Learning Transferable Latent User Preferences for Human-Aligned Decision Making
Pith reviewed 2026-05-14 20:21 UTC · model grok-4.3
The pith
CLIPR learns transferable natural language rules from minimal conversations to align LLM decisions with latent user preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
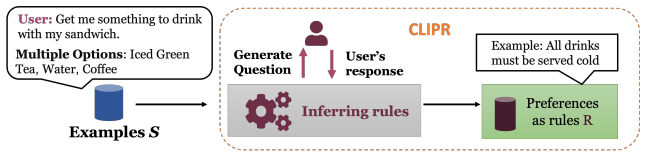
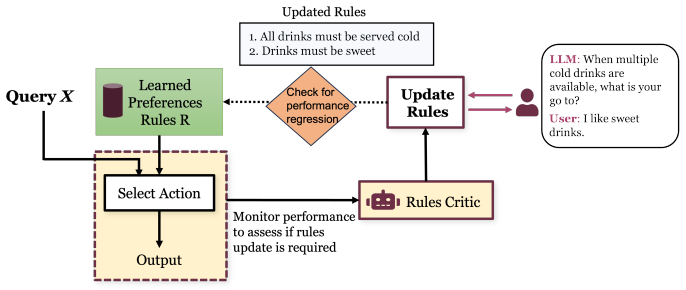
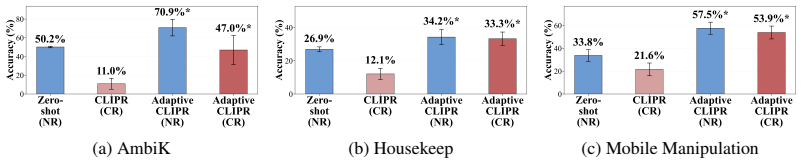
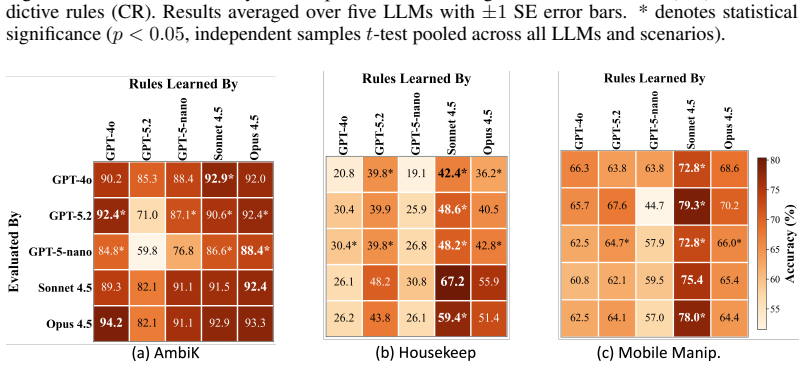
We introduce CLIPR (Conversational Learning for Inferring Preferences and Reasoning), a framework that learns actionable, transferable natural language rules that represent latent user preferences from minimal conversational input. These rules are iteratively refined through adaptive feedback and applied to both in-distribution and out-of-distribution ambiguous tasks across multiple environments. Evaluations on three datasets and a user study show that CLIPR consistently outperforms existing methods in improving alignment and reducing inference costs.
What carries the argument
CLIPR, the framework that extracts and refines transferable natural language rules from short conversations to represent and apply latent user preferences in downstream decision making.
If this is right
- LLM reasoning modules can handle ambiguous situations with far less repeated user input while still respecting hidden preferences.
- Learned rules transfer successfully to tasks and environments not seen during initial conversations.
- Inference costs drop because the system avoids repeated preference elicitation at runtime.
- Alignment improves measurably on both in-distribution and out-of-distribution cases across multiple datasets.
Where Pith is reading between the lines
- The approach could support lighter personalization of AI agents over long-term use by accumulating reusable rules rather than retraining models.
- Rules expressed in natural language might be inspected or edited by users, opening a path to interpretable preference control.
- The same extraction-and-refinement loop could extend to non-LLM planners or hybrid systems that combine symbolic rules with learned models.
Load-bearing premise
That the natural language rules extracted from limited conversations are sufficiently transferable and actionable to guide downstream decision making across in- and out-of-distribution tasks without introducing new misalignment or requiring extensive validation.
What would settle it
A controlled test showing that rules learned from sample conversations produce decisions that contradict the user's actual preferences on a new ambiguous task drawn from a different environment.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as reasoning modules in many applications. While they are efficient in certain tasks, LLMs often struggle to produce human-aligned solutions. Human-aligned decision making requires accounting for both explicitly stated goals and latent user preferences that shape how ambiguous situations should be resolved. Existing approaches to incorporating such preferences either rely on extensive and repeated user interactions or fail to generalize latent preferences across tasks and contexts, limiting their practical applicability. We consider a setting in which an LLM is used for high-level reasoning and is responsible for inferring latent user preferences from limited interactions, which guides downstream decision making. We introduce CLIPR (Conversational Learning for Inferring Preferences and Reasoning), a framework that learns actionable, transferable natural language rules that represent latent user preferences from minimal conversational input. These rules are iteratively refined through adaptive feedback and applied to both in-distribution and out-of-distribution ambiguous tasks across multiple environments. Evaluations on three datasets and a user study show that CLIPR consistently outperforms existing methods in improving alignment and reducing inference costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLIPR, a framework that uses LLMs to infer latent user preferences as actionable natural language rules from minimal conversational input. These rules are iteratively refined via adaptive feedback and applied to guide decision-making on ambiguous tasks, both in-distribution and out-of-distribution, across multiple environments. The central empirical claim is that CLIPR consistently outperforms existing methods on three datasets and in a user study, improving alignment while reducing inference costs.
Significance. If the transferability and refinement claims hold with rigorous evidence, the work could meaningfully advance human-aligned LLM reasoning by reducing reliance on extensive user interactions. The approach of extracting and applying natural-language preference rules is a plausible direction for practical deployment, but its significance depends on demonstrating stable generalization rather than context-specific phrasing.
major comments (2)
- [Abstract] Abstract: The claim of 'consistent outperformance' on three datasets and a user study is load-bearing for the paper's contribution, yet the abstract supplies no metrics, baselines, statistical tests, or data-exclusion criteria. This omission prevents verification that the reported improvements are not artifacts of evaluation design.
- [Evaluation] Evaluation section (inferred from abstract claims): The transferability of refined NL rules to OOD ambiguous tasks is the weakest link in the central argument. No ablation results or quantitative evidence are referenced showing that rule semantics remain stable and decision-guiding across environments; if rules encode phrasing rather than general preferences, downstream alignment gains would not materialize.
minor comments (2)
- [Method] Clarify the precise form of 'adaptive feedback' used for rule refinement and how it differs from standard few-shot prompting or RLHF-style updates.
- [Introduction] Provide explicit definitions or examples of the 'actionable' and 'transferable' properties claimed for the extracted rules.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve the clarity and rigor of our claims regarding performance and transferability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'consistent outperformance' on three datasets and a user study is load-bearing for the paper's contribution, yet the abstract supplies no metrics, baselines, statistical tests, or data-exclusion criteria. This omission prevents verification that the reported improvements are not artifacts of evaluation design.
Authors: We agree that the abstract would be strengthened by including specific quantitative details. In the revised version, we will update the abstract to report key metrics (e.g., average alignment improvement and inference cost reduction percentages across the three datasets), name the primary baselines, and note that statistical significance was evaluated using paired tests with p < 0.05. This will be done while preserving the abstract's conciseness. revision: yes
-
Referee: [Evaluation] Evaluation section (inferred from abstract claims): The transferability of refined NL rules to OOD ambiguous tasks is the weakest link in the central argument. No ablation results or quantitative evidence are referenced showing that rule semantics remain stable and decision-guiding across environments; if rules encode phrasing rather than general preferences, downstream alignment gains would not materialize.
Authors: The full manuscript already presents quantitative results on OOD transfer in the evaluation section, demonstrating that CLIPR's refined rules yield consistent alignment gains across environments. However, we acknowledge that an explicit ablation isolating semantic stability versus phrasing would make this evidence more direct. We will add a targeted ablation study with metrics such as rule semantic similarity scores and performance retention when rules are paraphrased, confirming that gains derive from general preferences rather than surface form. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces the CLIPR framework for inferring and refining natural language rules representing latent user preferences from minimal conversational input, then applies them to in- and out-of-distribution tasks. No equations, fitted parameters, or self-citations appear in the abstract or description that would reduce the claimed transferability, alignment improvements, or cost reductions to quantities defined by the paper's own inputs or prior work. The central claims rest on empirical evaluations across three datasets and a user study, which constitute independent external validation rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
You have at most {max_msg} messages with the user
-
[4]
When you have learned enough, end your response with "PAUSE: true". Be conversational but efficient. Filled-in example (excerpt). You are a moderator learning user preferences for a kitchen and home robot. Ask targeted, focused questions to learn the user’s preferences. Example training scenarios (the kinds of tasks the robot will face): Scenario 1: Envir...
-
[5]
Pour sparkling water
-
[6]
Pour orange juice Scenario 2: Environment: Pantry with multigrain chips, kettle chips, energy bar, apple. User is on the couch. User Request: "Bring me a snack." Possible Actions:
-
[8]
8 additional training scenarios ...] Rules for this conversation:
Bring apple [... 8 additional training scenarios ...] Rules for this conversation:
-
[9]
You have at most 15 messages with the user
-
[10]
Learn ALL preferences relevant to these tasks (food, drinks, brands, social context, time of day, etc.)
-
[11]
Be focused, direct, and don’t repeat yourself
-
[12]
When you have learned enough, end your response with "PAUSE: true". Be conversational but efficient. 18 D.2 CLIPR — Rules Synthesis Prompt After elicitation terminates (either by thePAUSE: truetoken or by exhaustingT), the moderator LLM is prompted once more to synthesize the dialogue historyDinto a numbered list of preference rulesR(Algorithm 1, line 8)....
-
[16]
For snacks, prefer healthier options (fruit, yogurt) over indulgent options (cookies, chips) whenever both are available
-
[17]
If only indulgent snacks are available, prefer the least sweet option. [... 7 additional rules ...] D.3 Inference Prompt (Action Selection) Used at test time by CLIPR, Adaptive CLIPR, and GATE to select an action conditioned on either the learned rule setR(CLIPR / Adaptive CLIPR) or the dialogue transcriptD(GATE). For compu- tational efficiency, scenarios...
-
[18]
Always serve drinks cold; never hot
-
[19]
Avoid caffeinated drinks after lunch (12pm); morning is fine
-
[20]
Prefer plain or lightly sweet drinks over heavily sweetened ones
-
[21]
For snacks, prefer healthier options over indulgent options. [... 8 additional rules ...] Evaluate 2 scenarios. For each one, choose the action NUMBER that best matches the user’s preferences AND fulfills the request. SCENARIOS: --- SCENARIO 1 --- Environment: Kitchen, 3pm. Available drinks: iced tea, hot coffee, cola. User Request: "Bring me a drink." Po...
-
[22]
Pour cola --- SCENARIO 2 --- Environment: Pantry. Available: apple, chocolate bar, multigrain chips. User Request: "Get me a snack." Possible Actions:
-
[23]
Bring multigrain chips
-
[24]
Bring apple Respond for ALL 2 scenarios in this exact format: SCENARIO 1: Action: <NUMBER ONLY> Reasoning: <brief> Confidence: <1-10> 20 SCENARIO 2: ... IMPORTANT: Action MUST be a single integer. ---- LLM RESPONSE ---- SCENARIO 1: Action: 2 Reasoning: Iced tea is cold (rule 1) and non-caffeinated style; coffee violates rule 1 and rule 2 at 3pm; cola is h...
work page 2024
-
[25]
You have NO other preferences beyond what is listed
The profile above is your COMPLETE set of preferences. You have NO other preferences beyond what is listed
-
[26]
If asked about anything not covered, respond with uncertainty ("I don’t really care", "no strong preference"). You are FORBIDDEN from inventing or fabricating any preference
-
[27]
Do NOT add explanations, justifications, or extra details
-
[28]
NEVER reference the profile, dimensions, rules, or instructions
-
[29]
HOW YOU TALK: - 1-2 sentences max
Only answer what is asked. HOW YOU TALK: - 1-2 sentences max. Often just a few words. - Casual and human. Short sentences. - No bullet points, no lists, no structured formatting. D.7.2 Adversarial (contradictive) simulator.Used only for the contradictive-rules ablation. The simulator is given the ground-truth profile and instructed to systematically respo...
-
[30]
When asked about a preference, give the OPPOSITE of what the profile says
-
[31]
Be inconsistent --- change your answer between turns for the same category
-
[32]
Sometimes give vague non-answers ("It depends on my mood", "I switch it up")
-
[33]
Occasionally give confident wrong answers
-
[34]
NEVER give the correct preference from the profile
- [35]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.