How Human-Like Are Large Language Models? A Register-Aware Linguistic Evaluation Framework
Pith reviewed 2026-05-25 04:18 UTC · model grok-4.3
The pith
Large language models always deviate from human linguistic patterns, but the closest model depends on the register rather than size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
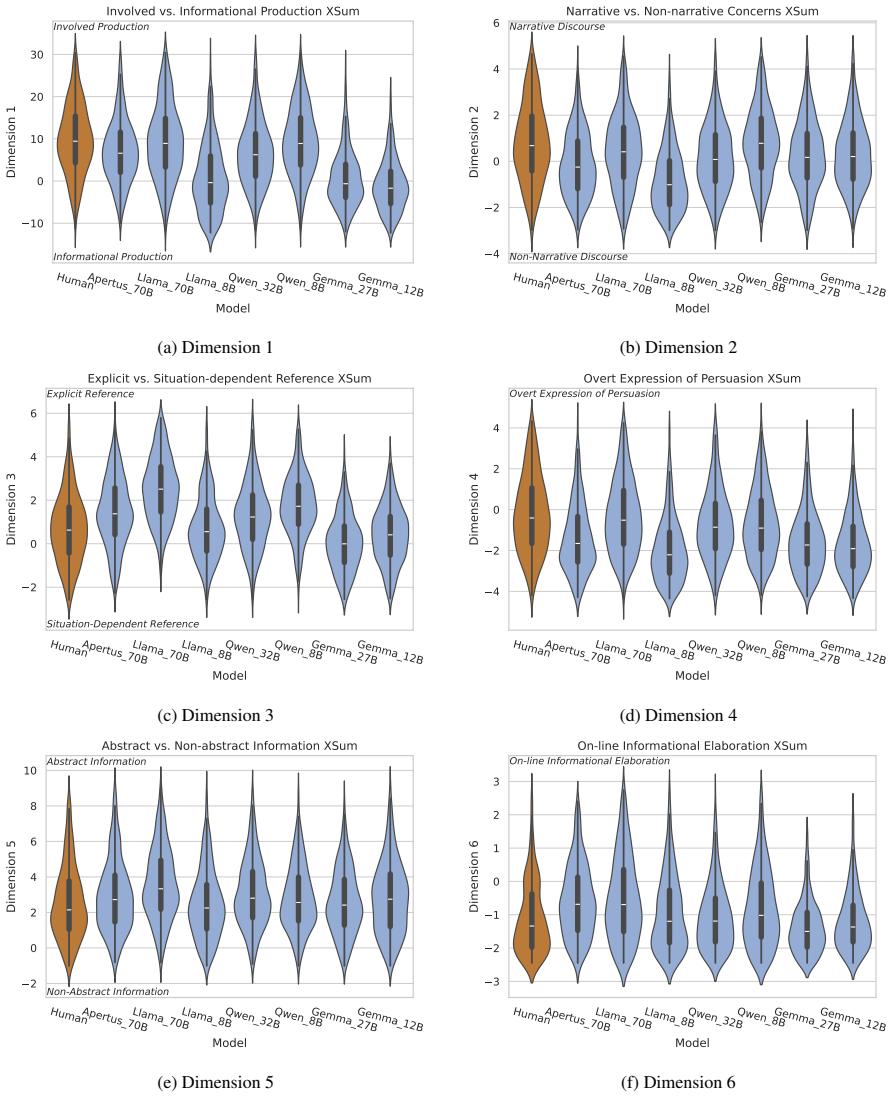
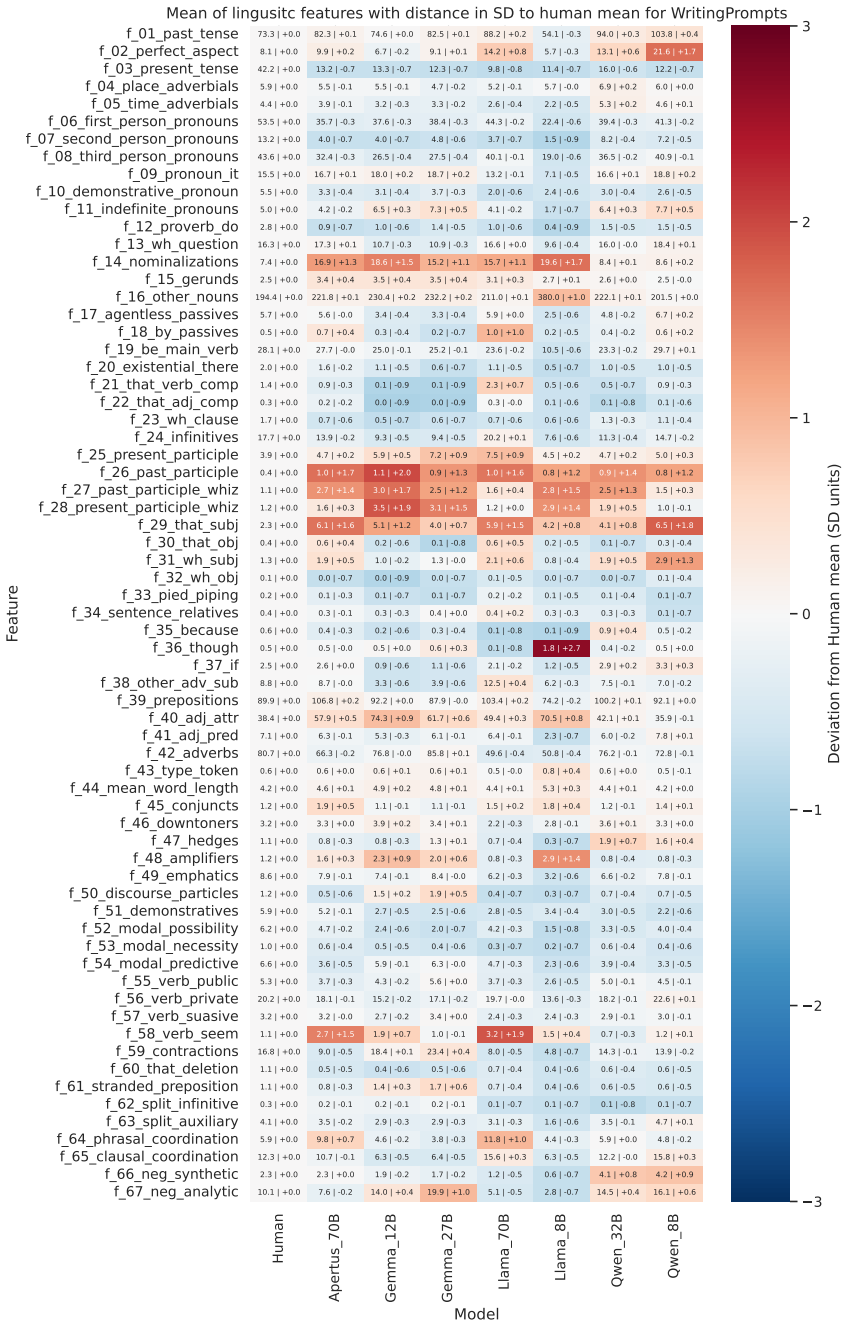
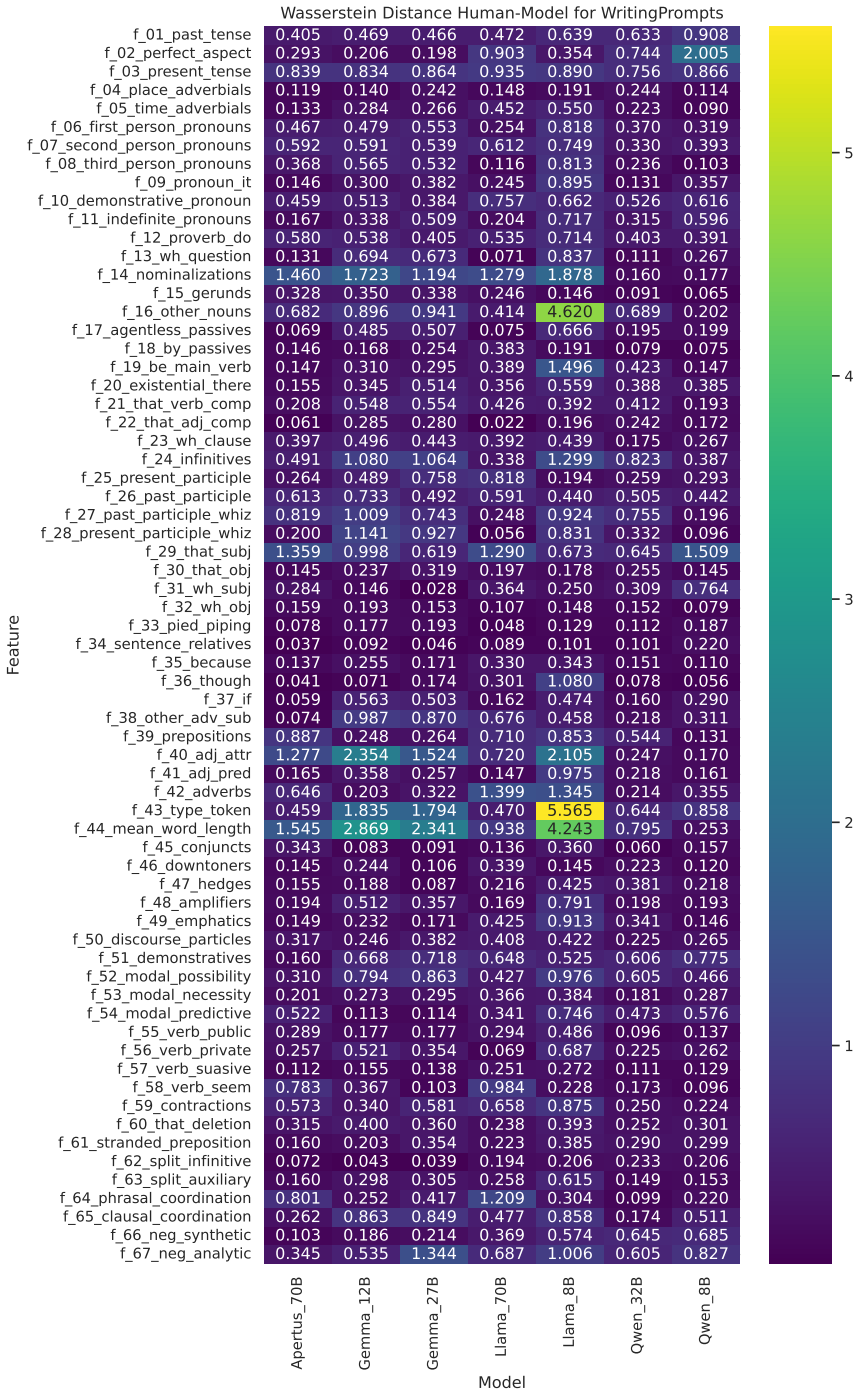
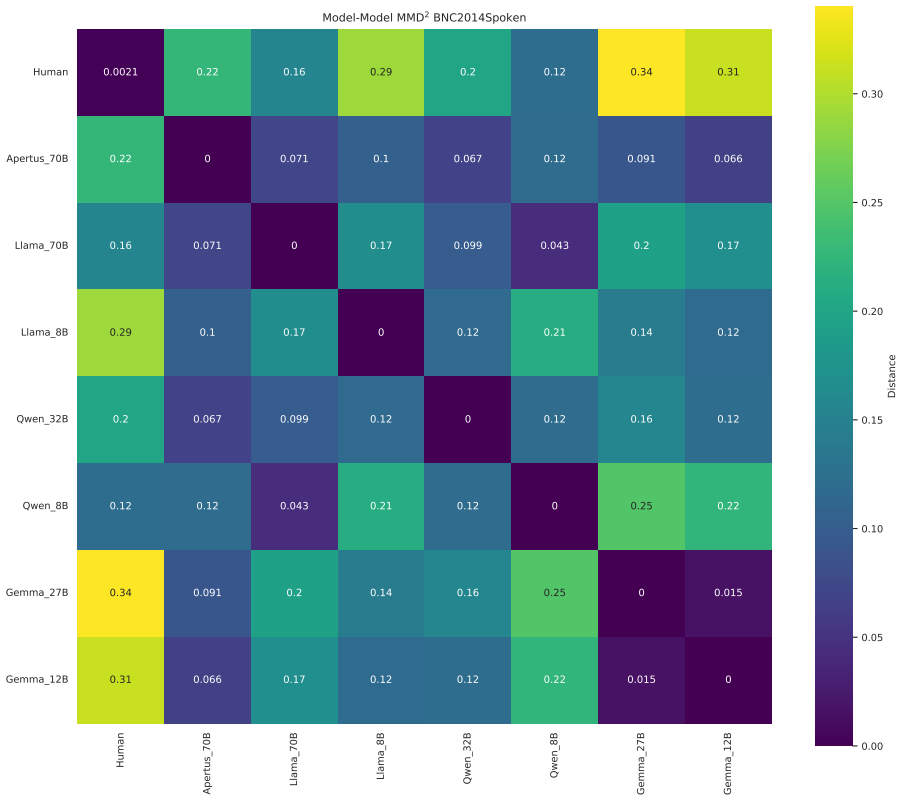
LLMs deviate from the human baseline in every tested setup when their texts are compared on lexico-grammatical feature distributions. The model that produces the distribution closest to human writing changes with the register, and this ordering is not dictated by model size.
What carries the argument
A two-sample Maximum Mean Discrepancy comparison between human and LLM corpora, performed separately for each register using the 67 Biber lexico-grammatical features.
If this is right
- Evaluation of LLM output must be performed register by register rather than with a single aggregate score.
- Larger models are not guaranteed to produce more human-like language distributions than smaller ones.
- Different communicative contexts expose different strengths among current open-source models.
- The framework supplies a quantitative basis for selecting models according to the intended register of use.
Where Pith is reading between the lines
- Fine-tuning on register-specific human data may close the observed gaps more effectively than further scaling.
- The same method could be applied to measure how well models handle register shifts within a single conversation.
- Training data that under-represents certain registers likely contributes to the systematic deviations found here.
Load-bearing premise
The 67 Biber features together with the MMD statistic capture the aspects of language production that determine whether a text feels human-like in a given register.
What would settle it
An experiment that finds one model size ranking first across every register would show that closeness is dictated by size after all.
Figures

























read the original abstract
While factual correctness and task-performance have been in focus of Large Language Model (LLM) research for a long time, the fundamental question of how human-like generated texts are on a linguistic level has been underexplored. From a corpus-linguistic perspective, language production is inherently context-dependent, with distinct communicative contexts giving rise to differences in frequencies and co-occurrence patterns of linguistic features. A text failing to adhere to these patterns can be content-wise correct, but still be unfavorable to human readers. In this work, we propose a context-aware evaluation framework in which human-likeness is assessed using a two-sample problem between the linguistic feature distribution of a human reference corpus for a given register and a corresponding LLM-generated corpus. We implement this framework using the Maximum Mean Discrepancy (MMD) and the 67 lexico-grammatical features introduced by Biber, which are commonly applied in corpus linguistics. In our experiments, we compare seven instruction-tuned, open-source models across five English-language datasets spanning distinct registers against a human baseline. While across all tested setups, LLMs deviate from the human baseline, which models are closest to human language depends on the register and is not dictated by model size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a context-aware evaluation framework for assessing the human-likeness of LLM-generated texts using Maximum Mean Discrepancy (MMD) to compare distributions of 67 Biber lexico-grammatical features between human reference corpora and LLM outputs across five distinct English registers. Experiments with seven instruction-tuned open-source LLMs reveal that all models deviate from human baselines, but the model closest to the human distribution varies depending on the register and is not solely determined by model size.
Significance. If the framework's assumptions hold, this work offers a valuable corpus-linguistic approach to LLM evaluation that accounts for register-specific linguistic patterns, moving beyond task performance metrics. The reliance on established Biber features and MMD contributes to the method's transparency and potential for replication in the field.
major comments (1)
- [Abstract] The central claim that 'which models are closest to human language depends on the register and is not dictated by model size' is load-bearing on the 67 Biber features plus two-sample MMD being a sufficient statistic for human-likeness (Abstract). The manuscript provides no evidence that these distances align with human judgments of naturalness or discourse-level properties in the tested registers, nor any ablation against expanded feature sets; if the ordering differs from such external validation, the register-dependence conclusion does not follow from the reported MMD values.
minor comments (1)
- [Abstract] The abstract states the main finding but does not name the five registers or seven models; adding these would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The central claim that 'which models are closest to human language depends on the register and is not dictated by model size' is load-bearing on the 67 Biber features plus two-sample MMD being a sufficient statistic for human-likeness (Abstract). The manuscript provides no evidence that these distances align with human judgments of naturalness or discourse-level properties in the tested registers, nor any ablation against expanded feature sets; if the ordering differs from such external validation, the register-dependence conclusion does not follow from the reported MMD values.
Authors: We acknowledge the referee's point that the manuscript does not provide direct evidence linking MMD distances on the Biber feature set to human judgments of naturalness. The 67 features are selected because they are a well-established, replicable set in corpus linguistics for modeling register variation (Biber 1988 and subsequent validation studies). MMD serves as a distribution-level comparator rather than a claim of sufficiency for all aspects of human-likeness. The reported finding is therefore scoped to relative distances within this operationalization: across the five registers, the model minimizing MMD changes and is not monotonically related to parameter count. We agree that external validation would strengthen interpretation. In revision we will (1) temper the abstract wording to emphasize that conclusions concern this specific feature set and metric, (2) add citations to existing literature on the predictive validity of Biber features for perceived register appropriateness, and (3) expand the limitations section to note the absence of human judgment correlation or feature-set ablations as directions for future work. No new experiments are added at this stage. revision: partial
Circularity Check
No circularity; direct empirical comparison to external human corpora
full rationale
The paper defines human-likeness via two-sample MMD distances on the fixed, externally established set of 67 Biber lexico-grammatical features between LLM-generated texts and independent human reference corpora for each register. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear; the reported register-dependent ordering of models follows immediately from these distance computations without any reduction of outputs to inputs by construction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Biber's 67 lexico-grammatical features capture the relevant frequency and co-occurrence patterns that distinguish registers in human language production.
Reference graph
Works this paper leans on
-
[1]
Precision-Recall Curves Using Information Divergence Frontiers , url =
Josip Djolonga and Mario Lucic and Marco Cuturi and Olivier Bachem and Olivier Bousquet and Sylvain Gelly , bibsource =. Precision-Recall Curves Using Information Divergence Frontiers , url =. The 23rd International Conference on Artificial Intelligence and Statistics,
-
[2]
Ghostbuster: Detecting Text Ghostwritten by Large Language Models , url =
Verma, Vivek and Fleisig, Eve and Tomlin, Nicholas and Klein, Dan , booktitle =. Ghostbuster: Detecting Text Ghostwritten by Large Language Models , url =
-
[3]
Manning and Chelsea Finn , bibsource =
Eric Mitchell and Yoonho Lee and Alexander Khazatsky and Christopher D. Manning and Chelsea Finn , bibsource =. DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature , url =. International Conference on Machine Learning,
-
[4]
Wu, Junchao and Yang, Shu and Zhan, Runzhe and Yuan, Yulin and Chao, Lidia Sam and Wong, Derek Fai , doi =. A. Computational Linguistics , language =
-
[5]
Krishna Pillutla and Swabha Swayamdipta and Rowan Zellers and John Thickstun and Sean Welleck and Yejin Choi and Za. Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual , editor =
work page 2021
-
[6]
Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M
Jason Wei and Maarten Bosma and Vincent Y. Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M. Dai and Quoc V. Le , bibsource =. Finetuned Language Models are Zero-Shot Learners , url =. The Tenth International Conference on Learning Representations,
- [7]
-
[8]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , bibsourc...
work page 2022
- [9]
-
[10]
Bagdasarov, Sergei and Alves, Diego , booktitle =. Like a
-
[11]
Differentiating between human-written and
Georgiou, Georgios P , journal =. Differentiating between human-written and
- [12]
- [13]
-
[14]
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , doi =. What. Applied Sciences , language =
-
[15]
Alex Wang and Yada Pruksachatkun and Nikita Nangia and Amanpreet Singh and Julian Michael and Felix Hill and Omer Levy and Samuel R. Bowman , bibsource =. SuperGLUE:. Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada , editor =
work page 2019
-
[16]
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven , booktitle =
-
[17]
Measuring Massive Multitask Language Understanding , url =
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , bibsource =. Measuring Massive Multitask Language Understanding , url =. 9th International Conference on Learning Representations,
- [19]
-
[20]
Veirano Pinto, Marcia , doi =. Elena. English Language and Linguistics , language =
-
[21]
Register as a predictor of linguistic variation , url =
Biber,, Douglas , doi =. Register as a predictor of linguistic variation , url =. Corpus Linguistics and Linguistic Theory , language =
-
[22]
Register, genre, and style , year =
Biber, Douglas and Conrad, Susan , doi =. Register, genre, and style , year =
-
[23]
Alkiek, Kenan and Wegmann, Anna and Zhu, Jian and Jurgens, David , language =. Neurobiber:
- [24]
-
[25]
Comparative linguistic analysis framework of human-written vs
Culda, Lia Cornelia and Nerişanu, Raluca Andreea and Cristescu, Marian Pompiliu and Mara, Dumitru Alexandru and Bâra, Adela and Oprea, Simona-Vasilica , doi =. Comparative linguistic analysis framework of human-written vs. machine-generated text , url =. Connection Science , language =
- [26]
-
[27]
Wang, Zhengxiang and Tripto, Nafis Irtiza and Park, Solha and Li, Zhenzhen and Zhou, Jiawei , language =. Catch
-
[28]
Wang, Yuxia and Mansurov, Jonibek and Ivanov, Petar and Su, Jinyan and Shelmanov, Artem and Tsvigun, Akim and Whitehouse, Chenxi and Mohammed Afzal, Osama and Mahmoud, Tarek and Sasaki, Toru and Arnold, Thomas and Aji, Alham Fikri and Habash, Nizar and Gurevych, Iryna and Nakov, Preslav , booktitle =. M4: Multi-generator, Multi-domain, and Multi-lingual B...
-
[30]
Liu, Jae Q. J. and Hui, Kelvin T. K. and Al Zoubi, Fadi and Zhou, Zing Z. X. and Samartzis, Dino and Yu, Curtis C. H. and Chang, Jeremy R. and Wong, Arnold Y. L. , doi =. The great detectives: humans versus. International Journal for Educational Integrity , language =
-
[31]
Stylometry can reveal artificial intelligence authorship, but humans struggle:
Zaitsu, Wataru and Jin, Mingzhe and Ishihara, Shunichi and Tsuge, Satoru and Inaba, Mitsuyuki , doi =. Stylometry can reveal artificial intelligence authorship, but humans struggle:. PLOS One , language =
-
[32]
Przystalski, Karol and Argasiński, Jan and Grabska-Gradzińska, Iwona and Ochab, Jeremi , doi =. Stylometry
-
[33]
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , doi =. Nature , language =
-
[34]
Shiyu Liang and Yixuan Li and R. Srikant , bibsource =. Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks , url =. 6th International Conference on Learning Representations,
-
[35]
Roy and Zoubin Ghahramani , bibsource =
Gintare Karolina Dziugaite and Daniel M. Roy and Zoubin Ghahramani , bibsource =. Training generative neural networks via Maximum Mean Discrepancy optimization , url =. Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence,
-
[36]
Mingsheng Long and Yue Cao and Jianmin Wang and Michael I. Jordan , bibsource =. Learning Transferable Features with Deep Adaptation Networks , url =. Proceedings of the 32nd International Conference on Machine Learning,
-
[37]
Zhu, Yongchun and Zhuang, Fuzhen and Wang, Jindong and Ke, Guolin and Chen, Jingwu and Bian, Jiang and Xiong, Hui and He, Qing , doi =. Deep. IEEE Transactions on Neural Networks and Learning Systems , keywords =
-
[38]
and Gil, María Victoria and Glaubitz, Christina and Greiner, Maximilian and Holick, Caroline T
Mirza, Adrian and Alampara, Nawaf and Kunchapu, Sreekanth and Ríos-García, Martiño and Emoekabu, Benedict and Krishnan, Aswanth and Gupta, Tanya and Schilling-Wilhelmi, Mara and Okereke, Macjonathan and Aneesh, Anagha and Asgari, Mehrdad and Eberhardt, Juliane and Elahi, Amir Mohammad and Elbeheiry, Hani M. and Gil, María Victoria and Glaubitz, Christina ...
-
[40]
Neel Guha and Julian Nyarko and Daniel E. Ho and Christopher R. LegalBench:. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , editor =
work page 2023
-
[41]
Alex Wang and Amanpreet Singh and Julian Michael and Felix Hill and Omer Levy and Samuel R. Bowman , bibsource =. 7th International Conference on Learning Representations,
-
[42]
Variation across speech and writing , year =
Biber, Douglas , publisher =. Variation across speech and writing , year =
-
[43]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
-
[44]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and Yang, Amy and Fan, Angela and Goyal, Anirudh and Hartshorn, Anthony and Yang, Aobo and Mitra, Archi and Sravankumar, Archie and Korenev, Artem and Hinsvark, A...
-
[45]
Team, Gemma and Kamath, Aishwarya and Ferret, Johan and Pathak, Shreya and Vieillard, Nino and Merhej, Ramona and Perrin, Sarah and Matejovicova, Tatiana and Ramé, Alexandre and Rivière, Morgane and Rouillard, Louis and Mesnard, Thomas and Cideron, Geoffrey and Grill, Jean-bastien and Ramos, Sabela and Yvinec, Edouard and Casbon, Michelle and Pot, Etienne...
-
[46]
Apertus, Project and Hernández-Cano, Alejandro and Hägele, Alexander and Huang, Allen Hao and Romanou, Angelika and Solergibert, Antoni-Joan and Pasztor, Barna and Messmer, Bettina and Garbaya, Dhia and Ďurech, Eduard Frank and Hakimi, Ido and Giraldo, Juan García and Ismayilzada, Mete and Foroutan, Negar and Moalla, Skander and Chen, Tiancheng and Sabolč...
-
[50]
Koupaee, Mahnaz and Wang, William Yang , journal =
-
[52]
Chang, Tyler A. and Bergen, Benjamin K. , doi =. Language Model Behavior: A Comprehensive Survey , url =. Computational Linguistics , number =
-
[53]
Bischoff, Sebastian and Darcher, Alana and Deistler, Michael and Gao, Richard and Gerken, Franziska and Gloeckler, Manuel and Haxel, Lisa and Kapoor, Jaivardhan and Lappalainen, Janne K. and Macke, Jakob H. and Moss, Guy and Pals, Matthijs and Pei, Felix and Rapp, Rachel and Sağtekin, A. Erdem and Schröder, Cornelius and Schulz, Auguste and Stefanidi, Zin...
-
[54]
Ramdas, Aaditya and Garcia, Nicolas and Cuturi, Marco , journal =. On
-
[55]
Gretton, Arthur and Borgwardt, Karsten M. and Rasch, Malte J. and Schölkopf, Bernhard and Smola, Alexander , journal =. A kernel two-sample test , url =
-
[56]
Personalized Text Generation with Fine-Grained Linguistic Control , url =
Alhafni, Bashar and Kulkarni, Vivek and Kumar, Dhruv and Raheja, Vipul , booktitle =. Personalized Text Generation with Fine-Grained Linguistic Control , url =
- [57]
-
[58]
Reinhart, Alex and Markey, Ben and Laudenbach, Michael and Pantusen, Kachatad and Yurko, Ronald and Weinberg, Gordon and Brown, David West , journal =. Do
-
[59]
Benchmark of stylistic variation in
Milička, Jiří and Marklová, Anna and Cvrček, Václav , journal =. Benchmark of stylistic variation in
-
[60]
Applied Corpus Linguistics , language =
Berber Sardinha, Tony , doi =. Applied Corpus Linguistics , language =
-
[61]
Milička, Jiří and Marklová, Anna and Cvrček, Václav , journal =
-
[62]
Djolonga, Josip and Lucic, Mario and Cuturi, Marco and Bachem, Olivier and Bousquet, Olivier and Gelly, Sylvain , editor =. Precision-. Proceedings of the. 2020 , pages =
work page 2020
-
[63]
Verma, Vivek and Fleisig, Eve and Tomlin, Nicholas and Klein, Dan , year =. Ghostbuster:. Proceedings of the 2024. doi:10.18653/v1/2024.naacl-long.95 , abstract =
-
[65]
Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid , year =. Proceedings of the 35th
-
[66]
Wei, Jason and Bosma, Maarten and Zhao, Vincent Y and Guu, Kelvin and Yu, Adams Wei and Lester, Brian and Du, Nan and Dai, Andrew M and Le, Quoc V , year =. International
- [67]
-
[68]
Training language models to follow instructions with human feedback , abstract =
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, Ry...
-
[69]
Bagdasarov, Sergei and Alves, Diego , year =. Like a. Proceedings of the
- [70]
-
[71]
Register Always Matters: Analysis of LLM Pretraining Data Through the Lens of Language Variation
Myntti, Amanda and Henriksson, Erik and Laippala, Veronika and Pyysalo, Sampo , month = sep, year =. Register. doi:10.48550/arXiv.2504.01542 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.01542
- [72]
-
[74]
Es, Shahul and James, Jithin and Espinosa-Anke, Luis and Schockaert, Steven , year =. System
-
[75]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , month = jan, year =. Measuring. doi:10.48550/arXiv.2009.03300 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[80]
and Aroyehun, Segun , month = dec, year =
Zanotto, Sergio E. and Aroyehun, Segun , month = dec, year =. Human. doi:10.48550/arXiv.2412.03025 , abstract =
-
[81]
machine-generated text , volume =
Comparative linguistic analysis framework of human-written vs. machine-generated text , volume =. Connection Science , author =. 2025 , pages =. doi:10.1080/09540091.2025.2507183 , abstract =
-
[82]
Paech, Samuel J. , month = jan, year =. doi:10.48550/arXiv.2312.06281 , abstract =
-
[83]
Mosca, Edoardo and Abdalla, Mohamed Hesham Ibrahim and Basso, Paolo and Musumeci, Margherita and Groh, Georg , year =. Distinguishing. Proceedings of the 3rd. doi:10.18653/v1/2023.trustnlp-1.17 , abstract =
-
[84]
International Journal for Educational Integrity , author =
The great detectives: humans versus. International Journal for Educational Integrity , author =. 2024 , pages =. doi:10.1007/s40979-024-00155-6 , abstract =
-
[87]
Anderson and Yarin Gal , title =
Nature , author =. 2024 , pages =. doi:10.1038/s41586-024-07566-y , abstract =
-
[88]
Liang, Shiyu and Li, Yixuan and Srikant, R , year =
-
[89]
Training generative neural networks via Maximum Mean Discrepancy optimization
Dziugaite, Gintare Karolina and Roy, Daniel M. and Ghahramani, Zoubin , month = may, year =. Training generative neural networks via. doi:10.48550/arXiv.1505.03906 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1505.03906
-
[90]
Learning Transferable Features with Deep Adaptation Networks
Long, Mingsheng and Cao, Yue and Wang, Jianmin and Jordan, Michael I. , month = may, year =. Learning. doi:10.48550/arXiv.1502.02791 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1502.02791
-
[93]
URL https:// doi.org/10.18653/v1/p19-1472
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , year =. Proceedings of the 57th. doi:10.18653/v1/P19-1472 , abstract =
-
[94]
SSRN Electronic Journal , author =
Legalbench:. SSRN Electronic Journal , author =. doi:10.2139/ssrn.4583531 , abstract =
-
[95]
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel , year =. Proceedings of the 2018. doi:10.18653/v1/W18-5446 , language =
-
[96]
Variation across speech and writing , publisher =
Biber, Douglas , year =. Variation across speech and writing , publisher =
-
[97]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.