Supporting System Testing with a Multi-Agent LLM-based Framework for Knowledge Graph Extraction: A Case Study with Ethernet Switch Systems
Pith reviewed 2026-05-20 08:28 UTC · model grok-4.3
The pith
A multi-agent LLM framework extracts knowledge graphs from Ethernet switch manuals at 0.97-0.99 correctness to support test automation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
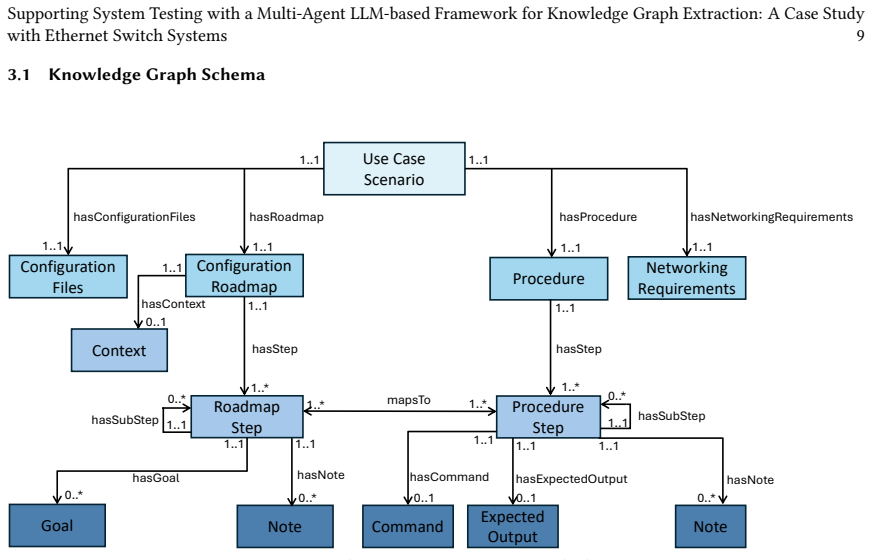
The multi-agent LLM-based framework extracts knowledge graphs from Ethernet switch configuration manuals using a fine-grained KG schema and an iterative Extract-Evaluate-Improve loop. On 50 real-world manuals the original prompts deliver average correctness scores of 0.97 to 0.99 across three extraction tasks, with further gains on difficult manuals through targeted prompt refinement. LLM judgments agree with human evaluations at Cohen's kappa of at least 0.72, and the resulting graphs support generation of useful and correct test case specifications for downstream system testing.
What carries the argument
Multi-agent LLM framework with fine-grained knowledge graph schema and iterative Extract-Evaluate-Improve loop that structures configuration knowledge from semi-structured technical manuals.
If this is right
- The generated knowledge graphs enable direct creation of test case specifications for Ethernet switch systems.
- Targeted prompt refinement inside the EEI loop raises correctness on the most complex manuals.
- Substantial agreement between LLM and human evaluations indicates the extraction outputs are reliable enough for industrial use.
Where Pith is reading between the lines
- The same multi-agent and iterative approach could convert other semi-structured industrial documents into machine-readable form for testing or analysis.
- Embedding the resulting graphs into existing test-generation tools would further reduce manual effort in hardware and software validation workflows.
- Full automation of the refinement step could eventually remove the need for human prompt adjustments on most documents.
Load-bearing premise
The fine-grained KG schema and iterative EEI loop are assumed to capture all implicit step attributes and complex section dependencies present in the manuals without systematic omission of critical configuration knowledge.
What would settle it
A new collection of Ethernet switch manuals in which the extracted graphs omit important configuration parameters or dependencies and thereby produce invalid test cases would show the framework fails to capture the full knowledge.
Figures













read the original abstract
Technical documents contain rich domain knowledge for automating downstream tasks such as system testing. While this paper focuses on Ethernet switch configuration manuals (ESCMs), we propose a general framework that can be adapted to different industrial contexts. ESCMs provide valuable domain knowledge for Ethernet switch testing, but their semi-structured format, implicit step attributes, and complex section dependencies make them difficult to directly leverage for test automation. To address this, we generate knowledge graphs (KGs) that capture configuration knowledge from ESCM in a structured form. We propose a multi-agent LLM-based framework that extracts, evaluates, and improves KGs from ESCMs using a fine-grained KG schema and an iterative Extract-Evaluate-Improve (EEI) loop. Our evaluation on 50 real-world ESCMs shows that our framework achieves high extraction correctness using the original prompts, with average correctness scores ranging from 0.97 to 0.99 across three extraction tasks. For challenging ESCMs, the EEI loop further improves correctness through manual-specific prompt refinement. Moreover, the LLM judgments and human evaluations show substantial agreement, with Cohen's kappa of at least 0.72 across all extraction tasks. Finally, feedback from industry testers indicates that the generated KGs can support the generation of useful and correct test case specifications (TCSs) for downstream testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multi-agent LLM-based framework for extracting knowledge graphs from semi-structured Ethernet switch configuration manuals (ESCMs) to support system testing. It introduces a fine-grained KG schema and an iterative Extract-Evaluate-Improve (EEI) loop, evaluates the approach on 50 real-world ESCMs reporting average correctness scores of 0.97–0.99 across three extraction tasks, documents Cohen’s kappa ≥ 0.72 agreement with human evaluators, and includes positive feedback from industry testers on utility for generating test case specifications.
Significance. If the extraction results hold, the work offers a practical contribution to automating knowledge capture from industrial technical documents for downstream testing tasks. Strengths include the use of 50 real documents, quantitative correctness metrics, human-LLM agreement statistics, and direct industry feedback. These elements provide empirical grounding for the extraction fidelity claims and suggest applicability beyond the Ethernet switch case study.
major comments (1)
- [§4] §4 (KG Schema Definition and EEI Loop): The evaluation reports high correctness (0.97–0.99) and human agreement (κ ≥ 0.72) but measures fidelity to the chosen schema rather than schema completeness. No independent audit is described that checks whether recurring implicit elements—such as conditional configuration rules, cross-section references, or vendor-specific step attributes—are systematically omitted from the fine-grained schema. This assumption is load-bearing for the claim that the resulting KGs fully support generation of correct and complete test case specifications.
minor comments (2)
- [Abstract] Abstract: The three extraction tasks are referenced but not named or briefly characterized, which would improve immediate readability for readers unfamiliar with the domain.
- [§5] §5 (Evaluation): Table or figure captions for the correctness scores and kappa values could explicitly state the number of documents and evaluators to allow quick assessment of statistical robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and describe the revisions we will make to strengthen the presentation of our approach.
read point-by-point responses
-
Referee: [§4] §4 (KG Schema Definition and EEI Loop): The evaluation reports high correctness (0.97–0.99) and human agreement (κ ≥ 0.72) but measures fidelity to the chosen schema rather than schema completeness. No independent audit is described that checks whether recurring implicit elements—such as conditional configuration rules, cross-section references, or vendor-specific step attributes—are systematically omitted from the fine-grained schema. This assumption is load-bearing for the claim that the resulting KGs fully support generation of correct and complete test case specifications.
Authors: We appreciate the referee’s distinction between extraction fidelity to a given schema and independent verification of schema completeness. The fine-grained KG schema was constructed from an initial analysis of representative ESCMs together with domain knowledge provided by our industry collaborators, with the explicit goal of supporting downstream test-case specification generation. The EEI loop and manual-specific prompt refinements were introduced precisely to improve extraction quality within that schema. We acknowledge that the reported metrics (correctness 0.97–0.99 and κ ≥ 0.72) evaluate how faithfully the extracted graphs conform to the chosen schema rather than whether every possible implicit element (conditional rules, cross-references, vendor-specific attributes) has been exhaustively captured. At the same time, the positive feedback from industry testers on the utility of the resulting KGs for producing correct and complete test cases offers pragmatic evidence that the schema is adequate for the intended use. In the revised manuscript we will (i) expand §4 with a clearer description of the schema-design process and its grounding in domain input, (ii) explicitly state that correctness is measured relative to the schema, and (iii) add a limitations paragraph discussing potential omissions and how the framework can be extended if additional elements are later identified. revision: yes
Circularity Check
No significant circularity; evaluation relies on external human judgments and industry feedback
full rationale
The paper presents a multi-agent LLM framework for KG extraction from ESCMs, with evaluation on 50 real-world documents using human correctness scores (0.97-0.99) and Cohen's kappa agreement (≥0.72). These metrics are computed against independent human annotations and tester feedback rather than any fitted parameters, self-referential predictions, or schema-derived quantities that reduce to the framework's own inputs. The KG schema and EEI loop are design choices justified by domain needs, not derived from the reported results. No equations, self-citation load-bearing uniqueness theorems, or renamings of known results appear in the derivation chain. The central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models guided by a fine-grained schema can reliably extract configuration knowledge from semi-structured technical manuals.
Reference graph
Works this paper leans on
-
[1]
Accessed: 2025. Langchain Official Website. https://www.langchain.com/
work page 2025
-
[2]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. 65–72
work page 2005
-
[3]
Zhen Bi, Jing Chen, Yinuo Jiang, Feiyu Xiong, Wei Guo, Huajun Chen, and Ningyu Zhang. 2024. Codekgc: Code language model for generative knowledge graph construction.ACM Transactions on Asian and Low-Resource Language Information Processing23, 3 (2024), 1–16
work page 2024
- [4]
-
[5]
Alberto Rodrigues Da Silva, Ana CR Paiva, and Valter ER Da Silva. 2018. A test specification language for information systems based on data entities, use cases and state machines. InInternational Conference on Model-Driven Engineering and Software Development. Springer, 455–474
work page 2018
-
[6]
Jinlan Fu, See Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2024. Gptscore: Evaluate as you desire. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 6556–6576
work page 2024
-
[7]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. 2024. A survey on llm-as-a-judge.The Innovation(2024)
work page 2024
-
[8]
Liang Guo, Fu Yan, Yuqian Lu, Ming Zhou, and Tao Yang. 2021. An automatic machining process decision-making system based on knowledge graph.International journal of computer integrated manufacturing34, 12 (2021), 1348–1369
work page 2021
-
[9]
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d’Amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, et al. 2021. Knowledge graphs.ACM Computing Surveys (Csur)54, 4 (2021), 1–37
work page 2021
-
[10]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM computing surveys55, 12 (2023), 1–38
work page 2023
- [11]
- [12]
-
[13]
Fuliang Li, Jiahai Yang, Jianping Wu, Zhiyan Zheng, Huijing Zhang, and Xingwei Wang. 2014. Configuration analysis and recommendation: Case studies in IPv6 networks.Computer Communications53 (2014), 37–51
work page 2014
-
[14]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
work page 2004
-
[15]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics12 (2024), 157–173
work page 2024
-
[16]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Satoshi Masuda, Satoshi Kouzawa, Kyousuke Sezai, Hidetoshi Suhara, Yasuaki Hiruta, and Kunihiro Kudou. 2026. Generating high-level test cases from requirements using LLM: An industry study. In2026 International Conference on Artificial Intelligence, Computer, Data Sciences and Applications (ACDSA). IEEE, 1–9
work page 2026
-
[18]
Dragan Milchevski, Gordon Frank, Anna Hätty, Bingqing Wang, Xiaowei Zhou, and Zhe Feng. 2025. Multi-Step Generation of Test Specifications using Large Language Models for System-Level Requirements. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track). 132–146
work page 2025
-
[19]
OpenAI. [n. d.]. OpenAI API Reference. https://platform.openai.com/docs/api-reference/introduction. Accessed: 2026-02-04
work page 2026
-
[20]
OpenAI. 2025. Introducing GPT-5. https://openai.com/index/introducing-gpt-5/. Accessed: 2026-04-23
work page 2025
-
[21]
Kazuki Otomo, Satoru Kobayashi, Kensuke Fukuda, Osamu Akashi, Kimihiro Mizutani, and Hiroshi Esaki. 2021. Towards extracting semantics of network config blocks. In2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 1443–1448
work page 2021
-
[22]
Jeff Z Pan, Simon Razniewski, Jan-Christoph Kalo, Sneha Singhania, Jiaoyan Chen, Stefan Dietze, Hajira Jabeen, Janna Omeliyanenko, Wen Zhang, Matteo Lissandrini, et al. 2023. Large language models and knowledge graphs: Opportunities and challenges.arXiv preprint arXiv:2308.06374(2023)
-
[23]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318. Manuscript submitted to ACM 44 Pan et al
work page 2002
-
[24]
Ciyuan Peng, Feng Xia, Mehdi Naseriparsa, and Francesco Osborne. 2023. Knowledge graphs: Opportunities and challenges.Artificial intelligence review56, 11 (2023), 13071–13102
work page 2023
-
[25]
Ofir Press, Noah A Smith, and Mike Lewis. 2021. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Syed Tahseen Raza Rizvi, Dominique Mercier, Stefan Agne, Steffen Erkel, Andreas Dengel, and Sheraz Ahmed. 2018. Ontology-based Information Extraction from Technical Documents.. InICAART (2). 493–500
work page 2018
-
[27]
Monalisa Sarma and Rajib Mall. 2009. Automatic generation of test specifications for coverage of system state transitions.Information and Software Technology51, 2 (2009), 418–432
work page 2009
-
[28]
HM Sneed. 1993. Automated tool support for ANSI/IEEE STD: 829-1983 software test documentation. InProceedings 1993 Software Engineering Standards Symposium. IEEE, 308–316
work page 1993
-
[29]
Yanqi Su, Zheming Han, Zhenchang Xing, Xin Xia, Xiwei Xu, Liming Zhu, and Qinghua Lu. 2022. Constructing a system knowledge graph of user tasks and failures from bug reports to support soap opera testing. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–13
work page 2022
-
[30]
Yanqi Su, Dianshu Liao, Zhenchang Xing, Qing Huang, Mulong Xie, Qinghua Lu, and Xiwei Xu. 2024. Enhancing exploratory testing by large language model and knowledge graph. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–12
work page 2024
-
[31]
Yanqi Su, Zhenchang Xing, Chong Wang, Chunyang Chen, Sherry Xu, Qinghua Lu, and Liming Zhu. 2025. Automated soap opera testing directed by llms and scenario knowledge: Feasibility, challenges, and road ahead.Proceedings of the ACM on Software Engineering2, FSE (2025), 757–778
work page 2025
-
[32]
2010.Practical model-based testing: a tools approach
Mark Utting and Bruno Legeard. 2010.Practical model-based testing: a tools approach. Elsevier
work page 2010
- [33]
-
[34]
Zhenzhen Yang, Rubing Huang, Chenhui Cui, Nan Niu, and Dave Towey. 2025. Requirements-based test generation: A comprehensive survey.ACM Transactions on Software Engineering and Methodology(2025)
work page 2025
-
[35]
Hongbin Ye, Ningyu Zhang, Hui Chen, and Huajun Chen. 2022. Generative knowledge graph construction: A review. InProceedings of the 2022 conference on empirical methods in natural language processing. 1–17
work page 2022
-
[36]
Bowen Zhang and Harold Soh. 2024. Extract, define, canonicalize: An llm-based framework for knowledge graph construction. InProceedings of the 2024 conference on empirical methods in natural language processing. 9820–9836
work page 2024
-
[37]
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2025. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models.Computational Linguistics(2025), 1–46
work page 2025
-
[38]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al
-
[39]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
work page 2023
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.