. Leen, and K. Müller, editors,Advances in Neural Information Processing Systems, volume 12. MIT Press, 1999
1999
-
[21]
Transformers can do bayesian inference
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers can do bayesian inference. InInternational Conference on Learning Representa- tions, 2022
2022
-
[22]
Statistical foundations of prior-data fitted networks
Thomas Nagler. Statistical foundations of prior-data fitted networks. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[23]
On the role of sparsity and dag constraints for learning linear dags.ArXiv, abs/2006.10201, 2020
Ignavier Ng, AmirEmad Ghassami, and Kun Zhang. On the role of sparsity and dag constraints for learning linear dags.ArXiv, abs/2006.10201, 2020
arXiv 2006
-
[24]
Do-PFN: In-context learning for causal effect estimation
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. Do-PFN: In-context learning for causal effect estimation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721): 523–529, 2005
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721): 523–529, 2005
2005
-
[26]
A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
Shohei Shimizu, Patrik O Hoyer, Aapo Hyvärinen, Antti Kerminen, and Michael Jordan. A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
2006
-
[27]
Directlingam: A direct method for learning a linear non-gaussian structural equation model.Journal of Machine Learning Research-JMLR, 12(Apr):1225–1248, 2011
Shohei Shimizu, Takanori Inazumi, Yasuhiro Sogawa, Aapo Hyvarinen, Yoshinobu Kawahara, Takashi Washio, Patrik O Hoyer, Kenneth Bollen, and Patrik Hoyer. Directlingam: A direct method for learning a linear non-gaussian structural equation model.Journal of Machine Learning Research-JMLR, 12(Apr):1225–1248, 2011
2011
-
[28]
An algorithm for fast recovery of sparse causal graphs.Social Science Computer Review, 9(1):62–72, 1991
Peter Spirtes and Clark Glymour. An algorithm for fast recovery of sparse causal graphs.Social Science Computer Review, 9(1):62–72, 1991
1991
-
[29]
MIT press, 2000
Peter Spirtes, Clark N Glymour, and Richard Scheines.Causation, prediction, and search. MIT press, 2000
2000
-
[30]
Tsamardinos, Constantin F
I. Tsamardinos, Constantin F. Aliferis, and Alexander R. Statnikov. Time and sample efficient discovery of markov blankets and direct causal relations. InKnowledge Discovery and Data Mining, 2003
2003
-
[31]
Towards efficient and effective discovery of markov blankets for feature selection.Inf
Hao Wang, Zhaolong Ling, Kui Yu, and Xindong Wu. Towards efficient and effective discovery of markov blankets for feature selection.Inf. Sci., 509:227–242, 2020
2020
-
[32]
Accurate markov boundary discovery for causal feature selection.IEEE Trans
Xingyu Wu, Bingbing Jiang, Kui Yu, Chunyan Miao, and Huanhuan Chen. Accurate markov boundary discovery for causal feature selection.IEEE Trans. Cybern., 50(12):4983–4996, 2020
2020
-
[33]
A closer look at tabPFN v2: Understanding its strengths and extending its capabilities
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Chao. A closer look at tabPFN v2: Understanding its strengths and extending its capabilities. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[34]
Kernel-based conditional independence test and application in causal discovery
Kun Zhang, Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Kernel-based conditional independence test and application in causal discovery. In Fábio Gagliardi Cozman and Avi Pfeffer, editors,UAI 2011, Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, Barcelona, Spain, July 14-17, 2011, pages 804–813. AUAI Press, 2011
2011
-
[35]
Limix: Unleashing structured-data modeling capability for generalist intelligence
Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, Ningbo Dai, Renzhe Xu, Shuyang Li, Tianyang Zhang, Yue He, Yuanrui Wang, Yunjia Zhang, Zijing Xu, Dongzhe Li, Fang Gao, Hao Zou, Jiandong Liu, Jiashuo Liu, Jiawei Xu, Kaijie Cheng, Kehan Li, Linjun Zhou, Qing Li, Shaohua Fan, Xiaoyu 10 Lin, Xinyan...
arXiv 2025
-
[36]
Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W
Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, and Bernie Wang. Mitra: Mixed synthetic priors for enhancing tabular foundation models. InThe Thirty-ninth Annual Conference on Neural Information Proc...
2025
-
[37]
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing. Dags with no tears: Continuous optimization for structure learning. InNeural Information Processing Systems, 2018. 11
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.