φ-Scene: Physically Grounded Image-to-3D Scene Reconstruction
Pith reviewed 2026-06-26 14:48 UTC · model grok-4.3
The pith
φ-Scene turns single-image scene reconstruction into sequential physical assembly by inferring supports, resolving penetrations with SDFs, and settling objects via rigid-body simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
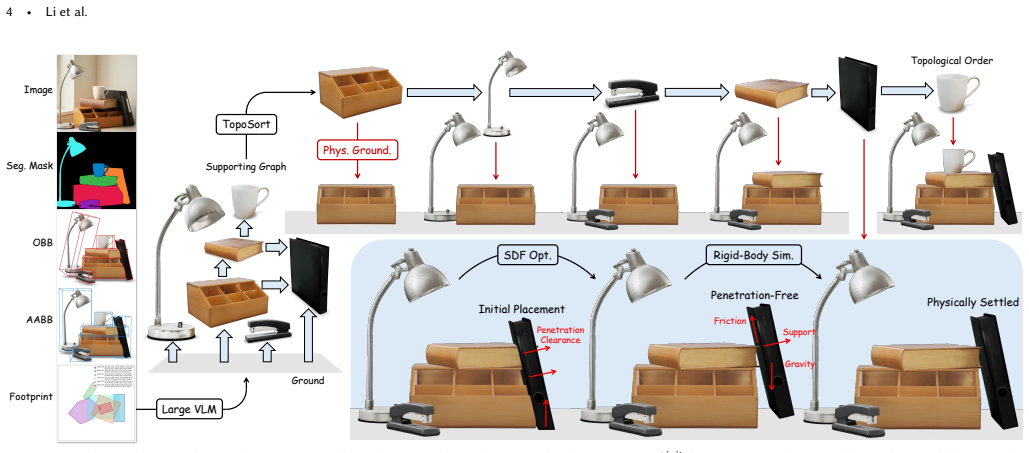
φ-Scene formulates reconstruction as topology-driven physical assembly: it infers how objects support one another, orders them accordingly, and progressively settles each object against its already stabilized support context. For each object in topological order, SDF-based optimization first resolves penetrations against the pre-settled support context, and rigid-body simulation then settles the object into a stable contact configuration under real-world physical constraints. On 3D-Front this yields the strongest overall performance among out-of-domain methods, remains competitive with in-domain baselines, and produces substantially lower penetration artifacts and post-simulation drift.
What carries the argument
Topology-driven physical assembly: inferring support relations from the image to produce a processing order, then sequentially applying SDF-based penetration resolution against settled supports followed by rigid-body simulation for stable contact.
If this is right
- Reconstructed scenes contain fewer floating objects and interpenetrations than purely geometric baselines.
- Physical plausibility metrics show reduced static contact errors and lower dynamic drift after simulation.
- Human and VLM raters assign higher scores for visual quality, reference alignment, and physical validity.
- The method works for open-vocabulary compositional scenes without domain-specific retraining.
- Outputs become more directly usable in simulation, robotics, and interactive environments.
Where Pith is reading between the lines
- The same support-ordering plus physics-settling loop could be applied to text-to-3D pipelines if support inference is adapted to language descriptions.
- Adding multi-view consistency checks before the physics stage might further reduce drift on real-world photographs.
- The topological ordering step could serve as a lightweight prior for other scene-understanding tasks such as affordance prediction.
- If support inference fails on highly occluded objects, the downstream SDF and simulation stages would inherit those errors.
Load-bearing premise
That support relations can be reliably inferred from the image and that the sequence of SDF resolution plus rigid-body simulation will produce stable scenes without new instabilities or scene-specific tuning.
What would settle it
Scenes with complex stacking where, after the full pipeline, either penetrations remain visible or post-simulation drift exceeds the levels reported on 3D-Front.
Figures






read the original abstract
Reconstructing compositional 3D scenes from a single image is a fundamental challenge in 3D world modeling. Recent methods can recover high-fidelity, complete 3D objects and predict plausible scene arrangements, but most still treat scene reconstruction primarily as a visual and geometric prediction problem. Their outputs may therefore contain floating objects, interpenetrations, or unstable-contact artifacts, limiting their physical validity and downstream usability in simulation, robotics, and interactive environments. We present $\phi$-Scene, a physically grounded approach to open-vocabulary and compositional image-to-3D scene reconstruction. The key premise is that a reconstructed scene should not be treated merely as a set of objects with predicted poses, but as a stable physical system. Accordingly, $\phi$-Scene formulates reconstruction as topology-driven physical assembly: it infers how objects support one another, orders them accordingly, and progressively settles each object against its already stabilized support context. For each object in topological order, SDF-based optimization first resolves penetrations against the pre-settled support context, and rigid-body simulation then settles the object into a stable contact configuration under real-world physical constraints. Experiments on 3D-Front show that $\phi$-Scene achieves the strongest overall performance among out-of-domain methods and remains highly competitive with in-domain baselines. Human and VLM evaluations further show strong preference for $\phi$-Scene in visual quality, reference alignment, and physical plausibility. Finally, dedicated physical plausibility metrics covering static contact quality and dynamic stability demonstrate that $\phi$-Scene substantially reduces penetration artifacts while producing much lower post-simulation drift, indicating more stable and physically grounded 3D scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
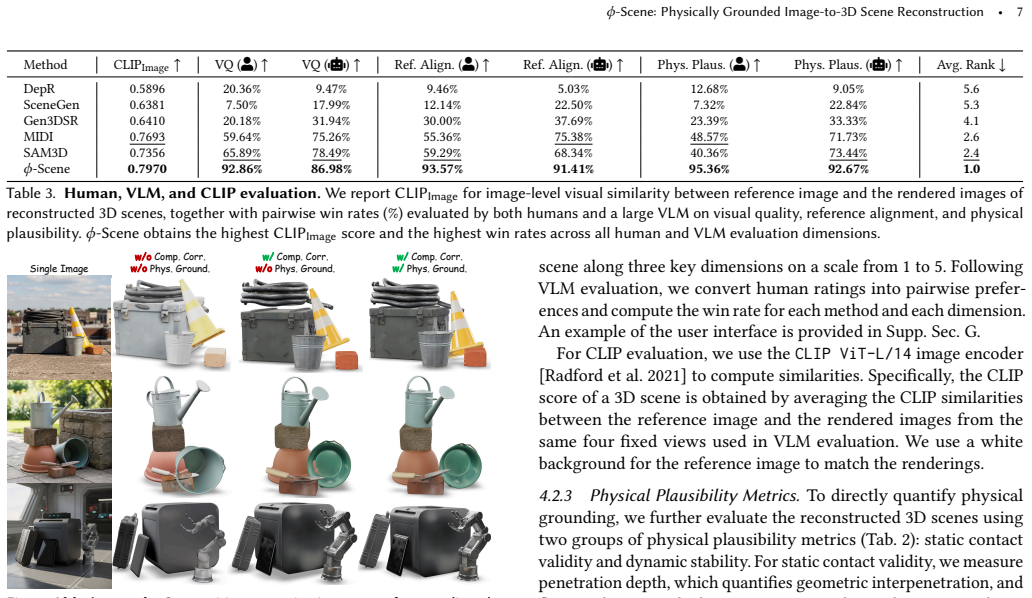
Summary. The paper presents φ-Scene, a method for open-vocabulary image-to-3D scene reconstruction that treats the output as a stable physical system. It infers support relations from the input image, imposes a topological order on objects, resolves interpenetrations via SDF-based optimization against already-settled context, and applies rigid-body simulation to reach stable contact configurations. On the 3D-Front dataset the method reports the strongest results among out-of-domain baselines, remains competitive with in-domain methods, receives favorable human and VLM judgments on visual quality and physical plausibility, and shows substantially lower penetration artifacts together with reduced post-simulation drift on dedicated physical metrics.
Significance. If the empirical claims hold, the work supplies a concrete route to physically valid compositional 3D scenes from single images, directly addressing a limitation that currently restricts downstream use in simulation and robotics. The introduction of explicit physical-plausibility metrics and the combination of human/VLM preference studies with quantitative drift measurements constitute a useful evaluation template for the field.
major comments (2)
- [§4 (method) and Experiments] The central claim that support inference plus SDF penetration resolution plus topo-ordered rigid-body simulation produces stable scenes without per-scene tuning rests on the assumption that support-relation errors do not create cycles or invalid orderings and that the SDF optimization always finds feasible non-penetrating poses. The manuscript provides no quantitative analysis of support-inference accuracy, failure cases, or sensitivity to ordering errors (e.g., in §4 or the supplementary material), leaving the robustness of the pipeline unverified.
- [Experiments / physical metrics] Table 2 (or equivalent results table) reports lower post-simulation drift for φ-Scene, yet the simulation parameters (friction coefficients, solver tolerances, number of simulation steps) and the precise definition of the drift metric are not stated. Without these, it is impossible to determine whether the reported stability advantage is reproducible or requires hidden tuning, directly bearing on the physical-validity claim.
minor comments (2)
- [§3] Notation for the topological ordering and the SDF optimization objective should be introduced with explicit equations rather than prose descriptions only.
- [Abstract] The abstract states that the method is “highly competitive with in-domain baselines,” but the corresponding quantitative numbers and the exact in-domain methods are not listed in the abstract; a short parenthetical summary would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The two major comments raise important points about pipeline robustness and reproducibility of the physical metrics. We address each below.
read point-by-point responses
-
Referee: [§4 (method) and Experiments] The central claim that support inference plus SDF penetration resolution plus topo-ordered rigid-body simulation produces stable scenes without per-scene tuning rests on the assumption that support-relation errors do not create cycles or invalid orderings and that the SDF optimization always finds feasible non-penetrating poses. The manuscript provides no quantitative analysis of support-inference accuracy, failure cases, or sensitivity to ordering errors (e.g., in §4 or the supplementary material), leaving the robustness of the pipeline unverified.
Authors: We agree that an explicit quantitative breakdown of support-inference accuracy would strengthen the robustness claim. The end-to-end physical metrics (penetration reduction and drift) provide indirect validation, but do not isolate support errors. In the revised version we will add, in the supplementary material, precision/recall numbers for the support predictor on 3D-Front, a set of failure-case visualizations, and a sensitivity experiment that perturbs the topological order and measures resulting drift. These additions directly address the concern without altering the core method. revision: yes
-
Referee: [Experiments / physical metrics] Table 2 (or equivalent results table) reports lower post-simulation drift for φ-Scene, yet the simulation parameters (friction coefficients, solver tolerances, number of simulation steps) and the precise definition of the drift metric are not stated. Without these, it is impossible to determine whether the reported stability advantage is reproducible or requires hidden tuning, directly bearing on the physical-validity claim.
Authors: The simulation parameters (friction coefficient 0.7, solver tolerance 1e-6, 500 settling steps) and the drift metric (mean object-center displacement after an additional 1000 gravity steps) are specified in supplementary Section C.2. We acknowledge that placing these details only in the supplement reduces immediate reproducibility. In the revision we will insert a short paragraph in the main-text physical-metrics subsection that reproduces the key parameters and metric definition, ensuring the results can be reproduced from the main paper alone. revision: yes
Circularity Check
No circularity: method uses standard primitives without self-referential derivations
full rationale
The paper presents a procedural pipeline (support inference, topological ordering, SDF-based penetration resolution, rigid-body simulation) built from established computer graphics and physics simulation components. No equations, fitted parameters, or predictions are described that reduce the output to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The approach is self-contained against external benchmarks and does not rename known results or smuggle ansatzes via prior work. This is the expected non-finding for a methods paper relying on off-the-shelf primitives.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Zero-1-to-3: Zero-shot one image to 3d object , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[2]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Luciddreamer: Towards high-fidelity text-to-3d generation via interval score matching , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[6]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deepsdf: Learning continuous signed distance functions for shape representation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
, author=
3d gaussian splatting for real-time radiance field rendering. , author=. ACM Trans. Graph. , volume=
-
[9]
Proceedings of the European conference on computer vision (ECCV) , pages=
Pixel2mesh: Generating 3d mesh models from single rgb images , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[10]
Advances in Neural Information Processing Systems , volume=
Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2209.14988 , year=
Dreamfusion: Text-to-3d using 2d diffusion , author=. arXiv preprint arXiv:2209.14988 , year=
-
[12]
Advances in neural information processing systems , volume=
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation , author=. Advances in neural information processing systems , volume=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Magic3d: High-resolution text-to-3d content creation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
arXiv preprint arXiv:2312.02201 , year=
Imagedream: Image-prompt multi-view diffusion for 3d generation , author=. arXiv preprint arXiv:2312.02201 , year=
-
[15]
arXiv preprint arXiv:2306.17843 , year=
Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors , author=. arXiv preprint arXiv:2306.17843 , year=
-
[16]
arXiv preprint arXiv:2308.16512 , year=
Mvdream: Multi-view diffusion for 3d generation , author=. arXiv preprint arXiv:2308.16512 , year=
-
[17]
arXiv preprint arXiv:2309.03453 , year=
Syncdreamer: Generating multiview-consistent images from a single-view image , author=. arXiv preprint arXiv:2309.03453 , year=
-
[18]
arXiv preprint arXiv:2310.15110 , year=
Zero123++: a single image to consistent multi-view diffusion base model , author=. arXiv preprint arXiv:2310.15110 , year=
-
[19]
arXiv preprint arXiv:2310.08092 , year=
Consistent123: Improve consistency for one image to 3d object synthesis , author=. arXiv preprint arXiv:2310.08092 , year=
-
[20]
European Conference on Computer Vision , pages=
Cascade-zero123: One image to highly consistent 3d with self-prompted nearby views , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[21]
Advances in Neural Information Processing Systems , volume=
One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Wonder3d: Single image to 3d using cross-domain diffusion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
arXiv preprint arXiv:2311.04400 , year=
Lrm: Large reconstruction model for single image to 3d , author=. arXiv preprint arXiv:2311.04400 , year=
-
[25]
arXiv preprint arXiv:2403.02151 , year=
Triposr: Fast 3d object reconstruction from a single image , author=. arXiv preprint arXiv:2403.02151 , year=
-
[26]
European conference on computer vision , pages=
Crm: Single image to 3d textured mesh with convolutional reconstruction model , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[27]
arXiv preprint arXiv:2404.07191 , year=
Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models , author=. arXiv preprint arXiv:2404.07191 , year=
-
[28]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Sf3d: Stable fast 3d mesh reconstruction with uv-unwrapping and illumination disentanglement , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[29]
arXiv preprint arXiv:1512.03012 , year=
Shapenet: An information-rich 3d model repository , author=. arXiv preprint arXiv:1512.03012 , year=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Objaverse: A universe of annotated 3d objects , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Advances in Neural Information Processing Systems , volume=
Objaverse-xl: A universe of 10m+ 3d objects , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Abo: Dataset and benchmarks for real-world 3d object understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Structured 3d latents for scalable and versatile 3d generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[34]
arXiv preprint arXiv:2512.14692 , year=
Native and compact structured latents for 3d generation , author=. arXiv preprint arXiv:2512.14692 , year=
-
[35]
2025 , eprint=
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details , author=. 2025 , eprint=
2025
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[39]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
3dtopia-xl: Scaling high-quality 3d asset generation via primitive diffusion , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[40]
Seed3D 1.0: From Images to High-Fidelity Simulation-Ready 3D Assets , author=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Graphdreamer: Compositional 3d scene synthesis from scene graphs , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
SIGGRAPH Asia 2024 Conference Papers , pages=
Discene: Object decoupling and interaction modeling for complex scene generation , author=. SIGGRAPH Asia 2024 Conference Papers , pages=
2024
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Discoscene: Spatially disentangled generative radiance fields for controllable 3d-aware scene synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[44]
Pattern Recognition , pages=
Layoutdreamer: Physics-guided layout for text-to-3d compositional scene generation , author=. Pattern Recognition , pages=. 2026 , publisher=
2026
-
[45]
2025 International Conference on 3D Vision (3DV) , pages=
Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view , author=. 2025 International Conference on 3D Vision (3DV) , pages=. 2025 , organization=
2025
-
[46]
ACM Transactions on Graphics (TOG) , volume=
Cast: Component-aligned 3d scene reconstruction from an rgb image , author=. ACM Transactions on Graphics (TOG) , volume=. 2025 , publisher=
2025
-
[47]
arXiv preprint arXiv:2410.07408 , year=
Automated creation of digital cousins for robust policy learning , author=. arXiv preprint arXiv:2410.07408 , year=
-
[48]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Artiscene: Language-driven artistic 3d scene generation through image intermediary , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[49]
arXiv preprint arXiv:2505.02836 , year=
Scenethesis: A language and vision agentic framework for 3d scene generation , author=. arXiv preprint arXiv:2505.02836 , year=
-
[50]
arXiv preprint arXiv:2508.15769 , year=
Scenegen: Single-image 3d scene generation in one feedforward pass , author=. arXiv preprint arXiv:2508.15769 , year=
-
[51]
arXiv preprint arXiv:2511.16624 , year=
Sam 3d: 3dfy anything in images , author=. arXiv preprint arXiv:2511.16624 , year=
-
[52]
arXiv e-prints , pages=
CUPID: Pose-Grounded Generative 3D Reconstruction from a Single Image , author=. arXiv e-prints , pages=
-
[53]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Depr: Depth guided single-view scene reconstruction with instance-level diffusion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[54]
arXiv preprint arXiv:2509.23607 , year=
ZeroScene: A Zero-Shot Framework for 3D Scene Generation from a Single Image and Controllable Texture Editing , author=. arXiv preprint arXiv:2509.23607 , year=
-
[55]
arXiv preprint arXiv:2402.07207 , year=
Gala3d: Towards text-to-3d complex scene generation via layout-guided generative gaussian splatting , author=. arXiv preprint arXiv:2402.07207 , year=
-
[56]
arXiv preprint arXiv:2311.17907 , year=
Cg3d: Compositional generation for text-to-3d via gaussian splatting , author=. arXiv preprint arXiv:2311.17907 , year=
-
[57]
arXiv preprint arXiv:2303.13843 , year=
Componerf: Text-guided multi-object compositional nerf with editable 3d scene layout , author=. arXiv preprint arXiv:2303.13843 , year=
-
[58]
2026 , howpublished =
2026
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Midi: Multi-instance diffusion for single image to 3d scene generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
arXiv preprint arXiv:2511.21978 , year=
PAT3D: Physics-Augmented Text-to-3D Scene Generation , author=. arXiv preprint arXiv:2511.21978 , year=
-
[61]
Advances in Neural Information Processing Systems , volume=
Phyrecon: Physically plausible neural scene reconstruction , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
arXiv preprint arXiv:2511.16719 , year=
Sam 3: Segment anything with concepts , author=. arXiv preprint arXiv:2511.16719 , year=
-
[63]
arXiv preprint arXiv:2408.00714 , year=
Sam 2: Segment anything in images and videos , author=. arXiv preprint arXiv:2408.00714 , year=
-
[64]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[65]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
3d-front: 3d furnished rooms with layouts and semantics , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[66]
arXiv preprint arXiv:2603.16869 , year=
SegviGen: Repurposing 3D Generative Model for Part Segmentation , author=. arXiv preprint arXiv:2603.16869 , year=
-
[67]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[68]
arXiv preprint arXiv:2507.02546 , year=
Moge-2: Accurate monocular geometry with metric scale and sharp details , author=. arXiv preprint arXiv:2507.02546 , year=
-
[69]
ACM Transactions on Graphics (TOG) , volume=
Diffcad: Weakly-supervised probabilistic cad model retrieval and alignment from an rgb image , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
2024
-
[70]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Reparo: Compositional 3d assets generation with differentiable 3d layout alignment , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[71]
International Journal of Computer Vision , volume=
3d-future: 3d furniture shape with texture , author=. International Journal of Computer Vision , volume=. 2021 , publisher=
2021
-
[72]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Pix3d: Dataset and methods for single-image 3d shape modeling , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[73]
arXiv preprint arXiv:1709.06158 , year=
Matterport3d: Learning from rgb-d data in indoor environments , author=. arXiv preprint arXiv:1709.06158 , year=
-
[74]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Sun rgb-d: A rgb-d scene understanding benchmark suite , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[75]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Total3dunderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[76]
European Conference on Computer Vision , pages=
Towards high-fidelity single-view holistic reconstruction of indoor scenes , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[77]
2024 International Conference on 3D Vision (3DV) , pages=
Single-view 3d scene reconstruction with high-fidelity shape and texture , author=. 2024 International Conference on 3D Vision (3DV) , pages=. 2024 , organization=
2024
-
[78]
Advances in Neural Information Processing Systems , volume=
Panoptic 3d scene reconstruction from a single rgb image , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Uni-3d: A universal model for panoptic 3d scene reconstruction , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[80]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.