A Formula-Driven Survey and Research Agenda for On-Policy Distillation
Pith reviewed 2026-06-26 08:59 UTC · model grok-4.3
The pith
On-policy distillation works by separating temporal credit from vocabulary-level probability routing in addition to KL direction and teacher access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that OPD effectiveness depends on the listed factors beyond KL direction or teacher access, and that distinguishing temporal credit from vocabulary routing produces distinct bias boundaries for the listed estimators while motivating GAE-OPD as a value-based hypothesis for log-ratio returns and Counterfactual Routed OPD for routing mass toward teacher-supported student-reachable alternatives. The taxonomy further maps actionability diagnostics, failure mechanisms, case studies, open problems, and a reporting checklist onto the same feedback-to-update variables.
What carries the argument
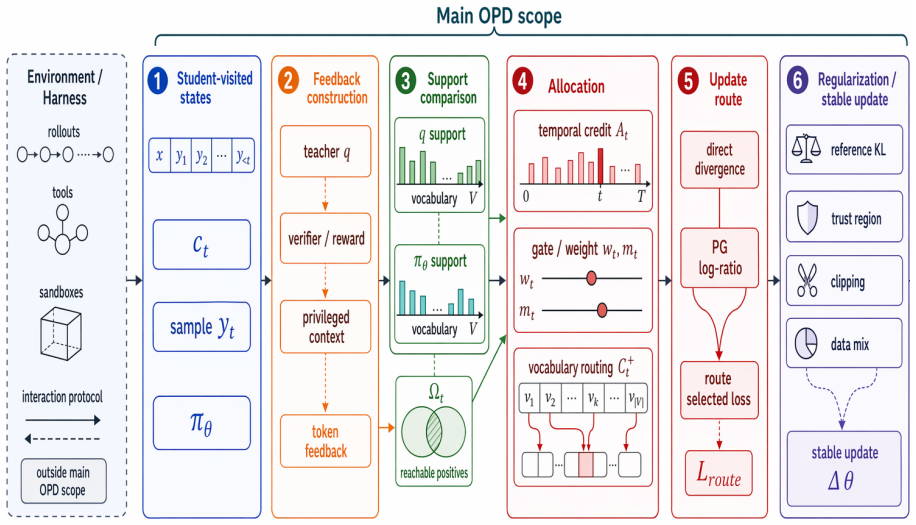
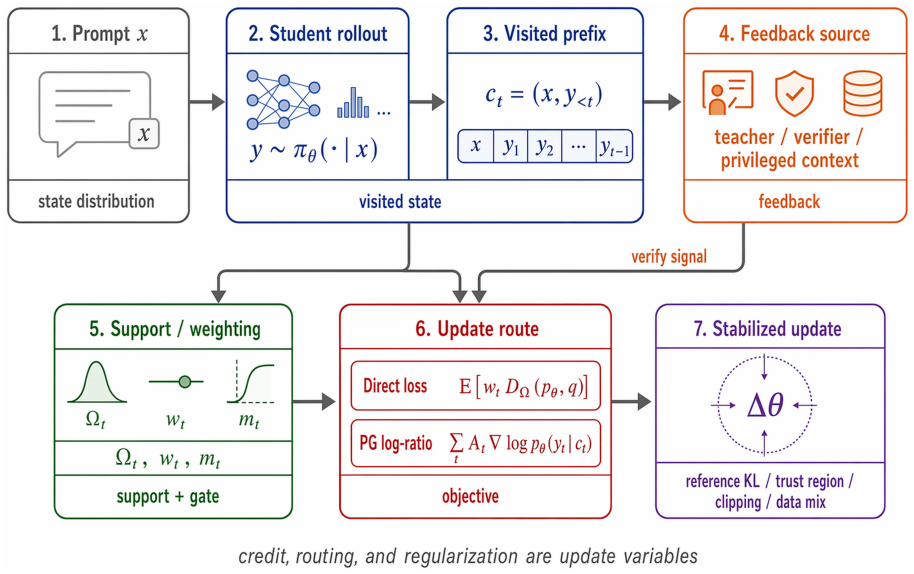
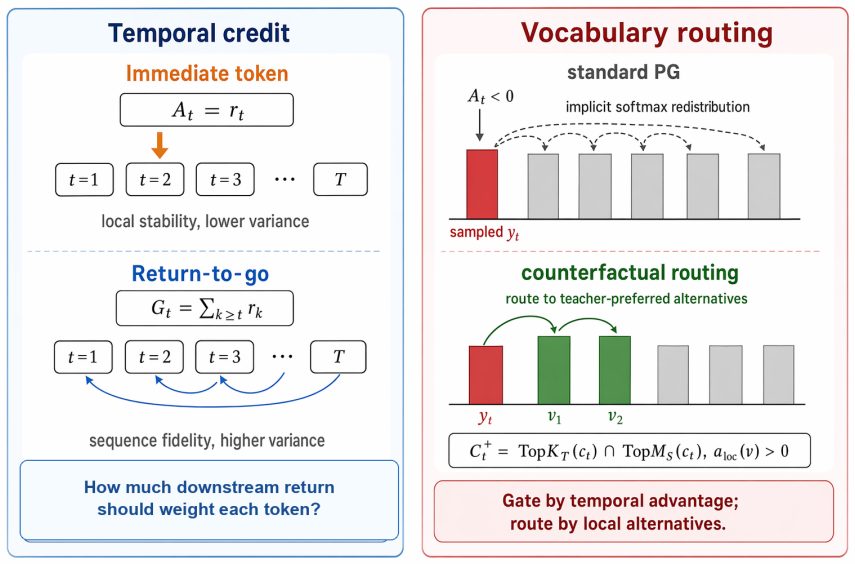
The formula-driven taxonomy that separates temporal credit (weighting of teacher-student log-ratio returns across a rollout) from vocabulary routing (direction of probability mass movement on token suppression).
If this is right
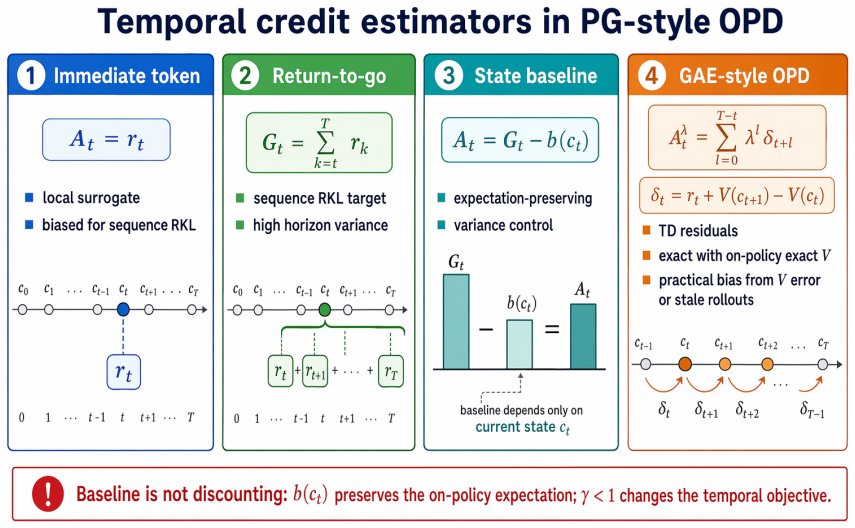
- Bias boundaries exist for immediate, return-to-go, discounted, and baseline-corrected estimators once the two mechanisms are separated.
- GAE-OPD becomes a natural value-based hypothesis for handling log-ratio returns.
- CR-OPD becomes a natural hypothesis for routing probability mass to teacher-supported alternatives.
- Actionability diagnostics, failure mechanisms, and a reporting checklist can be expressed in the same feedback-to-update variables.
Where Pith is reading between the lines
- The same separation could be tested in off-policy or hybrid distillation settings to check whether the bias boundaries generalize.
- Industrial implementations could adopt the reporting checklist to make stability claims comparable across papers.
- Explicit modeling of vocabulary routing might reduce the need for ad-hoc regularization terms in current OPD recipes.
Load-bearing premise
The mechanisms of temporal credit and vocabulary routing can be cleanly separated in sampled-token OPD to yield distinct bias boundaries.
What would settle it
An experiment that measures whether treating temporal credit and vocabulary routing as a single mechanism produces measurably different bias predictions than treating them separately on the same set of immediate, return-to-go, discounted, or baseline-corrected estimators.
Figures
read the original abstract
On-policy distillation (OPD) trains an LLM on states induced by the current or recent student policy: the student generates complete or partial rollouts, a teacher or self-teacher scores the resulting tokens under their generated contexts, and dense log-probability, logit, or distributional signals are converted into post-training updates. This survey studies OPD as a feedback-to-update problem rather than a single loss family. We develop a formula-driven taxonomy from two routes -- direct distributional losses and policy-gradient-style log-ratio updates -- and use it to organize core methods, verifier- or outcome-guided hybrids, industrial reports, framework implementations, failure modes, and stabilization recipes under explicit evidence boundaries. The taxonomy shows that OPD effectiveness depends not only on KL direction or teacher access, but also on state compatibility, support construction, temporal credit, vocabulary-level probability routing, gates and weights, and regularization. We further separate two mechanisms often conflated in sampled-token OPD stability discussions. Temporal credit asks how teacher-student log-ratio returns should weight sampled actions across a rollout; vocabulary routing asks where probability mass should move when negative feedback suppresses a sampled token. This distinction yields bias boundaries for immediate, return-to-go, discounted, and baseline-corrected estimators, motivates GAE-OPD as a value-based hypothesis for log-ratio returns, and motivates Counterfactual Routed OPD (CR-OPD) for routing probability mass toward teacher-supported, student-reachable alternatives. We close by mapping actionability diagnostics, failure mechanisms, case studies, open problems, and a reporting checklist onto the same feedback-to-update variables.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a formula-driven survey and research agenda for on-policy distillation (OPD) in LLMs. It frames OPD as a feedback-to-update problem and develops a taxonomy organized around direct distributional losses and policy-gradient-style log-ratio updates. The central contribution is a separation of temporal credit assignment (weighting log-ratio returns across rollouts) from vocabulary-level probability routing (movement of probability mass under negative feedback). This separation is claimed to produce explicit bias boundaries for immediate, return-to-go, discounted, and baseline-corrected estimators, to motivate new hypotheses such as GAE-OPD and CR-OPD, and to organize failure modes, stabilization recipes, verifier hybrids, and open problems under a common set of variables including state compatibility, support construction, gates, weights, and regularization.
Significance. If the taxonomy and the claimed separation hold, the work offers a structured conceptual framework that could help organize a rapidly growing area of LLM post-training. The formula-driven approach and the explicit mapping of OPD components to bias boundaries and diagnostics constitute a genuine organizational contribution. The manuscript supplies no new empirical results, error analysis, or machine-checked derivations, so its significance rests on the clarity and utility of the taxonomy for guiding future empirical and theoretical work rather than on any closed-form result or verified prediction.
major comments (2)
- [Abstract] Abstract: the central claim that the temporal-credit / vocabulary-routing distinction 'yields bias boundaries for immediate, return-to-go, discounted, and baseline-corrected estimators' is load-bearing for the contribution, yet the abstract supplies neither the explicit formulas nor a reference to the section in which those boundaries are derived. Without that grounding, the claim that the separation produces actionable bias boundaries remains unsubstantiated in the provided framing.
- [Abstract] Abstract: the assertion that the two mechanisms 'are frequently conflated in existing sampled-token OPD stability discussions' is presented as motivation for the taxonomy, but no specific citations, examples, or prior-work analysis are referenced to document the conflation. This weakens the justification for treating the separation as a novel and necessary distinction rather than a re-framing.
minor comments (1)
- [Abstract] The abstract is information-dense; a short illustrative example showing how one prior OPD method conflates the two mechanisms and how the proposed separation would re-classify it would improve accessibility without altering the technical content.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the abstract. We address each point below and will revise the abstract to improve grounding and motivation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the temporal-credit / vocabulary-routing distinction 'yields bias boundaries for immediate, return-to-go, discounted, and baseline-corrected estimators' is load-bearing for the contribution, yet the abstract supplies neither the explicit formulas nor a reference to the section in which those boundaries are derived. Without that grounding, the claim that the separation produces actionable bias boundaries remains unsubstantiated in the provided framing.
Authors: The bias boundaries are explicitly derived in Section 4 (Bias Boundaries), with Propositions 4.1--4.4 mapping the temporal-credit and vocabulary-routing mechanisms to the four estimator families. We agree the abstract would be strengthened by a direct pointer and will revise the sentence to read: '...This distinction yields bias boundaries for immediate, return-to-go, discounted, and baseline-corrected estimators (Section 4)...'. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the two mechanisms 'are frequently conflated in existing sampled-token OPD stability discussions' is presented as motivation for the taxonomy, but no specific citations, examples, or prior-work analysis are referenced to document the conflation. This weakens the justification for treating the separation as a novel and necessary distinction rather than a re-framing.
Authors: The manuscript documents the conflation with concrete examples in Section 2.3 and Table 1, referencing specific stability discussions in recent DPO/PPO-style LLM papers. To address the abstract-level concern, we will add a brief parenthetical reference to that section so the motivation is traceable without expanding the abstract length. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a survey that constructs a taxonomy by organizing existing OPD methods around two routes (distributional losses and log-ratio updates) and separating temporal credit from vocabulary routing. No load-bearing derivation, equation, or prediction reduces by construction to a fitted quantity or self-defined input; the bias boundaries and method hypotheses (GAE-OPD, CR-OPD) are presented as conceptual distinctions drawn from the literature rather than closed-form results internal to the paper. The contribution is taxonomic and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NeurIPS Deep Learning and Representation Learning Workshop , year =
Distilling the Knowledge in a Neural Network , author =. NeurIPS Deep Learning and Representation Learning Workshop , year =
-
[2]
Advances in Neural Information Processing Systems , volume =
Sequence to Sequence Learning with Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2014 , url =
2014
-
[3]
Advances in Neural Information Processing Systems , volume =
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2015 , url =
2015
-
[4]
International Conference on Learning Representations , year =
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author =. International Conference on Learning Representations , year =
-
[5]
arXiv preprint arXiv:1511.06732 , year =
Sequence Level Training with Recurrent Neural Networks , author =. arXiv preprint arXiv:1511.06732 , year =
-
[6]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , year =
Sequence-Level Knowledge Distillation , author =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , year =
2016
-
[7]
International Conference on Learning Representations , year =
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author =. International Conference on Learning Representations , year =
-
[8]
International Conference on Machine Learning , pages =
Trust Region Policy Optimization , author =. International Conference on Machine Learning , pages =. 2015 , url =
2015
-
[9]
arXiv preprint arXiv:1707.06347 , year =
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
-
[10]
Advances in Neural Information Processing Systems , year =
Using Fast Weights to Attend to the Recent Past , author =. Advances in Neural Information Processing Systems , year =
-
[11]
Proceedings of the National Academy of Sciences , volume =
Overcoming Catastrophic Forgetting in Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =. 2017 , url =
2017
-
[12]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , year =
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author =. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , year =
-
[13]
2023 , url =
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , journal =. 2023 , url =
2023
-
[14]
2024 , url =
Ko, Jongwoo and Kim, Sungnyun and Chen, Tianyi and Yun, Se-Young , journal =. 2024 , url =
2024
-
[15]
2025 , url =
Ko, Jongwoo and Chen, Tianyi and Kim, Sungnyun and Ding, Tianyu and Liang, Luming and Zharkov, Ilya and Yun, Se-Young , booktitle =. 2025 , url =
2025
-
[16]
Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for
Boizard, Nicolas and El Haddad, Kevin and Hudelot, C. Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for. Transactions on Machine Learning Research , year =
-
[17]
arXiv preprint arXiv:2504.11426 , year =
A Dual-Space Framework for General Knowledge Distillation of Large Language Models , author =. arXiv preprint arXiv:2504.11426 , year =
-
[18]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , journal =. 2024 , url =
2024
-
[19]
arXiv preprint arXiv:2501.12948 , year =
-
[20]
2025 , url =
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun , journal =. 2025 , url =
2025
-
[21]
arXiv preprint arXiv:2604.00626 , year =
A Survey of On-Policy Distillation for Large Language Models , author =. arXiv preprint arXiv:2604.00626 , year =
-
[22]
arXiv preprint arXiv:2605.18141 , year =
A Brief Overview: On-Policy Self-Distillation in Large Language Models , author =. arXiv preprint arXiv:2605.18141 , year =
-
[23]
arXiv preprint arXiv:2603.25562 , year =
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author =. arXiv preprint arXiv:2603.25562 , year =
-
[24]
arXiv preprint arXiv:2604.13016 , year =
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author =. arXiv preprint arXiv:2604.13016 , year =
-
[25]
arXiv preprint arXiv:2605.11182 , year =
The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes , author =. arXiv preprint arXiv:2605.11182 , year =
-
[26]
arXiv preprint arXiv:2605.10889 , year =
Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why , author =. arXiv preprint arXiv:2605.10889 , year =
-
[27]
arXiv preprint arXiv:2604.07941 , year =
Large Language Model Post-Training: A Unified View of Off-Policy and On-Policy Learning , author =. arXiv preprint arXiv:2604.07941 , year =
-
[28]
arXiv preprint arXiv:2511.10643 , year =
Black-Box On-Policy Distillation of Large Language Models , author =. arXiv preprint arXiv:2511.10643 , year =
-
[29]
arXiv preprint arXiv:2602.12275 , year =
On-Policy Context Distillation for Language Models , author =. arXiv preprint arXiv:2602.12275 , year =
-
[30]
arXiv preprint arXiv:2602.12125 , year =
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation , author =. arXiv preprint arXiv:2602.12125 , year =
-
[31]
arXiv preprint arXiv:2601.18734 , year =
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author =. arXiv preprint arXiv:2601.18734 , year =
-
[32]
arXiv preprint arXiv:2605.18740 , year =
Vision-OPD: Learning to See Fine Details for Multimodal LLMs via On-Policy Self-Distillation , author =. arXiv preprint arXiv:2605.18740 , year =
-
[33]
arXiv preprint arXiv:2604.08527 , year =
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models , author =. arXiv preprint arXiv:2604.08527 , year =
-
[34]
Findings of the Association for Computational Linguistics , year =
Stable On-Policy Distillation through Adaptive Target Reformulation , author =. Findings of the Association for Computational Linguistics , year =
-
[35]
arXiv preprint arXiv:2605.06387 , year =
Asymmetric On-Policy Distillation: Bridging Exploitation and Imitation at the Token Level , author =. arXiv preprint arXiv:2605.06387 , year =
-
[36]
arXiv preprint arXiv:2605.07865 , year =
KL for a KL: On-Policy Distillation with Control Variate Baseline , author =. arXiv preprint arXiv:2605.07865 , year =
-
[37]
arXiv preprint arXiv:2604.14084 , year =
TIP: Token Importance in On-Policy Distillation , author =. arXiv preprint arXiv:2604.14084 , year =
-
[38]
arXiv preprint arXiv:2604.10688 , year =
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting , author =. arXiv preprint arXiv:2604.10688 , year =
-
[39]
2026 , url =
Xiong, Jing and Shen, Hui and Gong, Shansan and Cheng, Yuxin and Shen, Jianghan and Tao, Chaofan and Tan, Haochen and Bai, Haoli and Shang, Lifeng and Wong, Ngai , journal =. 2026 , url =
2026
-
[40]
arXiv preprint arXiv:2603.11137 , year =
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation , author =. arXiv preprint arXiv:2603.11137 , year =
-
[41]
arXiv preprint arXiv:2601.19897 , year =
Self-Distillation Enables Continual Learning , author =. arXiv preprint arXiv:2601.19897 , year =
-
[42]
arXiv preprint arXiv:2601.20802 , year =
Reinforcement Learning via Self-Distillation , author =. arXiv preprint arXiv:2601.20802 , year =
-
[43]
arXiv preprint arXiv:2605.01347 , year =
MAD-OPD: Breaking the Ceiling in On-Policy Distillation via Multi-Agent Debate , author =. arXiv preprint arXiv:2605.01347 , year =
-
[44]
arXiv preprint arXiv:2604.27083 , year =
Co-Evolving Policy Distillation , author =. arXiv preprint arXiv:2604.27083 , year =
-
[45]
arXiv preprint arXiv:2601.02780 , year =
MiMo-V2-Flash Technical Report , author =. arXiv preprint arXiv:2601.02780 , year =
-
[46]
arXiv preprint arXiv:2604.13010 , year =
Lightning OPD: Efficient Post-Training for Large Reasoning Models with Offline On-Policy Distillation , author =. arXiv preprint arXiv:2604.13010 , year =
-
[47]
arXiv preprint arXiv:2603.07079 , year =
Entropy-Aware On-Policy Distillation of Language Models , author =. arXiv preprint arXiv:2603.07079 , year =
-
[48]
2026 , url =
Sun, Jie and Zheng, Mao and Song, Mingyang and Zhong, Qiyong and Cheng, Yilin and Feng, Bichuan and Liu, Pengfei and Fang, Junfeng and Wang, Xiang , journal =. 2026 , url =
2026
-
[49]
arXiv preprint arXiv:2505.09388 , year =
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
-
[50]
arXiv preprint arXiv:2602.15763 , year =
GLM-5: from Vibe Coding to Agentic Engineering , author =. arXiv preprint arXiv:2602.15763 , year =
-
[51]
Reasoning and Tool-use Compete in Agentic
Li, Yu and Yi, Mingyang and Li, Xiuyu and Fan, Ju and Jiang, Fuxin and Chen, Binbin and Li, Peng and Song, Jie and Zhang, Tieying , journal =. Reasoning and Tool-use Compete in Agentic. 2026 , url =
2026
-
[52]
arXiv preprint arXiv:2606.01249 , year =
Trust Region On-Policy Distillation , author =. arXiv preprint arXiv:2606.01249 , year =
-
[53]
arXiv preprint arXiv:2606.01039 , year =
OPD+: Rethinking the Advantage Design for On-Policy Distillation , author =. arXiv preprint arXiv:2606.01039 , year =
-
[54]
arXiv preprint arXiv:2605.29343 , year =
Draft-OPD: On-Policy Distillation for Speculative Draft Models , author =. arXiv preprint arXiv:2605.29343 , year =
-
[55]
arXiv preprint arXiv:2606.01476 , year =
OmniOPD: Logit-Free On-Policy Distillation via Speculative Verification , author =. arXiv preprint arXiv:2606.01476 , year =
-
[56]
2025 , howpublished =
On-Policy Distillation , author =. 2025 , howpublished =
2025
-
[57]
arXiv preprint arXiv:2605.07396 , year =
Rubric-based On-policy Distillation , author =. arXiv preprint arXiv:2605.07396 , year =
-
[58]
2026 , howpublished =
2026
-
[59]
Post-Training is About States, Not Tokens: A State Distribution View of
Nie, Dong , journal =. Post-Training is About States, Not Tokens: A State Distribution View of. 2026 , url =
2026
-
[60]
Reinforcement Learning from Rich Feedback with Distributional
Agrawal, Rishabh and Fein-Ashley, Jacob and Rashidinejad, Paria , journal =. Reinforcement Learning from Rich Feedback with Distributional. 2026 , url =
2026
-
[61]
2025 , url =
Fan, Jiabin and Luo, Guoqing and Bowling, Michael and Mou, Lili , journal =. 2025 , url =
2025
-
[62]
2025 , url =
Jung, Seongryong and Yoon, Suwan and Kim, DongGeon and Lee, Hwanhee , booktitle =. 2025 , url =
2025
-
[63]
2025 , url =
Xu, Hongling and Zhu, Qi and Deng, Heyuan and Li, Jinpeng and Hou, Lu and Wang, Yasheng and Shang, Lifeng and Xu, Ruifeng and Mi, Fei , journal =. 2025 , url =
2025
-
[64]
2025 , url =
Peng, Jingyu and Wang, Maolin and Cai, Hengyi and Li, Yuchen and Zhang, Kai and Wang, Shuaiqiang and Yin, Dawei and Zhao, Xiangyu , journal =. 2025 , url =
2025
-
[65]
arXiv preprint arXiv:2602.15260 , year =
Fast and Effective On-policy Distillation from Reasoning Prefixes , author =. arXiv preprint arXiv:2602.15260 , year =
-
[66]
2026 , url =
Yang, Zhicheng and Guo, Zhijiang and Song, Yifan and Xu, Minrui and Wang, Yongxin and Wang, Yiwei and Liang, Xiaodan and Tang, Jing , journal =. 2026 , url =
2026
-
[67]
arXiv preprint arXiv:2605.31490 , year =
Are Full Rollouts Necessary for On-Policy Distillation? , author =. arXiv preprint arXiv:2605.31490 , year =
-
[68]
arXiv preprint arXiv:2606.00305 , year =
Bridging Reasoning Trajectories in On-Policy Distillation via Near-Future Guidance , author =. arXiv preprint arXiv:2606.00305 , year =
-
[69]
arXiv preprint arXiv:2606.02684 , year =
Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation , author =. arXiv preprint arXiv:2606.02684 , year =
-
[70]
arXiv preprint arXiv:2604.16830 , year =
The Illusion of Certainty: Decoupling Capability and Calibration in On-Policy Distillation , author =. arXiv preprint arXiv:2604.16830 , year =
-
[71]
Why Does Self-Distillation Sometimes Degrade the Reasoning Capability of
Kim, Jeonghye and Luo, Xufang and Kim, Minbeom and Lee, Sangmook and Kim, Dohyung and Jeon, Jiwon and Li, Dongsheng and Yang, Yuqing , journal =. Why Does Self-Distillation Sometimes Degrade the Reasoning Capability of. 2026 , url =
2026
-
[72]
2026 , url =
Wang, Jiaqi and Zhang, Wenhao and Shi, Weijie and Li, Yaliang and Cheng, James , journal =. 2026 , url =
2026
-
[73]
2026 , url =
Zhong, Qiyong and Zheng, Mao and Song, Mingyang and Lin, Xin and Sun, Jie and Jiang, Houcheng and Wang, Xiang and Fang, Junfeng , journal =. 2026 , url =
2026
-
[74]
arXiv preprint arXiv:2605.17497 , year =
Self-Supervised On-Policy Distillation for Reasoning Language Models , author =. arXiv preprint arXiv:2605.17497 , year =
-
[75]
arXiv preprint arXiv:2603.16856 , year =
Online Experiential Learning for Language Models , author =. arXiv preprint arXiv:2603.16856 , year =
-
[76]
arXiv preprint arXiv:2412.14528 , year =
Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation on Language Models , author =. arXiv preprint arXiv:2412.14528 , year =
-
[77]
Advances in Neural Information Processing Systems , year =
Universal Cross-Tokenizer Distillation via Approximate Likelihood Matching , author =. Advances in Neural Information Processing Systems , year =
-
[78]
2026 , url =
Yang, Shenzhi and Zhu, Guangcheng and Song, Bowen and Wang, Haobo and Xia, Mingxuan and Zheng, Xing and Ma, Yingfan and Chen, Zhongqi and Wang, Weiqiang and Chen, Gang , journal =. 2026 , url =
2026
-
[79]
2026 , url =
Yang, Zhuolin and Liu, Zihan and Chen, Yang and Dai, Wenliang and Wang, Boxin and Lin, Sheng-Chieh and Lee, Chankyu and Chen, Yangyi and Jiang, Dongfu and He, Jiafan and Pi, Renjie and Lam, Grace and Lee, Nayeon and Bukharin, Alexander and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei , journal =. 2026 , url =
2026
-
[80]
2026 , url =
Li, Fengxiang and Zhang, Han and Huang, Haoyang and Wang, Jinghui and Hao, Jinhua and Yuan, Kun and Li, Mengtong and Zhang, Minglei and Xu, Pengcheng and Zhuang, Wenhao and Shao, Yizhen and Feng, Zongxian and Tang, Can and Wang, Chao and Tong, Chengxiao and Yang, Fan and Xiong, Gang and Gao, Haixuan and Gao, Han and Wang, Hao and Liu, Haochen and Sun, Hon...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.