PHAST-Net: Attention-Guided, Physics-Informed Network for Unified Estimation of Ideal Time-Frequency Representations
Pith reviewed 2026-06-26 06:33 UTC · model grok-4.3
The pith
PHAST-Net learns a mapping from a selected constellation of wavelet transforms to high-resolution ideal time-frequency representations using attention and a physics-informed reprojection loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
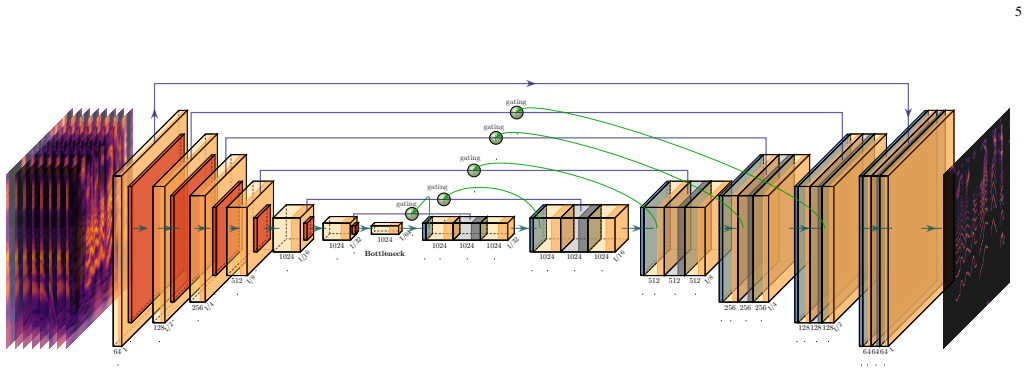
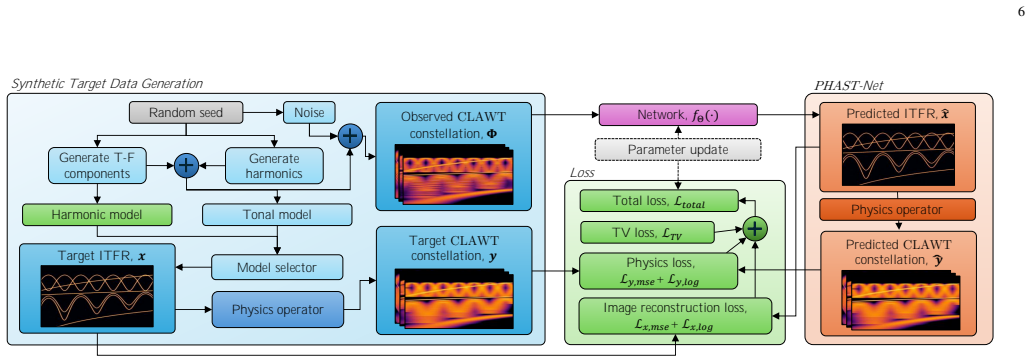
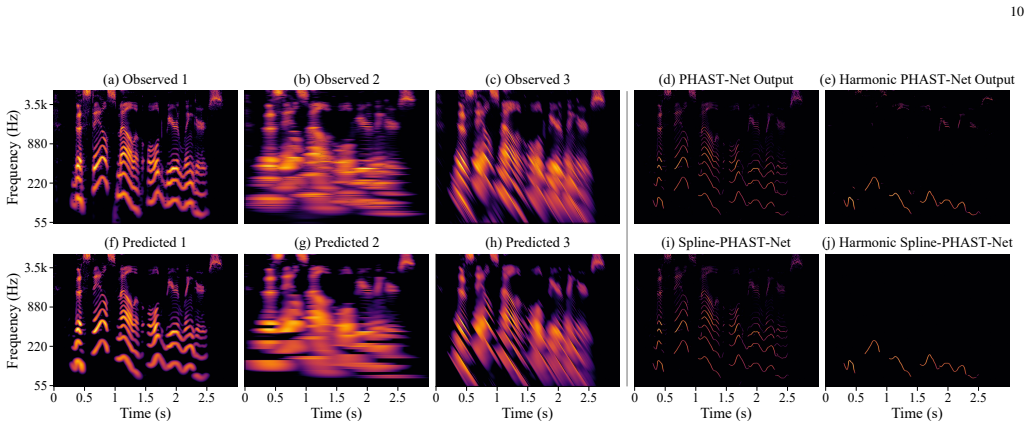
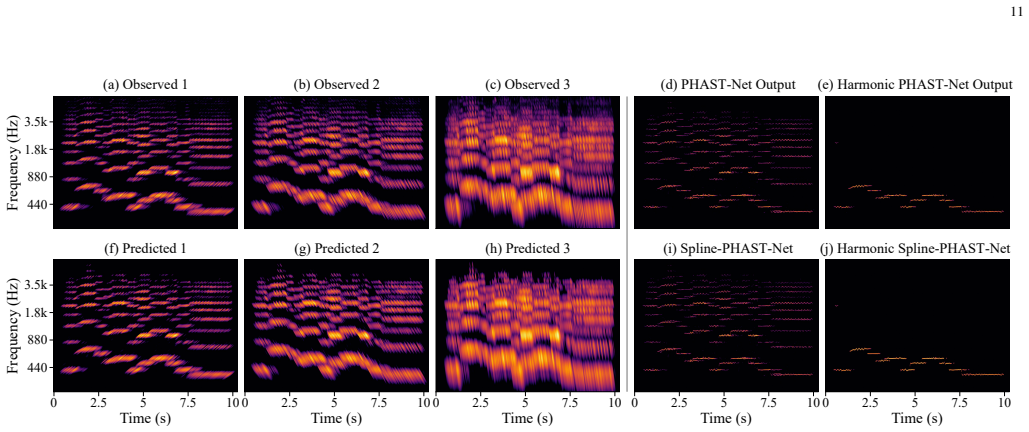
PHAST-Net estimates ITFRs by learning an application-general mapping from the proposed CLAWT constellation to high-resolution, cross-term-suppressed representations; the mapping is guided by attention layers and regularized by a physics-informed auxiliary reprojection loss that reconstructs the observed CLAWTs from the predicted ITFR and the corresponding Cohen's class kernels. The log-frequency formulation supports a Harmonic variant that isolates fundamental structure, while a Spline variant parameterizes detected ridges as continuous trajectories. Trained on an unbounded procedural dataset, the approach yields improved accuracy over established methods for unified analysis of speech, musi
What carries the argument
The physics-informed auxiliary reprojection loss that reconstructs the input CLAWT constellation from the predicted ITFR using the corresponding Cohen's class kernels, combined with attention layers for cross-term suppression.
If this is right
- A single trained network supplies spectral, tempo, metrical, and harmonic representations without separate estimators for each.
- The harmonic variant isolates fundamental structure and supports derived fundamental tempograms and metrograms.
- The spline variant converts detected ridges into continuous trajectories that support arbitrary-grid re-rendering and signal reconstruction.
- The reprojection loss reduces target sparsity effects and improves training stability while preserving energy conservation.
Where Pith is reading between the lines
- The log-frequency formulation might transfer to other harmonic-rich signals such as certain biomedical or mechanical recordings if the curvature-coverage selection still applies.
- The unified mapping could reduce the need for hand-tuned kernel parameters in conventional Cohen's class methods when the network is retrained on domain-specific data.
- If the reprojection loss proves robust, similar consistency objectives might be added to other physics-informed networks that map between related signal representations.
Load-bearing premise
The procedurally generated dataset and the CLAWT constellation selected by Cohen's class analysis produce inputs and targets that generalize to real nonstationary signals without introducing biases from the synthetic generation process.
What would settle it
Evaluating PHAST-Net accuracy on a large collection of real recorded speech and music signals against both traditional TFR methods and the reported synthetic-test performance would show whether the claimed improvements persist outside the procedural data.
Figures
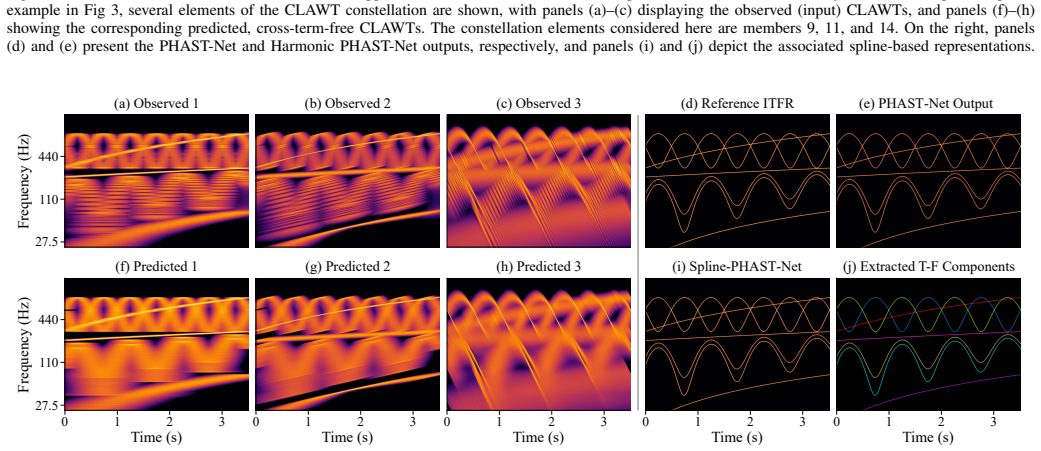
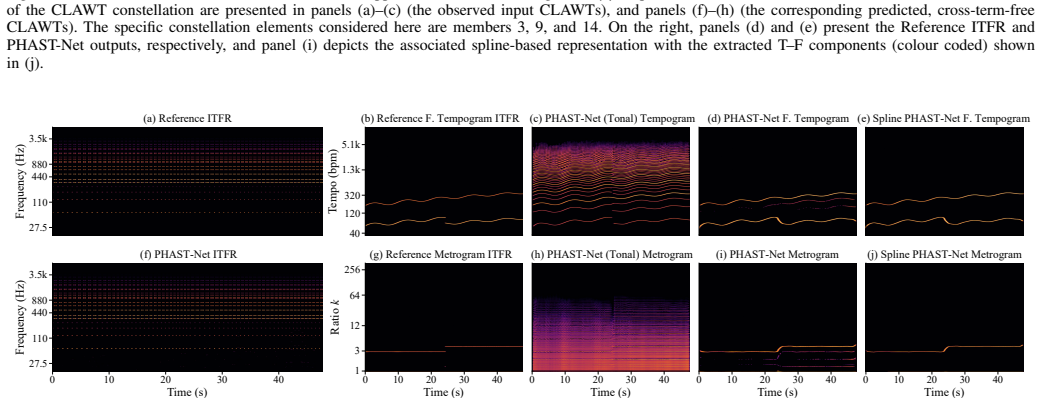
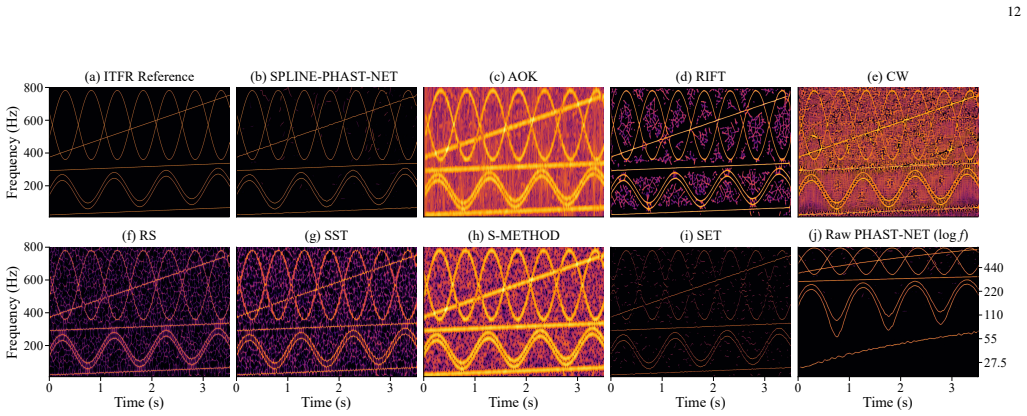
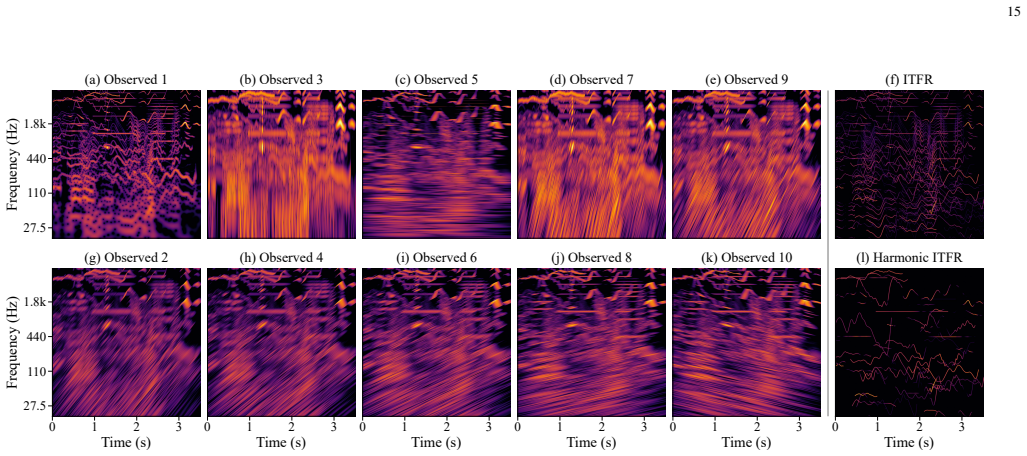
read the original abstract
We introduce PHAST-Net, an attention-guided, physics-informed network for unified estimation of Ideal Time-Frequency Representations (ITFRs), spanning spectral, tempo-based, metrical, and harmonic representations such as Spectrograms, Tempograms, and Metrograms. PHAST-Net learns an application-general mapping from a constellation of wavelet transforms, the proposed Continuous Log-frequency Adaptive Wavelet Transform (CLAWT), to high-resolution, cross-term-suppressed time-frequency (T-F) representations. The proposed constellation of CLAWTs is selected through Cohen's class kernel analysis to maximise curvature coverage in a logarithmic-frequency T-F plane tailored to harmonic signal structure. PHAST-Net further incorporates a proposed physics-informed auxiliary reprojection loss designed to reconstruct the idealised observed CLAWT constellation from the predicted ITFR and the corresponding Cohen's class kernels during training. This auxiliary objective promotes transform consistency and energy conservation, mitigates pathological target sparsity, and enhances optimisation stability. Attention layers further promote effective cross-term suppression across the input constellation. The log-frequency formulation also enables Harmonic PHAST-Net, which estimates a Harmonic ITFR that isolates fundamental structure, supporting robust fundamental-only representations for speech and music, such as derived fundamental Tempograms and Metrograms. We further introduce Spline-PHAST-Net, which parameterises detected and associated T-F ridges as continuous spline trajectories, enabling arbitrary-grid re-rendering and signal reconstruction. Trained on an effectively unbounded procedurally generated dataset, PHAST-Net demonstrates improved accuracy over established approaches, providing a unified framework for high-resolution, cross-term-robust analysis of speech, music, and broader nonstationary signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PHAST-Net, an attention-guided physics-informed neural network that maps a Cohen's-class-selected constellation of Continuous Log-frequency Adaptive Wavelet Transforms (CLAWTs) to high-resolution, cross-term-suppressed Ideal Time-Frequency Representations (ITFRs) including spectrograms, tempograms, and metrograms. It incorporates an auxiliary reprojection loss to enforce consistency between the predicted ITFR and the input CLAWTs via the corresponding kernels, uses attention for cross-term suppression, and introduces variants such as Harmonic PHAST-Net and Spline-PHAST-Net. The network is trained exclusively on an unbounded procedurally generated dataset and is claimed to outperform established approaches for speech, music, and nonstationary signals.
Significance. If the central claims hold after proper validation, the work could provide a unified, high-resolution framework for T-F analysis of harmonic signals with built-in cross-term robustness and energy conservation, potentially useful for downstream tasks in audio processing. The physics-informed reprojection loss and log-frequency formulation are conceptually attractive strengths, but their practical impact cannot be assessed without quantitative evidence.
major comments (3)
- [Abstract] Abstract: the central claim of 'improved accuracy over established approaches' is stated without any quantitative metrics, baselines, error bars, statistical tests, or dataset details; this absence makes the claim impossible to evaluate and is load-bearing for the paper's contribution.
- [Abstract] Abstract: training occurs exclusively on procedurally generated data whose statistics are controlled by the synthetic prior, yet no experiments, ablation, or discussion address generalization to real recordings (e.g., natural speech or music with differing modulation, noise, or harmonic statistics); this is the load-bearing assumption for applicability claims.
- [Abstract] Abstract: the reprojection loss is described as promoting 'transform consistency and energy conservation,' but no equations are supplied showing whether the loss is independent of the network parameters or reduces to a self-referential term that could be satisfied by construction; this risks circularity in the optimization objective.
minor comments (1)
- [Abstract] The abstract introduces several new terms (CLAWT, ITFRs, Harmonic PHAST-Net, Spline-PHAST-Net) without a concise definition or reference to their first appearance in the main text.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments on the manuscript. We address each major comment point-by-point below, indicating planned revisions to improve clarity and evaluability without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'improved accuracy over established approaches' is stated without any quantitative metrics, baselines, error bars, statistical tests, or dataset details; this absence makes the claim impossible to evaluate and is load-bearing for the paper's contribution.
Authors: The abstract is a high-level summary; the full manuscript provides quantitative comparisons against baselines (including error bars and statistical tests) along with dataset details in the Experiments section. To address the concern directly in the abstract, we will revise it to include key performance metrics and a brief description of the evaluation setup. revision: yes
-
Referee: [Abstract] Abstract: training occurs exclusively on procedurally generated data whose statistics are controlled by the synthetic prior, yet no experiments, ablation, or discussion address generalization to real recordings (e.g., natural speech or music with differing modulation, noise, or harmonic statistics); this is the load-bearing assumption for applicability claims.
Authors: The manuscript prioritizes the unbounded procedural dataset to enable controlled and comprehensive training. We will add a discussion subsection addressing the design choices in the synthetic prior intended to support generalization and note limitations regarding direct validation on real recordings as an area for future work. revision: partial
-
Referee: [Abstract] Abstract: the reprojection loss is described as promoting 'transform consistency and energy conservation,' but no equations are supplied showing whether the loss is independent of the network parameters or reduces to a self-referential term that could be satisfied by construction; this risks circularity in the optimization objective.
Authors: The full manuscript supplies the mathematical definition of the reprojection loss (as the discrepancy between input CLAWTs and kernel-reprojected predictions from the estimated ITFR), which is independent of network parameters and enforces consistency rather than being trivially satisfiable. We will revise the abstract to reference the loss formulation and clarify its auxiliary, non-circular nature. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents PHAST-Net as a neural network trained on procedurally generated synthetic data to map a CLAWT constellation (selected via standard Cohen's class analysis) to target ITFRs, using an auxiliary reprojection loss for consistency. No quoted equations or descriptions show any prediction reducing by construction to fitted inputs, self-definitional targets, or load-bearing self-citations. The central claims rest on empirical accuracy improvements over baselines within the described training setup, which is externally falsifiable and does not collapse to renaming or tautological reparameterization. This is the expected non-finding for a data-driven architecture paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cohen's class kernel analysis selects a CLAWT constellation that maximises curvature coverage for harmonic signals
- domain assumption The physics-informed auxiliary reprojection loss mitigates target sparsity and enhances optimisation stability
invented entities (2)
-
CLAWT (Continuous Log-frequency Adaptive Wavelet Transform)
no independent evidence
-
Ideal Time-Frequency Representations (ITFRs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dakovic, L
M. Dakovic, L. Stankovic, and T. Thayaparan,Time-Frequency Signal Analysis with Applications. Norwood, MA, USA: Artech House, 2013
2013
-
[2]
Boashash,Time-Frequency Signal Analysis and Processing: A Comprehensive Reference, 2nd ed
B. Boashash,Time-Frequency Signal Analysis and Processing: A Comprehensive Reference, 2nd ed. Academic Press, 2015
2015
-
[3]
The applied principles of EEG analysis methods in neuroscience and clinical neurology,
H. Zhang, Q. Q. Zhou, H. Chen, et al., “The applied principles of EEG analysis methods in neuroscience and clinical neurology,”Military Medical Research, vol. 10, no. 1, Art. no. 67, 2023
2023
-
[4]
Performance evaluation of time–frequency distributions for ECG signal analysis,
A. F. Hussein, S. J. Hashim, A. F. A. Aziz, et al., “Performance evaluation of time–frequency distributions for ECG signal analysis,”Journal of Medical Systems, vol. 42, no. 1, Art. no. 15, 2018
2018
-
[5]
EEG-based emotion recognition using quadratic time–frequency distribution,
R. Alazrai, R. Homoud, H. Alwanni, and M. I. Daoud, “EEG-based emotion recognition using quadratic time–frequency distribution,”Sensors, vol. 18, no. 8, Art. no. 2739, 2018
2018
-
[6]
A guide to LIGO–Virgo detector noise and extraction of transient gravitational-wave signals,
The LIGO Scientific Collaboration and the Virgo Collaboration, “A guide to LIGO–Virgo detector noise and extraction of transient gravitational-wave signals,” Classical and Quantum Gravity, vol. 37, no. 5, art. no. 055002, Feb. 2020
2020
-
[8]
Available: https://arxiv.org/abs/2501.15764
[Online]. Available: https://arxiv.org/abs/2501.15764
-
[9]
Cyclic tempogram—A mid-level tempo representation for music signals,
P. Grosche, M. M ¨uller, and F. Kurth, “Cyclic tempogram—A mid-level tempo representation for music signals,” in2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 2010, pp. 5522–5525
2010
-
[10]
Time Variable Tempo Detection and Beat Marking,
G. Peeters, “Time Variable Tempo Detection and Beat Marking,” inProc. Int. Comput. Music Conf. (ICMC), Barcelona, Spain, 2005, pp. 539–542
2005
-
[11]
Novel characterization method of impedance cardiography signals using time–frequency distributions,
J. Escriv ´a Mu ˜noz, Y . Pan, S. Ge, E. W. Jensen, and M. Vallverd ´u, “Novel characterization method of impedance cardiography signals using time–frequency distributions,”Medical and Biological Engineering and Computing, vol. 56, no. 10, pp. 1757–1770, 2018. 11 440 880 1.8k 3.5kFrequency (Hz) 0 2.5 5 7.5 10 Time (s) 440 880 1.8k 3.5kFrequency (Hz) 0 2.5...
2018
-
[12]
Recent advances in time–frequency analysis methods for machinery fault diagnosis: A review with application examples,
Z. Feng, M. Liang, and F. Chu, “Recent advances in time–frequency analysis methods for machinery fault diagnosis: A review with application examples,” Mechanical Systems and Signal Processing, vol. 38, no. 1, pp. 165–205, 2013
2013
-
[13]
Wave-Shape Function Analysis: When Cepstrum Meets Time–Frequency Analysis,
C.-Y . Lin, L. Su, and H.-T. Wu, “Wave-Shape Function Analysis: When Cepstrum Meets Time–Frequency Analysis,”J. F ourier Anal. Appl., vol. 24, no. 2, pp. 451– 505, 2018
2018
-
[14]
A signal-dependent time–frequency represen- tation: Optimal kernel design,
R. G. Baraniuk and D. L. Jones, “A signal-dependent time–frequency represen- tation: Optimal kernel design,”IEEE Transactions on Signal Processing, vol. 41, no. 4, pp. 1589–1602, 1993
1993
-
[15]
An adaptive optimal-kernel time–frequency representation,
D. L. Jones and R. G. Baraniuk, “An adaptive optimal-kernel time–frequency representation,”IEEE Transactions on Signal Processing, vol. 43, no. 10, pp. 2361– 2371, 1995
1995
-
[16]
Locally optimized adaptive directional time–frequency distributions,
M. Mohammadi, A. A. Pouyan, N. A. Khan, and V . Abolghasemi, “Locally optimized adaptive directional time–frequency distributions,”Circuits, Systems, and Signal Processing, vol. 37, no. 8, pp. 3154–3174, 2018
2018
-
[17]
Recovering realistic texture in image super-resolution by deep spatial feature transform,
X. Wang, K. Yu, C. Dong, and C. C. Loy, “Recovering realistic texture in image super-resolution by deep spatial feature transform,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, 2018, pp. 606– 615
2018
-
[18]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProc. 3rd Int. Conf. Learn. Represent. (ICLR), San Diego, CA, USA, May 7–9, 2015
2015
-
[19]
Multiscale vessel enhancement filtering,
A. F. Frangi, W. J. Niessen, K. L. Vincken, and M. A. Viergever, “Multiscale vessel enhancement filtering,” inMedical Image Computing and Computer-Assisted Intervention—MICCAI’98, W. M. Wells, A. Colchester, and S. Delp, Eds. Berlin, Heidelberg: Springer, 1998, pp. 130–137
1998
-
[20]
A robust high-resolution time–frequency representation based on the local optimization of the short-time fractional Fourier transform,
M. A. Awal, S. Ouelha, S. Dong, and B. Boashash, “A robust high-resolution time–frequency representation based on the local optimization of the short-time fractional Fourier transform,”Digital Signal Processing, vol. 70, pp. 125–144, 2017
2017
-
[21]
Calculation of a constant Q spectral transform,
J. C. Brown, “Calculation of a constant Q spectral transform,”The Journal of the Acoustical Society of America, vol. 89, no. 1, pp. 425–434, 1991
1991
-
[22]
Fundamental Frequency Estimation in Speech Signals With Variable Rate Particle Filters,
G. Zhang and S. Godsill, “Fundamental Frequency Estimation in Speech Signals With Variable Rate Particle Filters,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 24, no. 5, pp. 890–900, 2016
2016
-
[23]
A Novel Tempogram Generating Algorithm Based on Matching Pursuit,
W. Gui, Y . Sun, Y . Tao, Y . Li, L. Meng, and J. Zhang, “A Novel Tempogram Generating Algorithm Based on Matching Pursuit,”Applied Sciences, vol. 8, no. 4, Art. no. 561, 2018
2018
-
[24]
Crossterm-free time-frequency representation exploiting deep convolutional neural network,
S. Zhang, M. S. R. Pavel, and Y . D. Zhang, “Crossterm-free time-frequency representation exploiting deep convolutional neural network,”Signal Processing, vol. 192, Art. no. 108372, 2022
2022
-
[25]
WVDNet: Time-Frequency Analysis via Semi-Supervised Learning,
N. Liu, J. Wang, Y . Yang, Z. Li, and J. Gao, “WVDNet: Time-Frequency Analysis via Semi-Supervised Learning,”IEEE Signal Processing Letters, vol. 30, pp. 55– 59, 2023
2023
-
[26]
Robust Time-Frequency Reconstruction by Learning Structured Sparsity,
L. Jiang, H. Zhang, and L. Yu, “Robust Time-Frequency Reconstruction by Learning Structured Sparsity,”arXiv preprintarXiv:2004.14820, 2020
arXiv 2004
-
[27]
A Data-Driven High-Resolution Time- Frequency Distribution,
L. Jiang, H. Zhang, L. Yu, and G. Hua, “A Data-Driven High-Resolution Time- Frequency Distribution,”IEEE Signal Processing Letters, vol. 29, pp. 1512–1516, 2022
2022
-
[28]
WVD-GAN: A Wigner-Ville distribution enhancement method based on generative adversarial network,
D. Quan, F. Ren, X. Wang, M. Xing, N. Jin, and D. Zhang, “WVD-GAN: A Wigner-Ville distribution enhancement method based on generative adversarial network,”IET Radar , Sonar & Navigation, vol. 18, no. 6, pp. 849–865, 2024
2024
-
[29]
TFA-Net: A Deep Learning- Based Time-Frequency Analysis Tool,
P. Pan, Y . Zhang, Z. Deng, S. Fan, and X. Huang, “TFA-Net: A Deep Learning- Based Time-Frequency Analysis Tool,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 11, pp. 9274–9286, 2023
2023
-
[30]
Adaptive multi-scale TF-net for high-resolution time-frequency representations,
T. Chen, Q. Chen, Q. Zheng, Z. Li, Z. Zhang, L. Xie, and H. Su, “Adaptive multi-scale TF-net for high-resolution time-frequency representations,”Signal Processing, vol. 214, Art. no. 109247, 2024
2024
-
[31]
QTFN: A General End-to-End Time- Frequency Network to Reveal the Time-Varying Signatures of the Time Series,
T. Chen, Y . Jiao, L. Xie, and H. Su, “QTFN: A General End-to-End Time- Frequency Network to Reveal the Time-Varying Signatures of the Time Series,” Big Data Mining and Analytics, vol. 7, no. 3, pp. 905–919, 2024
2024
-
[32]
SparseTFNet: A Physically Informed Autoencoder for Sparse Time-Frequency Analysis of Seismic Data,
Y . Yang, Y . Lei, N. Liu, Z. Wang, J. Gao, and J. Ding, “SparseTFNet: A Physically Informed Autoencoder for Sparse Time-Frequency Analysis of Seismic Data,” 13 IEEE Transactions on Geoscience and Remote Sensing, vol. 60, Art. no. 4512812, 2022
2022
-
[33]
An automatic fast optimization of quadratic time–frequency distribution using the hybrid genetic algorithm,
M. A. Awal and B. Boashash, “An automatic fast optimization of quadratic time–frequency distribution using the hybrid genetic algorithm,”Signal Processing, vol. 131, pp. 134–142, 2017
2017
-
[34]
Reduced-interference time–frequency representations and sparse reconstruction of undersampled data,
Y . D. Zhang, M. G. Amin, and B. Himed, “Reduced-interference time–frequency representations and sparse reconstruction of undersampled data,” inProc. 21st European Signal Processing Conf. (EUSIPCO), Marrakech, Morocco, 2013, pp. 1–5
2013
-
[35]
Genc ¸ay, F
R. Genc ¸ay, F. Selc ¸uk, and B. Whitcher,An Introduction to Wavelets and Other Filtering Methods in Finance and Economics. San Diego, CA, USA: Academic Press, 2001
2001
-
[36]
A guide to wavelets for economists,
P. M. Crowley, “A guide to wavelets for economists,”Journal of Economic Surveys, vol. 21, no. 2, pp. 207–267, 2007
2007
-
[37]
Improving the readability of time–frequency and time–scale representations by the reassignment method,
F. Auger and P. Flandrin, “Improving the readability of time–frequency and time–scale representations by the reassignment method,”IEEE Transactions on Signal Processing, vol. 43, no. 5, pp. 1068–1089, 1995
1995
-
[38]
Wigner distribution function: Relation to short-term spectral estimation, smoothing, and performance in noise,
A. H. Nuttall, “Wigner distribution function: Relation to short-term spectral estimation, smoothing, and performance in noise,” Naval Underwater Systems Center, New London, CT, USA, Tech. Rep. 8225, Feb. 1988
1988
-
[39]
Deconvolution for positive time–frequency distributions,
J. W. Pitton, L. E. Atlas, and P. J. Loughlin, “Deconvolution for positive time–frequency distributions,” inProc. 27th Asilomar Conf. Signals, Systems and Computers, Pacific Grove, CA, USA, 1993, vol. 2, pp. 1450–1454
1993
-
[40]
The synchrosqueezing algorithm for time-varying spectral analysis: Robustness properties and new paleoclimate applications,
G. Thakur, E. Brevdo, N. S. Fu ˇckar, and H.-T. Wu, “The synchrosqueezing algorithm for time-varying spectral analysis: Robustness properties and new paleoclimate applications,”Signal Processing, vol. 93, no. 5, pp. 1079–1094, 2013
2013
-
[41]
Time–frequency reassignment: From principles to algorithms,
P. Flandrin, F. Auger, and E. Chassande-Mottin, “Time–frequency reassignment: From principles to algorithms,” inApplications in Time-Frequency Signal Process- ing, A. Papandreou-Suppappola, Ed. Boca Raton, FL, USA: CRC Press, 2003, pp. 179–204
2003
-
[42]
The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis,
N. E. Huang, Z. Shen, S. R. Long, M. C. Wu, H. H. Shih, Q. Zheng, N.-C. Yen, C.-C. Tung, and H. H. Liu, “The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis,”Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 454, no. 1971, pp. 903–995, 1998
1971
-
[43]
Variational mode decomposition,
K. Dragomiretskiy and D. Zosso, “Variational mode decomposition,”IEEE Trans- actions on Signal Processing, vol. 62, no. 3, pp. 531–544, 2014
2014
-
[44]
Design of an optimal piece-wise spline Wigner–Ville distribution for TFD performance evaluation and comparison,
M. Al-Sa’d, B. Boashash, and M. Gabbouj, “Design of an optimal piece-wise spline Wigner–Ville distribution for TFD performance evaluation and comparison,”IEEE Transactions on Signal Processing, vol. 69, pp. 3963–3976, 2021
2021
-
[45]
The Hilbert Transform,
F. R. Kschischang, “The Hilbert Transform,” Dept. Elect. & Comput. Eng., Univ. of Toronto, Toronto, ON, Canada, 2006. [Online]. Available: https://www.comm. utoronto.ca/∼frank/notes/
2006
-
[46]
An efficient antialiasing technique,
X. Wu, “An efficient antialiasing technique,”ACM SIGGRAPH Comput. Graph., vol. 25, no. 4, pp. 143–152, 1991
1991
-
[47]
A Tacholess Order Tracking Method Based on Inverse Short Time Fourier Transform and Singular Value De- composition for Bearing Fault Diagnosis,
L. Xu, S. Chatterton, P. Pennacchi, and C. Liu, “A Tacholess Order Tracking Method Based on Inverse Short Time Fourier Transform and Singular Value De- composition for Bearing Fault Diagnosis,”Sensors, vol. 20, no. 23, Art. no. 6924, 2020
2020
-
[48]
Eliminating har- monic noise in vibroseis data through sparsity-promoted waveform modeling,
D. Liu, X. Li, W. Wang, X. Wang, Z. Shi, and W. Chen, “Eliminating har- monic noise in vibroseis data through sparsity-promoted waveform modeling,” Geophysics, vol. 87, no. 3, pp. V183–V191, 2022
2022
-
[49]
S. Fenet, R. Badeau, and G. Richard, “Reassigned time–frequency representations of discrete time signals and application to the Constant-Q Transform,”Signal Process., vol. 132, pp. 170–176, Mar. 2017, doi: 10.1016/j.sigpro.2016.10.008
-
[50]
N. Holighaus, Z. Pr ˚uˇsa, and P. L. Søndergaard, “Reassignment and synchrosqueez- ing for general time–frequency filter banks, subsampling and processing,”Signal Process., vol. 125, pp. 1–8, Aug. 2016, doi: 10.1016/j.sigpro.2016.01.007
-
[51]
J. M. Cozens and S. J. Godsill, “Dynamic Time Signature Recognition, Tempo Inference, and Beat Tracking Through the Metrogram Transform,” IEEE Open Journal of Signal Processing, vol. 5, pp. 140–149, 2024, doi: 10.1109/OJSP.2023.3344048
-
[52]
Speech/music classification using features from spectral peaks,
M. Bhattacharjee, S. R. M. Prasanna, and P. Guha, “Speech/music classification using features from spectral peaks,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 1549–1559, 2020
2020
-
[53]
An exhaustive review of automatic music transcription techniques: Survey of music transcription techniques,
B. S. Gowrishankar and N. U. Bhajantri, “An exhaustive review of automatic music transcription techniques: Survey of music transcription techniques,” in Proc. Int. Conf. Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 2016, pp. 140–152
2016
-
[54]
Music deep learning: Deep learning methods for music signal processing—A review of the state of the art,
L. Moysis, et al., “Music deep learning: Deep learning methods for music signal processing—A review of the state of the art,”IEEE Access, vol. 11, pp. 17031– 17052, 2023
2023
-
[55]
On the quantum correction for thermodynamic equilibrium,
E. P. Wigner, “On the quantum correction for thermodynamic equilibrium,” Physical Review, vol. 40, no. 5, pp. 749–759, 1932
1932
-
[56]
Matching pursuits with time–frequency dictionaries,
S. Mallat and Z. Zhang, “Matching pursuits with time–frequency dictionaries,” IEEE Transactions on Signal Processing, vol. 41, no. 12, pp. 3397–3415, 1993
1993
-
[57]
YIN, a fundamental frequency estimator for speech and music,
A. de Cheveign ´e and H. Kawahara, “YIN, a fundamental frequency estimator for speech and music,”J. Acoust. Soc. Am., vol. 111, no. 4, pp. 1917–1930, Apr. 2002
1917
-
[58]
Th ´eorie et applications de la notion de signal analytique,
J. Ville, “Th ´eorie et applications de la notion de signal analytique,”C ˆables et Transmissions, vol. 2A, no. 1, pp. 61–74, 1948
1948
-
[59]
Mallat,A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed
S. Mallat,A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed. Amsterdam, The Netherlands: Elsevier/Academic Press, 2009
2009
-
[60]
Flandrin,Time-Frequency/Time-Scale Analysis
P. Flandrin,Time-Frequency/Time-Scale Analysis. San Diego, CA, USA: Academic Press, 1999
1999
-
[61]
Time–frequency distributions—A review,
L. Cohen, “Time–frequency distributions—A review,”Proceedings of the IEEE, vol. 77, no. 7, pp. 941–981, 1989
1989
-
[62]
Estimating and interpreting the instantaneous frequency of a signal—Part 1: Fundamentals,
B. Boashash, “Estimating and interpreting the instantaneous frequency of a signal—Part 1: Fundamentals,”Proceedings of the IEEE, vol. 80, no. 4, pp. 520– 538, 1992
1992
-
[63]
Polynomial Wigner–Ville distributions and their relationship to time-varying higher order spectra,
B. Boashash and P. O’Shea, “Polynomial Wigner–Ville distributions and their relationship to time-varying higher order spectra,”IEEE Transactions on Signal Processing, vol. 42, no. 1, pp. 216–220, 1994
1994
-
[64]
The interference structure of the Wigner distribution and related time–frequency signal representations,
F. Hlawatsch and P. Flandrin, “The interference structure of the Wigner distribution and related time–frequency signal representations,” inThe Wigner Distribu- tion—Theory and Applications in Signal Processing, W. Mecklenbr ¨auker and F. Hlawatsch, Eds. Amsterdam, The Netherlands: Elsevier, 1997, pp. 59–133
1997
-
[65]
Improved time–frequency representation of multi- component signals using exponential kernels,
J. Choi and W. J. Williams, “Improved time–frequency representation of multi- component signals using exponential kernels,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 6, pp. 862–871, 1989
1989
-
[66]
Time–frequency super-resolution with superlets,
V . V . Moca, H. B ˆarzan, A. Nagy-D ˆabˆacan, and R. C. Mures ¸an, “Time–frequency super-resolution with superlets,”Nature Communications, vol. 12, Art. no. 337, 2021
2021
-
[67]
A super-resolution spectrogram using coupled PLCA,
J. Nam, G. J. Mysore, J. Ganseman, K. Lee, and J. S. Abel, “A super-resolution spectrogram using coupled PLCA,” inProc. Interspeech, Makuhari, Japan, 2010, pp. 1696–1699
2010
-
[68]
Attention guided U- Net for accurate iris segmentation,
S. Lian, Z. Luo, Z. Zhong, X. Lin, S. Su, and S. Li, “Attention guided U- Net for accurate iris segmentation,”Journal of Visual Communication and Image Representation, vol. 56, pp. 296–304, 2018
2018
-
[69]
A method for time–frequency analysis,
L. Stankovi ´c, “A method for time–frequency analysis,”IEEE Transactions on Signal Processing, vol. 42, no. 1, pp. 225–229, 1994
1994
-
[70]
Synchroextracting transform,
G. Yu, M. Yu, and C. Xu, “Synchroextracting transform,”IEEE Trans. Ind. Electron., vol. 64, no. 10, pp. 8042–8054, 2017
2017
-
[71]
On a measure of divergence between two statistical populations defined by their probability distributions,
A. Bhattacharyya, “On a measure of divergence between two statistical populations defined by their probability distributions,”Bull. Calcutta Math. Soc., vol. 35, pp. 99–109, 1943
1943
-
[72]
Divergence measures based on the Shannon entropy,
J. Lin, “Divergence measures based on the Shannon entropy,”IEEE Trans. Inf. Theory, vol. 37, no. 1, pp. 145–151, Jan. 1991
1991
-
[73]
Prolate spheroidal wave functions, Fourier analysis and uncertainty—I,
D. Slepian and H. O. Pollak, “Prolate spheroidal wave functions, Fourier analysis and uncertainty—I,”Bell Syst. Tech. J., vol. 40, no. 1, pp. 43–63, 1961
1961
-
[74]
A measure of some time–frequency distributions concentration,
L. Stankovi ´c, “A measure of some time–frequency distributions concentration,” Signal Processing, vol. 81, no. 3, pp. 621–631, 2001
2001
-
[75]
The Hungarian method for the assignment problem,
H. W. Kuhn, “The Hungarian method for the assignment problem,”Naval Research Logistics Quarterly, vol. 2, nos. 1–2, pp. 83–97, 1955
1955
-
[76]
de Boor,A Practical Guide to Splines
C. de Boor,A Practical Guide to Splines. New York, NY , USA: Springer-Verlag, 1978. [76]IEEE Recommended Practice for Speech Quality Measurements, IEEE Std. 297- 1969, May 1969, doi: 10.1109/IEEESTD.1969.7405210. VI. BIOGRAPHY James M. Cozens(Member, IEEE) is a Ph.D. candidate in the Probabilistic Systems, Information, and Inference Group (ψ 2) at the Uni...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.