MedCAGD: Context-Aware Gated Decoder for Efficient Medical Image Segmentation
Pith reviewed 2026-07-02 15:24 UTC · model grok-4.3
The pith
A context-aware gated decoder translates pretrained encoder features into more accurate medical image segmentations by regulating multi-scale fusion and injecting global context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
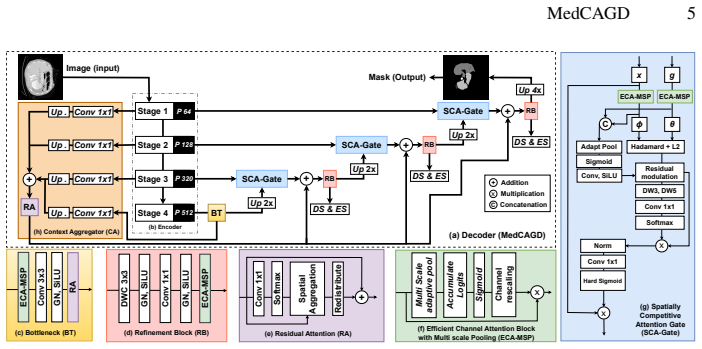
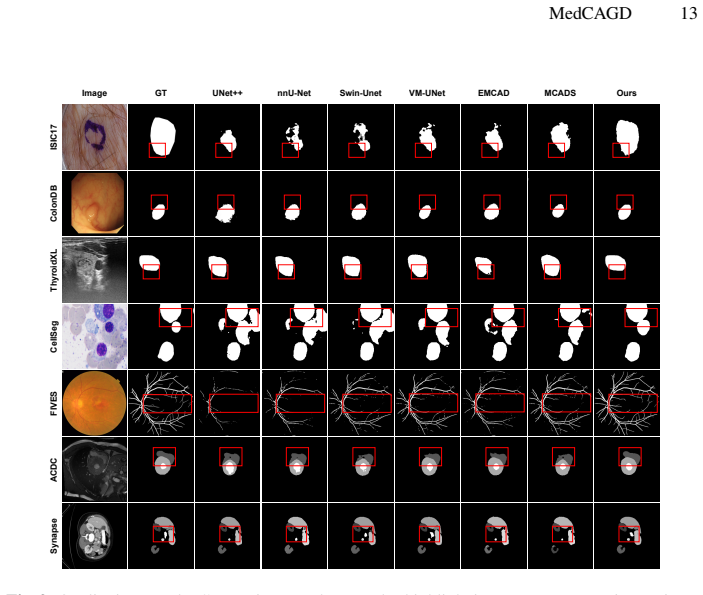
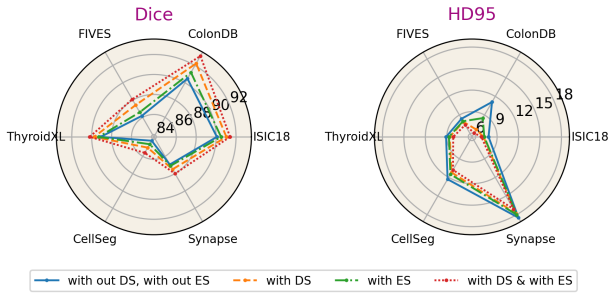
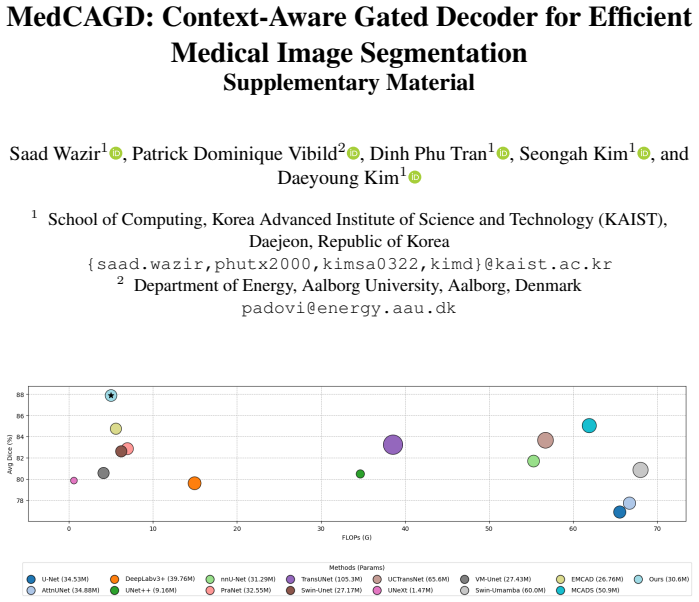
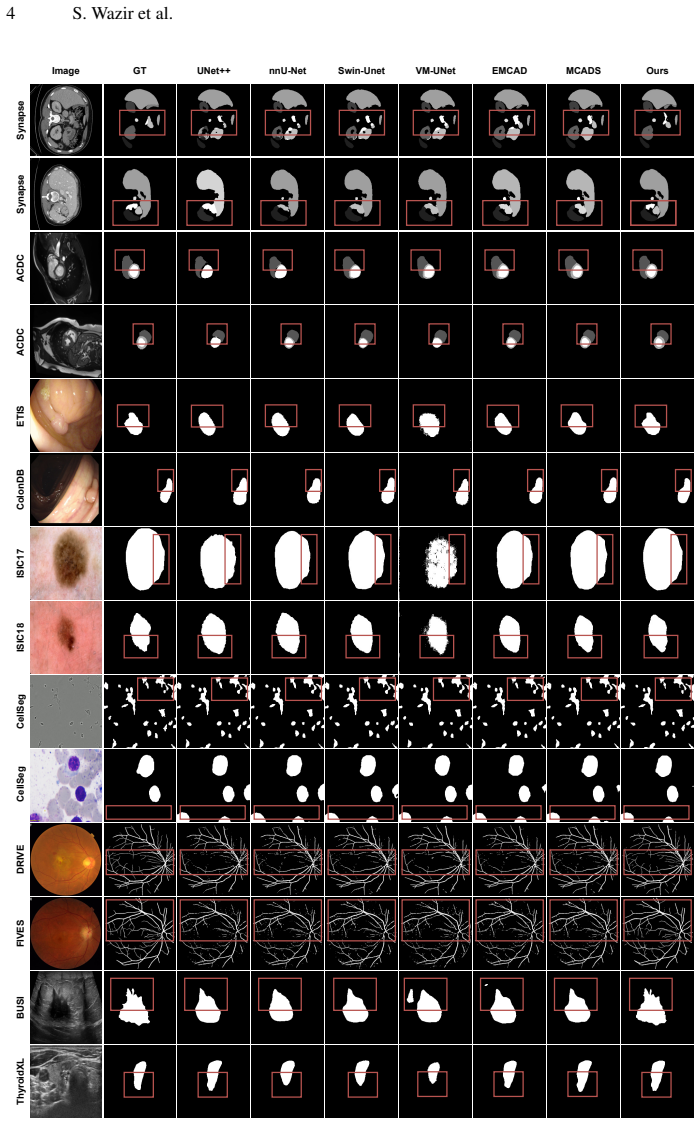
The central claim is that a context-aware gated decoder, built from multi-scale channel recalibration, gated skip fusion with spatial competition, and global context aggregation, enables effective translation of rich pretrained encoder representations into spatially consistent pixel predictions under conditions of low contrast, structural ambiguity, and scale variability, as shown by consistent gains over strong baselines on eleven medical image segmentation benchmarks while remaining computationally practical.
What carries the argument
The context-aware gated decoder, which systematically regulates feature fusion through lightweight multi-scale channel recalibration, gated skip connections with spatial competition, and global context aggregation that injects encoder-wide information into intermediate stages.
If this is right
- Segmentation accuracy improves across eleven diverse medical image benchmarks while keeping computational cost practical.
- Strong pretrained encoders become more useful because their features are better aligned and aggregated during decoding.
- Boundary preservation and cross-scale consistency increase without requiring heavier models or more training data.
- The same decoder components can be dropped into existing encoder-decoder pipelines to upgrade performance with minimal overhead.
Where Pith is reading between the lines
- If decoder-centric fixes work here, similar gated and context mechanisms could be tested on non-medical segmentation tasks where pretrained encoders are already strong.
- The design suggests that future work might compare decoder upgrades directly against encoder scaling to decide where to allocate compute.
- Global context injection at multiple decoding stages could be examined for its effect on small-object detection in the same medical datasets.
Load-bearing premise
That decoder design, rather than further encoder improvements or changes in training protocol, is the main remaining bottleneck after large-scale pretraining.
What would settle it
An ablation or comparison experiment in which replacing or upgrading the encoder alone produces equal or larger gains than adding the proposed decoder, or in which the new decoder shows no accuracy lift on the same benchmarks.
Figures
read the original abstract
Medical image segmentation relies on the ability of encoder-decoder architectures to translate rich feature representations into accurate pixel-level predictions under challenging conditions such as low contrast, structural ambiguity, and scale variability. While recent advances in large-scale pretraining and transformer-based encoders have substantially improved feature extraction, segmentation accuracy remains constrained by decoder design, particularly in terms of cross-scale alignment, contextual integration, and boundary preservation. In this work, we revisit medical image segmentation from a decoder-centric perspective and propose a context-aware gated decoder that systematically regulates feature fusion and contextual aggregation throughout the decoding process. The proposed decoder integrates lightweight multi-scale channel recalibration, gated skip fusion with spatial competition and a global context aggregation mechanism that injects encoder-wide information into intermediate decoding stages. This design enables effective translation of strong pretrained encoder representations into spatially consistent predictions. Extensive experiments across 11 medical image segmentation benchmarks validate the effectiveness and demonstrate that the proposed approach consistently outperforms strong baselines while remaining computationally practical. Code: https://github.com/saadwazir/MedCAGD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MedCAGD, a context-aware gated decoder for medical image segmentation. It integrates lightweight multi-scale channel recalibration, gated skip fusion with spatial competition, and a global context aggregation mechanism to improve feature fusion and contextual integration in the decoding process, aiming to better translate pretrained encoder representations into accurate segmentations. The paper reports extensive experiments on 11 benchmarks showing consistent outperformance over strong baselines while remaining computationally practical.
Significance. If the results hold under controlled conditions, the work could be significant by providing a decoder-centric improvement that addresses cross-scale alignment, contextual integration, and boundary preservation in medical segmentation after encoder advances, while remaining computationally practical.
major comments (1)
- [Experiments] The central claim that decoder design (rather than encoder quality or training protocol) is the primary remaining bottleneck after large-scale pretraining requires a controlled ablation that holds the pretrained encoder and training protocol fixed while swapping only the proposed decoder components. The current experimental comparisons of complete models against baselines do not provide this isolation, so observed gains cannot be unambiguously attributed to the multi-scale recalibration, gated skip fusion, or global context aggregation mechanisms.
minor comments (1)
- [Abstract] The abstract states that the approach 'consistently outperforms strong baselines' but supplies no quantitative margins, error bars, or statistical tests; these should be summarized with specific numbers and significance levels in the abstract or early in the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will incorporate revisions to strengthen the experimental isolation of decoder contributions.
read point-by-point responses
-
Referee: [Experiments] The central claim that decoder design (rather than encoder quality or training protocol) is the primary remaining bottleneck after large-scale pretraining requires a controlled ablation that holds the pretrained encoder and training protocol fixed while swapping only the proposed decoder components. The current experimental comparisons of complete models against baselines do not provide this isolation, so observed gains cannot be unambiguously attributed to the multi-scale recalibration, gated skip fusion, or global context aggregation mechanisms.
Authors: We agree that controlled ablations isolating the decoder would provide stronger support for attributing gains specifically to our proposed components. While our experiments demonstrate consistent gains over strong baselines using pretrained encoders and include internal module ablations, the current setup compares full models. In the revised manuscript, we will add experiments that fix the pretrained encoder (e.g., ResNet or ViT backbone) and training protocol across variants, then directly compare our context-aware gated decoder against standard decoders (U-Net-style, FPN) and other recent designs. This will isolate the contributions of multi-scale channel recalibration, gated skip fusion with spatial competition, and global context aggregation. revision: yes
Circularity Check
No derivation chain; architectural proposal with empirical validation
full rationale
The paper presents an architectural proposal for a context-aware gated decoder, integrating multi-scale recalibration, gated skip fusion, and global context aggregation. It makes no mathematical derivations, first-principles predictions, or fitted-parameter claims that could reduce to inputs by construction. Validation rests on experiments across 11 benchmarks comparing complete models to baselines. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is empirical outperformance rather than a closed derivation, so no circularity is present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data in brief28, 104863 (2020).https://doi.org/10.1016/j.dib.2019
Al-Dhabyani, W., Gomaa, M., Khaled, H., Fahmy, A.: Dataset of breast ultrasound im- ages. Data in brief28, 104863 (2020).https://doi.org/10.1016/j.dib.2019. 104863
-
[2]
Bernard, O., Lalande, A., Zotti, C., Cervenansky, F., Yang, X., Heng, P.A., Cetin, I., Lekadir, K., Camara, O., Ballester, M.A.G., et al.: Deep learning techniques for automatic mri car- diac multi-structures segmentation and diagnosis: is the problem solved? IEEE transactions on medical imaging37(11), 2514–2525 (2018).https://doi.org/10.1109/TMI. 2018.2837502
work page doi:10.1109/tmi 2018
-
[3]
Codella, N., Rotemberg, V ., Tschandl, P., Celebi, M.E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., et al.: Skin lesion analysis toward melanoma detec- tion 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv preprint arXiv:1902.03368 (2019).https://doi.org/10.48550/arXiv.1902. 03368
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902 2018
-
[4]
In: 2018 IEEE 15th interna- tional symposium on biomedical imaging (ISBI 2018)
Codella, N.C., Gutman, D., Celebi, M.E., Helba, B., Marchetti, M.A., Dusza, S.W., Kalloo, A., Liopyris, K., Mishra, N., Kittler, H., et al.: Skin lesion analysis toward melanoma de- tection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In: 2018 IEEE 15th intern...
-
[5]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Duong, V .H., Vu, H., Phan, H.D., Nguyen, D.Q., Pham, D.H., Le, Q.T., Nguyen, B.S., Do, T.D., Dinh, V .S., Nguyen, T.C., et al.: Thyroidxl: Advancing thyroid nodule diagnosis with an expert-labeled, pathology-validated dataset. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 616–626. Springer (2025).https: /...
-
[6]
Scientific data 9(1), 475 (2022).https://doi.org/10.1038/s41597-022-01564-3
Jin, K., Huang, X., Zhou, J., Li, Y ., Yan, Y ., Sun, Y ., Zhang, Q., Wang, Y ., Ye, J.: Fives: A fundus image dataset for artificial intelligence based vessel segmentation. Scientific data 9(1), 475 (2022).https://doi.org/10.1038/s41597-022-01564-3
-
[7]
Landman, B., Xu, Z., Igelsias, J., Styner, M., Langerak, T., Klein, A.: Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge. In: Proc. MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge. vol. 5, p. 12 (2015).https:// doi.org/10.7303/syn3193805
-
[8]
Na- ture Methods21, 1103–1113 (2024).https://doi.org/10.1038/s41592-024- 02233-6 MedCAGD 7
Ma, J., Xie, R., Ayyadhury, S., Ge, C., Gupta, A., Gupta, R., Gu, S., Zhang, Y ., Lee, G., Kim, J., Lou, W., Li, H., Upschulte, E., Dickscheid, T., de Almeida, J.G., Wang, Y ., Han, L., Yang, X., Labagnara, M., Gligorovski, V ., Scheder, M., Rahi, S.J., Kempster, C., Pollitt, A., Espinosa, L., Mignot, T., Middeke, J.M., Eckardt, J.N., Li, W., Li, Z., Cai,...
-
[9]
Müller, D., Hartmann, D., Meyer, P., Auer, F., Rey, I.S., Kramer, F.: Miseval: A metric library for medical image segmentation evaluation. In: MIE. pp. 33–37 (2022).https://doi. org/10.48550/arXiv.2201.09395
-
[10]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Rahman, M.M., Munir, M., Marculescu, R.: Emcad: Efficient multi-scale convolutional at- tention decoding for medical image segmentation. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 11769–11779 (2024).https: //doi.org/10.48550/arXiv.2405.06880
-
[11]
IEEE Transactions on Medical Imaging23(4), 501–509 (2004).https://doi.org/10.1109/TMI.2004.825627
Staal, J., Abramoff, M., Niemeijer, M., Viergever, M., van Ginneken, B.: Ridge-based vessel segmentation in color images of the retina. IEEE Transactions on Medical Imaging23(4), 501–509 (2004).https://doi.org/10.1109/TMI.2004.825627
-
[12]
Journal of healthcare engineering2017(1), 4037190 (2017).https: //doi.org/10.1155/2017/4037190
Vázquez, D., Bernal, J., Sánchez, F.J., Fernández-Esparrach, G., López, A.M., Romero, A., Drozdzal, M., Courville, A.: A benchmark for endoluminal scene segmentation of colonoscopy images. Journal of healthcare engineering2017(1), 4037190 (2017).https: //doi.org/10.1155/2017/4037190
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.