Data Intelligence Agents: Interpreting, Modeling, and Querying Enterprise Data via Autonomous Coding Agents
Pith reviewed 2026-06-26 18:23 UTC · model grok-4.3
The pith
Autonomous coding agents that generate, execute, validate and repair code match or beat published results on all seven SQL benchmarks across four dialects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An architecture built on autonomous coding agents that generate, execute, validate, and repair concrete code artifacts, combined with shared memory for experience reuse, generalizes across seven SQL benchmarks spanning four task categories and four dialects, matching or surpassing the best published results on all seven while confining adaptation to natural-language instructions.
What carries the argument
Autonomous coding agents (ACAs) that generate, execute, validate, and repair concrete code artifacts, drawing on shared memory for reuse.
If this is right
- The three-agent workflow compresses repeated handoffs between data owners, engineers, and analysts into a single system that surfaces artifacts for expert review.
- Deployment in production for enterprise customers becomes feasible because the agents surface concrete, reviewable code rather than opaque text.
- Generalization across dialects and task categories occurs without retraining or architecture changes, only by updating the natural-language instructions.
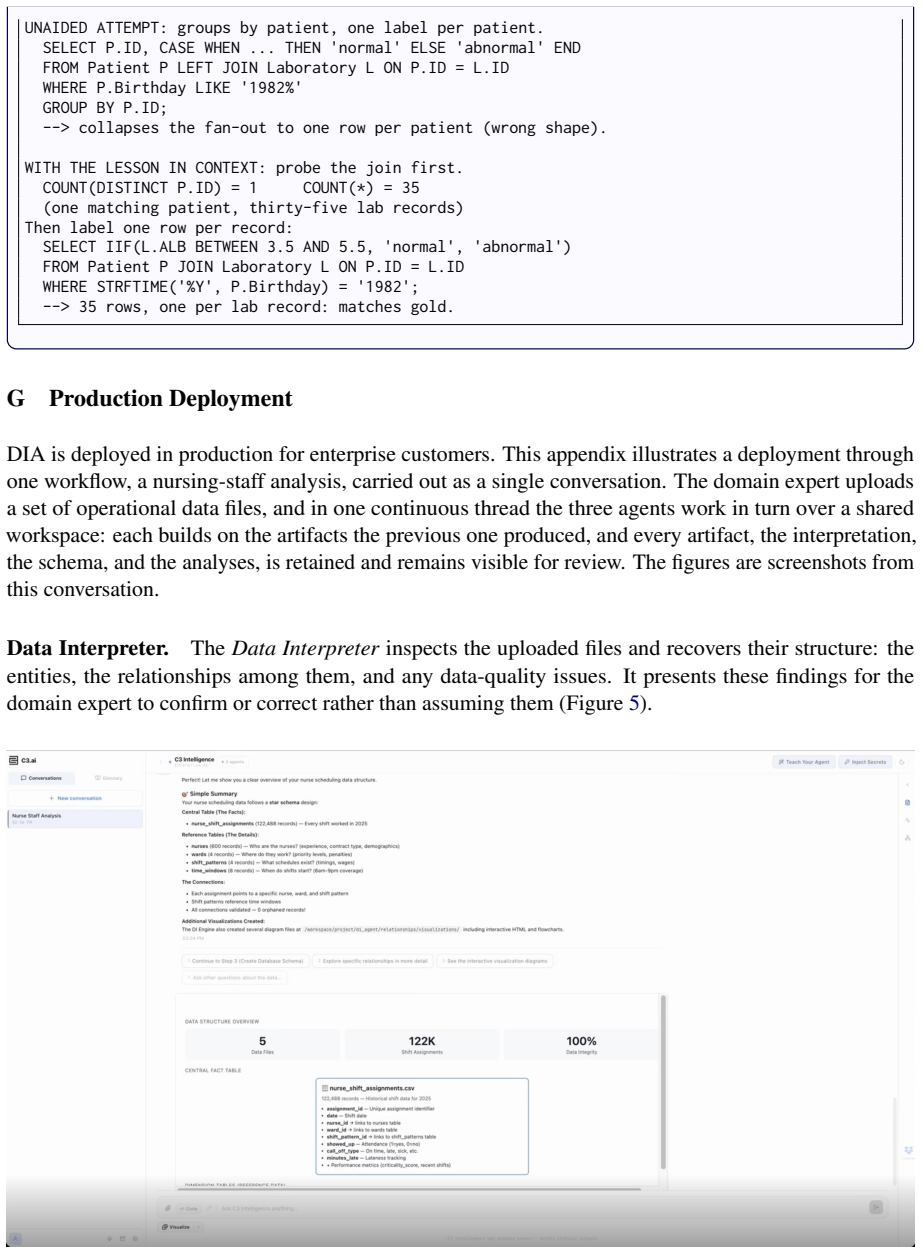
- Shared memory enables reuse of prior successful artifacts, reducing the need to regenerate solutions for similar data problems.
Where Pith is reading between the lines
- The same ACA-plus-shared-memory pattern could be tested on non-SQL data tasks such as ETL pipeline construction or visualization code generation by swapping only the instruction templates.
- If repair loops remain bounded, the approach could reduce the number of domain-expert review cycles required in production data integration.
- Extending the shared memory to include cross-dialect translation examples might further improve zero-shot performance on unseen SQL variants.
Load-bearing premise
Autonomous coding agents can reliably generate, execute, validate, and repair working code for data tasks without human intervention even when only the natural-language instructions change.
What would settle it
A new SQL benchmark or dialect where the agents produce code that fails to execute or validate correctly after repeated repair attempts, despite receiving only natural-language task instructions and no code changes.
Figures

read the original abstract
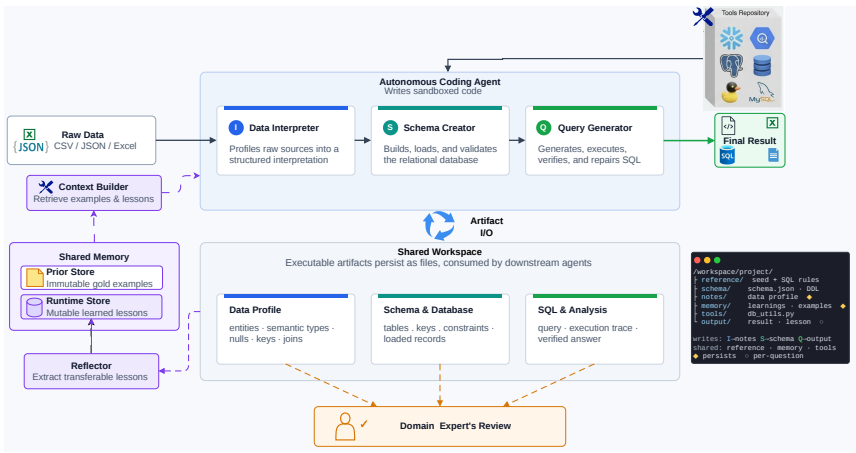
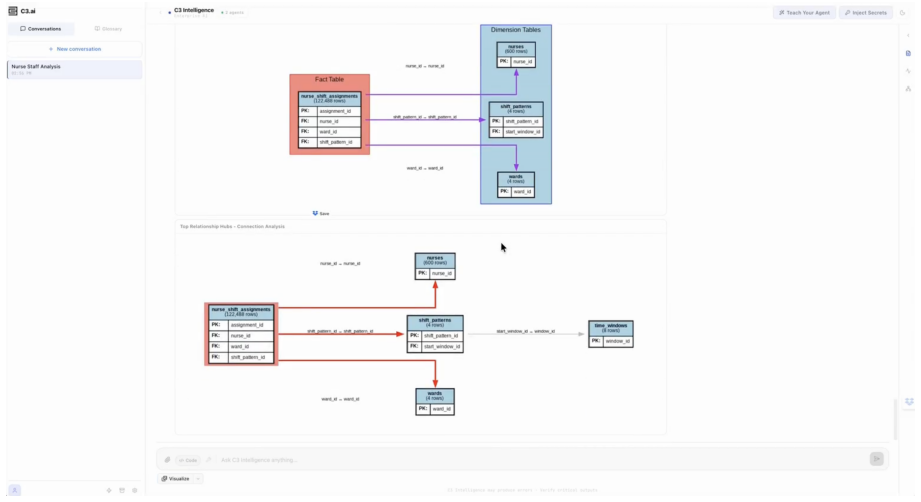
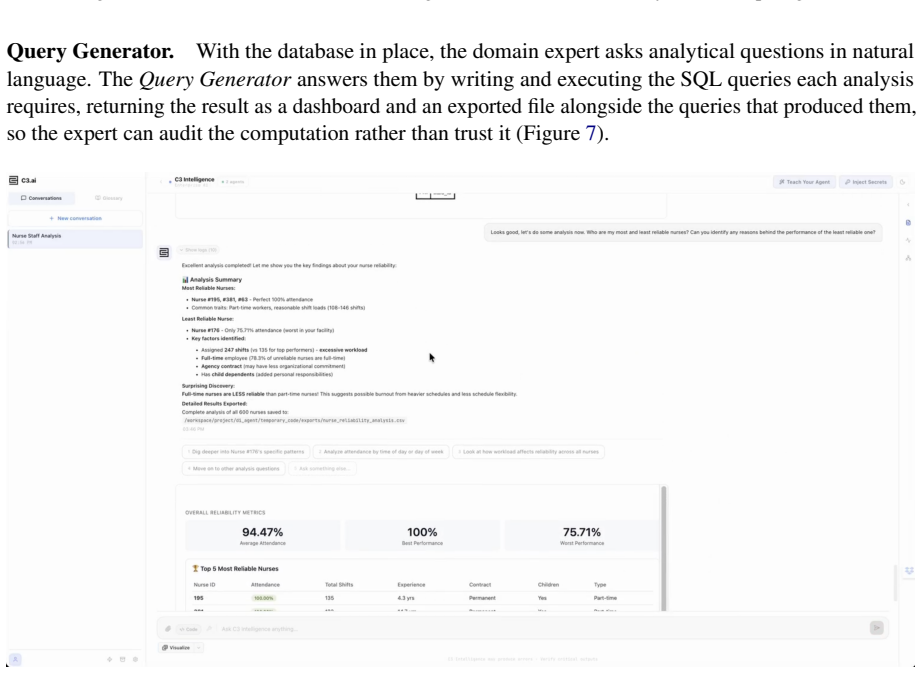
Production data integration is bottlenecked by repeated, lossy handoffs between data owners, engineers, and analysts who must collaboratively discover, structure, and query enterprise data. We present Data Intelligence Agents (DIA), a system of three agents (Data Interpreter, Schema Creator, and Query Generator) that compresses this workflow by treating autonomous coding agents (ACAs) as a first-class abstraction: rather than emitting text, the agents generate, execute, validate, and repair concrete artifacts, draw on a shared memory for experience reuse, and surface each for review by domain experts. DIA is deployed in production for enterprise customers. We study the Query Generator in depth and evaluate it in fully autonomous mode across seven SQL benchmarks spanning four task categories and four dialects. It matches or surpasses the best published results on all seven, demonstrating that an architecture grounded in execution, built on ACAs and a shared memory, generalizes across the data intelligence workload with adaptation confined to natural-language instructions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Data Intelligence Agents (DIA), a system of three agents (Data Interpreter, Schema Creator, and Query Generator) that treat autonomous coding agents as a first-class abstraction. These agents generate, execute, validate, and repair concrete code artifacts rather than emitting text, draw on shared memory for reuse, and are intended for review by domain experts. The Query Generator is studied in depth and evaluated in fully autonomous mode on seven SQL benchmarks spanning four task categories and four dialects; the central claim is that it matches or surpasses the best published results on all seven, with adaptation confined to natural-language instructions and generalization supported by the execution-grounded architecture and shared memory. The system is deployed in production for enterprise customers.
Significance. If the evaluation results hold with full substantiation of the autonomous loop, the work would be significant for multi-agent systems research by showing that an architecture based on code generation/execution/repair with shared memory can generalize across diverse data intelligence workloads without benchmark-specific parameter changes. The production deployment and emphasis on concrete artifacts add practical value beyond typical text-only agent evaluations.
major comments (2)
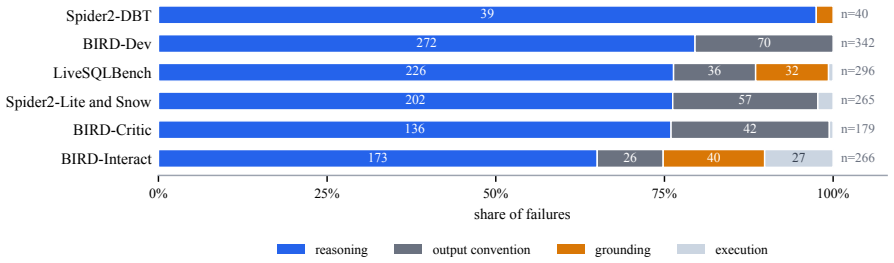
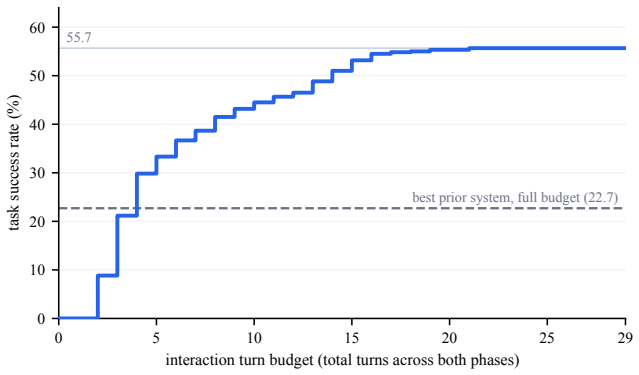
- [Evaluation of the Query Generator] The central generalization claim (that the architecture generalizes across the seven benchmarks with adaptation confined to natural-language instructions) rests on the Query Generator operating in fully autonomous mode. However, the manuscript provides no quantitative reporting on autonomous success rate, average repair iterations, failure modes, or explicit verification that agent code, prompts, and memory initialization were identical across all benchmarks and dialects.
- [Methods / Agent Architecture] The description of the autonomous coding agent loop (generate, execute, validate, repair) lacks sufficient detail on how validation and repair are implemented without human intervention or benchmark-specific scaffolding, which is load-bearing for assessing whether the reported SOTA-matching performance truly demonstrates the claimed generalization.
minor comments (2)
- The abstract and introduction mention production deployment for enterprise customers but provide no supporting metrics, case studies, or error analysis from real deployments to ground the practical claims.
- Notation for the three agents and shared memory could be clarified with a diagram or explicit pseudocode to improve readability of the system architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of the work. We address each major comment below and will incorporate the requested details into a revised manuscript to better substantiate the autonomous operation and generalization claims.
read point-by-point responses
-
Referee: [Evaluation of the Query Generator] The central generalization claim (that the architecture generalizes across the seven benchmarks with adaptation confined to natural-language instructions) rests on the Query Generator operating in fully autonomous mode. However, the manuscript provides no quantitative reporting on autonomous success rate, average repair iterations, failure modes, or explicit verification that agent code, prompts, and memory initialization were identical across all benchmarks and dialects.
Authors: We agree that quantitative metrics on autonomous performance are needed to substantiate the generalization claim. In the revised manuscript we will add a dedicated evaluation subsection (or appendix table) reporting: (i) autonomous success rate per benchmark (percentage of queries solved without any human intervention), (ii) average number of repair iterations per query, (iii) breakdown of failure modes (e.g., execution errors, validation failures, timeout), and (iv) explicit confirmation that the agent code base, system prompts, and shared-memory initialization were held identical across all seven benchmarks and four dialects, with only the natural-language task instructions varying. revision: yes
-
Referee: [Methods / Agent Architecture] The description of the autonomous coding agent loop (generate, execute, validate, repair) lacks sufficient detail on how validation and repair are implemented without human intervention or benchmark-specific scaffolding, which is load-bearing for assessing whether the reported SOTA-matching performance truly demonstrates the claimed generalization.
Authors: We acknowledge that the current Methods section does not provide enough implementation detail on the fully autonomous loop. In the revision we will expand the description of the Query Generator to specify: the exact validation criteria (execution success against the target database, syntactic checks, and semantic result matching where ground truth is available), the repair procedure (iterative re-prompting of the agent using error messages and prior attempts retrieved from shared memory), and confirmation that these steps operate without human intervention or any benchmark-specific scaffolding or code templates. revision: yes
Circularity Check
No circularity detected; claims rest on external benchmarks
full rationale
The paper's central claim is an empirical result: the Query Generator matches or surpasses published SOTA on seven independent SQL benchmarks in fully autonomous mode. No equations, parameter fits, self-definitions, or self-citation chains are present in the provided text that would reduce this performance claim to a tautology or internal input. The architecture description and evaluation are self-contained against external benchmarks with no load-bearing internal reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autonomous coding agents can generate, execute, validate, and repair concrete code artifacts for data tasks
invented entities (1)
-
Data Intelligence Agents with Data Interpreter, Schema Creator, and Query Generator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2023 , url=
Pourreza, Mohammadreza and Rafiei, Davood , booktitle=. 2023 , url=
2023
-
[2]
2025 , url=
Pourreza, Mohammadreza and Talaei, Shayan and Sun, Ruoxi and Wang, Xingchen and Zhang, Shuaichen and Mirhoseini, Azalia and Saberi, Amin and Arik, Sercan O , booktitle=. 2025 , url=
2025
-
[3]
Xie, Xiangjin and Xu, Guangwei and Zhao, Lingyan and Guo, Ruijie , journal=
-
[4]
A Preview of
Gao, Yingqi and Liu, Yifu and Li, Xiaoxia and Shi, Xiaorong and Zhu, Yin and Wang, Yiming and Li, Shiqi and Li, Wei and Hong, Yuntao and Luo, Zhiling and others , journal=. A Preview of
-
[5]
, journal=
Yang, Haolin and Zhang, Jipeng and He, Zhitao and Zhou, Alexander and Fung, Yi R. , journal=
-
[6]
2025 , doi=
Li, Haoyang and Wu, Shang and Zhang, Xiaokang and Huang, Xinmei and Zhang, Jing and Jiang, Fuxin and Wang, Shuai and Zhang, Tieying and Chen, Jianjun and Shi, Rui and Chen, Hong and Li, Cuiping , journal=. 2025 , doi=
2025
-
[7]
Cao, Bowen and Liao, Weibin and Sun, Yushi and Fang, Dong and Li, Haitao and Lam, Wai , journal=
-
[8]
Deng, Minghang and Ramachandran, Ashwin and Xu, Canwen and Hu, Lanxiang and Yao, Zhewei and Datta, Anupam and Zhang, Hao , journal=
-
[9]
Biswal, Asim and Lei, Chuan and Qin, Xiao and Li, Aodong and Narayanaswamy, Balakrishnan and Kraska, Tim , journal=
-
[10]
Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-
Chu, Zhibo and Wang, Zichong and Qin, Qitao , journal=. Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-
-
[11]
Yang, Zerui and Wang, Weichuan and Xu, Yanwei and Song, Linqi and Matsuda, Yudai and Han, Wei and Bai, Bo , journal=
-
[12]
Chen, Zui and Li, Han and Zhang, Xinhao and Chen, Xiaoyu and Dong, Chunyin and Wang, Yifeng and Cai, Xin and Zhang, Su and Li, Ziqi and Ding, Chi and Li, Jinxu and Wang, Shuai and Zhao, Dousheng and Gao, Sanhai and Liu, Guangyi , journal=
-
[13]
Next-Generation Database Interfaces: A Survey of
Hong, Zijin and Yuan, Zheng and Zhang, Qinggang and Chen, Hao and Dong, Junnan and Huang, Feiran and Huang, Xiao , journal=. Next-Generation Database Interfaces: A Survey of
-
[14]
Talaei, Shayan and Pourreza, Mohammadreza and Chang, Yu-Chen and Mirhoseini, Azalia and Saberi, Amin , journal=
-
[15]
Wang, Bing and Ren, Changyu and Yang, Jian and Liang, Xinnian and Bai, Jiaqi and Chai, Linzheng and Yan, Zhao and Zhang, Qian-Wen and Yin, Di and Sun, Xing , journal=
-
[16]
2019 , url=
Yu, Tao and Zhang, Rui and Yasunaga, Michihiro and Tan, Yi Chern and Lin, Xi Victoria and others , booktitle=. 2019 , url=
2019
-
[17]
2019 , url=
Yu, Tao and Zhang, Rui and Er, Heyang and Li, Suyi and Xue, Eric and Pang, Bo and others , booktitle=. 2019 , url=
2019
-
[18]
Bogdanov, Olena and Jung, Yeunji and Dhir, Chandra and Gaddam, Pareekshitreddy and Jain, Saurabh and Tumati, Lakshmi and Parthasarathy, Vijay and Shirgaonkar, Anup , journal=
-
[19]
Su, Aofeng and Wang, Aowen and Ye, Chao and Zhou, Chen and Zhang, Ga and Chen, Gang and Zhu, Guangcheng and Wang, Haobo and Xu, Haokai and Chen, Hao and others , journal=
-
[20]
Wang, Qin and Li, Youhuan and Feng, Yansong and Chen, Si and Li, Ziming and Zhang, Pan and Si, Zihui and Chen, Yixuan and Shi, Zhichao and Huang, Zebin and Chen, Guo and Jin, Wenqiang , journal=
-
[21]
Fan, Meihao and Fan, Ju and Zhang, Yuxin and Zhang, Shaolei and Du, Xiaoyong and Song, Jie and Li, Peng and Jiang, Fuxin and Zhang, Tieying and Chen, Jianjun , journal=
-
[22]
2026 , url=
Lei, Fangyu and Meng, Jinxiang and Huang, Yiming and Zhao, Junjie and Zhang, Yitong and Luo, Jianwen and Zou, Xin and Yang, Ruiyi and Shi, Wenbo and Gao, Yan and He, Shizhu and Wang, Zuo and Liu, Qian and Wang, Yang and Wang, Ke and Zhao, Jun and Liu, Kang , booktitle=. 2026 , url=
2026
-
[23]
Executable Code Actions Elicit Better
Wang, Xingyao and Chen, Yangyi and Yuan, Lifan and Zhang, Yizhe and Li, Yunzhu and Peng, Hao and Ji, Heng , booktitle=. Executable Code Actions Elicit Better. 2024 , url=
2024
-
[24]
arXiv preprint arXiv:2506.03011 , year=
Coding Agents with Multimodal Browsing are Generalist Problem Solvers , author=. arXiv preprint arXiv:2506.03011 , year=
-
[25]
2026 , url=
Song, Yang and Vyas, Anoushka and Wei, Zirui and Pakazad, Sina Khoshfetrat and Ohlsson, Henrik and Neubig, Graham , booktitle=. 2026 , url=
2026
-
[26]
Transactions on Machine Learning Research (TMLR) , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[27]
2023 , url=
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle=. 2023 , url=
2023
-
[28]
and Daruki, Samira and Tang, Xiangru and Tirumalashetty, Vishy and Lee, George and Rofouei, Mahsan and Lin, Hangfei and Han, Jiawei and Lee, Chen-Yu and Pfister, Tomas , journal=
Ouyang, Siru and Yan, Jun and Hsu, I-Hung and Chen, Yanfei and Jiang, Ke and Wang, Zifeng and Han, Rujun and Le, Long T. and Daruki, Samira and Tang, Xiangru and Tirumalashetty, Vishy and Lee, George and Rofouei, Mahsan and Lin, Hangfei and Han, Jiawei and Lee, Chen-Yu and Pfister, Tomas , journal=
-
[29]
Divide, Link, and Conquer: Recall-oriented Schema Linking for
Pradeep, Kiran and Db, Kirushikesh and Madaan, Nishtha and Mehta, Sameep and Bhattacharyya, Pushpak , booktitle =. Divide, Link, and Conquer: Recall-oriented Schema Linking for. 2025 , pages =
2025
-
[30]
2025 , pages =
Sharma, Chetan and Narayanam, Ramasuri and Pal, Soumyabrata and Yeturu, Kalidas and Saini, Shiv Kumar and Mukherjee, Koyel , booktitle =. 2025 , pages =
2025
-
[31]
and Heath, Fenno F
Khabiri, Elham and Kephart, Jeffrey O. and Heath, Fenno F. and Jayaraman, Srideepika and Li, Yingjie and Tipu, Fateh A. and Shah, Dhruv and Fokoue, Achille and Bhamidipaty, Anu , booktitle =. Declarative Techniques for. 2025 , pages =
2025
-
[32]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , year =
Enabling Self-Improving Agents to Learn at Test Time With Human-In-The-Loop Guidance , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , year =
2025
-
[33]
Li, Jinyang and Hui, Binyuan and Qu, Ge and others , booktitle=. Can. 2023 , url=
2023
-
[34]
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-
Lei, Fangyu and Chen, Jixuan and Ye, Yuxiao and Cao, Ruisheng and Shin, Dongchan and others , booktitle=. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-. 2025 , url=
2025
-
[35]
2025 , url=
Li, Jinyang and Li, Xiaolong and Qu, Ge and Jacobsson, Per and Qin, Bowen and others , booktitle=. 2025 , url=
2025
-
[36]
2026 , url=
Huo, Nan and Xu, Xiaohan and Li, Jinyang and Jacobsson, Per and Lin, Shipei and others , booktitle=. 2026 , url=
2026
-
[37]
2025 , howpublished=
2025
-
[38]
and Yao, Zhewei and He, Yuxiong , journal=
Wang, Yibo and Kuang, Nikki Lijing and Yu, Philip S. and Yao, Zhewei and He, Yuxiong , journal=. Learning to Retrieve: Dual-Level Long-Term Memory for Text-to-
-
[39]
Wang, Pengfei and Sun, Baolin and Dong, Xuemei and Dai, Yaxun and Yuan, Hongwei and others , journal=
-
[40]
Wang, Ziyang and Zheng, Yuanlei and Cao, Zhenbiao and Zhang, Xiaojin and Wei, Zhongyu and others , journal=
-
[41]
Text-to-
Hao, Zhifeng and Song, Qibin and Cai, Ruichu and Xu, Boyan and others , journal=. Text-to-
-
[42]
Understanding the Effects of Noise in Text-to-
Wretblad, Niklas and Riseby, Fredrik and Biswas, Rahul and Ahmadi, Amin and Holmstr. Understanding the Effects of Noise in Text-to-. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=. doi:10.18653/v1/2024.acl-short.34 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.