Can LLMs Be CEOs? Benchmarking Strategic Resource Reallocation with Multi-Role Agent Simulation
Pith reviewed 2026-06-27 01:40 UTC · model grok-4.3
The pith
LLMs achieve high structural validity in CEO resource allocation but diverge sharply on strategic calibration when synthesizing conflicting advisor inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
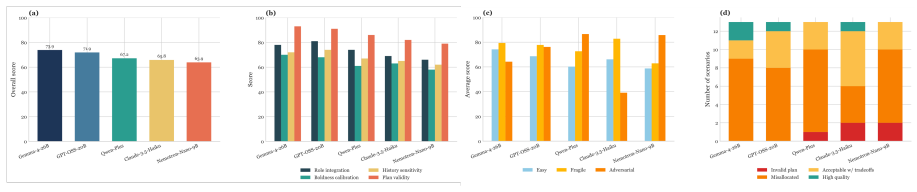
In the CEO-Bench multi-round simulation, LLM agents must redirect capital across business units while receiving private signals from CFO, CTO, COO, and CMO advisors with distinct priorities; all tested models produce structurally valid plans yet show marked differences in strategic calibration, with systematic patterns of advisor capture, conservative defaults under ambiguity, historical amnesia, and an integration-boldness tradeoff.
What carries the argument
CEO-Bench, a multi-agent environment in which an LLM CEO agent receives role-conditioned private signals from four C-suite advisors and outputs multi-round allocation plans scored on role integration, conditional boldness, history-sensitive judgment, and plan validity.
If this is right
- Models that engage more deeply with conflicting advisor perspectives produce less decisive allocation plans.
- All tested models exhibit single-advisor capture and historical amnesia as recurring failure modes.
- Current frontier LLMs remain limited in handling the full stack of executive capabilities required for organizational decision-making.
- The benchmark results delineate a capability boundary that future AI-assisted executive systems must address.
Where Pith is reading between the lines
- Designers of AI executive assistants may need explicit mechanisms to resolve the observed integration-boldness tradeoff.
- Extending the benchmark to include measurable real-company financial outcomes could test whether calibration scores predict downstream performance.
- The same multi-advisor structure could be adapted to evaluate LLMs in other domains with information asymmetry such as regulatory compliance or clinical resource allocation.
Load-bearing premise
The 13 scenarios and four role-conditioned advisors with private signals accurately capture the defining challenges of real executive decision-making under information asymmetry, organizational constraints, and temporal dependencies.
What would settle it
Running the same models on a new set of 13 scenarios drawn from documented historical corporate reallocation cases and checking whether models with higher strategic calibration scores produce allocations closer to the observed real-world outcomes.
Figures
read the original abstract
Evaluating the decision-making capabilities of large language models (LLMs) is a growing research priority, yet existing benchmarks focus on isolated cognitive tasks such as reasoning, knowledge retrieval, and economic rationality in stylized settings. These evaluations overlook the defining challenge of real executive decision-making: integrating conflicting recommendations from specialized stakeholders under information asymmetry, organizational constraints, and temporal dependencies. We introduce \textsc{CEO-Bench}, a multi-agent benchmark that evaluates LLMs on CEO-level strategic resource reallocation -- the process of redirecting capital across business units in a multi-round, constraint-rich organizational environment. In \textsc{CEO-Bench}, LLM agents receive conflicting advice from four role-conditioned C-suite advisors (CFO, CTO, COO, CMO), each with private signals and distinct priorities, and must synthesize these into a concrete allocation plan evaluated along four dimensions: role integration, conditional boldness, history-sensitive judgment, and plan validity. Experiments across five frontier models on 13 scenarios reveal that all models achieve high structural validity but diverge sharply on strategic calibration -- the hardest capability layer. We identify systematic failure modes including single-advisor capture, conservative default under ambiguity, and historical amnesia, and uncover a structural integration-boldness tradeoff: models that engage more deeply with conflicting perspectives tend to produce less decisive action. These findings delineate the current capability boundary of LLMs as organizational decision-makers and inform the design of future AI-assisted executive systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CEO-Bench, a multi-agent simulation benchmark for evaluating LLMs on CEO-level strategic resource reallocation. In the benchmark, LLM agents must synthesize conflicting private signals from four role-conditioned C-suite advisors (CFO, CTO, COO, CMO) across 13 scenarios in a multi-round, constraint-rich setting. The evaluation uses four dimensions (role integration, conditional boldness, history-sensitive judgment, plan validity) and reports that five frontier models achieve high structural validity but diverge sharply on strategic calibration, with identified failure modes including single-advisor capture, conservative defaults, historical amnesia, and an integration-boldness tradeoff.
Significance. If the benchmark design and metrics hold, the work supplies a reproducible, multi-stakeholder evaluation framework that moves beyond isolated reasoning or economic tasks toward organizational decision-making under asymmetry and constraints. The explicit identification of systematic failure modes and the reported tradeoff between deeper integration and decisiveness would be a concrete contribution to delineating current LLM limits as executive agents and guiding future AI-assisted systems.
major comments (1)
- [Scenario Design and Evaluation Rubrics] The central claim that the observed divergence on strategic calibration delineates the capability boundary of LLMs as organizational decision-makers rests on the assumption that the 13 scenarios and four role-conditioned advisors with private signals accurately instantiate the defining challenges of real executive decisions. No validation against actual corporate cases, expert review of scenario realism, or sensitivity analysis to alternative advisor signal structures is reported; without this, the generalizability of the structural-validity vs. strategic-calibration split cannot be assessed.
minor comments (1)
- [Evaluation Metrics] The four evaluation dimensions are introduced in the abstract but their precise operationalization (e.g., how 'history-sensitive judgment' is scored from multi-round traces) should be stated with explicit rubrics or pseudocode in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating scenario design against real-world executive challenges. This feedback helps clarify the scope and limitations of CEO-Bench. Below we respond directly to the major comment and describe targeted revisions.
read point-by-point responses
-
Referee: The central claim that the observed divergence on strategic calibration delineates the capability boundary of LLMs as organizational decision-makers rests on the assumption that the 13 scenarios and four role-conditioned advisors with private signals accurately instantiate the defining challenges of real executive decisions. No validation against actual corporate cases, expert review of scenario realism, or sensitivity analysis to alternative advisor signal structures is reported; without this, the generalizability of the structural-validity vs. strategic-calibration split cannot be assessed.
Authors: We agree that the absence of direct validation against real corporate cases or formal expert review limits strong claims about external validity. The 13 scenarios were constructed to isolate core executive challenges—information asymmetry, conflicting stakeholder priorities, multi-round temporal dependencies, and hard resource constraints—drawing on established strategic management literature (e.g., capital reallocation under uncertainty and cross-functional conflict). Each scenario varies these dimensions systematically while keeping advisor roles fixed to standard C-suite mandates. This controlled, reproducible design enables the clean identification of failure modes and the integration-boldness tradeoff that would be difficult to isolate in observational corporate data. Nevertheless, we recognize that without external anchoring the generalizability of the structural-validity versus strategic-calibration distinction remains provisional. In the revised manuscript we will: (1) expand the Scenario Design subsection with an explicit mapping of each scenario to documented real-world analogs, (2) add a dedicated Limitations paragraph on external validity, and (3) include a sensitivity analysis that perturbs advisor signal strengths and conflict levels in two representative scenarios. These additions will better support the reported divergence while transparently bounding the claims. revision: yes
Circularity Check
No significant circularity; benchmark design and results are independently specified
full rationale
The paper introduces CEO-Bench as an explicit multi-agent simulation with fixed scenarios, advisor roles, private signals, and four evaluation dimensions (role integration, conditional boldness, history-sensitive judgment, plan validity). These elements are defined in the manuscript prior to any model runs. The reported outcomes—high structural validity across models with divergence on strategic calibration—are direct empirical measurements obtained by executing the five LLMs on the 13 scenarios. No parameter is fitted to a data subset and then relabeled as a prediction; no result is derived by construction from the inputs; no load-bearing claim rests on a self-citation chain; and no uniqueness theorem or ansatz is smuggled in. The mapping from observed outputs to capability layers can be inspected against the stated rubrics without reduction to the benchmark definition itself. This is a standard, self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Harvard business review , volume=
The manager's job: Folklore and fact , author=. Harvard business review , volume=
-
[2]
, author=
The Nature of Managerial Work. , author=. 1974 , publisher=
1974
-
[3]
2009 , publisher=
Managing , author=. 2009 , publisher=
2009
-
[4]
1968 , publisher=
The functions of the executive , author=. 1968 , publisher=
1968
-
[5]
1993 , publisher=
Organizations , author=. 1993 , publisher=
1993
-
[6]
Strategic management journal , volume=
Strategic decision making , author=. Strategic management journal , volume=. 1992 , publisher=
1992
-
[7]
Administrative science quarterly , pages=
A process model of internal corporate venturing in the diversified major firm , author=. Administrative science quarterly , pages=. 1983 , publisher=
1983
-
[8]
Managerial and Decision Economics , pages=
The Coasian and Knightian theories of the firm , author=. Managerial and Decision Economics , pages=. 1989 , publisher=
1989
-
[9]
Journal of Management , volume=
A review of the internal capital allocation literature: Piecing together the capital allocation puzzle , author=. Journal of Management , volume=. 2017 , publisher=
2017
-
[10]
The Review of Financial Studies , volume=
Resource allocation within firms and financial market dislocation: Evidence from diversified conglomerates , author=. The Review of Financial Studies , volume=. 2014 , publisher=
2014
-
[11]
The Journal of Finance , volume=
Capital and labor reallocation within firms , author=. The Journal of Finance , volume=. 2015 , publisher=
2015
-
[12]
The journal of finance , volume=
Internal capital markets and the competition for corporate resources , author=. The journal of finance , volume=. 1997 , publisher=
1997
-
[13]
The journal of Finance , volume=
The cost of diversity: The diversification discount and inefficient investment , author=. The journal of Finance , volume=. 2000 , publisher=
2000
-
[14]
The Review of Financial Studies , volume=
Evidence on the dark side of internal capital markets , author=. The Review of Financial Studies , volume=. 2010 , publisher=
2010
-
[15]
Business Functions
How nimble resource allocation can double your company’s value , author=. Business Functions. May , volume=
-
[16]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[17]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dmt-rolebench: A dynamic multi-turn dialogue based benchmark for role-playing evaluation of large language model and agent , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Computers in Human Behavior: Artificial Humans , pages=
RVBench: Role values benchmark for role-playing LLMs , author=. Computers in Human Behavior: Artificial Humans , pages=. 2025 , publisher=
2025
-
[20]
IEEE Robotics and Automation Letters , year=
Llm-based multi-agent decision-making: Challenges and future directions , author=. IEEE Robotics and Automation Letters , year=
-
[21]
arXiv preprint arXiv:2402.09552 , year=
Steer: Assessing the economic rationality of large language models , author=. arXiv preprint arXiv:2402.09552 , year=
-
[22]
Strategy Science , volume=
How well can AI do strategy? Empirical benchmarking using strategy simulations , author=. Strategy Science , volume=. 2026 , publisher=
2026
-
[23]
International Conference on Learning Representations , volume=
Large language models as optimizers , author=. International Conference on Learning Representations , volume=
-
[24]
arXiv preprint arXiv:2404.01230 , year=
Llm as a mastermind: A survey of strategic reasoning with large language models , author=. arXiv preprint arXiv:2404.01230 , year=
-
[25]
Strategic behavior of large language models: Game structure vs. contextual framing , author=. arXiv preprint arXiv:2309.05898 , year=
-
[26]
arXiv preprint arXiv:2604.13592 , year=
Foresight Optimization for Strategic Reasoning in Large Language Models , author=. arXiv preprint arXiv:2604.13592 , year=
-
[27]
arXiv preprint arXiv:2605.09009 , year=
Large Language Models for Sequential Decision-Making: Improving In-Context Learning via Supervised Fine-Tuning , author=. arXiv preprint arXiv:2605.09009 , year=
-
[28]
Journal of Business Research , volume=
AI strategy under institutional pressure: strategic conformity and decision-making in large language models , author=. Journal of Business Research , volume=. 2026 , publisher=
2026
-
[29]
2022 , publisher=
CEO excellence: The six mindsets that distinguish the best leaders from the rest , author=. 2022 , publisher=
2022
-
[30]
arXiv preprint arXiv:2402.01680 , year=
Large language model based multi-agents: A survey of progress and challenges , author=. arXiv preprint arXiv:2402.01680 , year=
-
[31]
arXiv preprint arXiv:2503.18825 , year=
EconEvals: Benchmarks and Litmus Tests for Economic Decision-Making by LLM Agents , author=. arXiv preprint arXiv:2503.18825 , year=
-
[32]
McKinsey Quarterly , volume=
How to put your money where your strategy is , author=. McKinsey Quarterly , volume=
-
[33]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[34]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[35]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[36]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[37]
arXiv preprint arXiv:2605.14355 , year=
Herculean: An Agentic Benchmark for Financial Intelligence , author=. arXiv preprint arXiv:2605.14355 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.