Modeling Local, Global, and Cross-Modal Context in Multimodal 3D MRI
Pith reviewed 2026-06-26 05:26 UTC · model grok-4.3
The pith
MICViT uses four attention mechanisms to model both intra-modal and cross-modal local and global contexts in 3D multimodal brain MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
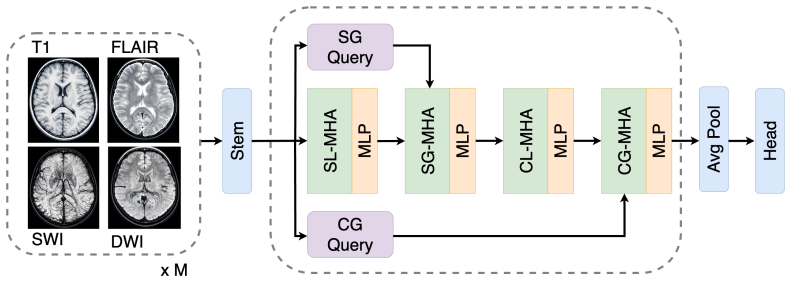
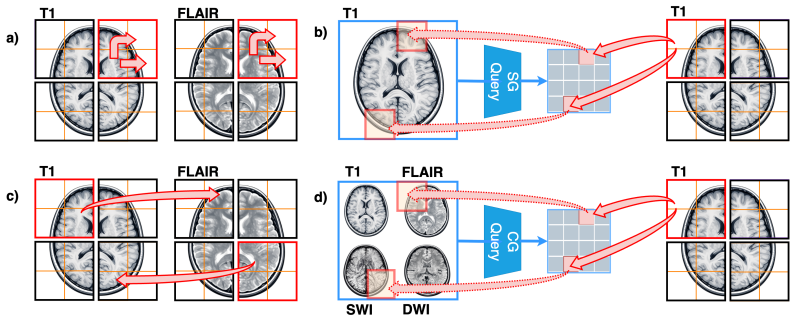
MICViT is a 3D vision transformer that combines modality-specific local attention, modality-specific global attention, cross-modal local attention, and cross-modal global attention to learn both within-modality representations and between-modality interactions, producing stronger performance on brain age prediction that increases with the number of input modalities.
What carries the argument
The four attention mechanisms in MICViT that separately process modality-specific local/global contexts and cross-modal local/global contexts.
If this is right
- Adding modalities produces larger accuracy improvements on brain age prediction than in baseline models.
- Explicit separation of intra- and cross-modal attention outperforms standard multimodal fusion approaches in 3D settings.
- Representation learning benefits when local and global scales are modeled for both within-modality and between-modality interactions.
- Neuroimaging models can better exploit complementary information from heterogeneous MRI acquisitions.
Where Pith is reading between the lines
- The same split-attention design could transfer to other 3D multimodal medical imaging tasks such as combined CT-MRI analysis.
- Clinical pipelines might achieve higher accuracy by routinely including more MRI contrasts without requiring proportionally larger training sets.
- Training protocols could be simplified if cross-modal attention reduces the need for deeper or wider networks to capture modality interactions.
Load-bearing premise
Larger gains from adding modalities are caused by the cross-modal attention rather than increased model capacity or uncontrolled training or dataset factors.
What would settle it
An ablation that removes or replaces the cross-modal attention layers while matching total parameters, training procedure, and data shows the multimodal performance advantage disappears.
Figures
read the original abstract
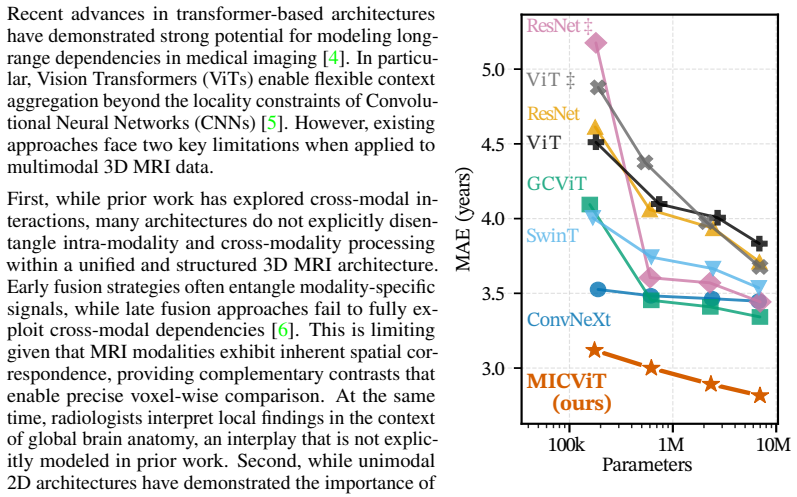
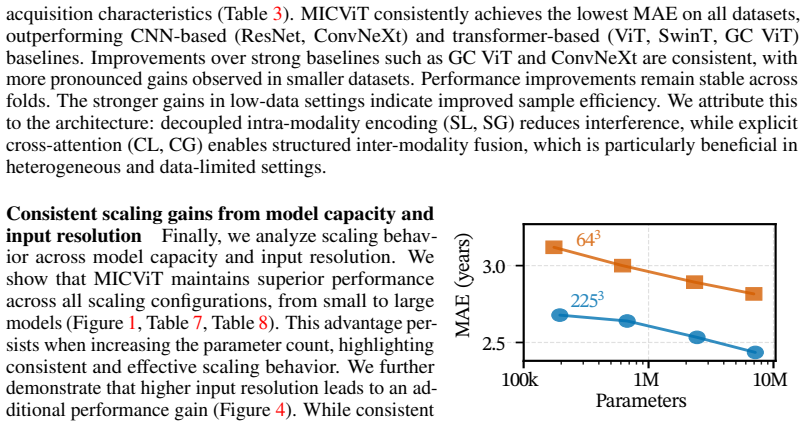
Brain MRI poses a fundamental challenge for machine learning: models must learn from high-dimensional 3D data spanning multiple co-registered modalities, despite the limited sample sizes typical of neuroimaging studies relative to the diversity in anatomy, pathology, and acquisition conditions. While multimodal imaging provides complementary information critical for clinical interpretation, effectively integrating these signals remains difficult. We propose Multimodal Intra- and Cross-Context Vision Transformer (MICViT), a 3D vision transformer that explicitly models both modality-specific representations and cross-modal interactions across local and global contexts. Concretely, MICViT combines four attention mechanisms: modality-specific local and global attention for intra-modal feature learning, and cross-modal local and global attention to capture interactions between modalities. We evaluate MICViT on brain age prediction across three heterogeneous datasets (UK Biobank, n=41,404; SOOP, n=1,062; Cam-CAN, n=613) using multiple MRI modalities (e.g. T1, FLAIR, DWI, SWI). MICViT consistently outperforms state-of-the-art CNN and transformer baselines in 3D settings. Notably, it benefits more strongly from multimodal inputs, yielding larger performance gains as additional modalities are incorporated. These results demonstrate that explicitly modeling intra- and cross-modal interactions is key to unlocking the full potential of multimodal brain MRI, highlighting a promising direction for representation learning in neuroimaging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MICViT, a 3D vision transformer for multimodal brain MRI that combines modality-specific local/global attention with cross-modal local/global attention to model intra- and inter-modal context. It reports evaluation on brain-age prediction across UK Biobank (n=41,404), SOOP (n=1,062) and Cam-CAN (n=613) using T1, FLAIR, DWI and SWI, claiming consistent superiority over CNN and transformer baselines together with larger gains as more modalities are added.
Significance. If the performance advantages can be shown to arise specifically from the four explicit attention blocks rather than capacity or training differences, the work would supply concrete evidence that explicit intra- and cross-modal context modeling improves multimodal 3D representation learning in neuroimaging, a direction of clear practical interest given the small-sample, high-dimensional nature of the domain.
major comments (2)
- [Abstract] Abstract: the central claim that MICViT 'benefits more strongly from multimodal inputs, yielding larger performance gains' is stated without any numerical deltas, error bars, baseline implementations, or ablation tables, so the magnitude and reliability of the reported multimodal scaling cannot be assessed from the provided text.
- [Evaluation] Evaluation section (implied by the abstract's results paragraph): no ablation is described that removes only the cross-modal local and global attention blocks while keeping total parameter count, optimizer schedule and data augmentation identical; without such a capacity-matched control the attribution of larger multimodal gains to the cross-modal mechanisms remains unisolated.
minor comments (1)
- [Abstract] Abstract: the phrase 'e.g. T1, FLAIR, DWI, SWI' leaves the exact modality combinations used in each reported experiment unspecified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to improve the clarity and rigor of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MICViT 'benefits more strongly from multimodal inputs, yielding larger performance gains' is stated without any numerical deltas, error bars, baseline implementations, or ablation tables, so the magnitude and reliability of the reported multimodal scaling cannot be assessed from the provided text.
Authors: We agree that the abstract's brevity makes the claim harder to evaluate in isolation. The full manuscript reports the supporting results (including MAE values with standard deviations, baseline comparisons, and modality scaling trends) in the evaluation section and associated tables. To address the concern directly, we will revise the abstract to incorporate specific numerical deltas and error bars drawn from those experiments while remaining within length limits. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the abstract's results paragraph): no ablation is described that removes only the cross-modal local and global attention blocks while keeping total parameter count, optimizer schedule and data augmentation identical; without such a capacity-matched control the attribution of larger multimodal gains to the cross-modal mechanisms remains unisolated.
Authors: This is a fair and important point for isolating the contribution of the cross-modal blocks. Our existing comparisons are against CNN and transformer baselines that lack these blocks, and we observe larger gains with additional modalities. However, a dedicated capacity-matched ablation that disables only the cross-modal local/global attention (while preserving parameter count and all training details) is not currently present. We will add this controlled ablation to the revised manuscript to strengthen the attribution. revision: yes
Circularity Check
No circularity: empirical architecture proposal evaluated on external data
full rationale
The paper introduces MICViT as a 3D vision transformer with four explicit attention blocks (modality-specific local/global and cross-modal local/global) and reports empirical performance on brain age prediction across three independent external datasets (UK Biobank, SOOP, Cam-CAN). No derivation chain, equations, or fitted parameters are presented that reduce by construction to quantities defined from the same data or prior self-citations. The central claim rests on observed outperformance and multimodal scaling in held-out evaluations rather than any self-referential definition or prediction step. This is a standard empirical comparison with no load-bearing self-referential elements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms can effectively model both intra-modal and cross-modal interactions in 3D multimodal MRI volumes
Reference graph
Works this paper leans on
-
[1]
Robert J. Gillies, Paul E. Kinahan, and Hedvig Hricak. Radiomics: Images Are More than Pictures, They Are Data.Radiology, 278(2):563–577, February 2016. ISSN 0033-8419. doi: 10.1148/radiol.2015151169. URL https://pubs.rsna.org/doi/10.1148/radiol. 2015151169
-
[2]
Mark Haacke, Robert W
E. Mark Haacke, Robert W. Brown, Michael R. Thompson, and Ramesh Venkatesan, editors. Magnetic resonance imaging: physical principles and sequence design. Wiley-Liss, New York, NY , 1999. ISBN 978-0-471-35128-3
1999
-
[3]
Marc-Andre Schulz, Danilo Bzdok, Stefan Haufe, John-Dylan Haynes, and Kerstin Rit- ter. Performance reserves in brain-imaging-based phenotype prediction.Cell Reports, 43 (1):113597, January 2024. ISSN 22111247. doi: 10.1016/j.celrep.2023.113597. URL https://linkinghub.elsevier.com/retrieve/pii/S2211124723016091
-
[4]
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L. Yuille, and Yuyin Zhou. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation, February 2021. URL http://arxiv.org/abs/2102.04306. arXiv:2102.04306 [cs]
Pith/arXiv arXiv 2021
-
[5]
Satoshi Takahashi, Yusuke Sakaguchi, Nobuji Kouno, Ken Takasawa, Kenichi Ishizu, Yu Akagi, Rina Aoyama, Naoki Teraya, Amina Bolatkan, Norio Shinkai, Hidenori Machino, Kazuma Kobayashi, Ken Asada, Masaaki Komatsu, Syuzo Kaneko, Masashi Sugiyama, and Ryuji Hamamoto. Comparison of Vision Transformers and Convolutional Neural Networks in Medical Image Analysi...
-
[6]
Shih-Cheng Huang, Anuj Pareek, Saeed Seyyedi, Imon Banerjee, and Matthew P. Lungren. Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines.npj Digital Medicine, 3(1):136, October 2020. ISSN 2398-
2020
-
[7]
URL https://www.nature.com/articles/ s41746-020-00341-z
doi: 10.1038/s41746-020-00341-z. URL https://www.nature.com/articles/ s41746-020-00341-z
-
[8]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, August 2021
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, August 2021. URLhttp://arxiv.org/abs/2103.14030. arXiv:2103.14030 [cs]
Pith/arXiv arXiv 2021
-
[9]
Global Context Vision Transformers, June 2023
Ali Hatamizadeh, Hongxu Yin, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Global Context Vision Transformers, June 2023. URL http://arxiv.org/abs/2206.09959. arXiv:2206.09959 [cs]
arXiv 2023
-
[10]
Multi-view 3D Object Detection Network for Autonomous Driving
Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3D Object Detection Network for Autonomous Driving. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6526–6534, Honolulu, HI, July 2017. IEEE. ISBN 978-1-5386- 0457-1. doi: 10.1109/CVPR.2017.691. URL http://ieeexplore.ieee.org/document/ 8100174/
-
[11]
Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y . Ng. Multimodal deep learning. InProceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, pages 689–696, Madison, WI, USA, June 2011. Omnipress. ISBN 978-1-4503-0619-5. 10
2011
-
[12]
Multimodal Machine Learning: A Survey and Taxonomy, August 2017
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal Machine Learning: A Survey and Taxonomy, August 2017. URL http://arxiv.org/abs/1705. 09406. arXiv:1705.09406 [cs]
Pith/arXiv arXiv 2017
-
[13]
Kai Sun, Siyan Xue, Fuchun Sun, Haoran Sun, Yu Luo, Ling Wang, Siyuan Wang, Na Guo, Lei Liu, Tian Zhao, Xinzhou Wang, Lei Yang, Shuo Jin, Jun Yan, and Jiahong Dong. Medical Multimodal Foundation Models in Clinical Diagnosis and Treatment: Applications, Chal- lenges, and Future Directions, December 2024. URL http://arxiv.org/abs/2412.02621. arXiv:2412.02621 [cs]
arXiv 2024
-
[14]
Na Luo, Weiyang Shi, Zhengyi Yang, Ming Song, and Tianzi Jiang. Multimodal Fusion of Brain Imaging Data: Methods and Applications.Machine Intelligence Research, 21(1): 136–152, February 2024. ISSN 2731-5398. doi: 10.1007/s11633-023-1442-8. URL https: //doi.org/10.1007/s11633-023-1442-8
-
[15]
Yihao Li, Mostafa El Habib Daho, Pierre-Henri Conze, Rachid Zeghlache, Hugo Le Boité, Ramin Tadayoni, Béatrice Cochener, Mathieu Lamard, and Gwenolé Quellec. A review of deep learning-based information fusion techniques for multimodal medical image classification, April 2024. URLhttp://arxiv.org/abs/2404.15022. arXiv:2404.15022 [cs]
arXiv 2024
-
[16]
Huntenburg, Leonie Lampe, Mehdi Rahim, Alexandre Abraham, R
Franziskus Liem, Gaël Varoquaux, Jana Kynast, Frauke Beyer, Shahrzad Kharabian Masouleh, Julia M. Huntenburg, Leonie Lampe, Mehdi Rahim, Alexandre Abraham, R. Cameron Craddock, Steffi Riedel-Heller, Tobias Luck, Markus Loeffler, Matthias L. Schroeter, Anja Veronica Witte, Arno Villringer, and Daniel S. Margulies. Predicting brain-age from multimodal imagi...
-
[17]
Quintana, Dag Alnaes, Genevieve Richard, Ann-Marie G
Jaroslav Rokicki, Thomas Wolfers, Wibeke Nordhøy, Natalia Tesli, Daniel S. Quintana, Dag Alnaes, Genevieve Richard, Ann-Marie G. de Lange, Martina J. Lund, Linn Norbom, Ingrid Agartz, Ingrid Melle, Terje Naerland, Geir Selbaek, Karin Persson, Jan Egil Nordvik, Emanuel Schwarz, Ole A. Andreassen, Tobias Kaufmann, and Lars T. Westlye. Multimodal imaging imp...
-
[18]
Jirsaraie, Aaron J
Robert J. Jirsaraie, Aaron J. Gorelik, Martins M. Gatavins, Denis A. Engemann, Ryan Bogdan, Deanna M. Barch, and Aristeidis Sotiras. A systematic review of multimodal brain age studies: Uncovering a divergence between model accuracy and utility.Patterns, 4(4):100712, April
-
[19]
doi: 10.1016/j.patter.2023.100712
ISSN 2666-3899. doi: 10.1016/j.patter.2023.100712
-
[20]
Moona Mazher, Geoff J. M. Parker, and Daniel C. Alexander. Towards Generalisable Foun- dation Models for Brain MRI, December 2025. URL http://arxiv.org/abs/2510.23415. arXiv:2510.23415 [cs]
arXiv 2025
-
[21]
Yu Liu, Yu Shi, Fuhao Mu, Juan Cheng, Chang Li, and Xun Chen. Multimodal MRI V olumetric Data Fusion With Convolutional Neural Networks.IEEE Transactions on Instrumentation and Measurement, 71:1–15, 2022. ISSN 1557-9662. doi: 10.1109/TIM.2022.3184360. URL https://ieeexplore.ieee.org/document/9800914
-
[22]
Garomsa, Anna Zapaishchykova, Tafadzwa L
Divyanshu Tak, Biniam A. Garomsa, Anna Zapaishchykova, Tafadzwa L. Chaunzwa, Juan Car- los Climent Pardo, Zezhong Ye, John Zielke, Yashwanth Ravipati, Suraj Pai, Sri Vajapeyam, Maryam Mahootiha, Mitchell Parker, Luke R. G. Pike, Ceilidh Smith, Ariana M. Familiar, Kevin X. Liu, Sanjay Prabhu, Omar Arnaout, Pratiti Bandopadhayay, Ali Nabavizadeh, Sabine Mue...
-
[23]
Osman Semih Kayhan and Jan C. van Gemert. On Translation Invariance in CNNs: Convolu- tional Layers can Exploit Absolute Spatial Location, May 2020. URL http://arxiv.org/ abs/2003.07064. arXiv:2003.07064 [cs]. 11
arXiv 2020
-
[24]
Swart, George Obaido, Matt Jordan, and Philip Ilono
Ibomoiye Domor Mienye, Theo G. Swart, George Obaido, Matt Jordan, and Philip Ilono. Deep Convolutional Neural Networks in Medical Image Analysis: A Review.Information, 16(3):195, March 2025. ISSN 2078-2489. doi: 10.3390/info16030195. URL https://www.mdpi.com/ 2078-2489/16/3/195
-
[25]
Lam, Greg Ver Steeg, and Paul M
Umang Gupta, Pradeep K. Lam, Greg Ver Steeg, and Paul M. Thompson. Improved Brain Age Estimation with Slice-based Set Networks, February 2021. URL http://arxiv.org/abs/ 2102.04438. arXiv:2102.04438 [eess]
arXiv 2021
-
[26]
Vishnu M Bashyam, Guray Erus, Jimit Doshi, Mohamad Habes, Ilya M Nasrallah, Monica Truelove-Hill, Dhivya Srinivasan, Liz Mamourian, Raymond Pomponio, Yong Fan, Lenore J Launer, Colin L Masters, Paul Maruff, Chuanjun Zhuo, Henry Völzke, Sterling C Johnson, Jurgen Fripp, Nikolaos Koutsouleris, Theodore D Satterthwaite, Daniel Wolf, Raquel E Gur, Ruben C Gur...
-
[27]
Paul Hamilton, and Anders Eklund
Johan Jönemo, Muhammad Usman Akbar, Robin Kämpe, J. Paul Hamilton, and Anders Eklund. Efficient Brain Age Prediction from 3D MRI V olumes Using 2D Projections.Brain Sciences, 13(9):1329, September 2023. ISSN 2076-3425. doi: 10.3390/brainsci13091329. URL https://www.mdpi.com/2076-3425/13/9/1329
-
[28]
Beckmann, Andrea Vedaldi, and Stephen M
Han Peng, Weikang Gong, Christian F. Beckmann, Andrea Vedaldi, and Stephen M. Smith. Accurate brain age prediction with lightweight deep neural networks.Medical Image Analysis, 68:101871, February 2021. ISSN 13618415. doi: 10.1016/j.media.2020.101871. URL https://linkinghub.elsevier.com/retrieve/pii/S1361841520302358
-
[29]
Dinsdale, Emma Bluemke, Stephen M
Nicola K. Dinsdale, Emma Bluemke, Stephen M. Smith, Zobair Arya, Diego Vidaurre, Mark Jenkinson, and Ana I. L. Namburete. Learning patterns of the ageing brain in MRI using deep convolutional networks.NeuroImage, 224:117401, January 2021. ISSN 1053-8119. doi: 10.1016/j.neuroimage.2020.117401. URL https://www.sciencedirect.com/science/ article/pii/S1053811...
-
[30]
Burkett, Hoon-Ki Min, Matthew L
Jeyeon Lee, Brian J. Burkett, Hoon-Ki Min, Matthew L. Senjem, Emily S. Lundt, Hugo Botha, Jonathan Graff-Radford, Leland R. Barnard, Jeffrey L. Gunter, Christopher G. Schwarz, Kejal Kantarci, David S. Knopman, Bradley F. Boeve, Val J. Lowe, Ronald C. Petersen, Clifford R. Jack, and David T. Jones. Deep learning-based brain age prediction in normal aging a...
2022
-
[31]
Leonardsen, Han Peng, Tobias Kaufmann, Ingrid Agartz, Ole A
Esten H. Leonardsen, Han Peng, Tobias Kaufmann, Ingrid Agartz, Ole A. Andreassen, Elisa- beth Gulowsen Celius, Thomas Espeseth, Hanne F. Harbo, Einar A. Høgestøl, Ann-Marie de Lange, Andre F. Marquand, Didac Vidal-Piñeiro, James M. Roe, Geir Selbæk, Øystein Sørensen, Stephen M. Smith, Lars T. Westlye, Thomas Wolfers, and Yunpeng Wang. Deep neural networks...
-
[32]
Sheng He, Diana Pereira, Juan David Perez, Randy L. Gollub, Shawn N. Murphy, Sanjay Prabhu, Rudolph Pienaar, Richard L. Robertson, P. Ellen Grant, and Yangming Ou. Multi- channel attention-fusion neural network for brain age estimation: Accuracy, generality, and interpretation with 16,705 healthy MRIs across lifespan.Medical Image Analysis, 72:102091, Aug...
-
[33]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, August 2023. URL http: //arxiv.org/abs/1706.03762. arXiv:1706.03762 [cs]
Pith/arXiv arXiv 2023
-
[34]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, June 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, 12 Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, June 2021. URL http://arxiv.org/abs/2010.11929. arXiv:2010.11929 [cs]
Pith/arXiv arXiv 2021
-
[35]
Landman, and S
Jun Li, Junyu Chen, Yucheng Tang, Ce Wang, Bennett A. Landman, and S. Kevin Zhou. Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives, June 2022. URL https://arxiv.org/abs/2206. 01136v3
2022
-
[36]
Sheng He, P. Ellen Grant, and Yangming Ou. Global-Local Transformer for Brain Age Estimation.IEEE Transactions on Medical Imaging, 41(1):213–224, January 2022. ISSN 0278-0062, 1558-254X. doi: 10.1109/TMI.2021.3108910. URL https://ieeexplore.ieee. org/document/9525077/
-
[37]
Triamese-ViT: A 3D-Aware Method for Robust Brain Age Estimation from MRIs, January 2024
Zhaonian Zhang and Richard Jiang. Triamese-ViT: A 3D-Aware Method for Robust Brain Age Estimation from MRIs, January 2024. URL http://arxiv.org/abs/2401.09475. arXiv:2401.09475 [cs] version: 1
arXiv 2024
-
[38]
Haiyan Zhao, Hongjie Cai, and Manhua Liu. Transformer based multi-modal MRI fusion for prediction of post-menstrual age and neonatal brain development analysis.Medical Image Analysis, 94:103140, May 2024. ISSN 13618415. doi: 10.1016/j.media.2024.103140. URL https://linkinghub.elsevier.com/retrieve/pii/S1361841524000653
-
[39]
SwiFT: Swin 4D fMRI Transformer, October
Peter Yongho Kim, Junbeom Kwon, Sunghwan Joo, Sangyoon Bae, Donggyu Lee, Yoonho Jung, Shinjae Yoo, Jiook Cha, and Taesup Moon. SwiFT: Swin 4D fMRI Transformer, October
- [40]
-
[41]
Karla L Miller, Fidel Alfaro-Almagro, Neal K Bangerter, David L Thomas, Essa Yacoub, Junqian Xu, Andreas J Bartsch, Saad Jbabdi, Stamatios N Sotiropoulos, Jesper LR Andersson, Ludovica Griffanti, Gwenaëlle Douaud, Thomas W Okell, Peter Weale, Iulius Dragonu, Steve Garratt, Sarah Hudson, Rory Collins, Mark Jenkinson, Paul M Matthews, and Stephen M Smith. M...
-
[42]
Littlejohns, Jo Holliday, Lorna M
Thomas J. Littlejohns, Jo Holliday, Lorna M. Gibson, Steve Garratt, Niels Oesingmann, Fidel Alfaro-Almagro, Jimmy D. Bell, Chris Boultwood, Rory Collins, Megan C. Conroy, Nicola Crabtree, Nicola Doherty, Alejandro F. Frangi, Nicholas C. Harvey, Paul Leeson, Karla L. Miller, Stefan Neubauer, Steffen E. Petersen, Jonathan Sellors, Simon Sheard, Stephen M. S...
-
[43]
Data11, 839, DOI: 10.1038/s41597-024-03667-5 (2024)
John Absher, Sarah Goncher, Roger Newman-Norlund, Nicholas Perkins, Grigori Yourganov, Jan Vargas, Sanjeev Sivakumar, Naveen Parti, Shannon Sternberg, Alex Teghipco, Makayla Gibson, Sarah Wilson, Leonardo Bonilha, and Chris Rorden. The stroke outcome optimization project: Acute ischemic strokes from a comprehensive stroke center.Scientific Data, 11 (1):83...
-
[44]
Meredith A Shafto, Lorraine K Tyler, Marie Dixon, Jason R Taylor, James B Rowe, Rho- dri Cusack, Andrew J Calder, William D Marslen-Wilson, John Duncan, Tim Dalgleish, Richard N Henson, Carol Brayne, and Fiona E Matthews. The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) study protocol: a cross-sectional, lifespan, multidisciplinary examination o...
-
[45]
Taylor, Nitin Williams, Rhodri Cusack, Tibor Auer, Meredith A
Jason R. Taylor, Nitin Williams, Rhodri Cusack, Tibor Auer, Meredith A. Shafto, Marie Dixon, Lorraine K. Tyler, null Cam-Can, and Richard N. Henson. The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) data repository: Structural and functional MRI, MEG, and 13 cognitive data from a cross-sectional adult lifespan sample.NeuroImage, 144(Pt B):262–269...
-
[46]
Fusion or Confusion? Multimodal Com- plexity Is Not All You Need, 2025
Tillmann Rheude, Roland Eils, and Benjamin Wild. Fusion or Confusion? Multimodal Com- plexity Is Not All You Need, 2025. URL https://arxiv.org/abs/2512.22991. Version Number: 2
Pith/arXiv arXiv 2025
-
[47]
The Road Less Scheduled, October 2024
Aaron Defazio, Xingyu Alice Yang, Harsh Mehta, Konstantin Mishchenko, Ahmed Khaled, and Ashok Cutkosky. The Road Less Scheduled, October 2024. URL http://arxiv.org/abs/ 2405.15682. arXiv:2405.15682 [cs]
arXiv 2024
-
[48]
Surrogate Gap Minimization Improves Sharpness-Aware Training, March 2022
Juntang Zhuang, Boqing Gong, Liangzhe Yuan, Yin Cui, Hartwig Adam, Nicha Dvornek, Sekhar Tatikonda, James Duncan, and Ting Liu. Surrogate Gap Minimization Improves Sharpness-Aware Training, March 2022. URL http://arxiv.org/abs/2203.08065. arXiv:2203.08065 [cs]
arXiv 2022
-
[49]
Asher Trockman and J. Zico Kolter. Mimetic Initialization of Self-Attention Layers, May 2023. URLhttp://arxiv.org/abs/2305.09828. arXiv:2305.09828 [cs]
arXiv 2023
-
[50]
On Layer Normalization in the Transformer Architecture, June 2020
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On Layer Normalization in the Transformer Architecture, June 2020. URL http://arxiv.org/abs/2002.04745. arXiv:2002.04745 [cs]
arXiv 2020
-
[51]
A ConvNet for the 2020s, March 2022
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s, March 2022. URL http://arxiv.org/abs/2201.03545. arXiv:2201.03545 [cs]
arXiv 2022
-
[52]
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design, July 2018
Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design, July 2018. URL http://arxiv.org/abs/ 1807.11164. arXiv:1807.11164 [cs]
Pith/arXiv arXiv 2018
-
[53]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, 2022. URL https://arxiv.org/ abs/2205.14135. Version Number: 2
Pith/arXiv arXiv 2022
-
[54]
Time Matters: Scaling Laws for Any Budget, October 2024
Itay Inbar and Luke Sernau. Time Matters: Scaling Laws for Any Budget, October 2024. URL http://arxiv.org/abs/2406.18922. arXiv:2406.18922 [cs]
arXiv 2024
-
[55]
Joanna M Wardlaw, Eric E Smith, Geert J Biessels, Charlotte Cordonnier, Franz Fazekas, Richard Frayne, Richard I Lindley, John T O’Brien, Frederik Barkhof, Oscar R Benavente, Sandra E Black, Carol Brayne, Monique Breteler, Hugues Chabriat, Charles DeCarli, Frank- Erik de Leeuw, Fergus Doubal, Marco Duering, Nick C Fox, Steven Greenberg, Vladimir Hachinski...
-
[56]
Charles DeCarli, Joseph Massaro, Danielle Harvey, John Hald, Mats Tullberg, Rhoda Au, Alexa Beiser, Ralph D’Agostino, and Philip A. Wolf. Measures of brain morphology and infarction in the framingham heart study: establishing what is normal.Neurobiology of Aging, 26(4): 491–510, April 2005. ISSN 0197-4580. doi: 10.1016/j.neurobiolaging.2004.05.004. URL ht...
-
[57]
Naftali Raz, Ulman Lindenberger, Karen M. Rodrigue, Kristen M. Kennedy, Denise Head, Adrienne Williamson, Cheryl Dahle, Denis Gerstorf, and James D. Acker. Regional Brain Changes in Aging Healthy Adults: General Trends, Individual Differences and Modifiers. Cerebral Cortex, 15(11):1676–1689, November 2005. ISSN 1047-3211. doi: 10.1093/cercor/ bhi044. URLh...
-
[58]
Simon R. Cox, Stuart J. Ritchie, Elliot M. Tucker-Drob, David C. Liewald, Saskia P. Hagenaars, Gail Davies, Joanna M. Wardlaw, Catharine R. Gale, Mark E. Bastin, and Ian J. Deary. Ageing and brain white matter structure in 3,513 UK Biobank participants.Nature Communications, 7(1):13629, December 2016. ISSN 2041-1723. doi: 10.1038/ncomms13629. URL https: /...
-
[59]
Electronic Com- merce Research and Applications73, 101527 (2025) https://doi.org/10.1016/j
Dani Beck, Ann-Marie G. de Lange, Ivan I. Maximov, Geneviève Richard, Ole A. Andreassen, Jan E. Nordvik, and Lars T. Westlye. White matter microstructure across the adult lifespan: A mixed longitudinal and cross-sectional study using advanced diffusion models and brain- age prediction.NeuroImage, 224:117441, January 2021. ISSN 1053-8119. doi: 10.1016/j. n...
work page doi:10.1016/j 2021
-
[60]
Farnaz Farokhian, Chunlan Yang, Iman Beheshti, Hiroshi Matsuda, and Shuicai Wu. Age- Related Gray and White Matter Changes in Normal Adult Brains.Aging and Disease, 8(6): 899–909, December 2017. ISSN 2152-5250. doi: 10.14336/AD.2017.0502. URL https: //pmc.ncbi.nlm.nih.gov/articles/PMC5758357/
-
[61]
Toledo, Tianhao Zhang, Nick Bryan, Lenore J
Mohamad Habes, Guray Erus, Jon B. Toledo, Tianhao Zhang, Nick Bryan, Lenore J. Launer, Yves Rosseel, Deborah Janowitz, Jimit Doshi, Sandra Van der Auwera, Bettina von Sarnowski, Katrin Hegenscheid, Norbert Hosten, Georg Homuth, Henry Völzke, Ulf Schminke, Wolfgang Hoffmann, Hans J. Grabe, and Christos Davatzikos. White matter hyperintensities and imaging ...
-
[62]
Cortina, Nikkita Khattar, Abinand C
Mustapha Bouhrara, Luis E. Cortina, Nikkita Khattar, Abinand C. Rejimon, Samuel Ajamu, Defne S. Cezayirli, and Richard G. Spencer. Maturation and degeneration of the human brainstem across the adult lifespan.Aging, 13(11):14862–14891, June 2021. ISSN 1945-4589. doi: 10.18632/aging.203183. URL https://www.aging-us.com/lookup/doi/10.18632/ aging.203183
-
[63]
Yu Wang, Ye Teng, Tianci Liu, Yuchun Tang, Wenjia Liang, Wenjun Wang, Zhuoran Li, Qing Xia, Feifei Xu, and Shuwei Liu. Morphological changes in the cerebellum during aging: evidence from convolutional neural networks and shape analysis.Frontiers in Ag- ing Neuroscience, 16, April 2024. ISSN 1663-4365. doi: 10.3389/fnagi.2024.1359320. URL https://www.front...
-
[64]
Xiang Chen, Zhiyuan Yuan, Jie Zhang, and Xiao-Yong Zhang. Multimodal quantitative MRI reveals age-related biophysical alterations in the human brain across the adult lifespan.NeuroIm- age, 327:121742, February 2026. ISSN 1053-8119. doi: 10.1016/j.neuroimage.2026.121742. URLhttps://www.sciencedirect.com/science/article/pii/S1053811926000601
-
[65]
Mapping heterogeneous region- and tissue-specific brain ageing patterns using quantitative MRI.Brain Communications, 8(1):fcag010, February
Xinjie Chen, Mario Ocampo-Pineda, Po-Jui Lu, Michelle G Jansen, Kwok-Shing Chan, Marcel Zwiers, Joukje M Oosterman, David G Norris, Andre F Marquand, Lester Melie-Garcia, Cristina Granziera, and José P Marques. Mapping heterogeneous region- and tissue-specific brain ageing patterns using quantitative MRI.Brain Communications, 8(1):fcag010, February
-
[66]
doi: 10.1093/braincomms/fcag010
ISSN 2632-1297. doi: 10.1093/braincomms/fcag010. URL https://doi.org/10. 1093/braincomms/fcag010
-
[67]
International Journal of Computer Vision , author =
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient- based Localization.International Journal of Computer Vision, 128(2):336–359, February 2020. ISSN 0920-5691, 1573-1405. doi: 10.1007/s11263-019-01228-7. URL http://arxiv.org/ abs/1610.0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.