How Much Static Structure Do Code Agents Need? A Study of Deterministic Anchoring
Pith reviewed 2026-06-26 03:46 UTC · model grok-4.3
The pith
Injecting lightweight static structure as comments makes LLM code agents navigate repositories more predictably by disciplining exploration rather than boosting intelligence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The deterministic anchoring effect demonstrates that static structure helps less by making agents smarter and more by making their navigation disciplined and reproducible. Starting from Codex, injecting call and inheritance topology improves function-level localization by 2.2 percentage points, shortens trajectories by 1.6 rounds, raises link-following rate from 0.15-0.18 to 0.21-0.24, halves run-to-run variance, and lifts Pass@1 by 3.4 points on medium repositories at roughly 10 percent extra token cost. Optimal granularity varies with repository characteristics, favoring inverse-only links in hub-heavy projects.
What carries the argument
deterministic anchoring effect: lightweight static analysis that injects stable structural facts (call graphs, inheritance hierarchies) as plain-text comments to constrain probabilistic agent navigation
If this is right
- Lightweight call and inheritance topology improves localization accuracy and shortens interaction rounds on medium-scale repositories.
- Denser annotations show diminishing returns while inverse-only links help hub-heavy projects avoid context overload.
- Anchors raise consistent link following and cut run-to-run variance roughly in half while adding about 10 percent tokens.
- Guidelines emerge: use lightweight topology by default on medium projects and prune forward edges on large ones.
Where Pith is reading between the lines
- The reproducibility benefit may extend to other stochastic LLM tasks where navigation or search is involved.
- Scale sensitivity suggests annotation strategies will need to adapt per project rather than follow a single rule.
- Integrating such anchors directly into development environments could make agent-assisted coding more dependable in practice.
Load-bearing premise
The static analysis that produces the injected comments yields accurate structural facts that agents can parse and use without adding new errors or noise to the prompt.
What would settle it
Running the same localization tasks multiple times with and without the structural comments and checking whether the variance in trajectories and success rates stays the same or increases instead of decreasing.
Figures
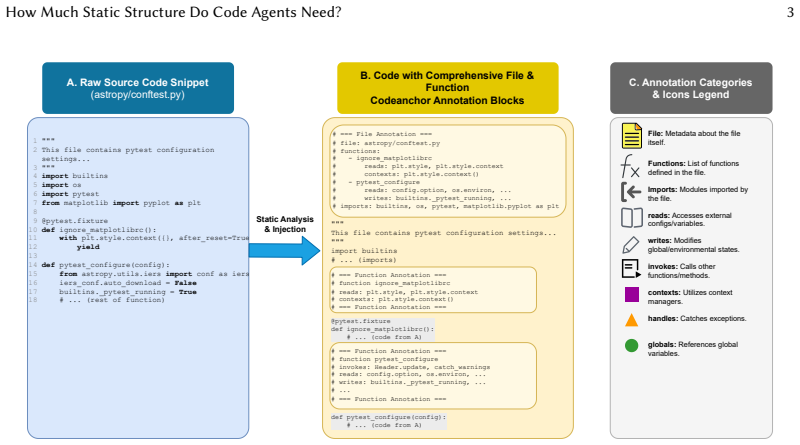
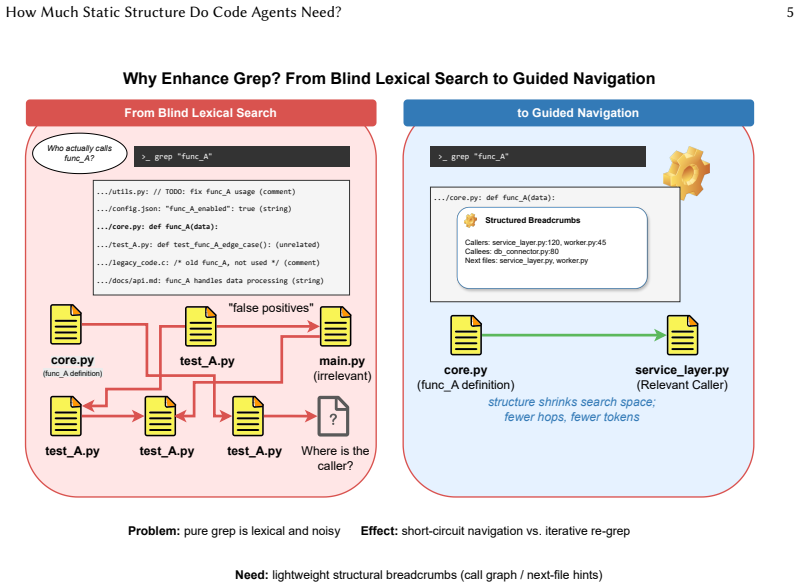
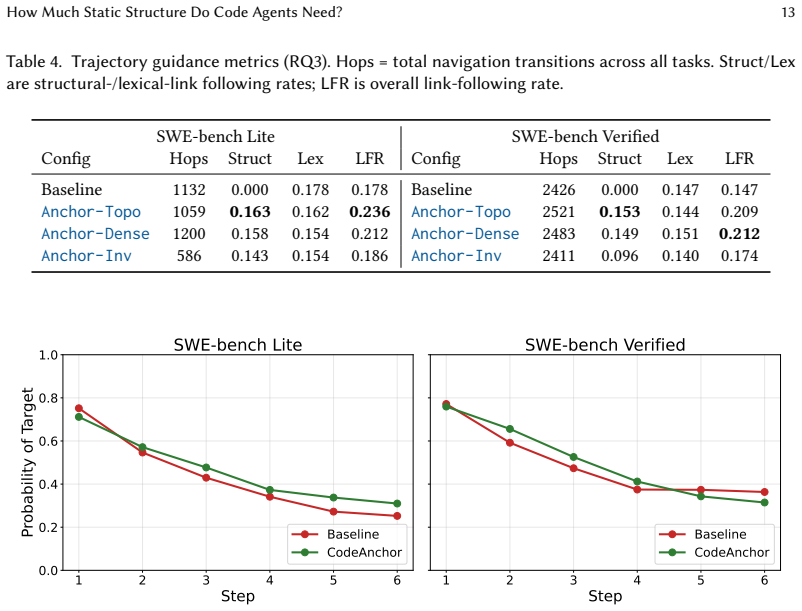
read the original abstract
LLM-based code agents navigate repositories through keyword search but miss the structural relationships, such as call graphs, inheritance hierarchies, and configuration dependencies, that define how software actually works. This makes agent navigation stochastic and difficult to reproduce across runs. We investigate whether lightweight static analysis can provide deterministic anchors for these agents: stable structural facts injected as plain-text comments that constrain probabilistic exploration and make navigation more predictable. Starting from a strong baseline, Codex from OpenAI, we systematically inject varying granularities of structural annotations and measure their effects on localization, trajectory behavior, and run-to-run stability. Our study identifies what we call the deterministic anchoring effect: static structure helps less by making agents "smarter" and more by making their navigation disciplined and reproducible. Three observations support this finding: (1) Anchoring works: lightweight call/inheritance topology improves function-level localization (+2.2pp Func@5) and shortens trajectories (-1.6 interaction rounds); (2) Anchoring is scale-sensitive: the optimal granularity and directionality depend on repository characteristics, where denser semantics show diminishing returns and hub-heavy projects benefit from inverse-only links that expose "who-calls-me" without forward edges; (3) Anchoring stabilizes: tags raise link-following rate from 0.15-0.18 to 0.21-0.24, roughly halve run-to-run variance, and improve single-run reliability (Pass@1 +3.4 pp) on medium-scale repositories, at the cost of roughly 10% more input tokens. These observations suggest practical guidelines: default to lightweight topology on medium projects, prune forward edges in large repositories, and reserve dense tags for implicit-dependency cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that lightweight static analysis can supply deterministic anchors for LLM code agents by injecting structural facts (call graphs, inheritance hierarchies) as plain-text comments. Starting from the Codex baseline, these injections improve function-level localization (+2.2pp Func@5), shorten trajectories (-1.6 rounds), raise link-following rates (0.21-0.24 vs. 0.15-0.18), halve run-to-run variance, and increase Pass@1 (+3.4pp) on medium-scale repositories, primarily by disciplining navigation rather than making agents smarter. The effect is scale-sensitive, with guidelines favoring lightweight topology on medium projects and inverse-only links on large ones, at a cost of ~10% more tokens.
Significance. If the central claims hold after validation, the work is significant for LLM-based code agent research: it supplies empirical evidence that modest static structure can measurably improve reproducibility and reliability with limited overhead, and it reframes the benefit as navigational discipline rather than semantic augmentation. The controlled-injection design against a named baseline is a methodological strength that could inform practical prompt-engineering guidelines.
major comments (2)
- [Abstract] Abstract: the deterministic-anchoring claim requires that the injected comments contain accurate structural facts that agents parse and act upon. No separate validation of static-analysis precision/recall on the studied repositories, nor any measurement of how often agents correctly reference versus ignore or misread the tags, is reported; without this, the stability gains could arise from prompt length or formatting rather than the structural content.
- [Abstract] Abstract: the reported deltas (+2.2pp Func@5, halved variance, +3.4pp Pass@1) are presented without error bars, statistical tests, dataset sizes, or exclusion criteria, leaving the quantitative support for the localization and stability claims only partially substantiated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation and statistical rigor. We address each major comment below and commit to revisions that directly strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the deterministic-anchoring claim requires that the injected comments contain accurate structural facts that agents parse and act upon. No separate validation of static-analysis precision/recall on the studied repositories, nor any measurement of how often agents correctly reference versus ignore or misread the tags, is reported; without this, the stability gains could arise from prompt length or formatting rather than the structural content.
Authors: We agree that the current manuscript lacks explicit validation of static-analysis accuracy and direct measurement of agent engagement with the injected tags. In the revision we will add (1) precision/recall figures for the call-graph and inheritance extraction on the exact repositories used and (2) a trajectory-level analysis quantifying how often agents reference, ignore, or misread the structural comments. These additions will allow us to distinguish structural content effects from prompt-length or formatting artifacts. revision: yes
-
Referee: [Abstract] Abstract: the reported deltas (+2.2pp Func@5, halved variance, +3.4pp Pass@1) are presented without error bars, statistical tests, dataset sizes, or exclusion criteria, leaving the quantitative support for the localization and stability claims only partially substantiated.
Authors: We accept that the quantitative claims require stronger statistical support. The revised manuscript will report (a) error bars or confidence intervals for all deltas, (b) results of appropriate statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests across runs), (c) exact dataset sizes and repository characteristics, and (d) any exclusion criteria applied during evaluation. These changes will make the localization and stability results fully substantiated. revision: yes
Circularity Check
Empirical measurement study with no derivation chain or fitted predictions
full rationale
The paper reports an experimental study that injects static-analysis comments into agent prompts and measures downstream effects (localization accuracy, trajectory length, variance) against the external Codex baseline. No equations, models, or predictions are derived; all results are direct empirical outcomes. No self-citations are invoked as load-bearing premises, and no quantities are fitted then re-presented as predictions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agent navigation is stochastic and can be constrained by additional factual context in the prompt
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, and Arjan JC Van Gemund. 2007. On the accuracy of spectrum-based fault localization. In Testing: Academic and Industrial Conference Practice and Research Techniques (TAIC PART-MUTATION). IEEE, 89–98
2007
-
[2]
Hiralal Agrawal and Joseph R Horgan. 1990. Dynamic program slicing.ACM SIGPlan Notices25, 6, 246–256
1990
-
[3]
Aider AI. 2024. Aider RepoMap: Using a map of your codebase.https://aider.chat/docs/repomap.html. Accessed: 2024
2024
-
[4]
Reem Aleithan. 2025. Revisiting SWE-Bench: On the Importance of Data Quality for LLM-Based Code Models. In2025 IEEE/ACM 47th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion). IEEE, 235–236. doi:10.1109/icse-companion66252.2025.00075
-
[5]
Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. 2019. code2vec: Learning distributed representations of code. InProceedings of the ACM on Programming Languages, Vol. 3. 1–29
2019
-
[6]
Florian Angermeir, Maximilian Amougou, Mark Kreitz, Andreas Bauer, Matthias Linhuber, Davide Fucci, Daniel Mendez, Tony Gorschek, et al. 2025. Reflections on the Reproducibility of Commercial LLM Performance in Empirical Software Engineering Studies. How Much Static Structure Do Code Agents Need? 19
2025
-
[7]
Anthropic. 2025. Claude Code. https://code.claude.com/docs Agentic coding assistant with repository search and file inspection
2025
-
[8]
1996.Software change impact analysis
Robert S Arnold. 1996.Software change impact analysis. IEEE Computer Society Press
1996
-
[9]
Sebastian Baltes, Florian Angermeir, Chetan Arora, Marvin Muñoz Barón, Chunyang Chen, Lukas Böhme, Fabio Calefato, Neil Ernst, Davide Falessi, Brian Fitzgerald, Davide Fucci, Marcos Kalinowski, Stefano Lambiase, Daniel Russo, Mircea Lungu, Lutz Prechelt, Paul Ralph, Rijnard van Tonder, Christoph Treude, and Stefan Wagner. 2025. Guidelines for Empirical St...
Pith/arXiv arXiv 2025
-
[10]
David Binkley. 1998. The application of program slicing to regression testing.Information and software technology40, 11-12 (1998), 583–594
1998
-
[11]
Eric Bodden, Andreas Sewe, Jan Sinschek, Hela Oueslati, and Mira Mezini. 2011. Taming reflection: Aiding static analysis in the presence of reflection and custom class loaders. InProceedings of the 33rd International Conference on Software Engineering. 241–250
2011
-
[12]
Markus Borg, Emil Alégroth, and Per Runeson. 2017. Software engineers’ information seeking behavior in change impact analysis-an interview study. In2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC). IEEE, 12–22
2017
-
[13]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2022. Codet: Code generation with generated tests.arXiv preprint arXiv:2207.10397(2022)
Pith/arXiv arXiv 2022
-
[15]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
Pith/arXiv arXiv 2021
-
[16]
Zhaoling Chen, Robert Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, and Xingyao Wang. 2025. LocAgent: Graph-Guided LLM Agents for Code Localization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Aust...
-
[17]
WALA Contributors. 2024. WALA: T. J. Watson Libraries for Analysis. https://github.com/wala/WALA. Accessed: 2026
2024
-
[18]
Patrick Cousot and Radhia Cousot. 1977. Abstract Interpretation: A Unified Lattice Model for Static Analysis of Programs by Construction or Approximation of Fixpoints. InProceedings of the 4th ACM Symposium on Principles of Programming Languages (POPL). ACM, 238–252. doi:10.1145/512950.512973
-
[19]
Michael D Ernst. 2003. Static and dynamic analysis: synergy and duality.WODA 2003: ICSE Workshop on Dynamic Analysis(2003), 24–27
2003
-
[20]
GitHub. 2024. GitHub Copilot Workspace. https://github.blog/news-insights/product-news/github- copilot-workspace/Agentic workflow for repository-level tasks
2024
-
[21]
Google. 2024. Gemini Code Assist. https://docs.cloud.google.com/gemini/docs/codeassist/overview Repository-aware coding assistant for IDEs and CI workflows
2024
-
[22]
Alex Gyori, Shuvendu K Lahiri, and Nimrod Partush. 2017. Refining interprocedural change-impact analysis using equivalence relations. InProceedings of the 26th ACM SIGSOFT international symposium on software testing and analysis. 318–328
2017
-
[23]
Vincent J Hellendoorn, Charles Sutton, Rishabh Singh, Petros Maniatis, and David Bieber. 2019. Global relational models of source code. InInternational conference on learning representations
2019
-
[24]
Susan Horwitz, Thomas W. Reps, and David W. Binkley. 1990. Interprocedural Slicing Using Dependence Graphs. ACM Transactions on Programming Languages and Systems12, 1 (1990), 26–60. doi:10.1145/77606.77608
-
[25]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[26]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE- bench: Can Language Models Resolve Real-World GitHub Issues?. InProceedings of the 12th International Conference on Learning Representations (ICLR).https://www.swebench.com/arXiv:2310.06770
Pith/arXiv arXiv 2024
-
[27]
James A Jones, Mary Jean Harrold, and John Stasko. 2002. Visualization of test information to assist fault localization. InProceedings of the 24th International Conference on Software Engineering (ICSE). ACM, 467–477
2002
-
[28]
Maria Kretsou, Elvira-Maria Arvanitou, Apostolos Ampatzoglou, Ignatios Deligiannis, and Vassilis C Gerogiannis
-
[29]
Change impact analysis: A systematic mapping study.Journal of systems and software174 (2021), 110892
2021
-
[30]
Chris Lattner and Vikram S. Adve. 2004. LLVM: A Compilation Framework for Lifelong Program Analysis and Transformation. In2nd IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE Computer Society, 75–88. doi:10.1109/CGO.2004.1281665 20 Lin et al
-
[31]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33, 9459–9474
2020
-
[32]
Bixin Li, Xiaobing Sun, Hareton Leung, and Sai Zhang. 2013. A survey of code-based change impact analysis techniques. Software Testing, Verification and Reliability23, 8 (2013), 613–646
2013
-
[33]
Fengjie Li, Jiajun Jiang, Jiajun Sun, and Hongyu Zhang. 2025. Hybrid Automated Program Repair by Combining Large Language Models and Program Analysis.ACM Transactions on Software Engineering and Methodology34, 7, Article 202 (August 2025), 28 pages. doi:10.1145/3715004
-
[34]
Xia Li, Wei Li, Yuqun Zhang, and Lingming Zhang. 2019. DeepFL: Integrating multiple fault diagnosis dimensions for deep fault localization. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). ACM, 169–180
2019
-
[35]
Junwei Liu, Yixuan Chen, Mingwei Liu, Xin Peng, and Yiling Lou. 2024. STALL+: Boosting LLM-based Repository-level Code Completion with Static Analysis.arXiv preprint arXiv:2406.10018(2024). arXiv:2406.10018 [cs.SE] https: //arxiv.org/abs/2406.10018
arXiv 2024
-
[36]
Yiling Lou, Qihao Zhu, Jinhao Dong, Xia Li, Zeyu Sun, Dan Hao, Lu Zhang, and Lingming Zhang. 2021. Boosting coverage-based fault localization via graph-based representation learning. InProceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 664–676
2021
-
[37]
Microsoft. 2016. Language Server Protocol. https://microsoft.github.io/language-server-protocol/ . Ac- cessed: 2026
2016
-
[38]
Microsoft. 2019. CodeQL: The libraries and queries that power security researchers around the world. https: //github.com/github/codeql
2019
-
[39]
Seokhyeon Moon, Yunho Kim, Moonzoo Kim, and Shin Yoo. 2014. Ask the mutants: Mutating faulty programs for fault localization. In2014 IEEE Seventh International Conference on Software Testing, Verification and Validation (ICST). IEEE, 153–162
2014
-
[40]
OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]https://arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2023
-
[41]
Alessandro Orso, Taweesup Apiwattanapong, and Mary Jean Harrold. 2003. Leveraging field data for impact analysis and regression testing.ACM SIGSOFT Software Engineering Notes28, 5, 128–137
2003
-
[42]
Siru Ouyang, Wenhao Yun, Yu Zeng, Zonghai Yang, Meng Zhang, and Jiawei Han. 2025. RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph.arXiv preprint arXiv:2410.14684(2025)
arXiv 2025
-
[43]
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. 2025. Training Software Engineering Agents and Verifiers with SWE-Gym. InForty-second International Conference on Machine Learning (ICML). OpenReview.net. arXiv:2412.21139 [cs.SE]https://openreview.net/forum?id=Cq1BNvHx74
Pith/arXiv arXiv 2025
-
[44]
Mike Papadakis and Yves Le Traon. 2015. Metallaxis-FL: Mutation-based fault localization.Software Testing, Verification and Reliability25, 5-7 (2015), 605–628
2015
-
[45]
r2c. 2020. Semgrep: Lightweight static analysis for many languages.https://semgrep.dev/
2020
-
[46]
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Founda- tions and Trends in Information Retrieval3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[47]
Barbara G Ryder. 2003. Dimensions of precision in reference analysis of object-oriented programming languages. In International Conference on Compiler Construction. Springer, 126–137
2003
-
[48]
Saha, Matthew Lease, Sarfraz Khurshid, and Dewayne E
Ripon K. Saha, Matthew Lease, Sarfraz Khurshid, and Dewayne E. Perry. 2013. Improving bug localization using structured information retrieval. In2013 28th IEEE/ACM International Conference on Automated Software Engineering, ASE 2013, Silicon Valley, CA, USA, November 11-15, 2013, Ewen Denney, Tevfik Bultan, and Andreas Zeller (Eds.). IEEE, 345–355. doi:10...
-
[49]
Vitalis Salis, Thodoris Sotiropoulos, Panos Louridas, Diomidis Spinellis, and Dimitris Mitropoulos. 2021. PyCG: Practical Call Graph Generation in Python. In43rd IEEE/ACM International Conference on Software Engineering (ICSE). IEEE, 1646–1657. doi:10.1109/ICSE43902.2021.00146arXiv:2103.00587
work page doi:10.1109/icse43902.2021.00146arxiv:2103.00587 2021
-
[50]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems 36 (NeurIPS). http://papers.nips.cc/paper_files/paper/2023/hash/ d842425e4bf79ba039352da0f6...
Pith/arXiv arXiv 2023
-
[51]
Pratik Shah, Rajat Ghosh, Aryan Singhal, and Debojyoti Dutta. 2025. RANGER – Repository-Level Agent for Graph- Enhanced Retrieval.arXiv preprint arXiv:2509.25257(2025). arXiv:2509.25257 [cs.SE] https://arxiv.org/abs/2509. 25257
arXiv 2025
-
[52]
Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. 2024. Trial and Error: Exploration- Based Trajectory Optimization for LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, How Much Static Structur...
2024
-
[53]
Frank Tip. 1994. A survey of program slicing techniques. (1994)
1994
-
[54]
Tree-sitter Contributors. 2018. Tree-sitter: An incremental parsing system for programming tools. https://github. com/tree-sitter/tree-sitter. Accessed: 2024
2018
-
[55]
Raja Vallée-Rai, Phong Co, Etienne Gagnon, Laurie Hendren, Patrick Lam, and Vijay Sundaresan. 2010. Soot: A Java bytecode optimization framework. InCASCON First Decade High Impact Papers. 214–224
2010
-
[56]
Shaowei Wang and David Lo. 2015. Amalgam+: Composing rich information sources for accurate bug localization. In Journal of Software: Evolution and Process, Vol. 27. Wiley, 921–942
2015
-
[57]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning
2024
-
[58]
Mark Weiser. 1984. Program Slicing .IEEE Transactions on Software Engineering10, 04 (July 1984), 352–357. doi:10.1109/TSE.1984.5010248
-
[59]
Chunqiu Steven Xia and Lingming Zhang. 2022. Less training, more repairing please: revisiting automated program repair via zero-shot learning. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 959–971. doi: 10.1145/3540250.3549101 arXiv:2207.08281
-
[60]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. 2024. TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks....
Pith/arXiv arXiv 2024
-
[61]
Aidan Z.H. Yang, Claire Le Goues, Ruben Martins, and Vincent J. Hellendoorn. 2024. Large Language Models for Test-Free Fault Localization. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE). 165–176. doi:10.1145/3597503.3623342
-
[62]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
-
[63]
InAdvances in Neu- ral Information Processing Systems 38 (NeurIPS)
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InAdvances in Neu- ral Information Processing Systems 38 (NeurIPS). http://papers.nips.cc/paper_files/paper/2024/hash/ 5a7c947568c1b1328ccc5230172e1e7c-Abstract-Conference.htmlarXiv:2405.15793
Pith/arXiv arXiv 2024
-
[64]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Syner- gizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[65]
Inseok Yeo, Duksan Ryu, and Jongmoon Baik. 2025. Improving LLM-Based Fault Localization with External Memory and Project Context. arXiv:2506.03585 [cs.SE]
arXiv 2025
-
[66]
Boxi Yu, Yuxuan Zhu, Pinjia He, and Daniel Kang. 2025. UTBoost: Rigorous Evaluation of Coding Agents on SWE- Bench. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria, 3762–3774. doi:10.18653/v1/2025.acl-long.189
-
[67]
Zhongming Yu, Hejia Zhang, Yujie Zhao, Hanxian Huang, Matrix Yao, Ke Ding, and Jishen Zhao. 2025. OrcaLoca: An LLM Agent Framework for Software Issue Localization. arXiv:2502.00350 [cs.SE] To appear at ICML 2025
arXiv 2025
-
[68]
Daoguang Zan, Zhirong Huang, Ailun Yu, Shaoxin Lin, Yifan Shi, Wei Liu, Dong Chen, Zongshuai Qi, Hao Yu, Lei Yu, Dezhi Ran, Muhan Zeng, Bo Shen, Guangtai Liang, Bei Guan, Pengjie Huang, Tao Xie, and Yongji Wang. 2024. SWE-bench-java: A GitHub Issue Resolving Benchmark for Java.arXiv preprint arXiv:2408.14354(2024)
arXiv 2024
-
[69]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. Repocoder: Repository-level code completion through iterative retrieval and generation.arXiv preprint arXiv:2303.12570(2023)
arXiv 2023
-
[70]
Jian Zhou, Hongyu Zhang, and David Lo. 2012. Where should the bugs be fixed? More accurate information retrieval- based bug localization based on bug reports. In34th International Conference on Software Engineering, ICSE 2012, June 2-9, 2012, Zurich, Switzerland, Martin Glinz, Gail C. Murphy, and Mauro Pezzè (Eds.). IEEE Computer Society, 14–24. doi:10.11...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.