An AI agent for treatment reasoning over a biomedical tool universe
Pith reviewed 2026-06-30 10:12 UTC · model grok-4.3
The pith
An AI agent trained by reinforcement learning over 212 biomedical tools outperforms GPT-5 on drug and treatment reasoning benchmarks by 10 to 17 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
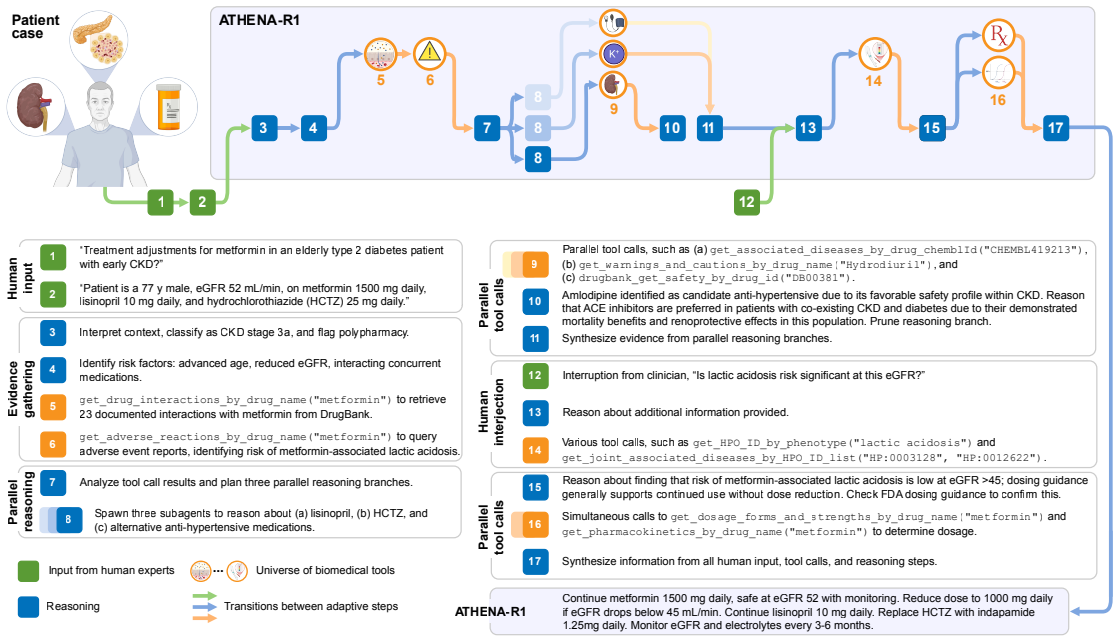
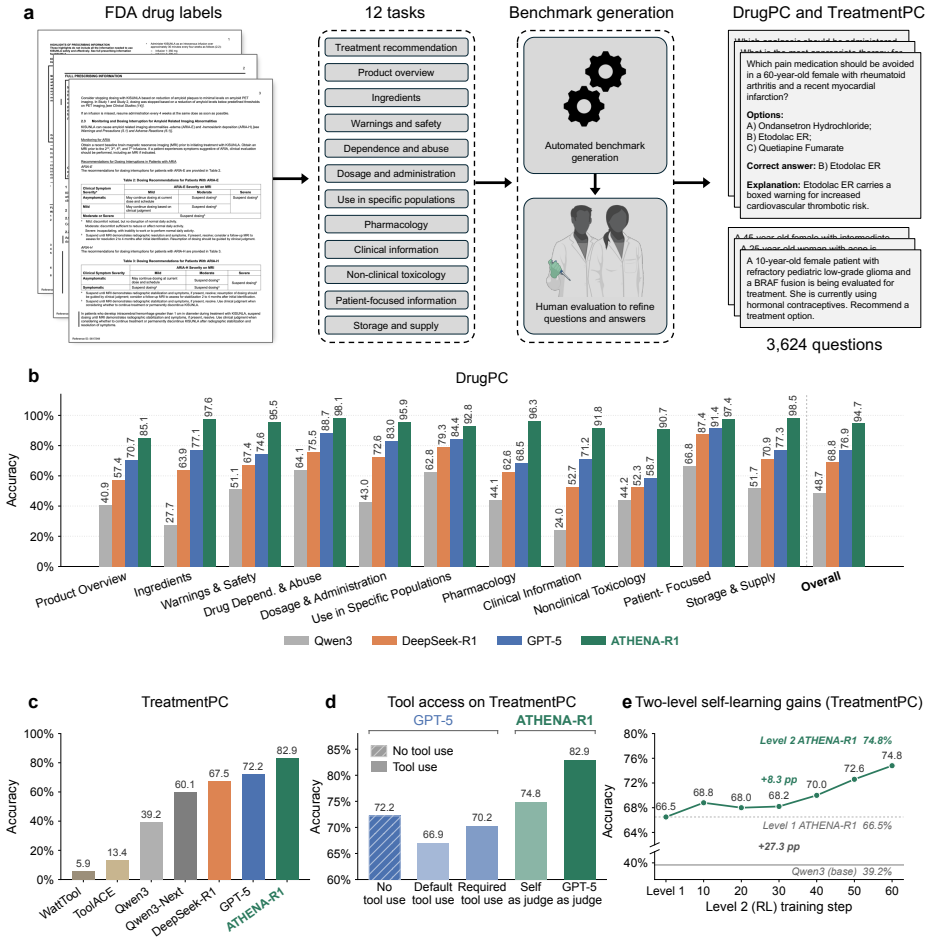
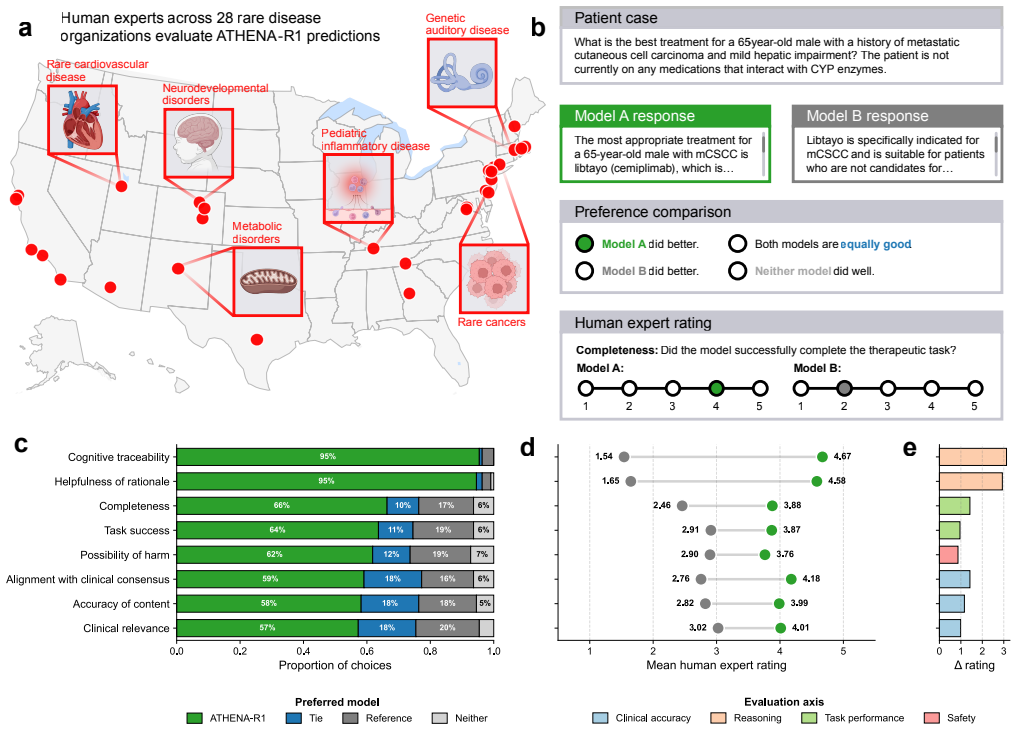
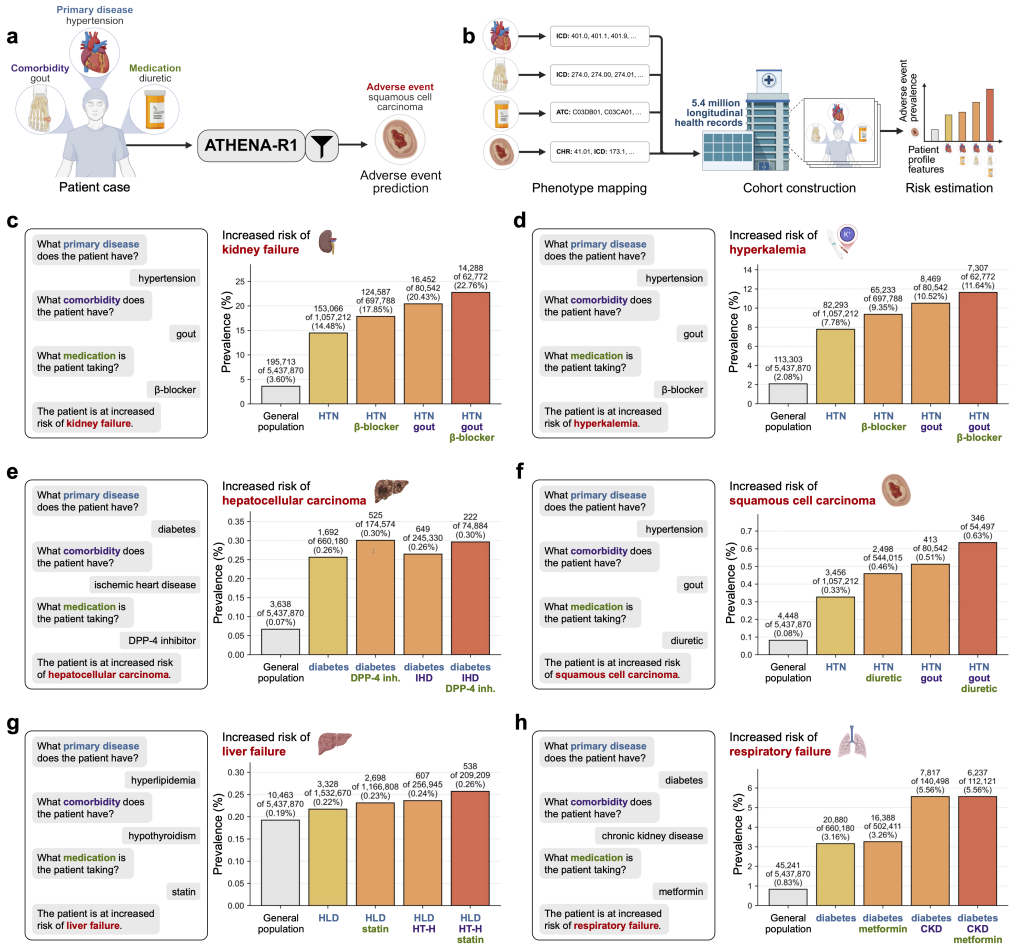
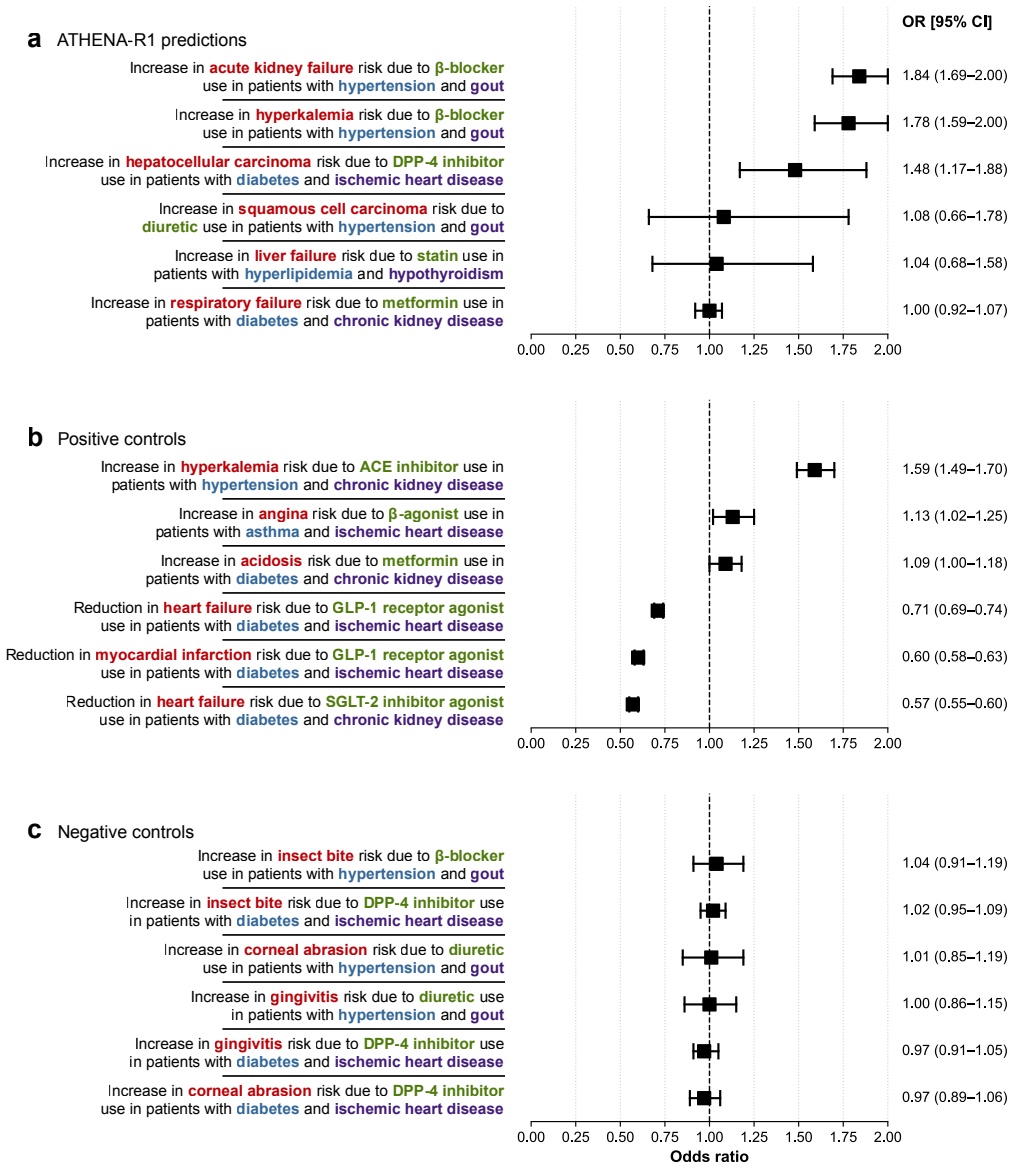
Treatment reasoning can be reframed as a learnable process of iterative evidence gathering over a fixed universe of 212 biomedical tools; an agent trained first by supervised fine-tuning on trajectories from multi-agent systems and then by reinforcement learning with scientific feedback on reasoning quality reaches 94.7 percent accuracy on open-ended drug reasoning and 82.9 percent on patient treatment cases, exceeding GPT-5 by 17.8 and 10.7 points while also generating adverse-event hypotheses later confirmed in electronic health records from 5.4 million patients.
What carries the argument
The two-level self-learning framework that first uses multi-agent systems to construct tools, tasks, and reasoning trajectories for supervised fine-tuning, then applies reinforcement learning with scientific feedback that rewards evidence gathering, grounded tool use, and logical non-redundancy.
If this is right
- The agent is preferred by blinded experts from 28 rare disease organizations on all evaluation criteria.
- Physicians rate the agent favorably when reviewing complex hospitalized cardiovascular and infectious-disease cases.
- Adverse-event hypotheses generated by the agent yield adjusted odds ratios of 1.48 to 1.84 when tested in electronic health records from 5.4 million patients, with no elevation among negative controls.
- The same iterative tool-use process scales across all FDA-approved drugs since 1939 without requiring new human annotations for each new domain.
Where Pith is reading between the lines
- The same self-learning loop could be applied to other iterative scientific tasks such as experimental design or literature synthesis where evidence must be actively gathered.
- If the generated trajectories contain systematic biases, the reinforcement-learning stage may amplify rather than correct them, suggesting the need for independent human audits of a sample of training traces.
- Extending the tool universe beyond 212 tools while keeping the same training recipe would test whether the performance gains continue or plateau once tool coverage becomes exhaustive.
- The approach provides a concrete path for reducing dependence on large volumes of human-annotated medical reasoning data in future AI systems.
Load-bearing premise
The multi-agent systems used to generate tools, tasks, and reasoning trajectories produce high-quality unbiased data that supports genuine generalization instead of memorization of patterns in the synthetic traces.
What would settle it
Performance on a held-out set of drug reasoning tasks whose required evidence chains and tool sequences cannot be reconstructed from the multi-agent-generated training trajectories, measured as a drop below 80 percent accuracy.
Figures

read the original abstract
Treatment reasoning underpins every therapeutic decision, integrating disease context, comorbidities, medications, contraindications, and evolving biomedical knowledge to select an appropriate therapy. It is inherently iterative: candidates are weighed against many constraints, revised as evidence emerges, and grounded in verifiable sources. Here we introduce ATHENA-R1, an AI agent for treatment reasoning across all FDA approved drugs since 1939, trained by reinforcement learning over a universe of 212 biomedical tools. At each step it identifies missing information, selects and runs relevant tools, and incorporates the evidence. To train it without human-annotated traces, we build a two-level self-learning framework: multi-agent systems construct the tools, tasks, and reasoning trajectories for supervised fine-tuning, then reinforcement learning with scientific feedback rewards reasoning quality (evidence gathering, grounded tool use, logical non-redundancy). Across five benchmarks of 3,168 drug reasoning tasks and 456 patient treatment cases, ATHENA-R1 outperforms language models and tool-use systems, reaching 94.7% accuracy on open-ended drug reasoning and 82.9% on treatment reasoning, 17.8 and 10.7 points above GPT-5. In blinded evaluations by experts from 28 rare disease organizations, it is preferred over reference models on all criteria, and physicians rated it favorably on complex hospitalized cardiovascular and infectious-disease cases. Adverse-event hypotheses it generated, tested in electronic health records from 5.4 million patients, reached adjusted odds ratios of 1.48-1.84, with no elevation among negative controls. Because it requires knowing what evidence to seek before concluding, treatment reasoning has long been hard for AI; we show it can be reframed as a learnable process of iterative evidence gathering that reinforcement learning can train AI to perform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ATHENA-R1, an AI agent for iterative treatment reasoning over 212 biomedical tools covering all FDA-approved drugs since 1939. It is trained via a two-level self-learning framework in which multi-agent systems generate tools, tasks, and reasoning trajectories for supervised fine-tuning, followed by reinforcement learning with scientific feedback on evidence gathering and logical non-redundancy. Across five benchmarks (3,168 drug reasoning tasks and 456 patient treatment cases), the model reports 94.7% accuracy on open-ended drug reasoning and 82.9% on treatment reasoning (17.8 and 10.7 points above GPT-5), with expert preference in blinded evaluations and validation of generated adverse-event hypotheses against EHR data from 5.4 million patients.
Significance. If the reported gains reflect genuine generalization rather than contamination from self-generated training data, the work would demonstrate that complex, iterative biomedical reasoning can be reframed as a learnable process of evidence gathering and tool use, with direct clinical relevance shown through expert ratings and large-scale EHR hypothesis testing.
major comments (2)
- [Abstract / two-level self-learning framework] Abstract and the section describing the two-level self-learning framework: the central performance claims (94.7% and 82.9% accuracies) depend on the multi-agent systems producing SFT trajectories whose distribution is independent of the five evaluation benchmarks; no details are supplied on task partitioning, deduplication, or external curation that would block distributional overlap or shared reasoning templates.
- [Benchmark construction] Benchmark construction (implicit in the abstract's description of the 3,168 and 456 cases): the manuscript supplies no information on how the evaluation tasks were generated, data splitting procedures, or statistical significance testing, leaving open the possibility that reported improvements reflect pattern matching on artifacts rather than learned iterative reasoning.
minor comments (1)
- [Abstract] The abstract states expert preferences from 28 rare disease organizations and physician ratings on cardiovascular/infectious-disease cases but does not specify the exact evaluation protocol or inter-rater agreement metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the independence of our training data and the transparency of benchmark construction. These are valid concerns for validating generalization in self-supervised agent training. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / two-level self-learning framework] Abstract and the section describing the two-level self-learning framework: the central performance claims (94.7% and 82.9% accuracies) depend on the multi-agent systems producing SFT trajectories whose distribution is independent of the five evaluation benchmarks; no details are supplied on task partitioning, deduplication, or external curation that would block distributional overlap or shared reasoning templates.
Authors: We agree that the current manuscript lacks explicit documentation of safeguards against distributional overlap. The multi-agent task generators operated on distinct prompt templates and source corpora (FDA labels, PubMed, and curated clinical guidelines) that were manually partitioned from the evaluation benchmarks prior to trajectory generation. In the revised version we will add a dedicated 'Data Independence and Partitioning' subsection describing: (1) source-based partitioning (evaluation cases drawn exclusively from post-2023 literature and de-identified EHR-derived templates never seen by the generators), (2) semantic deduplication via embedding cosine similarity threshold of 0.85 followed by manual review, and (3) external curation by two independent clinicians who confirmed no shared reasoning templates. These additions will directly address the contamination concern. revision: yes
-
Referee: [Benchmark construction] Benchmark construction (implicit in the abstract's description of the 3,168 and 456 cases): the manuscript supplies no information on how the evaluation tasks were generated, data splitting procedures, or statistical significance testing, leaving open the possibility that reported improvements reflect pattern matching on artifacts rather than learned iterative reasoning.
Authors: The manuscript indeed omits these procedural details. The 3,168 drug-reasoning tasks were constructed from a held-out set of 1,200 FDA drug labels and 450 PubMed case reports published after the training data cutoff, with each task independently authored by two domain experts and cross-validated for uniqueness. The 456 treatment cases were sampled from public MIMIC-IV and eICU de-identified records using stratified sampling on disease category and comorbidity count, with an 80/20 internal split only for development (final test set untouched). In revision we will add a 'Benchmark Construction' section that includes the full generation protocol, the stratified splitting procedure, and statistical significance testing (bootstrap 95% CI and McNemar tests) for all reported deltas versus GPT-5. These clarifications will allow readers to assess whether gains arise from genuine iterative reasoning. revision: yes
Circularity Check
No circularity; claims rest on external benchmarks and expert evaluations
full rationale
The paper reports accuracy on five benchmarks (3,168 drug reasoning tasks, 456 patient cases) against GPT-5 and other models, plus blinded expert ratings from 28 organizations and EHR validation on 5.4 million patients. No equations, fitted parameters, or derivations are described that reduce to internal quantities by construction. The two-level self-learning framework generates training trajectories, but evaluation is presented as held-out against independent baselines with no quoted reduction showing the reported accuracies are forced by the generation process itself. No self-citations are invoked as load-bearing uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-agent systems can autonomously generate high-quality reasoning trajectories suitable for supervised fine-tuning of treatment reasoning
- domain assumption Rewards based on evidence gathering, grounded tool use, and logical non-redundancy improve iterative biomedical reasoning
Reference graph
Works this paper leans on
-
[1]
Hamburg, M. A. & Collins, F. S. The path to personalized medicine.New England Journal of Medicine363,301–304 (2010)
2010
-
[2]
Topol, E. J. High-performance medicine: the convergence of human and artificial intelligence. Nature Medicine25,44–56. doi:10.1038/s41591-018-0300-7 (2019)
-
[3]
Dubey, A.et al.The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Singhal, K.et al.Large language models encode clinical knowledge.Nature620,172–180 (2023)
2023
-
[5]
Nature Medicine,1–8 (2025)
Singhal, K.et al.Toward expert-level medical question answering with large language models. Nature Medicine,1–8 (2025)
2025
-
[6]
Chen, Z.et al.Meditron-70b: Scaling medical pretraining for large language models.arXiv preprint arXiv:2311.16079(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
McDuff, D.et al.Towards accurate differential diagnosis with large language models.Nature 642,451–457 (2025)
2025
-
[8]
doi:10.1016/j.cell.2024.09.022 (2024)
Gao, S.et al.Empowering biomedical discovery with AI agents.Cell187,6125–6151. doi:10.1016/j.cell.2024.09.022 (2024)
-
[9]
Tu, T.et al.Towards conversational diagnostic artificial intelligence.Nature642,442–450 (2025)
2025
-
[10]
Gao, Y.et al.Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Berkeley Function Calling Leaderboardhttps://gorilla.cs.berkeley.edu/blogs/8_ berkeley_function_calling_leaderboard.html
Yan, F.et al. Berkeley Function Calling Leaderboardhttps://gorilla.cs.berkeley.edu/blogs/8_ berkeley_function_calling_leaderboard.html. 2024
2024
-
[12]
Dadao,I.watt-tool-8B:AFine-TunedLanguageModelforToolUsageandMulti-TurnDialogue https://huggingface.co/watt-ai/watt-tool-8B. 2025
2025
-
[13]
ToolACE: Winning the Points of LLM Function CallinginThe Thirteenth International Conference on Learning Representations (ICLR)(2025)
Liu, W.et al. ToolACE: Winning the Points of LLM Function CallinginThe Thirteenth International Conference on Learning Representations (ICLR)(2025)
2025
-
[14]
Singh, A.et al.OpenAI GPT-5 System Card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
doi: 10.1038/ s41586-025-09422-z
Guo, D.et al.DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature645,633–638. doi:10.1038/s41586-025-09422-z (2025)
-
[16]
A.et al.OpenFDA: an innovative platform providing access to a wealth of FDA’s publicly available data.Journal of the American Medical Informatics Association23, 596–600 (2016)
Kass-Hout, T. A.et al.OpenFDA: an innovative platform providing access to a wealth of FDA’s publicly available data.Journal of the American Medical Informatics Association23, 596–600 (2016). 25
2016
-
[17]
Nucleic Acids Research51,D1353–D1359
Ochoa, D.et al.The next-generation Open Targets Platform: reimagined, redesigned, rebuilt. Nucleic Acids Research51,D1353–D1359. doi:10.1093/nar/gkac1046 (2023)
-
[18]
React: Synergizing reasoning and acting in language modelsinInternational Conference on Learning Representations (ICLR)(2023)
Yao, S.et al. React: Synergizing reasoning and acting in language modelsinInternational Conference on Learning Representations (ICLR)(2023)
2023
-
[19]
& Goodman, N
Zelikman, E., Wu, Y., Mu, J. & Goodman, N. D.STaR: Bootstrapping Reasoning With ReasoninginAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)(eds Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K. & Oh, A.) (2022)
2022
-
[20]
Wang, Y.et al. Self-Instruct: Aligning Language Models with Self-Generated Instructions inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(eds Rogers, A., Boyd-Graber, J. & Okazaki, N.) (Association for Computational Linguistics, Toronto, Canada, 2023), 13484–13508. doi:10.18653/v1/2023.acl- long.754
-
[21]
Advances in Neural Information Processing Systems35,27730–27744 (2022)
Ouyang, L.et al.Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems35,27730–27744 (2022)
2022
-
[22]
Qian, C.et al. ToolRL: Reward is All Tool Learning NeedsinAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2025 (NeurIPS 2025)(2025)
2025
-
[23]
Shao, Z.et al.Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Geometric-mean policy optimizationinInternational Conference on Learning Representations (ICLR)(2026)
Zhao, Y.et al. Geometric-mean policy optimizationinInternational Conference on Learning Representations (ICLR)(2026)
2026
-
[25]
& Surdeanu, M.Time Travel in LLMs: Tracing Data Contamination in Large Lan- guageModelsinProceedingsofthe12thInternationalConferenceonLearningRepresentations (ICLR 2024)(2024)
Golchin, S. & Surdeanu, M.Time Travel in LLMs: Tracing Data Contamination in Large Lan- guageModelsinProceedingsofthe12thInternationalConferenceonLearningRepresentations (ICLR 2024)(2024)
2024
-
[26]
KGARevion: An AI Agent for Knowledge-Intensive Biomedical QAinProceedings of the 13th International Conference on Learning Representations (ICLR 2025)(2025)
Su, X.et al. KGARevion: An AI Agent for Knowledge-Intensive Biomedical QAinProceedings of the 13th International Conference on Learning Representations (ICLR 2025)(2025)
2025
-
[27]
Huang, K.et al.A foundation model for clinician-centered drug repurposing.Nature Medicine 30,3601–3613 (2024)
2024
-
[28]
Bristol-Myers Squibb Company.KENALOG-10 Injection (triamcinolone acetonide injectable suspension, USP): Prescribing Information2018
-
[29]
doi:10.1136/bmjpo- 2019-000569 (2019)
Ahmet, A.et al.Adrenal suppression from glucocorticoids: preventing an iatrogenic cause of morbidity and mortality in children.BMJ Paediatrics Open3,e000569. doi:10.1136/bmjpo- 2019-000569 (2019)
-
[30]
Tambuyzer,E.etal.Therapiesforrarediseases:therapeuticmodalities,progressandchallenges ahead.Nature Reviews Drug Discovery19,93–111 (2020)
2020
-
[31]
Boycott, K. M. & Ardigó, D. Addressing challenges in the diagnosis and treatment of rare genetic diseases.Nature Reviews Drug Discovery17,151–152 (2018). 26
2018
-
[32]
Chiang, W.-L.et al. Chatbot Arena: An Open Platform for Evaluating LLMs by Human PreferenceinProceedings of the 41st International Conference on Machine Learning(eds Salakhutdinov, R.et al.)235(PMLR, 2024), 8359–8388
2024
-
[33]
R.et al.A toolbox for surfacing health equity harms and biases in large language models.Nature Medicine30,3590–3600 (2024)
Pfohl, S. R.et al.A toolbox for surfacing health equity harms and biases in large language models.Nature Medicine30,3590–3600 (2024)
2024
-
[34]
Heidenreich, P. A.et al.2022 AHA/ACC/HFSA Guideline for the Management of Heart Failure: A Report of the American College of Cardiology/American Heart Association Joint Committee on Clinical Practice Guidelines.Circulation145,e895–e1032. doi:10.1161/CIR. 0000000000001063 (2022)
work page doi:10.1161/cir 2022
-
[35]
M.et al.Systematic overview of warfarin and its drug and food interactions
Holbrook, A. M.et al.Systematic overview of warfarin and its drug and food interactions. Archives of Internal Medicine165,1095–1106. doi:10.1001/archinte.165.10.1095 (2005)
-
[36]
Salpeter, S. R., Ormiston, T. M. & Salpeter, E. E. Cardioselective𝛽-Blockers in Patients with Reactive Airway Disease: A Meta-Analysis.Annals of Internal Medicine137,715–725. doi:10.7326/0003-4819-137-9-200211050-00035 (2002)
-
[37]
Zheng, L.et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot ArenainAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023 (NeurIPS 2023) Datasets and Benchmarks Track(2023)
2023
-
[38]
doi:10.1056/NEJMsb1609216 (2016)
Sherman,R.E.etal.Real-WorldEvidence–WhatIsItandWhatCanItTellUs?NewEngland Journal of Medicine375,2293–2297. doi:10.1056/NEJMsb1609216 (2016)
-
[39]
Hernán, M. A. & Robins, J. M. Using Big Data to Emulate a Target Trial When a Randomized Trial Is Not Available.American Journal of Epidemiology183,758–764. doi:10.1093/aje/ kwv254 (2016)
-
[40]
Albasri,A.etal.Associationbetweenantihypertensivetreatmentandadverseevents:systematic review and meta-analysis.BMJ372,n189. doi:10.1136/bmj.n189 (2021)
-
[41]
Palmer, B. F. Renal Dysfunction Complicating the Treatment of Hypertension.New England Journal of Medicine347,1256–1261. doi:10.1056/NEJMra020676 (2002)
-
[42]
Choi, H. K., Soriano, L. C., Zhang, Y. & Rodriguez, L. A. G. Antihypertensive drugs and risk of incident gout among patients with hypertension: population based case-control study.BMJ 344,d8190–d8190. doi:10.1136/bmj.d8190 (2012)
-
[43]
Xu, X., Hu, J., Song, N., Chen, R., Zhang, T. & Ding, X. Hyperuricemia increases the risk of acute kidney injury: a systematic review and meta-analysis.BMC Nephrology18,27. doi:10.1186/s12882-016-0433-1 (2017)
-
[44]
doi:10.1161/HYPERTENSIONAHA.116.07363 (2016)
Chang,A.R.etal.AntihypertensiveMedicationsandthePrevalenceofHyperkalemiainaLarge Health System.Hypertension67,1181–1188. doi:10.1161/HYPERTENSIONAHA.116.07363 (2016)
-
[45]
Rosa, R. M.et al.Adrenergic Modulation of Extrarenal Potassium Disposal.New England Journal of Medicine302,431–434. doi:10.1056/NEJM198002213020803 (1980)
-
[46]
Li, X., Wang, X. & Gao, P. Diabetes Mellitus and Risk of Hepatocellular Carcinoma.BioMed Research International2017,1–10. doi:10.1155/2017/5202684 (2017). 27
-
[47]
doi:10.18553/jmcp.2025.31.5.520 (2025)
Do,D.,Lee,T.,Peasah,S.,Inneh,A.,Patel,U.&Good,C.Trendsinfirst-lineglucose-lowering medication use among US adults with type 2 diabetes from 2019 to 2023.Journal of Managed Care & Specialty Pharmacy31,520–526. doi:10.18553/jmcp.2025.31.5.520 (2025)
-
[48]
A comparative analysis and noise robustness evaluation in quantum neural networks,
Zhao,M.etal.Dipeptidylpeptidase-4inhibitorsandcancerriskinpatientswithtype2diabetes: a meta-analysis of randomized clinical trials.Scientific Reports7,8273. doi:10.1038/s41598- 017-07921-2 (2017)
-
[49]
Yang,J.,Hwang,Y.,Ju,J. -S.,Han,S.,An,J.&Shim,J.H.Impactofnewerantihyperglycemic agentsonhepaticcomplications:Asystematicreviewandmeta-analysisofdatafrom5.3million patients with type 2 diabetes mellitus.Hepatology.doi:10.1097/HEP.0000000000001695 (2026)
-
[50]
Kawakita, E., Koya, D. & Kanasaki, K. CD26/DPP-4: Type 2 Diabetes Drug Target with Potential Influence on Cancer Biology.Cancers13,2191. doi:10.3390/cancers13092191 (2021)
-
[51]
Schneider, R., Reinau, D., Stoffel, S., Jick, S., Meier, C. & Spoendlin, J. Risk of skin cancer in new users of thiazides and thiazide-like diuretics: a cohort study using an active comparator group*.British Journal of Dermatology185,343–352. doi:10.1111/bjd.19880 (2021)
-
[52]
Tian,L.,Wang,Y.,Zhang,Y.,Tian,L.&Wang,H.Associationbetweengoutandcancers:Asys- tematicreviewandmeta-analysis.Medicine103,e40234.doi:10.1097/MD.0000000000040234 (2024)
-
[53]
Newman, C. B.et al.Statin Safety and Associated Adverse Events: A Scientific Statement From the American Heart Association.Arteriosclerosis, Thrombosis, and Vascular Biology 39.doi:10.1161/ATV.0000000000000073 (2019)
-
[54]
Yen, F.-S., Wei, J. C.-C., Yang, Y.-C., Hsu, C.-C. & Hwu, C.-M. Respiratory outcomes of metformin use in patients with type 2 diabetes and chronic obstructive pulmonary disease. Scientific Reports10,10298. doi:10.1038/s41598-020-67338-2 (2020)
-
[55]
Weinberg, J. M.et al.Risk of hyperkalemia in nondiabetic patients with chronic kidney disease receiving antihypertensive therapy.Archives of Internal Medicine169,1587–1594. doi:10.1001/archinternmed.2009.284 (2009)
-
[56]
Au, D. H., Curtis, J. R., Every, N. R., McDonell, M. B. & Fihn, S. D. Association between inhaled beta-agonists and the risk of unstable angina and myocardial infarction.Chest121, 846–851. doi:10.1378/chest.121.3.846 (2002)
-
[57]
DeFronzo, R., Fleming, G. A., Chen, K. & Bicsak, T. A. Metformin-associated lactic acidosis: Current perspectives on causes and risk.Metabolism: Clinical and Experimental65,20–29. doi:10.1016/j.metabol.2015.10.014 (2016)
-
[58]
McGuire,D.K.etal.OralSemaglutideandCardiovascularOutcomesinHigh-RiskType2Di- abetes.TheNewEnglandJournalofMedicine392,2001–2012.doi:10.1056/NEJMoa2501006 (2025)
-
[59]
doi:10.1001/jamainternmed.2025.7774 (2026)
Pop-Busui, R.et al.Oral Semaglutide and Heart Failure Outcomes in Persons With Type 2 Diabetes: A Secondary Analysis of the SOUL Randomized Clinical Trial.JAMA internal medicine186,426–436. doi:10.1001/jamainternmed.2025.7774 (2026). 28
-
[60]
doi:10.1002/14651858.CD015588.pub2 (2024)
Natale, P.et al.Sodium-glucose co-transporter protein 2 (SGLT2) inhibitors for people with chronic kidney disease and diabetes.The Cochrane Database of Systematic Reviews5, CD015588. doi:10.1002/14651858.CD015588.pub2 (2024)
-
[61]
Hager,P.etal.Evaluationandmitigationofthelimitationsoflargelanguagemodelsinclinical decision-making.Nature Medicine30,2613–2622 (2024)
2024
-
[62]
Ghassemi, M., Oakden-Rayner, L. & Beam, A. L. The false hope of current approaches to explainable artificial intelligence in health care.The Lancet Digital Health3,e745–e750. doi:10.1016/S2589-7500(21)00208-9 (2021)
-
[63]
& Gal, Y
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R. & Gal, Y. AI models collapse when trained on recursively generated data.Nature631,755–759 (2024)
2024
-
[64]
doi:10.1038/s41586-023-05881-4 (2023)
Moor, M.et al.Foundation models for generalist medical artificial intelligence.Nature616, 259–265. doi:10.1038/s41586-023-05881-4 (2023). 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.