Safety is Contextual, LLM-Judges Are Not: Navigating the Rigid Priors of Evaluators
Pith reviewed 2026-06-27 21:37 UTC · model grok-4.3
The pith
LLM-judges rarely adjust safety evaluations when context or definitions contradict their internal priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-judges can learn from new information, yet they are broadly unlikely to adjust their evaluations if the context or safety definition contradicts their prior.
What carries the argument
The internal safety priors of the LLM-judge, which determine whether in-context information or redefined safety criteria can override the model's default safety stance.
If this is right
- Safety evaluations produced by LLM-judges will often reflect the model's fixed priors rather than the criteria explicitly stated in the prompt.
- Providing demonstrations or novel context has limited steering power when the new material conflicts with those priors.
- Generalist and safety-specific LLM judges exhibit similar resistance, suggesting the issue is widespread across current judge models.
Where Pith is reading between the lines
- Hybrid human-plus-LLM review pipelines may be needed for cases where prompt context and model priors diverge.
- The finding limits how far in-context learning alone can be relied upon to enforce new safety policies in evaluator systems.
- Future work could test whether additional training stages that explicitly reward context-following reduce this rigidity.
Load-bearing premise
The tested in-context scenarios, safety definitions, and model set sufficiently represent the behavior of LLM-judges in real deployment for safety evaluation at scale.
What would settle it
A follow-up experiment that presents the same models with real deployment safety cases and shows consistent revision of judgments when the supplied safety definition directly contradicts the model's prior.
Figures

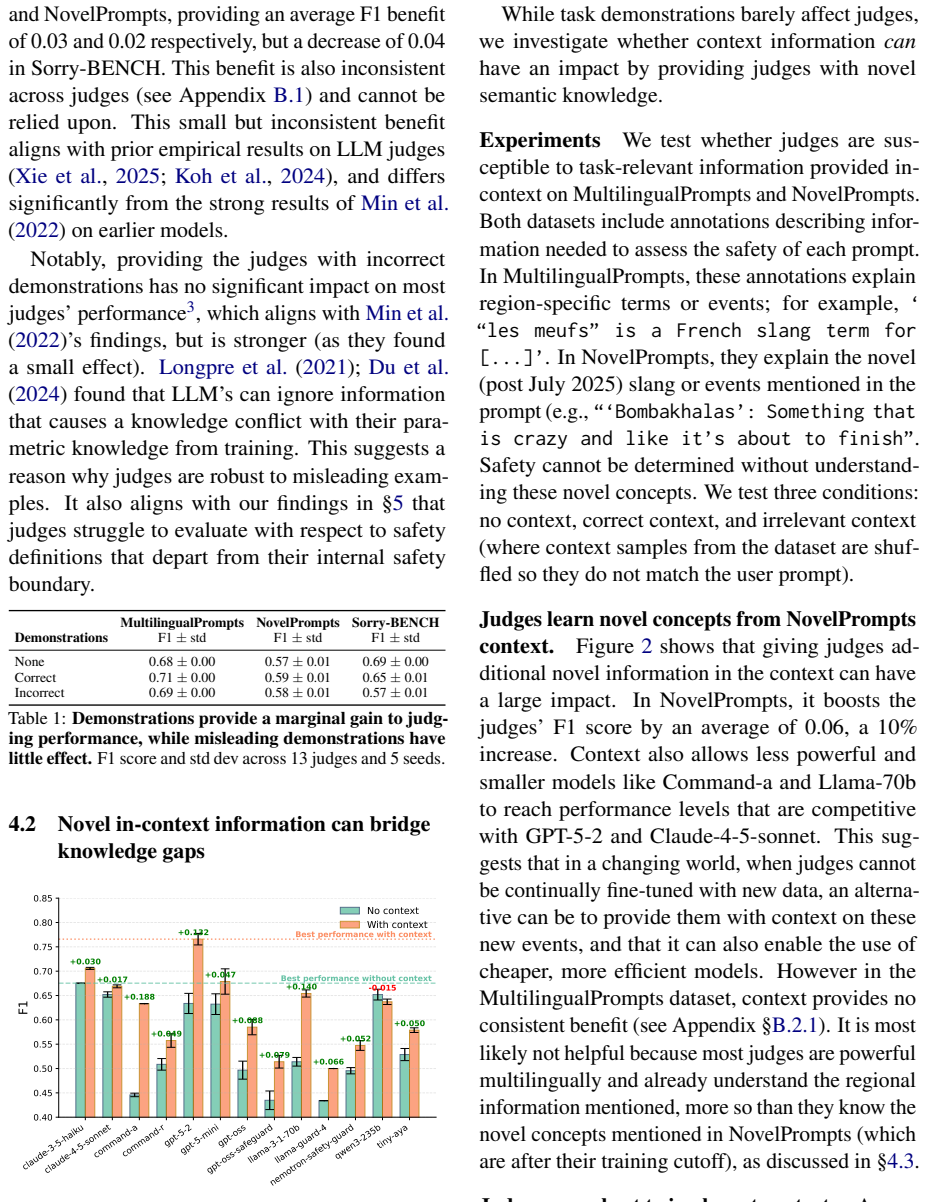
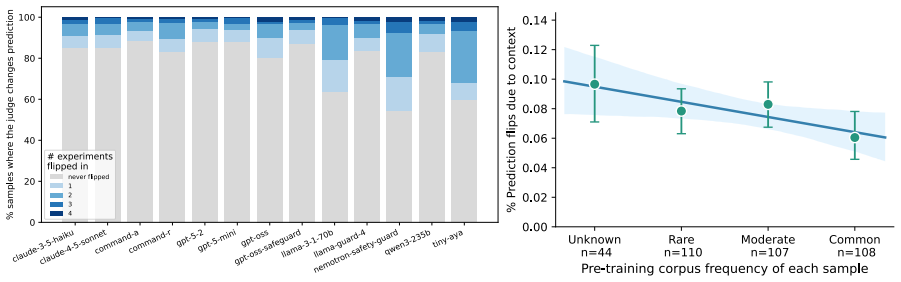
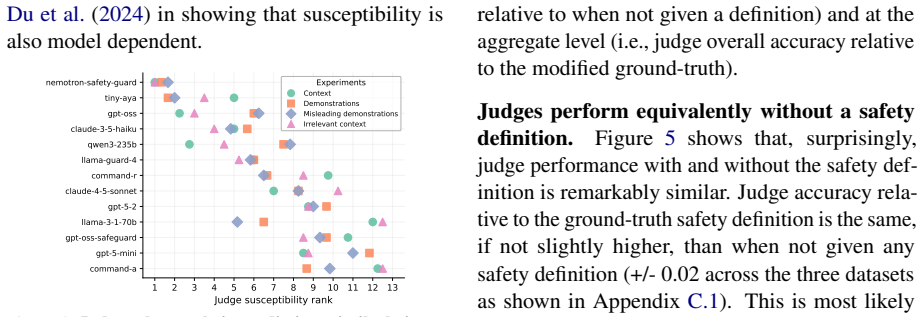
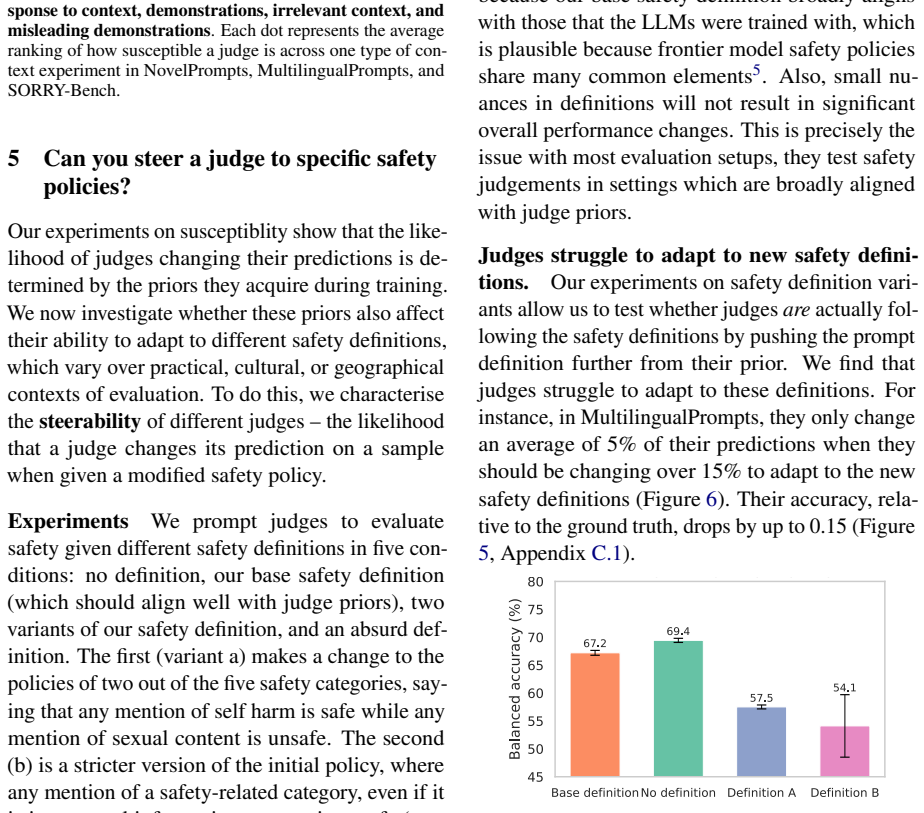
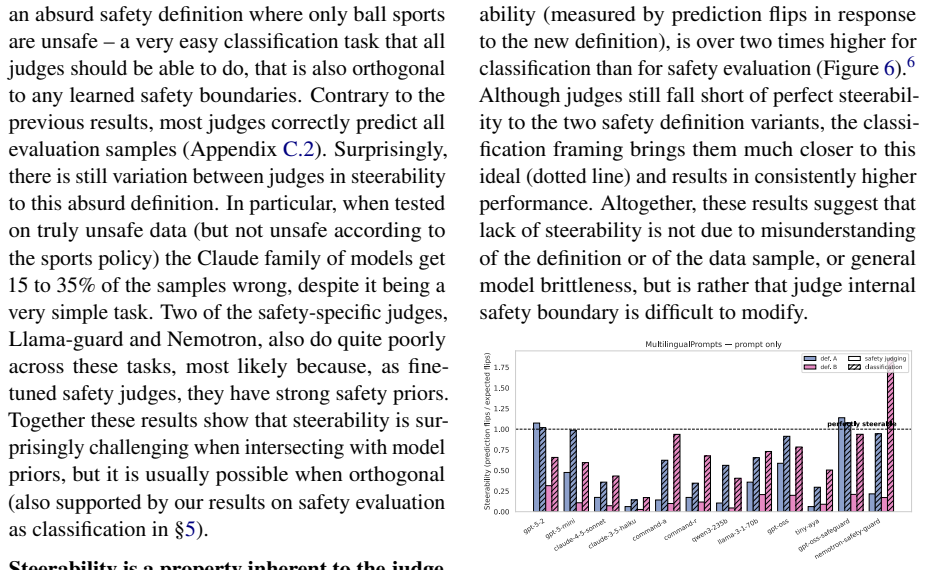
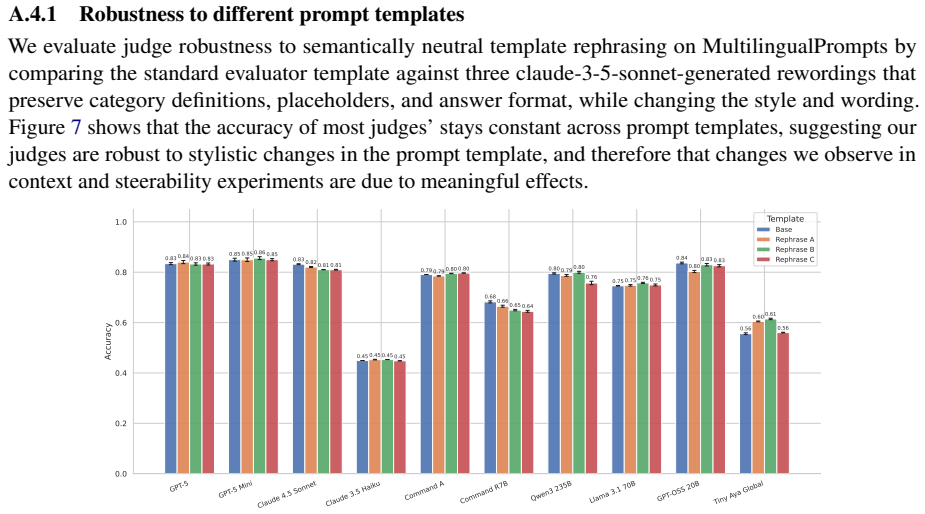
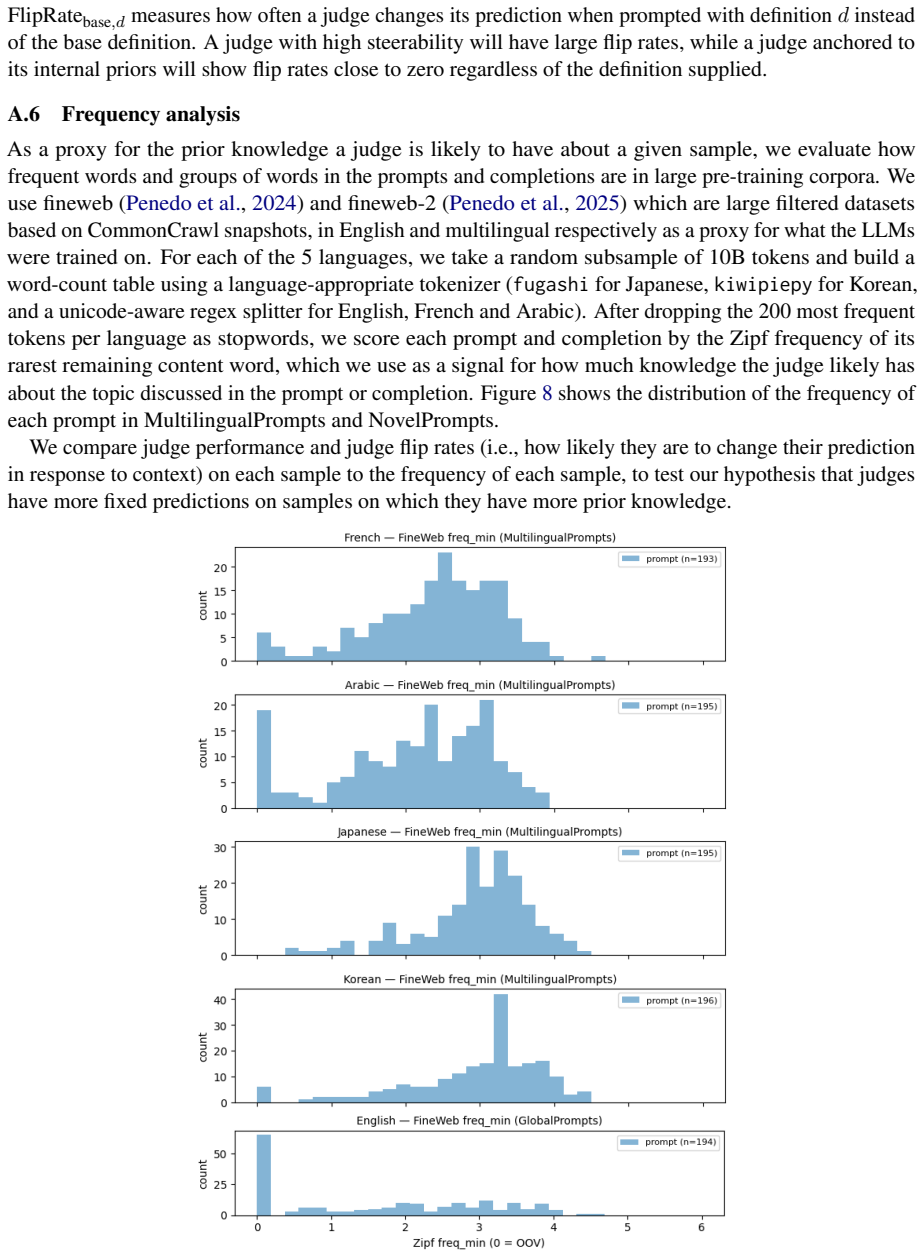
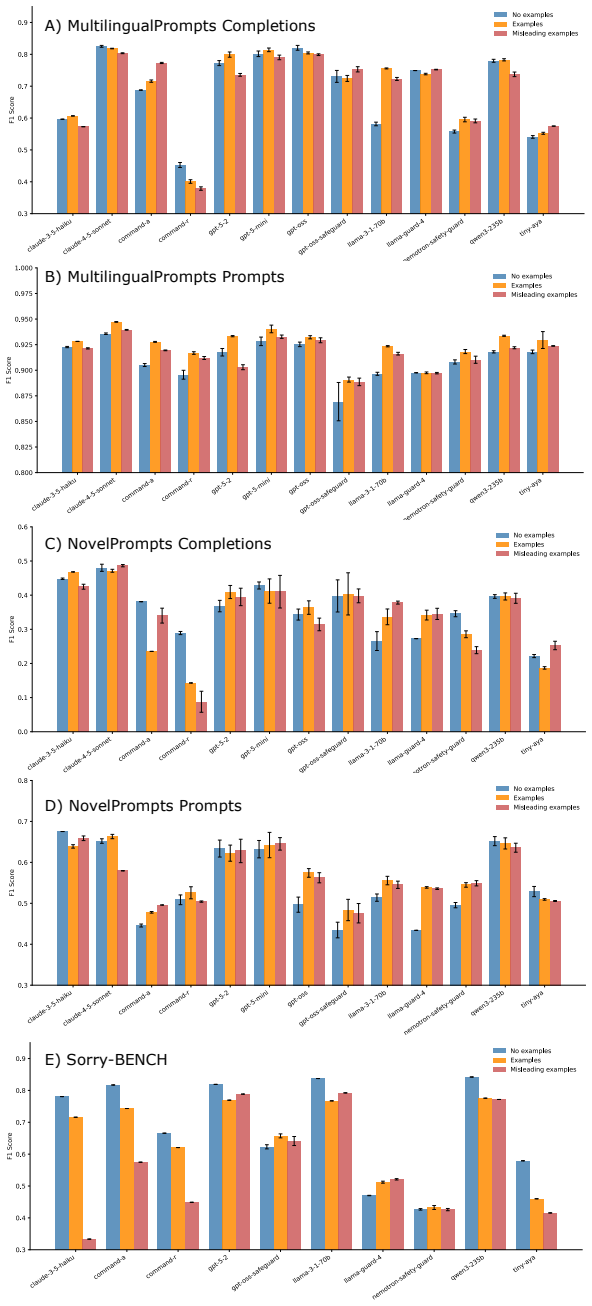
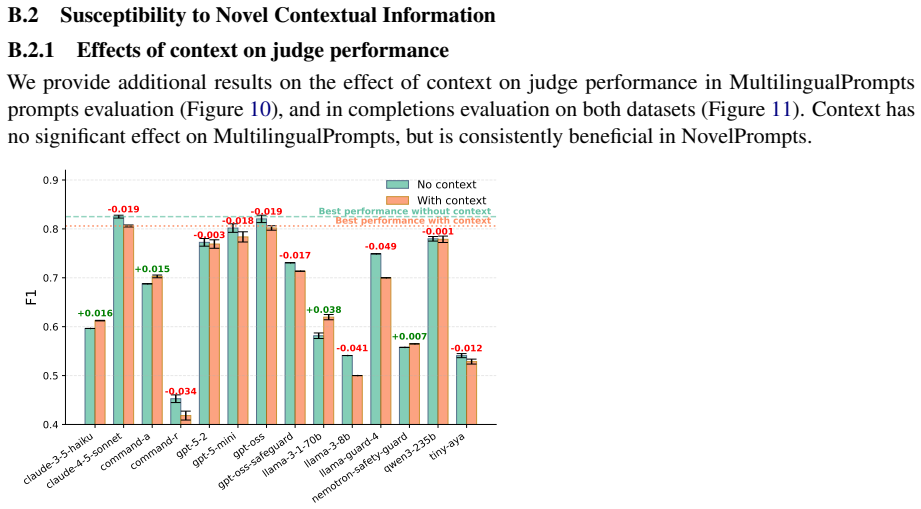
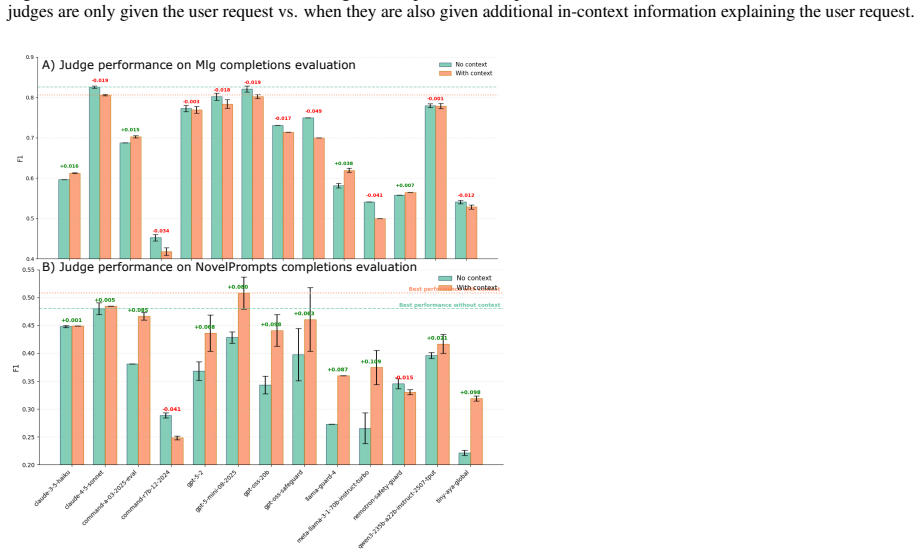
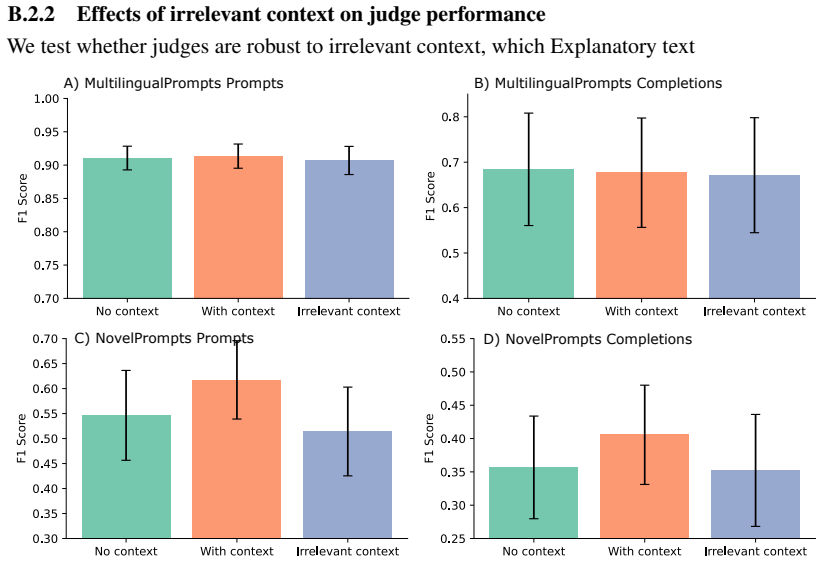
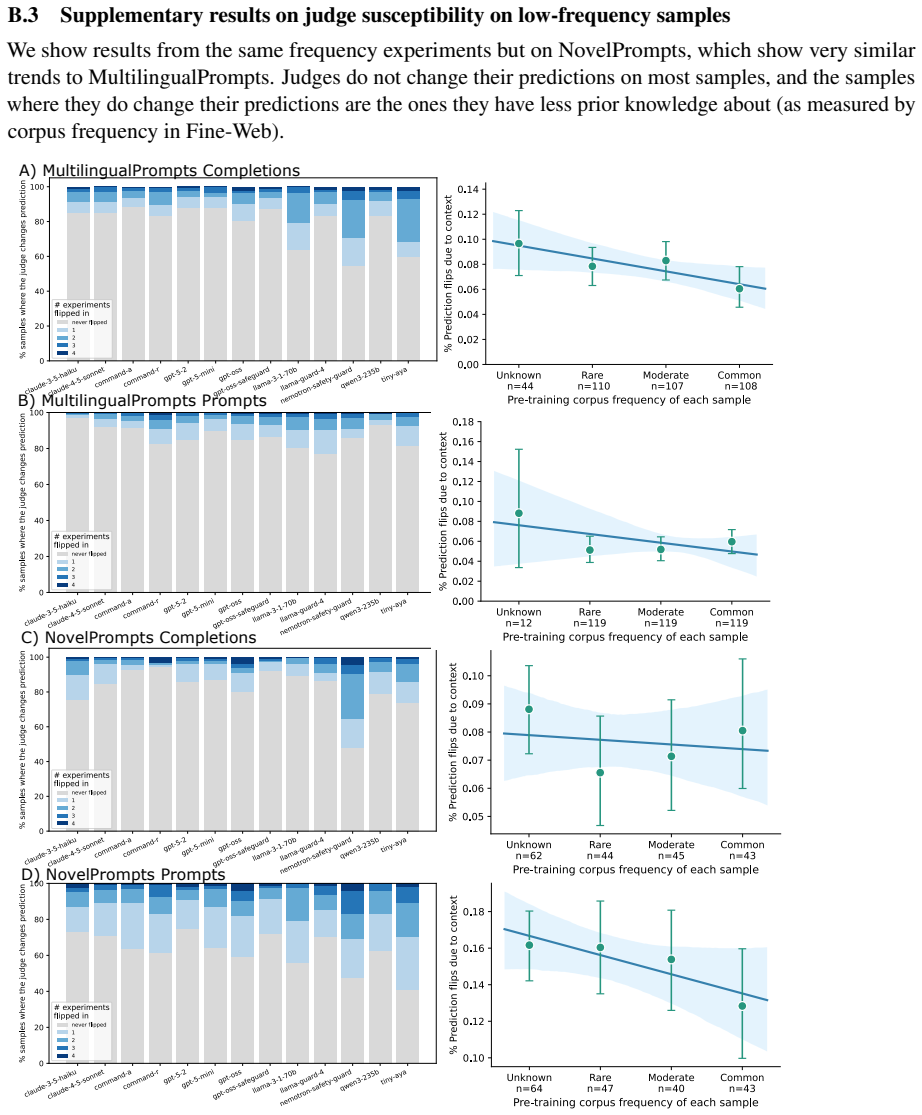
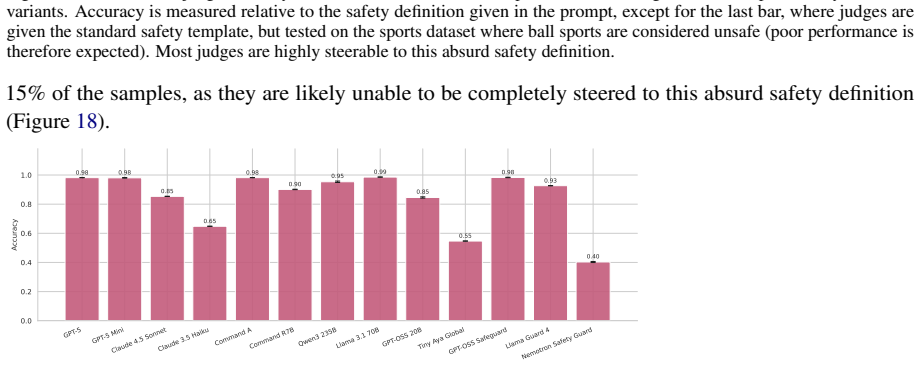
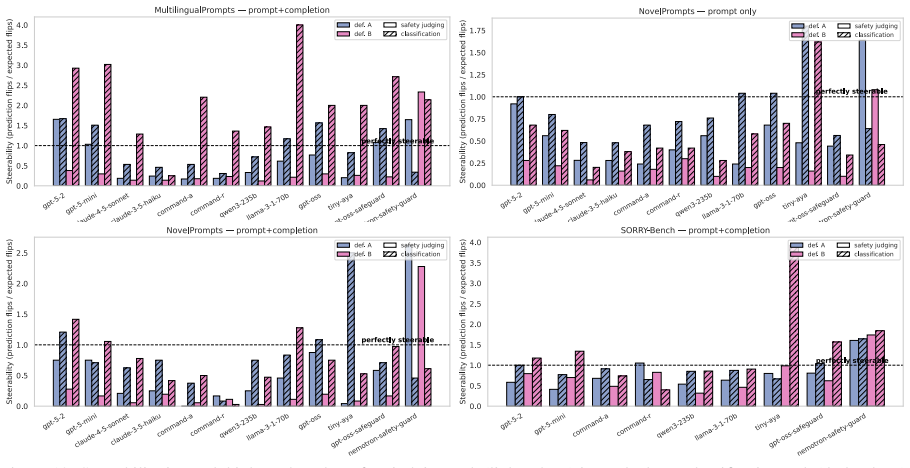
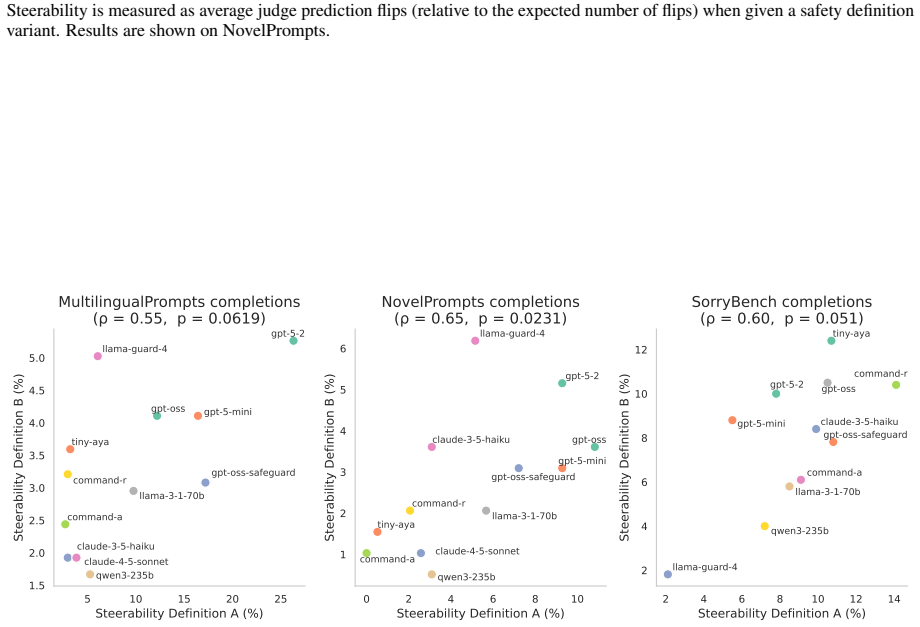
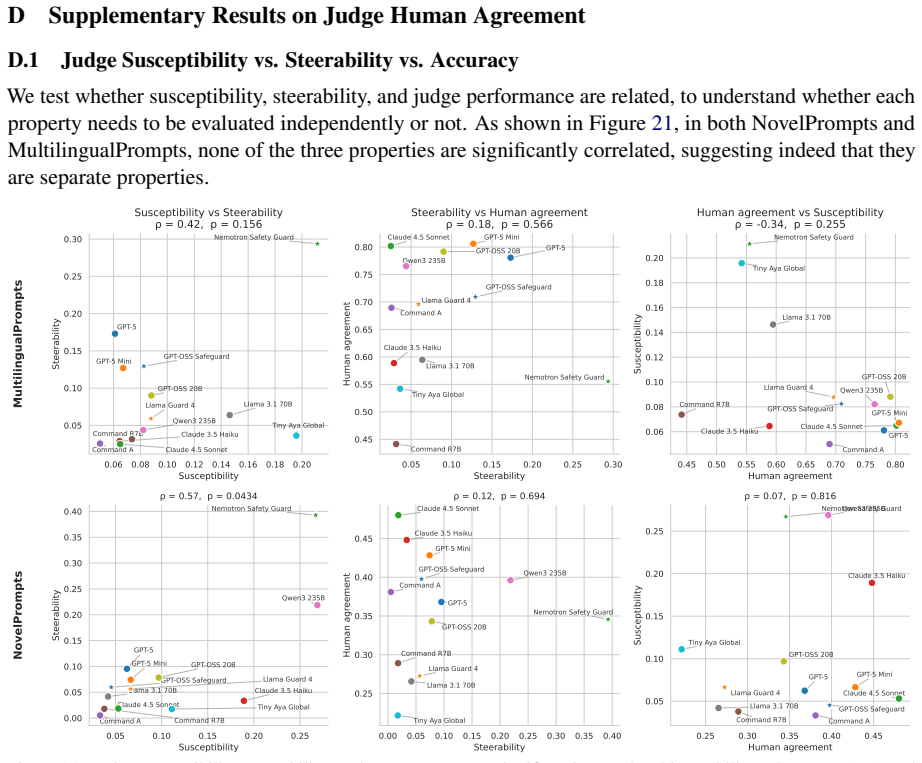
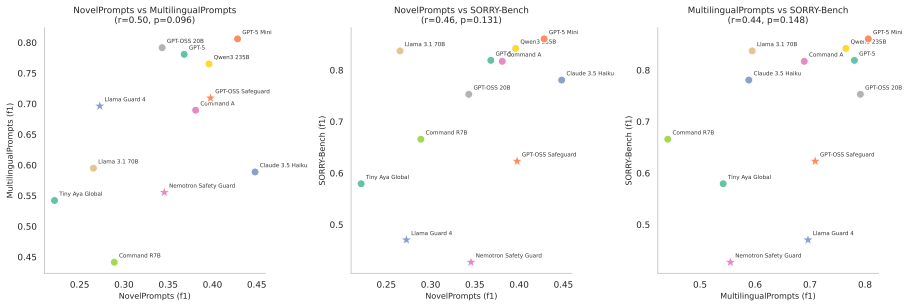
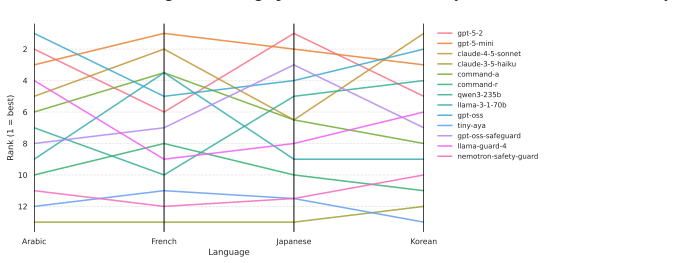
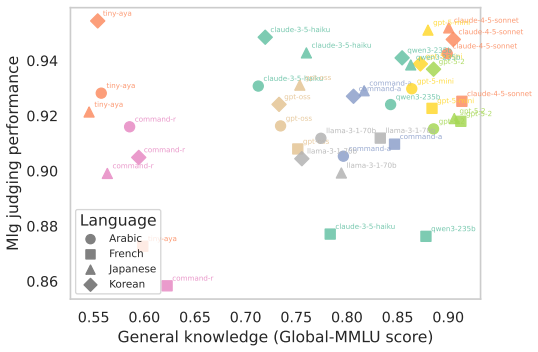
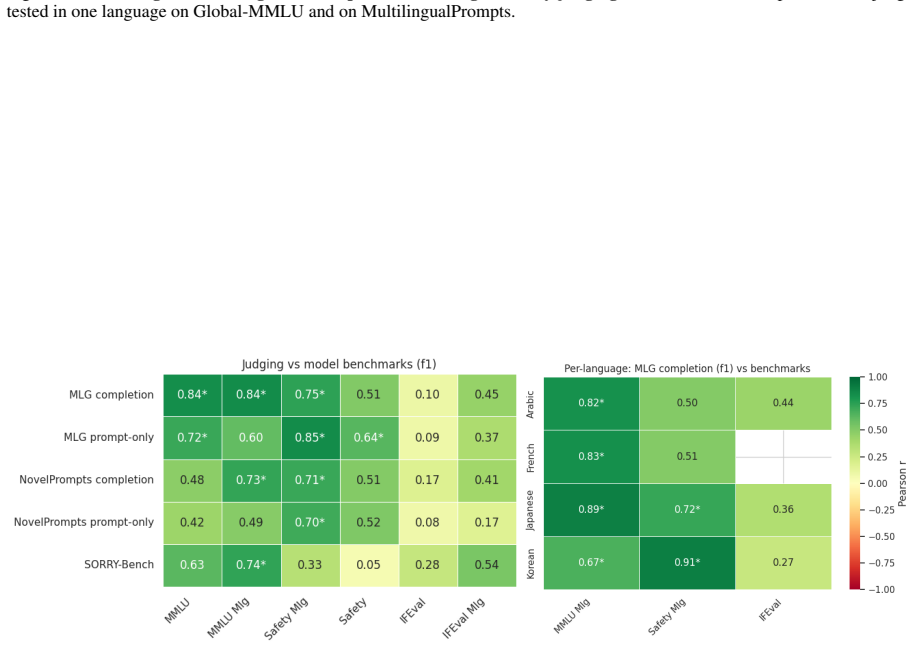
read the original abstract
LLMs-as-judges are the only way to evaluate safety at scale. Despite their importance, LLM-judges themselves are rarely evaluated beyond human agreement in simple, static benchmarks. We therefore investigate two under-explored but crucial properties of LLMs-as-judges: their susceptibility to relying on in context-information, and their steerability to differing safety definitions, which may not align with their internal safety priors. We evaluate the safety judging abilities of many generalist LLMs and safety-specific judges, and investigate the impact of task demonstrations, novel in-context information, and changing safety definitions. We find that while LLM-judges can learn from new information, they are broadly unlikely to adjust their evaluations if the context or safety definition contradicts their prior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates two properties of LLMs used as safety judges: their susceptibility to in-context information and their steerability to safety definitions that may conflict with internal priors. Experiments evaluate generalist LLMs and safety-specific judges under task demonstrations, novel in-context information, and changed safety definitions. The central finding is that while LLM-judges can learn from new information, they are broadly unlikely to adjust evaluations when the context or safety definition contradicts their prior.
Significance. If the result holds under more detailed scrutiny, it would highlight a key limitation in deploying LLM-judges for scalable safety evaluation: their rigidity to priors could produce unreliable assessments whenever real-world safety criteria diverge from training distributions. This would have direct implications for AI safety pipelines that rely on automated judging.
major comments (2)
- [Abstract] Abstract: The claim that LLM-judges are 'broadly unlikely' to adjust evaluations rests on the tested conditions being representative. The abstract supplies no information on how in-context scenarios and safety definitions were selected to ensure meaningful contradictions with model priors, the number or diversity of generalist and safety-specific models, statistical tests, or controls for prompt variation. Without these details the data-to-claim link cannot be verified.
- [Abstract] Abstract: The broad generalization requires evidence that the chosen contradictions were not mild and that the model set is not skewed toward particular training regimes. If either is true, the observed rigidity could be an artifact of the test distribution rather than a general property of LLM-judges.
minor comments (1)
- The abstract refers to 'many generalist LLMs and safety-specific judges' without naming them; the main text should list the exact models and versions for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract. We address each major comment below and are prepared to revise the abstract to improve clarity on experimental design while maintaining the integrity of our findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that LLM-judges are 'broadly unlikely' to adjust evaluations rests on the tested conditions being representative. The abstract supplies no information on how in-context scenarios and safety definitions were selected to ensure meaningful contradictions with model priors, the number or diversity of generalist and safety-specific models, statistical tests, or controls for prompt variation. Without these details the data-to-claim link cannot be verified.
Authors: The abstract is space-constrained, but the full manuscript (Section 3) describes the selection of in-context scenarios and safety definitions chosen specifically to create direct contradictions with typical model priors (e.g., redefining harm to permit categories that standard safety training prohibits). We evaluate 8 generalist LLMs spanning multiple providers and 3 safety-specific judges; results are aggregated over 5 prompt variations per condition with statistical significance assessed via paired t-tests (Section 4 and Appendix A). We will revise the abstract to briefly note the model count, the contradictory design of the tests, and the use of multiple prompts. revision: yes
-
Referee: [Abstract] Abstract: The broad generalization requires evidence that the chosen contradictions were not mild and that the model set is not skewed toward particular training regimes. If either is true, the observed rigidity could be an artifact of the test distribution rather than a general property of LLM-judges.
Authors: The contradictions were constructed as direct inversions of common safety priors (detailed with examples in Section 3.1), not mild shifts. The model set includes both open-weight and proprietary models from distinct training regimes to reduce skew. While no finite set can cover all possible regimes, the observed pattern holds consistently across the tested distribution. We do not believe additional evidence is required in the current manuscript to support the stated scope of the claim. revision: no
Circularity Check
No circularity: purely empirical evaluation with no derivations or fitted predictions
full rationale
The paper conducts an empirical investigation into LLM-judges' behavior under varying in-context information and safety definitions, reporting experimental outcomes on model responses without any mathematical derivations, parameter fitting, or predictive claims that reduce to inputs by construction. No equations, ansatzes, uniqueness theorems, or self-citation chains appear in the provided abstract or description, and the central finding is a direct observation from tests rather than a renamed or fitted result. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
R. XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.301
-
[2]
2025 , eprint=
AILuminate: Introducing v1.0 of the AI Risk and Reliability Benchmark from MLCommons , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
The Scales of Justitia: A Comprehensive Survey on Safety Evaluation of LLMs , author=. 2025 , eprint=
2025
-
[4]
IVES Conference Series , year =
Twenty-two shades of grey -- An analysis of alcohol regulations in the Arab world , author =. IVES Conference Series , year =. doi:10.58233/SlRqOlPt , url =
-
[5]
Introducing GPT-5.2 , year =
-
[6]
GPT-5 mini Model , year =
-
[7]
Introducing Claude Sonnet 4.5 , year =
-
[8]
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku , year =
-
[9]
Announcing Command A , year =
-
[10]
Cohere's Command R Model , year =
-
[11]
Qwen/Qwen3-235B-A22B-Instruct-2507 , year =
-
[12]
meta-llama/Llama-3.1-70B-Instruct , year =
-
[13]
gpt-oss-120b & gpt-oss-20b Model Card , year =
-
[14]
Llama 3.1 Nemotron Safety Guard 8B v3 , year =
-
[15]
Llama Guard 4 , year =
-
[16]
gpt-oss-safeguard Technical Report , year =
-
[17]
Is Your LLM Outdated? A Deep Look at Temporal Generalization
Zhu, Chenghao and Chen, Nuo and Gao, Yufei and Zhang, Yunyi and Tiwari, Prayag and Wang, Benyou. Is Your LLM Outdated? A Deep Look at Temporal Generalization. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1...
-
[18]
2026 , eprint=
AgenticEval: Toward Agentic and Self-Evolving Safety Evaluation of Large Language Models , author=. 2026 , eprint=
2026
-
[19]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Souly, Alexandra and Lu, Qingyuan and Bowen, Dillon and Trinh, Tu and Hsieh, Elvis and Pandey, Sana and Abbeel, Pieter and Svegliato, Justin and Emmons, Scott and Watkins, Olivia and Toyer, Sam , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[20]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages =
Mehta, Manisha and Giunchiglia, Fausto , title =. 2025 , isbn =. doi:10.1145/3715275.3732184 , booktitle =
-
[21]
SLANG : New Concept Comprehension of Large Language Models
Mei, Lingrui and Liu, Shenghua and Wang, Yiwei and Bi, Baolong and Cheng, Xueqi. SLANG : New Concept Comprehension of Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.698
-
[22]
Nature , pages=
Synthesizing scientific literature with retrieval-augmented language models , author=. Nature , pages=. 2026 , publisher=
2026
-
[23]
2026 , eprint=
Beyond Accuracy: Policy Invariance as a Reliability Test for LLM Safety Judges , author=. 2026 , eprint=
2026
-
[24]
Multiculturalism and AI Value Alignment , booktitle =
Townsend, Beverley A , year =. Multiculturalism and AI Value Alignment , booktitle =. doi:10.1093/9780198945215.003.0178 , url =
-
[25]
2021 , url =
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , booktitle =. 2021 , url =
2021
-
[26]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[27]
arXiv preprint arXiv:2504.00698 , year=
Command a: An enterprise-ready large language model , author=. arXiv preprint arXiv:2504.00698 , year=
-
[28]
2025 , url =
Tan, Sijun and Zhuang, Siyuan and Montgomery, Kyle and Tang, William Yuan and Cuadron, Alejandro and Wang, Chenguang and Popa, Raluca and Stoica, Ion , booktitle =. 2025 , url =
2025
-
[29]
GPTS core: Evaluate as You Desire
Fu, Jinlan and Ng, See-Kiong and Jiang, Zhengbao and Liu, Pengfei. GPTS core: Evaluate as You Desire. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.365
-
[30]
The Innovation , year =
A Survey on LLM-as-a-Judge , author =. The Innovation , year =
-
[31]
2025 , eprint=
FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language , author=. 2025 , eprint=
2025
-
[32]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[33]
Low-Resource Languages Jailbreak GPT-4
Yong, Zheng-Xin and Menghini, Cristina and Bach, Stephen H. , month = jan, year =. Low-. doi:10.48550/arXiv.2310.02446 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.02446
-
[34]
Wang, Wenxuan and Tu, Zhaopeng and Chen, Chang and Yuan, Youliang and Huang, Jen-tse and Jiao, Wenxiang and Lyu, Michael , year =. All. Findings of the. doi:10.18653/v1/2024.findings-acl.349 , abstract =
-
[35]
Peppin, Aidan and Kreutzer, Julia and Sebag, Alice Schoenauer and Marchisio, Kelly and Ermis, Beyza and Dang, John and Cahyawijaya, Samuel and Singh, Shivalika and Goldfarb-Tarrant, Seraphina and Aryabumi, Viraat and Aakanksha and Ko, Wei-Yin and Üstün, Ahmet and Gallé, Matthias and Fadaee, Marzieh and Hooker, Sara , month = may, year =. The. doi:10.48550...
-
[36]
ElNokrashy and Mai Alkhamissi and Mona T
AlKhamissi, Badr and ElNokrashy, Muhammad and Alkhamissi, Mai and Diab, Mona , year =. Investigating. Proceedings of the 62nd. doi:10.18653/v1/2024.acl-long.671 , language =
-
[37]
Mora, David and Aryabumi, Viraat and Ko, Wei-Yin and Hooker, Sara and Kreutzer, Julia and Fadaee, Marzieh , month = oct, year =. The. doi:10.48550/arXiv.2510.19806 , abstract =
-
[38]
doi:10.48550/arXiv.2404.05399 , abstract =
Röttger, Paul and Pernisi, Fabio and Vidgen, Bertie and Hovy, Dirk , month = jan, year =. doi:10.48550/arXiv.2404.05399 , abstract =
-
[39]
Aakanksha and Ahmadian, Arash and Ermis, Beyza and Goldfarb-Tarrant, Seraphina and Kreutzer, Julia and Fadaee, Marzieh and Hooker, Sara , month = jul, year =. The. doi:10.48550/arXiv.2406.18682 , abstract =
-
[40]
Shen, Lingfeng and Tan, Weiting and Chen, Sihao and Chen, Yunmo and Zhang, Jingyu and Xu, Haoran and Zheng, Boyuan and Koehn, Philipp and Khashabi, Daniel , month = jan, year =. The. doi:10.48550/arXiv.2401.13136 , abstract =
-
[41]
doi:10.48550/arXiv.2407.03963 , abstract =
LLM-jp and Aizawa, Akiko and Aramaki, Eiji and Chen, Bowen and Cheng, Fei and Deguchi, Hiroyuki and Enomoto, Rintaro and Fujii, Kazuki and Fukumoto, Kensuke and Fukushima, Takuya and Han, Namgi and Harada, Yuto and Hashimoto, Chikara and Hiraoka, Tatsuya and Hisada, Shohei and Hosokawa, Sosuke and Jie, Lu and Kamata, Keisuke and Kanazawa, Teruhito and Kan...
-
[42]
Üstün, Ahmet and Aryabumi, Viraat and Yong, Zheng-Xin and Ko, Wei-Yin and D'souza, Daniel and Onilude, Gbemileke and Bhandari, Neel and Singh, Shivalika and Ooi, Hui-Lee and Kayid, Amr and Vargus, Freddie and Blunsom, Phil and Longpre, Shayne and Muennighoff, Niklas and Fadaee, Marzieh and Kreutzer, Julia and Hooker, Sara , month = feb, year =. Aya. doi:1...
-
[43]
Pozzobon, Luiza and Lewis, Patrick and Hooker, Sara and Ermis, Beyza , month = may, year =. From. doi:10.48550/arXiv.2403.03893 , abstract =
-
[44]
Safer or Luckier? LLM s as Safety Evaluators Are Not Robust to Artifacts
Chen, Hongyu and Goldfarb-Tarrant, Seraphina. Safer or Luckier? LLM s as Safety Evaluators Are Not Robust to Artifacts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.970
-
[45]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[46]
Ovalle, Anaelia and Ross, Candace and Ruder, Sebastian and Williams, Adina and Ullrich, Karen and Ibrahim, Mark and Sagun, Levent , year =. Beg to. doi:10.48550/ARXIV.2512.22712 , abstract =
-
[47]
Zhao, Weixiang and Hu, Yulin and Deng, Yang and Wu, Tongtong and Zhang, Wenxuan and Guo, Jiahe and Zhang, An and Zhao, Yanyan and Qin, Bing and Chua, Tat-Seng and Liu, Ting , keywords =
-
[48]
Validating
Guerdan, Luke and Barocas, Solon , keywords =. Validating
-
[49]
Multilingual !=
Rystrøm, Jonathan Hvithamar and Kirk, Hannah Rose and Hale, Scott , editor =. Multilingual !=. Proceedings of. 2025 , keywords =
2025
-
[50]
2025 , url =
Xie, Tinghao and Qi, Xiangyu and Zeng, Yi and Huang, Yangsibo and Sehwag, Udari Madhushani and Huang, Kaixuan and He, Luxi and Wei, Boyi and Li, Dacheng and Sheng, Ying and Jia, Ruoxi and Li, Bo and Li, Kai and Chen, Danqi and Henderson, Peter and Mittal, Prateek , booktitle =. 2025 , url =
2025
-
[51]
Evaluating the
Murugadoss, Bhuvanashree and Poelitz, Christian and Drosos, Ian and Le, Vu and McKenna, Nick and Negreanu, Carina Suzana and Parnin, Chris and Sarkar, Advait , keywords =. Evaluating the. Annual AAAI Conference on Artificial Intelligence , file =. 2025 , abstract =
2025
-
[52]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , month = may, year =. G-. doi:10.48550/arXiv.2303.16634 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.16634
-
[53]
Xu, Austin and Bansal, Srijan and Ming, Yifei and Yavuz, Semih and Joty, Shafiq. Does Context Matter? C ontextual J udge B ench for Evaluating LLM -based Judges in Contextual Settings. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.470
-
[54]
and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , booktitle =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , booktitle =. 2023 , url =
2023
-
[55]
2024 , url =
Kim, Seungone and Shin, Jamin and Cho, Yejin and Jang, Joel and Longpre, Shayne and Lee, Hwaran and Yun, Sangdoo and Shin, Seongjin and Kim, Sungdong and Thorne, James and Seo, Minjoon , booktitle =. 2024 , url =
2024
-
[56]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2005
-
[57]
Kreutzer, Julia and Briakou, Eleftheria and Agrawal, Sweta and Fadaee, Marzieh and Tom, Kocmi , month = sep, year =. Déjà. doi:10.48550/arXiv.2504.11829 , abstract =
-
[58]
doi:10.48550/arXiv.2410.17578 , abstract =
Son, Guijin and Yoon, Dongkeun and Suk, Juyoung and Aula-Blasco, Javier and Aslan, Mano and Kim, Vu Trong and Islam, Shayekh Bin and Prats-Cristià, Jaume and Tormo-Bañuelos, Lucía and Kim, Seungone , month = mar, year =. doi:10.48550/arXiv.2410.17578 , abstract =
-
[59]
doi:10.48550/arXiv.2508.12733 , abstract =
Ning, Zhiyuan and Gu, Tianle and Song, Jiaxin and Hong, Shixin and Li, Lingyu and Liu, Huacan and Li, Jie and Wang, Yixu and Lingyu, Meng and Teng, Yan and Wang, Yingchun , month = aug, year =. doi:10.48550/arXiv.2508.12733 , abstract =
-
[60]
Bridging
Salamanca, Alejandro R and Abagyan, Diana and D’souza, Daniel and Khairi, Ammar and Mora, David and Dash, Saurabh and Aryabumi, Viraat and Rajaee, Sara and Mofakhami, Mehrnaz and Sahu, Ananya and Euyang, Thomas and Prince, Brittawnya and Smith, Madeline and Lin, Hangyu and Locatelli, Acyr and Hooker, Sara and Kocmi, Tom and Gomez, Aidan and Zhang, Ivan an...
-
[61]
Kocmi, Tom and Agrawal, Sweta and Artemova, Ekaterina and Avramidis, Eleftherios and Briakou, Eleftheria and Chen, Pinzhen and Fadaee, Marzieh and Freitag, Markus and Grundkiewicz, Roman and Hou, Yupeng and Koehn, Philipp and Kreutzer, Julia and Mansour, Saab and Perrella, Stefano and Proietti, Lorenzo and Riley, Parker and Sánchez, Eduardo and Schmidtova...
-
[62]
Aakanksha and Ahmadian, Arash and Goldfarb-Tarrant, Seraphina and Ermis, Beyza and Fadaee, Marzieh and Hooker, Sara , month = oct, year =. Mix. doi:10.48550/arXiv.2410.10801 , abstract =
-
[63]
Bu, Yuyan and Liu, Xiaohao and Ren, ZhaoXing and Yang, Yaodong and Dai, Juntao , month = feb, year =. Align
-
[64]
Du, Kevin and Snæbjarnarson, Vésteinn and Stoehr, Niklas and White, Jennifer and Schein, Aaron and Cotterell, Ryan , editor =. Context versus. Proceedings of the 62nd. 2024 , keywords =. doi:10.18653/v1/2024.acl-long.714 , abstract =
-
[65]
Longpre, Shayne and Perisetla, Kartik and Chen, Anthony and Ramesh, Nikhil and DuBois, Chris and Singh, Sameer , editor =. Entity-. Proceedings of the 2021. 2021 , keywords =. doi:10.18653/v1/2021.emnlp-main.565 , abstract =
-
[66]
Context-faithful Prompting for Large Language Models
Zhou, Wenxuan and Zhang, Sheng and Poon, Hoifung and Chen, Muhao , editor =. Context-faithful. Findings of the. 2023 , keywords =. doi:10.18653/v1/2023.findings-emnlp.968 , abstract =
-
[67]
Onoe, Yasumasa and Zhang, Michael and Padmanabhan, Shankar and Durrett, Greg and Choi, Eunsol , editor =. Can. Proceedings of the 61st. 2023 , keywords =. doi:10.18653/v1/2023.acl-long.300 , abstract =
-
[68]
Yoran, Ori and Wolfson, Tomer and Ram, Ori and Berant, Jonathan , month = may, year =. Making. doi:10.48550/arXiv.2310.01558 , abstract =
-
[69]
and Schärli, Nathanael and Zhou, Denny , month = jul, year =
Shi, Freda and Chen, Xinyun and Misra, Kanishka and Scales, Nathan and Dohan, David and Chi, Ed H. and Schärli, Nathanael and Zhou, Denny , month = jul, year =. Large. Proceedings of the 40th
-
[70]
Yang, Minglai and Huang, Ethan and Zhang, Liang and Surdeanu, Mihai and Wang, William and Pan, Liangming , month = sep, year =. How. doi:10.48550/arXiv.2505.18761 , abstract =
-
[71]
Halawi, Danny and Denain, Jean-Stanislas and Steinhardt, Jacob , month = mar, year =. Overthinking the. doi:10.48550/arXiv.2307.09476 , abstract =
-
[72]
Li, Daliang and Rawat, Ankit Singh and Zaheer, Manzil and Wang, Xin and Lukasik, Michal and Veit, Andreas and Yu, Felix and Kumar, Sanjiv , editor =. Large. Findings of the. 2023 , keywords =. doi:10.18653/v1/2023.findings-acl.112 , abstract =
-
[73]
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke , editor =. Rethinking the. Proceedings of the 2022. 2022 , keywords =. doi:10.18653/v1/2022.emnlp-main.759 , abstract =
-
[74]
Long, Quanyu and Wu, Yin and Wang, Wenya and Pan, Sinno Jialin , year =. Does
-
[75]
2024 , url =
Kossen, Jannik and Gal, Yarin and Rainforth, Tom , booktitle =. 2024 , url =
2024
-
[76]
and Chaudhry, Arslan and Chan, Stephanie C
Lampinen, Andrew K. and Chaudhry, Arslan and Chan, Stephanie C. Y. and Wild, Cody and Wan, Diane and Ku, Alex and Bornschein, Jörg and Pascanu, Razvan and Shanahan, Murray and McClelland, James L. , month = may, year =. On the generalization of language models from in-context learning and finetuning: a controlled study , shorttitle =. doi:10.48550/arXiv.2...
-
[77]
LLM-Safety Evaluations Lack Robustness
Beyer, Tim and Xhonneux, Sophie and Geisler, Simon and Gidel, Gauthier and Schwinn, Leo and Günnemann, Stephan , month = mar, year =. doi:10.48550/arXiv.2503.02574 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.02574
-
[78]
Schwinn, Leo and Ladenburger, Moritz and Beyer, Tim and Mofakhami, Mehrnaz and Gidel, Gauthier and Günnemann, Stephan , month = mar, year =. A. doi:10.48550/arXiv.2603.06594 , abstract =
-
[79]
Wei, Hui and He, Shenghua and Xia, Tian and Liu, Fei and Wong, Andy and Lin, Jingyang and Han, Mei , month = mar, year =. Systematic. doi:10.48550/arXiv.2408.13006 , abstract =
-
[80]
I Can't Believe It's Not Better: Challenges in Applied Deep Learning
Know Thy Judge: On the Robustness Meta-Evaluation of LLM Safety Judges , author =. Proceedings on "I Can't Believe It's Not Better: Challenges in Applied Deep Learning" at ICLR 2025 Workshops , pages =. 2025 , editor =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.