Challenger at MultiPRIDE: Is It Hate Speech or Reclaimed?
Pith reviewed 2026-06-28 17:18 UTC · model grok-4.3
The pith
Semantic embeddings cleaned by Cleanlab and classified by an MLP separate hate speech from reclaimed language in imbalanced data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
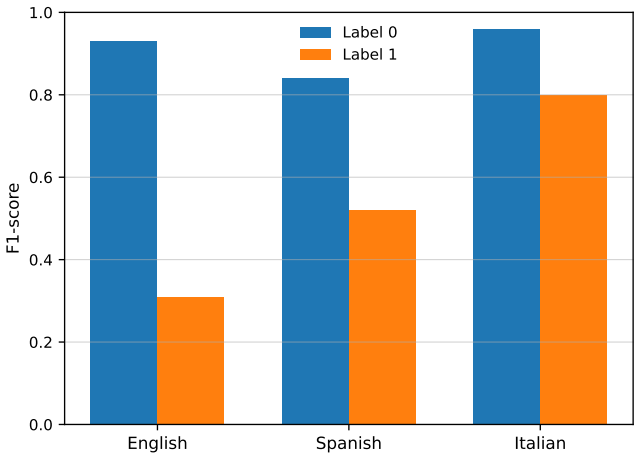
The authors claim that generating dense semantic text embeddings, running a Cleanlab label-noise filter that uses logistic regression, and then classifying with an MLP produces robust performance on distinguishing genuine hate speech from reclaimed language despite extreme class imbalance in the MultiPride dataset.
What carries the argument
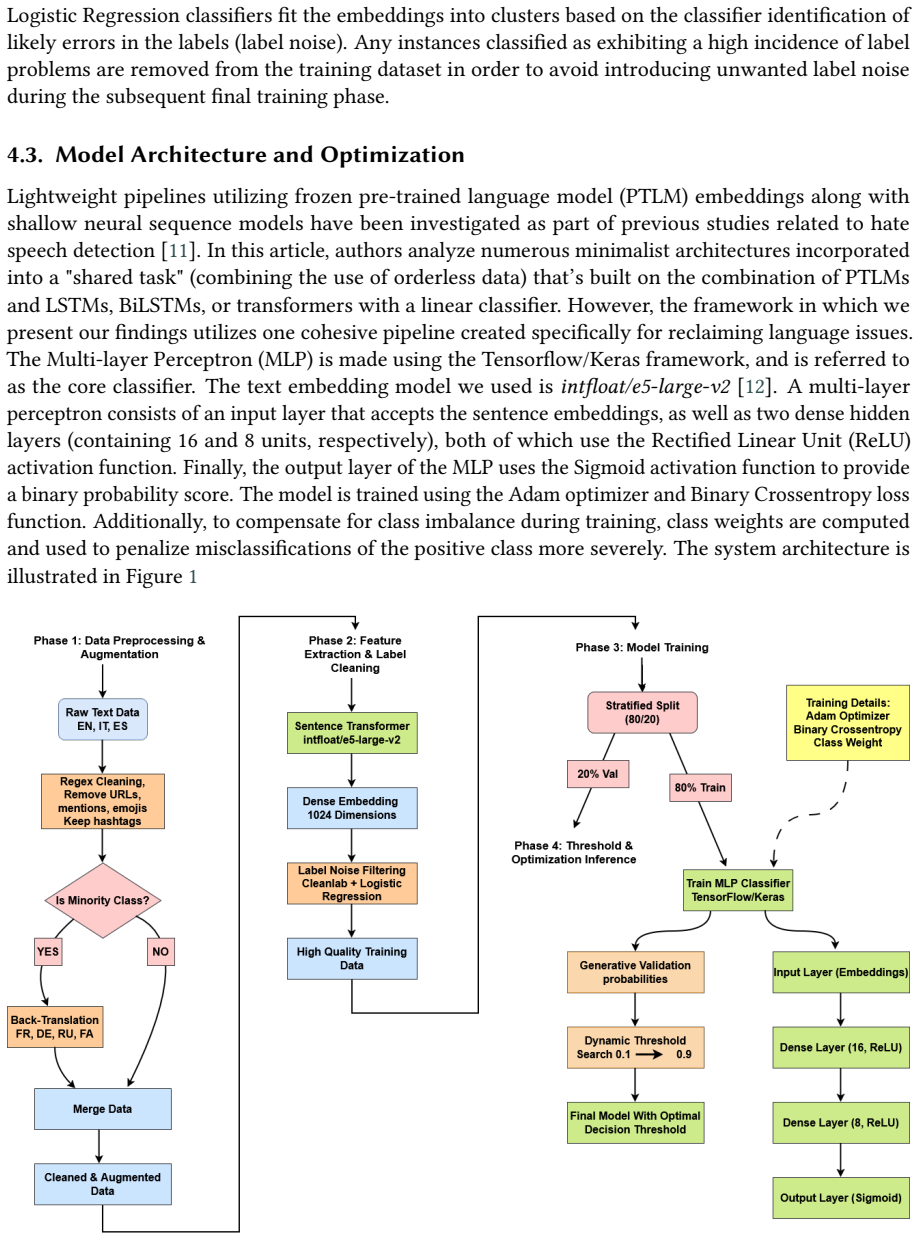
A three-stage pipeline of dense semantic embeddings followed by Cleanlab-plus-logistic-regression noise filtering and an MLP classifier.
If this is right
- The system remains interpretable and runs on limited hardware while handling severe imbalance.
- Performance scales with larger embedding models and better preprocessing while keeping the same filtering-plus-MLP structure.
- Macro-averaged metrics stay usable even when reclaimed language is the minority class.
- The label-cleaning step reduces the impact of noisy annotations common in social-media hate-speech data.
Where Pith is reading between the lines
- The same filtering-plus-MLP pattern might transfer to other nuanced detection tasks such as sarcasm or coded language where label noise is high.
- If the logistic-regression step in Cleanlab systematically removes edge-case reclaimed phrases, downstream bias against minority dialects could increase.
- Replacing the MLP with a simpler linear model after the same embedding and cleaning stages would test how much the neural classifier itself contributes.
Load-bearing premise
Cleanlab with logistic regression can reliably spot and fix mislabeled reclaimed-language examples without discarding valid but unusual instances in this context-sensitive task.
What would settle it
Running the trained pipeline on a held-out set of manually verified reclaimed versus hate-speech examples and measuring whether the F1 score falls below the level reported for the original imbalanced test data.
Figures
read the original abstract
The spread of hate speech has become increasingly harmful in modern digital environments, particularly on social networking platforms. While recent advances have shown promising results in automatic hate speech detection, a key challenge remains: distinguishing genuine hate speech from reclaimed language. Accurate labeling is difficult due to the nuanced and context-dependent nature of reclaimed expressions. In this paper, we present a simple and interpretable approach for distinguishing hate speech from reclaimed language, developed for the MultiPride Shared Task. Our method generates dense semantic text embeddings and incorporates a label-noise filtering stage using Cleanlab with logistic regression, followed by a Multi-layer Perceptron (MLP) neural network for final classification. The system is designed to operate under limited computational resources while maintaining strong performance. We evaluate our approach using precision, recall, and F1-score, including macro-averaged metrics. Experimental results demonstrate robust performance despite extreme class imbalance in the dataset. Overall, the findings highlight the potential for further improvements through larger embedding models and more advanced preprocessing techniques while preserving interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a pipeline for the MultiPRIDE shared task on distinguishing hate speech from reclaimed language: dense semantic embeddings are generated, followed by a Cleanlab + logistic regression stage to filter label noise, and an MLP for final classification. The system is positioned as simple, interpretable, and resource-efficient; the abstract states that experimental results demonstrate robust performance (via precision, recall, and F1, including macro averages) despite extreme class imbalance.
Significance. A validated, lightweight pipeline that reliably separates reclaimed language from hate speech under imbalance would be useful for moderation systems. The described approach has the virtue of using off-the-shelf components and preserving interpretability, but its significance cannot be assessed until the filtering stage is shown not to discard valid but atypical reclaimed instances and until concrete metrics, baselines, and ablations are supplied.
major comments (2)
- [Abstract / Experimental results] Abstract and (presumably) §3–4: the central claim that the pipeline yields 'robust performance despite extreme class imbalance' is unsupported by any reported numbers, baselines, confidence intervals, or error analysis. Without these, the empirical contribution cannot be evaluated.
- [Methods / Label-noise filtering] Label-noise filtering stage (Cleanlab + logistic regression on embeddings): no confidence thresholds, fit diagnostics, ablation (with vs. without filtering), or check that the filter preserves valid but context-dependent reclaimed examples are provided. In a task where reclaimed language is intentionally atypical, this step is load-bearing for the robustness claim yet lacks any verification that logistic regression on fixed embeddings separates noise from signal.
minor comments (1)
- [Abstract] The abstract states that larger embedding models and advanced preprocessing are suggested for future work, but does not indicate whether any such variants were already tested in the current experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional empirical detail will strengthen the paper. We address each major comment below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and (presumably) §3–4: the central claim that the pipeline yields 'robust performance despite extreme class imbalance' is unsupported by any reported numbers, baselines, confidence intervals, or error analysis. Without these, the empirical contribution cannot be evaluated.
Authors: We agree that concrete metrics are required to substantiate the robustness claim. The current manuscript states that precision, recall, and F1 (including macro averages) were computed, but does not tabulate the values or provide baselines. In revision we will add the numerical results, baseline comparisons, confidence intervals, and a concise error analysis to both the abstract and §4. revision: yes
-
Referee: [Methods / Label-noise filtering] Label-noise filtering stage (Cleanlab + logistic regression on embeddings): no confidence thresholds, fit diagnostics, ablation (with vs. without filtering), or check that the filter preserves valid but context-dependent reclaimed examples are provided. In a task where reclaimed language is intentionally atypical, this step is load-bearing for the robustness claim yet lacks any verification that logistic regression on fixed embeddings separates noise from signal.
Authors: We will expand the methods description to report the exact Cleanlab confidence thresholds, logistic-regression fit statistics, and an ablation comparing performance with versus without the filtering stage. For the concern about atypical reclaimed instances, the embeddings are intended to capture semantic context; we will add a qualitative discussion of filtered examples and note any limitations in the revised text. revision: yes
Circularity Check
No circularity: standard empirical ML pipeline with off-the-shelf components
full rationale
The paper describes a straightforward classification pipeline (dense embeddings + Cleanlab+logistic regression noise filter + MLP) evaluated on a shared-task dataset. No equations, derivations, or first-principles claims appear; performance is reported via standard metrics on held-out data. No self-citations, fitted parameters renamed as predictions, or self-definitional steps are present. The method is self-contained against external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Albladi, M. Islam, A. Das, M. Bigonah, Z. Zhang, F. Jamshidi, M. Rahgouy, N. Raychawdhary, D. Marghitu, C. Seals, Hate speech detection using large language models: A comprehensive review, IEEE Access 13 (2025) 20871–20892. doi:10.1109/ACCESS.2025.3532397
-
[2]
A. Schmidt, M. Wiegand, A survey on hate speech detection using natural language processing, in: L.-W. Ku, C.-T. Li (Eds.), Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, Association for Computational Linguistics, Valencia, Spain, 2017, pp. 1–10. URL: https://aclanthology.org/W17-1101/. doi:10.18653/v1/W17-1101
-
[3]
A. Tontodimamma, E. Nissi, A. Sarra, L. Fontanella, Thirty years of research into hate speech: topics of interest and their evolution, Scientometrics 126 (2021) 157–179. URL: https://doi.org/10. 1007/s11192-020-03737-6. doi:10.1007/s11192-020-03737-6
-
[4]
A. B. De Oliveira, C. d. S. Baptista, A. A. Firmino, A. C. De Paiva, A large language model approach to detect hate speech in political discourse using multiple language corpora, in: Proceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, SAC ’24, Association for Computing Machinery, New York, NY, USA, 2024, p. 1461–1468. URL: https://doi.org/1...
-
[5]
A. Toktarova, D. Syrlybay, B. Myrzakhmetova, G. Anuarbekova, G. Rakhimbayeva, B. Zhylanbaeva, N. Suieuova, M. Kerimbekov, Hate speech detection in social networks using machine learning and deep learning methods, International Journal of Advanced Computer Science and Applications 14 (2023). URL: http://dx.doi.org/10.14569/IJACSA.2023.0140542. doi:10.14569...
-
[6]
E. Zsisku, A. Zubiaga, H. Dubossarsky, Hate speech detection and reclaimed language: Mitigating false positives and compounded discrimination, in: Proceedings of the 16th ACM Web Science Conference (WEBSCI ’24), ACM, Stuttgart, Germany, 2024, pp. 241–249. doi:10.1145/3614419. 3644025
-
[7]
PLOS ONE7(6), 38869 (2012) https://doi.org/10.1371/journal.pone
M. Mozafari, R. Farahbakhsh, N. Crespi, Hate speech detection and racial bias mitigation in social media based on bert model, PLOS ONE 15 (2020) 1–26. URL: https://doi.org/10.1371/journal.pone. 0237861. doi:10.1371/journal.pone.0237861
-
[8]
Hate Lingo: A Target-based Linguistic Analysis of Hate Speech in Social Media
M. ElSherief, V. Kulkarni, D. Nguyen, W. Y. Wang, E. Belding, Hate lingo: A target-based linguistic analysis of hate speech in social media, 2018. URL: https://arxiv.org/abs/1804.04257. arXiv:1804.04257
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
J. M. Pérez, F. M. Luque, D. Zayat, M. Kondratzky, A. Moro, P. S. Serrati, J. Zajac, P. Miguel, N. Debandi, A. Gravano, V. Cotik, Assessing the impact of contextual information in hate speech detection, IEEE Access 11 (2023) 30575–30590. doi:10.1109/ACCESS.2023.3258973
-
[10]
Ferrando, L
C. Ferrando, L. Draetta, M. Madeddu, M. Sosto, V. Patti, P. Rosso, C. Bosco, J. Mata, E. Gualda, Multipride at evalita 2026: Overview of the multilingual automatic detection of slur reclamation in the lgbtq+ context task, in: Proceedings of the Ninth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2...
2026
-
[11]
Nozza, A
D. Nozza, A. Cignarella, G. Damo, T. Caselli, V. Patti, Hodi at evalita 2023: Overview of the first shared task on homotransphobia detection in italian, in: M. Lai, S. Menini, M. Polignano, V. Russo, R. Sprugnoli, G. Venturi (Eds.), Proceedings of the Eighth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (E...
2023
-
[12]
L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, F. Wei, Text embeddings by weakly-supervised contrastive pre-training, arXiv preprint arXiv:2212.03533 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.