TopoPult-SSL: Gland-Mask-Free Cross-Device Meibomian Gland Segmentation via Self-Distilled Weak Clinical Priors
Pith reviewed 2026-06-28 06:10 UTC · model grok-4.3
The pith
A two-stage framework adapts meibomian gland segmentation to new devices without target gland masks by using weak clinical priors and self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TopoPult-SSL demonstrates that domain adaptation for gland segmentation can proceed from source-trained models to new devices by anchoring on weak priors from eyelid outlines and metadata alone in stage one, followed by self-distillation in stage two to produce a compact high-performing model that surpasses both ensemble teachers and existing semi-supervised baselines on cross-device data.
What carries the argument
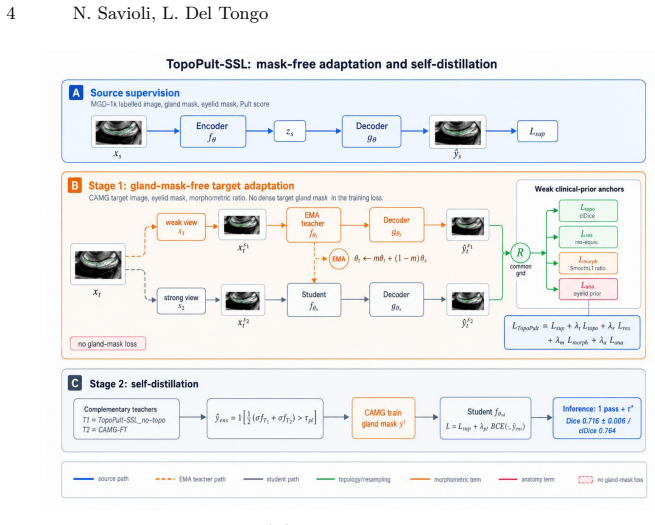
The TopoPult-SSL two-stage framework, where stage one employs four weak-prior anchors based on target eyelid masks and clinical metadata for mask-free adaptation, and stage two uses supervised self-distillation to combine complementary teachers into a single student model.
If this is right
- The approach allows initial deployment on new devices without collecting any dense gland masks.
- Stage-1 segmentations achieve statistically higher precision than foundation models like SAM and MedSAM.
- Self-distillation improves performance over the multi-teacher ensemble while requiring only one forward pass.
- The method is validated on a substantial reduction in dataset size from 1000 to 100 images across devices.
Where Pith is reading between the lines
- Weak clinical signals that are routinely recorded could reduce reliance on expensive annotations for other medical segmentation tasks.
- The framework might extend to additional imaging modalities where metadata like grades are available.
Load-bearing premise
The four weak-prior anchors from target eyelid masks and clinical metadata suffice to adapt the model without target gland masks appearing in the training loss.
What would settle it
Training the stage-1 model on the target device but removing or randomizing the weak priors and checking whether the resulting precision falls to the level of SAM (around 0.3) would falsify the claim that these priors drive the adaptation.
Figures
read the original abstract
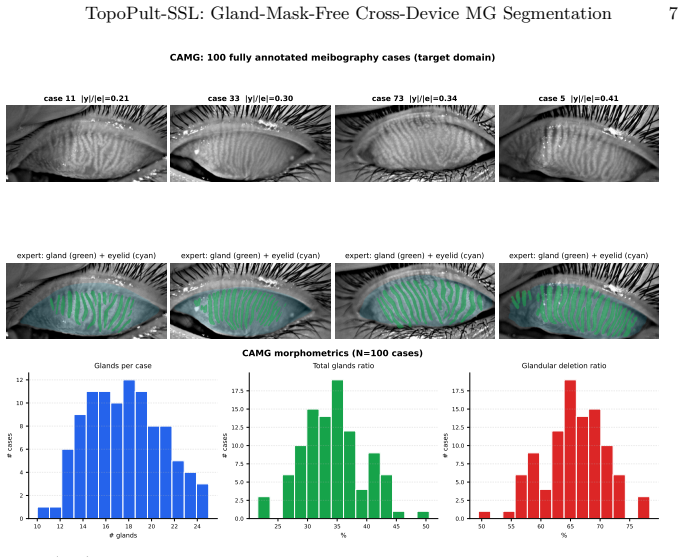
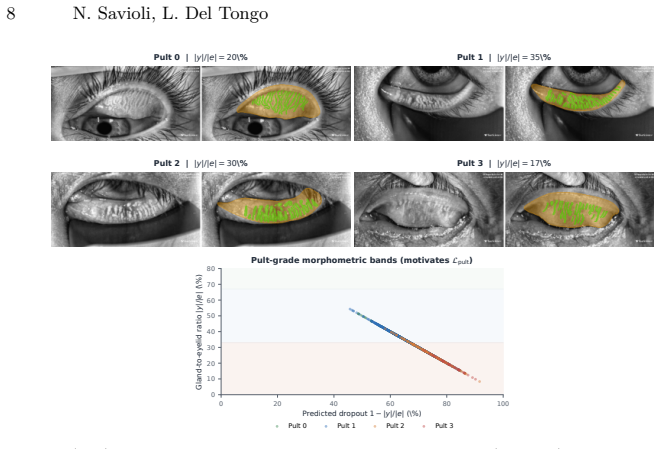
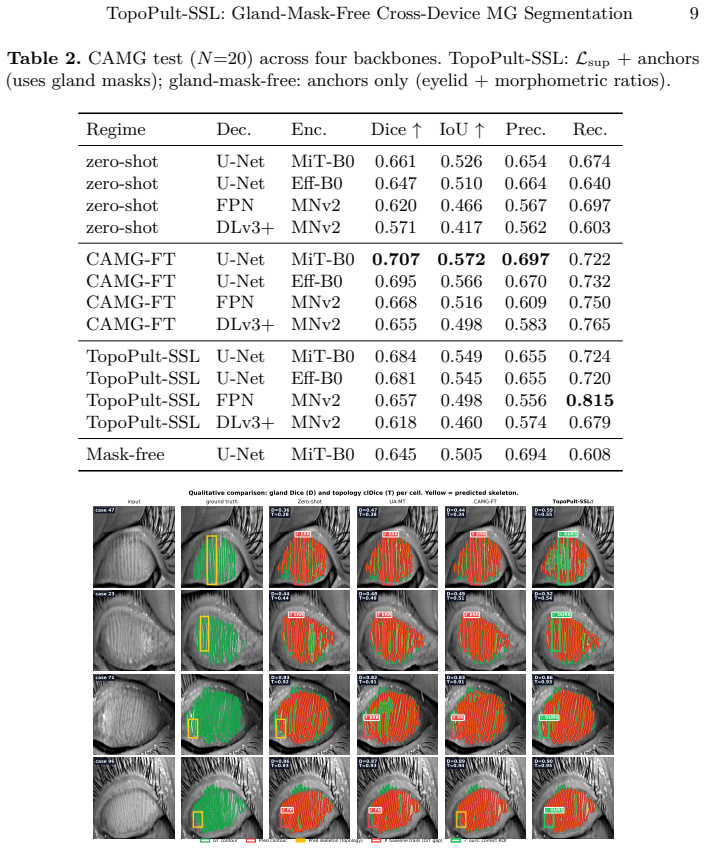
Every new clinical imaging device creates a domain shift where dense gland masks are expensive yet cheap clinical signals -- eyelid outlines, Pult grades, morphometric ratios -- are routinely recorded. We present TopoPult-SSL, a two-stage framework for cross-device meibomian gland segmentation. Stage 1 adapts a source-trained model without target gland masks in the training loss, using four weak-prior anchors driven by target eyelid masks and clinical metadata only. Stage 2, when target gland masks are available, distils complementary Stage-1 teachers into a single compact student via supervised self-distillation. We develop and validate the technique on the public MGD-1k to CAMG research benchmark (1,000 to 100 images, different device), where the distilled model achieves Dice 0.716+/-0.006 (best 0.726), surpassing UA-MT (0.710) and the ensemble teacher (0.720) -- with a single pass. The gland-mask-free Stage-1 variant reaches Precision 0.694 vs. 0.30-0.34 for SAM/MedSAM (p<0.001), enabling deployment without dense gland contouring. Code and reproducibility scripts are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TopoPult-SSL, a two-stage framework for cross-device meibomian gland segmentation. Stage 1 adapts a source-trained model to a target device using only four weak clinical priors (target eyelid masks, Pult grades, and morphometric ratios) with no target gland masks in the loss. Stage 2 performs supervised self-distillation from an ensemble of Stage-1 teachers into a compact student when target masks become available. On the MGD-1k to CAMG benchmark the distilled model reports Dice 0.716±0.006 (best 0.726), outperforming UA-MT (0.710) and the teacher ensemble (0.720); the mask-free Stage-1 variant reports Precision 0.694 versus 0.30–0.34 for SAM/MedSAM (p<0.001). Code is released.
Significance. If the four weak priors are shown to supply sufficient signal for domain adaptation, the approach would meaningfully lower the annotation cost of deploying gland segmentation across new clinical devices. The public release of reproducibility scripts is a concrete strength that supports verification of the reported numbers.
major comments (2)
- [Abstract / §3.1] Abstract and §3.1 (Stage-1 formulation): the central claim that the four weak-prior anchors alone drive successful domain adaptation rests on the unshown loss definitions and the absence of any ablation that isolates their contribution; without these the reported Stage-1 Precision 0.694 cannot be attributed to the priors rather than source-model carry-over.
- [§4] §4 (Experiments): the manuscript supplies aggregate Dice/Precision figures and a single p-value but does not report dataset splits, the exact number of target images used in Stage 1, or any control experiment that removes one or more of the four anchors; these omissions leave the data-to-claim link unverifiable.
minor comments (1)
- [Abstract] The benchmark description “MGD-1k to CAMG (1,000 to 100 images, different device)” should state the precise source and target dataset cardinalities and imaging-device specifications for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our method and experiments. We address each major comment below and commit to revisions that will make the contributions more verifiable.
read point-by-point responses
-
Referee: [Abstract / §3.1] Abstract and §3.1 (Stage-1 formulation): the central claim that the four weak-prior anchors alone drive successful domain adaptation rests on the unshown loss definitions and the absence of any ablation that isolates their contribution; without these the reported Stage-1 Precision 0.694 cannot be attributed to the priors rather than source-model carry-over.
Authors: The loss definitions for the four weak-prior anchors (eyelid masks, Pult grades, and morphometric ratios) are explicitly formulated in §3.1. We acknowledge, however, that an ablation isolating the incremental contribution of each anchor is absent. In the revision we will add a dedicated ablation table that removes one or more priors in turn and reports the resulting Precision on the target domain, thereby strengthening the attribution to the clinical priors rather than source-model carry-over alone. revision: yes
-
Referee: [§4] §4 (Experiments): the manuscript supplies aggregate Dice/Precision figures and a single p-value but does not report dataset splits, the exact number of target images used in Stage 1, or any control experiment that removes one or more of the four anchors; these omissions leave the data-to-claim link unverifiable.
Authors: We agree that these experimental details are necessary for full verifiability. The revision will explicitly state the train/validation/test splits of the 100-image CAMG target set, confirm that Stage 1 uses all 100 target images, and add control experiments that ablate individual anchors. These additions will be placed in an expanded §4 and will directly address the data-to-claim linkage. revision: yes
Circularity Check
No circularity: method claims rest on external benchmark validation without self-referential reductions
full rationale
The provided abstract and text describe a two-stage framework where Stage 1 uses four weak priors (eyelid masks + metadata) for mask-free adaptation and Stage 2 performs self-distillation. No equations, loss formulations, fitted parameters, or self-citations are quoted that would make the reported Dice/Precision scores equivalent to inputs by construction. Performance is presented as empirical results on the MGD-1k to CAMG benchmark, which is an external dataset split. This satisfies the self-contained criterion with no load-bearing steps reducing to definitions or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, X., Yuan, Y., Zeng, G., Wang, J.: Semi-supervised semantic segmentation with cross pseudo supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2613–2622 (2021), https://doi.org/10.48550/arXiv.2106.01226
-
[2]
Journal of Imaging12(1), 50 (2026),https://doi.org/10.3390/jimaging12010050
Fang, J., He, X., Jiang, Y., Wang, M.H.: Adam-net: Anatomy-guided attentive unsu- pervised domain adaptation for joint MG segmentation and MGD grading. Journal of Imaging12(1), 50 (2026),https://doi.org/10.3390/jimaging12010050
-
[3]
In: International Conference on Learning Representations (ICLR) (2018)
French, G., Mackiewicz, M., Fisher, M.: Self-ensembling for visual domain adapta- tion. In: International Conference on Learning Representations (ICLR) (2018)
2018
-
[4]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015),https://doi.org/10.48550/arXiv.1503.02531
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.02531 2015
-
[5]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4015–4026 (2023),https://doi.org/10.1109/ICCV51070.2023.00371
-
[6]
npj Digital Medicine8, 403 (2025), https://doi.org/10.1038/s41746-025-01753-5
Li, L., Xiao, K., Lai, T., Lai, K., Lin, J., Ge, Z., Liang, L., Huang, H., Zhang, X., Liu, L., Wang, Y., Shang, X., He, M., Xue, Y., Zhu, Z.: Development and multicenter validation of an AI-driven model for quantitative meibomian gland evaluation. npj Digital Medicine8, 403 (2025), https://doi.org/10.1038/s41746-025-01753-5
-
[7]
Eye and Vision12, 46 (2025),https://doi.org/10.1186/s40662-025-00460-2
Li, L., Xiao, K., Lai, T., Lai, K., Wang, Y., Shang, X., Xue, Y., Ge, Z., Liang, L., He, M., Lin, J., Zhu, Z.: AI-driven quantitative analysis of meibomian glands in children and adolescents: a benchmark dataset study. Eye and Vision12, 46 (2025),https://doi.org/10.1186/s40662-025-00460-2
-
[8]
Nature Communications15, 654 (2024), https://doi.org/10.1038/ s41467-024-44824-z
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medi- cal images. Nature Communications15, 654 (2024), https://doi.org/10.1038/ s41467-024-44824-z
2024
-
[9]
NeuroImage 194, 1–11 (2019),https://doi.org/10.1016/j.neuroimage.2019.03.026
Perone, C.S., Ballester, P., Barros, R.C., Cohen-Adad, J.: Unsupervised domain adaptation for medical imaging segmentation with self-ensembling. NeuroImage 194, 1–11 (2019),https://doi.org/10.1016/j.neuroimage.2019.03.026
-
[10]
Contact Lens and Anterior Eye36(1), 22–27 (2013), https://doi.org/10.1016/j.clae.2012.10.074
Pult, H., Riede-Pult, B.H.: Comparison of subjective grading and objective as- sessment in meibography. Contact Lens and Anterior Eye36(1), 22–27 (2013), https://doi.org/10.1016/j.clae.2012.10.074
-
[11]
In: Medical Image Computing and Computer- Assisted Intervention (MICCAI)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer- Assisted Intervention (MICCAI). pp. 234–241 (2015),https://doi.org/10.1007/ 978-3-319-24574-4_28
2015
-
[12]
The Ocular Surface26, 283–294 (2022),https://doi.org/10.1016/j.jtos.2022.06.006
Saha, R.K., Chowdhury, A.M.M., Na, K.S., Hwang, G.D., Eom, Y., Kim, J., Jeon, H.G., Hwang, H.S., Chung, E.S.: Automated quantification of meibomian gland dropout in infrared meibography using deep learning. The Ocular Surface26, 283–294 (2022),https://doi.org/10.1016/j.jtos.2022.06.006
-
[13]
Scientific Reports11, 7649 (2021), https://doi.org/10
Setu, M.A.K., Horstmann, J., Schmidt, S., Stern, M.E., Steven, P.: Deep learning- based automatic meibomian gland segmentation and morphology assessment in infrared meibography. Scientific Reports11, 7649 (2021), https://doi.org/10. 1038/s41598-021-87314-8
2021
-
[14]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Shit, S., Paetzold, J.C., Sekuboyina, A., Ezhov, I., Unger, A., Zhylka, A., Pluim, J.P.W., Bauer, U., Menze, B.H.: clDice – a novel topology-preserving loss function for tubular structure segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16560–16569 (2021), https://doi.org/10.1109/CVPR46437.202...
-
[15]
In: Advances in Neural Information Processing Systems (NeurIPS)
Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C., Cubuk, E.D., Kurakin, A., Li, C.L.: Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 596–608 (2020),https://doi.org/10.48550/arXiv.2001.07685
-
[16]
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 1195–1204 (2017),https: //doi.org/10.48550/arXiv.1703.01780
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1703.01780 2017
-
[17]
In: Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A
Yu, L., Wang, S., Li, X., Fu, C.W., Heng, P.A.: Uncertainty-aware self-ensembling model for semi-supervised 3d left atrium segmentation. In: Medical Image Com- puting and Computer-Assisted Intervention (MICCAI). pp. 605–613 (2019),https: //doi.org/10.1007/978-3-030-32245-8_67
-
[18]
Medical Physics52, 1615–1628 (2025),https: //doi.org/10.1002/mp.17542
Zhu, W., Liu, D., Zhuang, X., Gong, T., Shi, F., Xiang, D., Peng, T., Zhang, X., Chen, X.: Strip and boundary detection multi-task learning network for seg- mentation of meibomian glands. Medical Physics52, 1615–1628 (2025),https: //doi.org/10.1002/mp.17542
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.