Q-Fold: Query-Aware Focus-Context Spatio-Temporal Folding for Long Video Understanding
Pith reviewed 2026-06-27 10:02 UTC · model grok-4.3
The pith
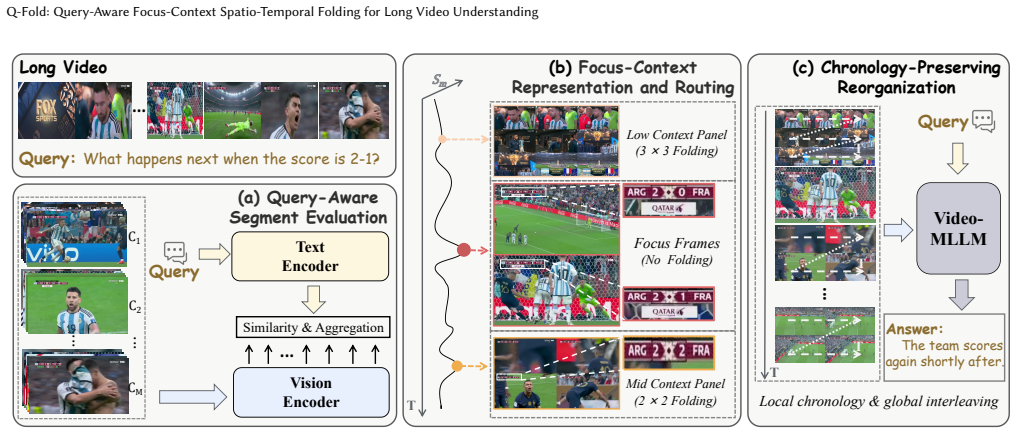
Q-Fold builds query-guided Focus-Context representations from long videos by keeping relevant segments as high-fidelity frames and folding others into contextual layouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
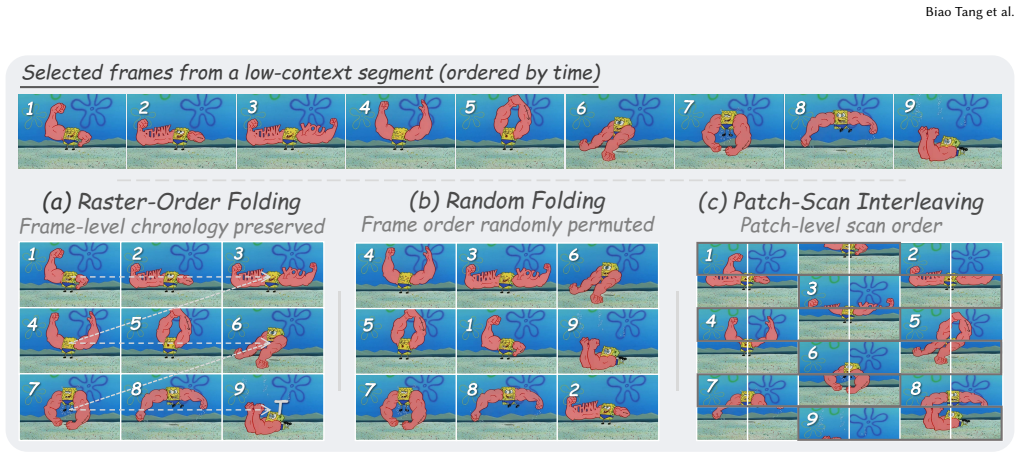
Q-Fold operates on contiguous temporal segments rather than isolated frames to construct a heterogeneous Focus-Context representation guided by the input query, preserving query-relevant segments as high-fidelity Focus Frames while folding less relevant segments into chronology-preserving contextual layouts.
What carries the argument
Query-aware Focus-Context spatio-temporal folding on temporal segments, which assigns high-fidelity preservation to relevant content and compresses the rest while retaining order.
Load-bearing premise
Query relevance can be reliably estimated from segment-level features without any training or fine-tuning of the estimator.
What would settle it
An experiment showing that random or uniform segment selection produces equal or higher accuracy than query-guided folding on the ultra-long video benchmark.
Figures


read the original abstract
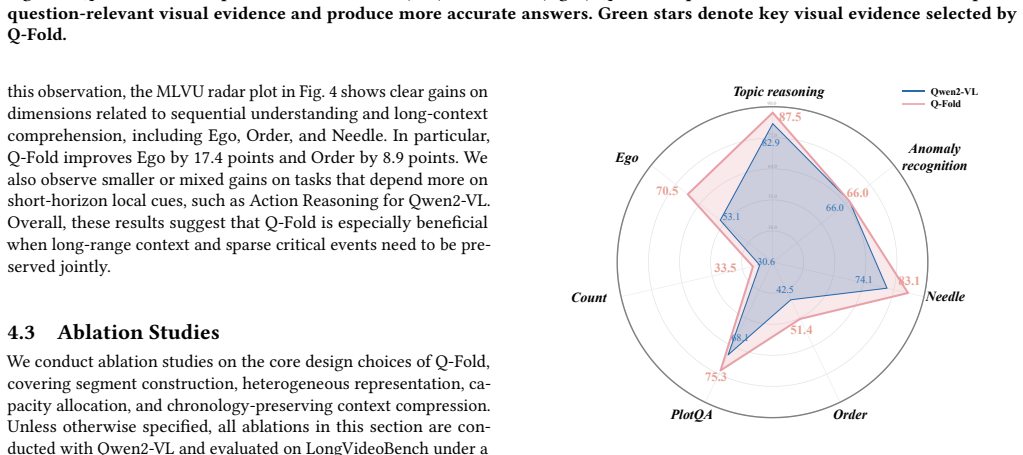
Long-video understanding remains challenging for multimodal large language models, because temporally extended videos often contain thousands of frames and are therefore expensive to process exhaustively. Existing methods usually construct compact visual inputs from long videos under a limited visual budget. However, most of them still follow a frame-centric paradigm and apply similar representations to retained content regardless of its importance. This makes it difficult to preserve both high-fidelity visual evidence and broad temporal coverage. To address this issue, we propose Q-Fold, a training-free input construction framework for long-video understanding. Instead of treating isolated frames as the basic modeling unit, Q-Fold operates on contiguous temporal segments and constructs a heterogeneous Focus--Context representation under query guidance. Query-relevant segments are preserved as high-fidelity Focus Frames, while less relevant segments are folded into chronology-preserving contextual layouts. In this way, Q-Fold preserves critical visual evidence and broad temporal coverage, while better maintaining local temporal continuity within short segments. Experiments on four long-video benchmarks with multiple Video-MLLMs show that Q-Fold consistently improves performance without increasing the input budget. Notably, it achieves gains of up to 9.1 percentage points on an ultra-long video benchmark. Code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Q-Fold, a training-free framework for long-video understanding in multimodal LLMs. It processes videos as contiguous temporal segments rather than isolated frames, using query guidance to retain query-relevant segments as high-fidelity Focus Frames while folding less relevant segments into chronology-preserving contextual layouts. This aims to balance critical visual evidence, broad temporal coverage, and local continuity under a fixed input budget. Experiments on four long-video benchmarks with multiple Video-MLLMs report consistent gains, up to 9.1 percentage points on an ultra-long benchmark.
Significance. If the query-guided relevance estimation from frozen segment features proves reliable, the approach offers a practical training-free method to improve long-video MLLM performance without increasing compute or token budget. The emphasis on segment-level folding for temporal continuity and the commitment to public code are positive elements that could aid reproducibility and adoption in efficient video processing pipelines.
major comments (2)
- [Abstract] Abstract: the central performance gains (up to 9.1 pp) rest on the unverified assumption that a training-free estimator can accurately identify query-relevant segments from segment-level features alone; no procedure, similarity metric, threshold, or validation of this relevance step is described, leaving open whether gains arise from correct Focus/Context decisions or from the folding structure itself.
- [Experiments] Experiments section (implied by benchmark results): reported gains lack error bars, multiple runs, or ablations isolating the relevance estimator from the folding mechanism, which is required to substantiate that the query-aware component is load-bearing rather than incidental.
minor comments (2)
- [Abstract] Abstract: the phrase 'query guidance' is used without specifying whether it involves text-video similarity, attention, or another mechanism; this notation should be clarified early.
- The manuscript states code will be released but provides no link or repository in the current version; this should be added for review.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and commit to revisions that will strengthen the description of the relevance estimator and provide supporting ablations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance gains (up to 9.1 pp) rest on the unverified assumption that a training-free estimator can accurately identify query-relevant segments from segment-level features alone; no procedure, similarity metric, threshold, or validation of this relevance step is described, leaving open whether gains arise from correct Focus/Context decisions or from the folding structure itself.
Authors: We agree that the current manuscript provides insufficient detail on the query-guided relevance estimation step. We will add an explicit subsection in the Methods that specifies the exact procedure: segment features are obtained by averaging frame embeddings within each temporal segment, relevance is computed via cosine similarity to the query embedding produced by the same vision encoder, and segments above a fixed percentile threshold are designated as Focus while the remainder are folded. We will also include a small validation experiment measuring the estimator's precision on a held-out set of annotated query-relevant segments. These additions will clarify the source of the observed gains. revision: yes
-
Referee: [Experiments] Experiments section (implied by benchmark results): reported gains lack error bars, multiple runs, or ablations isolating the relevance estimator from the folding mechanism, which is required to substantiate that the query-aware component is load-bearing rather than incidental.
Authors: We concur that isolating the contribution of the query-aware component is necessary. We will add an ablation study that replaces the relevance estimator with uniform segment selection and with random selection while keeping the folding mechanism identical; the resulting performance drop will quantify the value of query guidance. Regarding statistical reporting, because the core pipeline is deterministic once segments are chosen, we will re-run the full evaluation pipeline across three different random seeds for any stochastic preprocessing steps and report mean and standard deviation. These results will be added to the Experiments section. revision: yes
Circularity Check
No significant circularity; method is training-free with no fitted parameters or self-referential definitions
full rationale
The paper presents Q-Fold as a training-free input construction framework that operates on segments under query guidance, preserving focus frames and folding context without any equations, fitted parameters, or predictions that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and the central claim does not rename known results or fit inputs then relabel them as predictions. The relevance estimator is described as training-free but is not defined in terms of its own outputs, satisfying the criteria for a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. 2025. LLaVA- OneVision-1.5: Fully Open Framework for Democratized Multimodal Training. arXiv:2509.23661
Pith/arXiv arXiv 2025
-
[2]
Shimin Chen, Xiaohan Lan, Yitian Yuan, Zequn Jie, and Lin Ma. 2024. TimeMarker: A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability. arXiv:2411.18211
arXiv 2024
-
[3]
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yun- hao Fang, et al. 2025. LongVILA: Scaling Long-Context Visual Language Models for Long Videos. In13th International Conference on Learning Representations (ICLR)
2025
-
[4]
Lars Doorenbos, Federico Spurio, and Juergen Gall. 2025. Video Panels for Long Video Understanding. arXiv:2509.23724
Pith/arXiv arXiv 2025
-
[5]
Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, and Hui Wang. 2024. Video-CCAM: Enhancing Video-Language Understanding with Causal Cross- Attention Masks for Short and Long Videos. arXiv:2408.14023
arXiv 2024
-
[6]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 24108–24118
2025
-
[7]
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. 2024. MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13504–13514
2024
-
[8]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. GPT-4o System Card. arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[9]
Laurent Itti and Christof Koch. 2001. Computational modelling of visual attention. Nature Reviews Neuroscience2, 3 (2001), 194–203
2001
-
[10]
Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. 2024. An Image Grid Can Be Worth a Video: Zero-shot Video Question Answering Using a VLM. IEEE Access12 (2024), 193057–193075
2024
-
[11]
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2025. VideoChat: Chat-Centric Video Understanding. Science China Information Sciences68, 10 (2025), 200102
2025
-
[12]
Hao Liang, Jiapeng Li, Tianyi Bai, Xijie Huang, Linzhuang Sun, Zhengren Wang, Conghui He, Bin Cui, Chong Chen, and Wentao Zhang. 2024. KeyVideoLLM: Towards Large-scale Video Keyframe Selection. arXiv:2407.03104
arXiv 2024
-
[13]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-LLaVA: Learning United Visual Representation by Alignment Before Pro- jection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 5971–5984
2024
-
[14]
Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao
-
[15]
In13th International Conference on Learning Representations (ICLR)
Oryx MLLM: On-Demand Spatial-Temporal Understanding at Arbitrary Resolution. In13th International Conference on Learning Representations (ICLR)
-
[16]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 12585–12602
2024
-
[17]
Jeffrey Moran and Robert Desimone. 1985. Selective Attention Gates Visual Processing in the Extrastriate Cortex.Science (New York, N.Y.)229 (09 1985), 782–784. doi:10.1126/science.4023713
-
[18]
OpenAI. 2023. GPT-4V(ision) System Card. https://openai.com/index/gpt-4v- system-card/
2023
-
[19]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[20]
InProceedings of the International Conference on Machine Learning (ICML)
Learning Transferable Visual Models From Natural Language Supervi- sion. InProceedings of the International Conference on Machine Learning (ICML). 8748–8763
-
[21]
Weiming Ren, Wentao Ma, Huan Yang, Cong Wei, Ge Zhang, and Wenhu Chen. 2025. Vamba: Understanding Hour-Long Videos with Hybrid Mamba- Transformers. InProceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV). 21197–21208
2025
-
[22]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bor- des, Zhuang Liu, Hu Xu, et al. 2025. LongVU: Spatiotemporal Adaptive Com- pression for Long Video-Language Understanding. InProceedings of the 42nd International Conference on Machine Learning (ICML). 9 Biao Tang et al
2025
-
[23]
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. 2025. Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 26160–26169
2025
-
[24]
Wenhui Tan, Ruihua Song, Jiaze Li, Jianzhong Ju, and Zhenbo Luo. 2026. Think-Clip-Sample: Slow-Fast Frame Selection for Video Understanding. arXiv:2601.11359
arXiv 2026
-
[25]
Canhui Tang, Zifan Han, Hongbo Sun, Sanping Zhou, Xuchong Zhang, Xin Wei, Ye Yuan, Huayu Zhang, Jinglin Xu, and Hao Sun. 2025. TSPO: Temporal Sampling Policy Optimization for Long-form Video Language Understanding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). 9368–9376
2025
-
[26]
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. 2025. Adaptive Keyframe Sampling for Long Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[27]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al
-
[28]
Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805
-
[29]
Qwen Team. 2025. Qwen2.5-VL. https://qwenlm.github.io/blog/qwen2.5-vl/
2025
-
[30]
XiaoMi Core Team, Zihao Yue, Zhenru Lin, et al . 2025. MiMo-VL Technical Report. arXiv:2506.03569
arXiv 2025
-
[31]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-VL: Enhancing Vision- Language Model’s Perception of the World at Any Resolution. arXiv:2409.12191
Pith/arXiv arXiv 2024
-
[32]
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. 2025. LVBench: An Extreme Long Video Understanding Benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 22958–22967
2025
-
[33]
Yuxuan Wang, Yiqi Song, Cihang Xie, Yang Liu, and Zilong Zheng. 2025. Vide- oLLaMB: Long Video Understanding with Recurrent Memory Bridges. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 24170–24181
2025
-
[34]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding. InProceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS)
2024
-
[35]
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, and Afshin Dehghan. 2024. SlowFast-LLaVA: A Strong Training- Free Baseline for Video Large Language Models. arXiv:2407.15841
arXiv 2024
-
[36]
Linli Yao, Haoning Wu, Kun Ouyang, Yuanxing Zhang, Caiming Xiong, Bei Chen, Xu Sun, and Junnan Li. 2025. Generative Frame Sampler for Long Video Understanding. InFindings of the Association for Computational Linguistics: ACL 2025
2025
-
[37]
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. 2024. mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models. arXiv:2408.04840
Pith/arXiv arXiv 2024
-
[38]
Sicheng Yu, Chengkai Jin, Huanyu Wang, Zhenghao Chen, Sheng Jin, Zhongrong Zuo, Xiaolei Xu, Zhenbang Sun, Bingni Zhang, Jiawei Wu, Hao Zhang, and Qianru Sun. 2025. Frame-Voyager: Learning to Query Frames for Video Large Language Models. InProceedings of the 13th International Conference on Learning Representations (ICLR)
2025
-
[39]
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. 2024. Long-CLIP: Unlocking the Long-Text Capability of CLIP. InProceedings of the 18th European Conference on Computer Vision (ECCV)
2024
-
[40]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-LLaMA: An Instruction-Tuned Audio-Visual Language Model for Video Understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP). 543–553
2023
-
[41]
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. 2025. LMMs- Eval: Reality Check on the Evaluation of Large Multimodal Models. InFindings of the Association for Computational Linguistics: NAACL 2025. 881–916
2025
-
[42]
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. 2024. Long Context Transfer from Language to Vision. arXiv:2406.16852
Pith/arXiv arXiv 2024
-
[43]
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. 2025. Q- Frame: Query-aware Frame Selection and Multi-Resolution Adaptation for Video- LLMs. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 22056–22065
2025
-
[44]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al . 2025. MLVU: Benchmarking Multi-task Long Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13691–13701
2025
-
[45]
Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Zhenheng Yang, and Yang You. 2026. FOCUS: Efficient Keyframe Selection for Long Video Understand- ing. InProceedings of the 14th International Conference on Learning Representations (ICLR). 10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.