RA-LWLM: Retrieval-Augmented In-Context Localization with Wireless Foundation Models
Pith reviewed 2026-06-28 13:18 UTC · model grok-4.3
The pith
Retrieval from per-scene databases lets a frozen wireless foundation model localize users in unseen environments at the same accuracy as seen scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
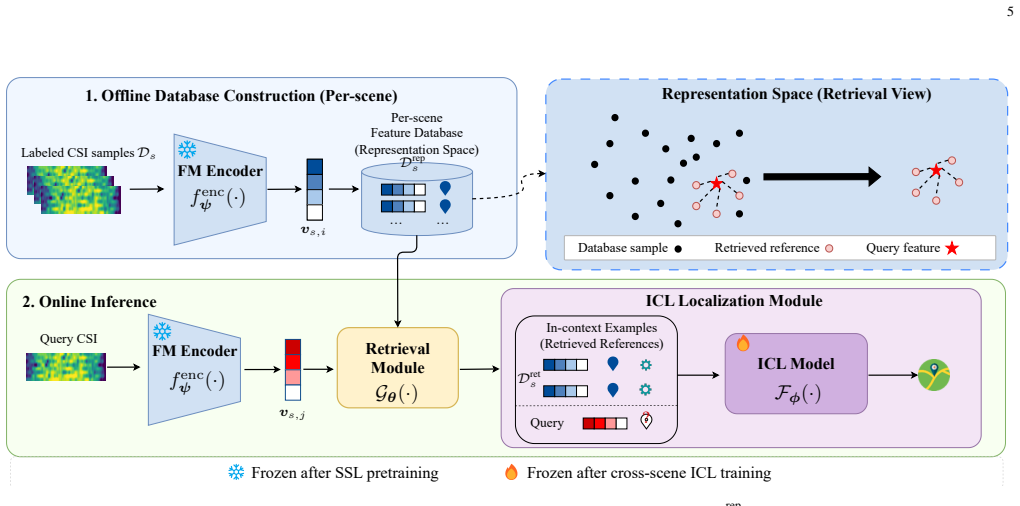
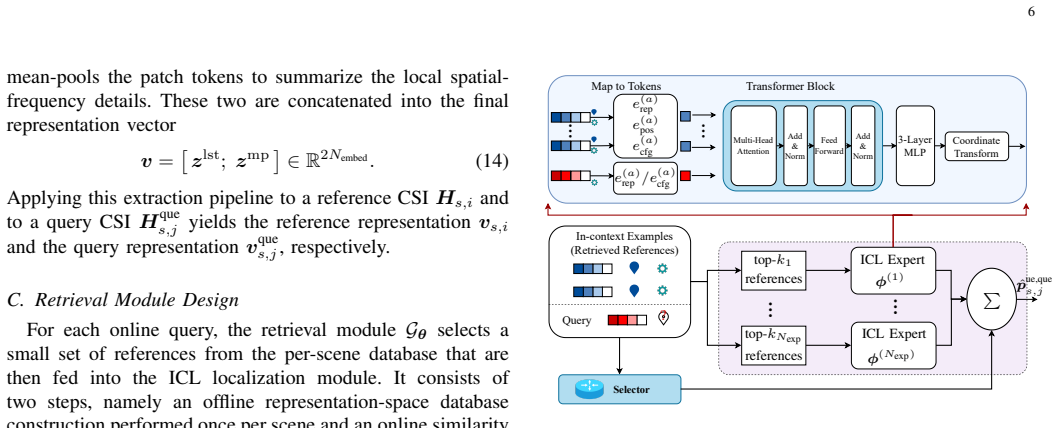
RA-LWLM achieves training-free cross-scene adaptation for wireless localization by externalizing scene-specific information into per-scene fingerprint databases, using a frozen FM encoder to map raw channel state information into scene-agnostic representations, a similarity-based retrieval module, and a transformer-based in-context learning module with mixture-of-experts design that fuses the query and retrieved references to predict UE position, yielding nearly identical accuracy on seen and unseen scenes without per-scene retraining.
What carries the argument
The mixture-of-experts in-context learning module that softly combines experts specialized for different context sizes after similarity retrieval in the frozen FM representation space.
If this is right
- The same model weights can be deployed across heterogeneous base-station configurations and propagation environments without retraining.
- Mixture-of-experts selection adapts the amount of retrieved context to each query's retrieval quality and scene complexity.
- Scene knowledge is updated simply by adding or replacing entries in the per-scene database rather than by gradient updates.
- The framework outperforms both fully end-to-end trained localizers and non-retrieval foundation-model baselines in cross-scene settings.
Where Pith is reading between the lines
- The same retrieval-plus-in-context pattern could be tested on related wireless tasks such as channel estimation or beam prediction when environments change.
- External databases may reduce the data and compute cost of keeping foundation models current in other domains that face distribution shift.
- Real-world over-the-air measurements instead of ray-tracing would provide a direct check on whether the scene-agnostic representations hold outside simulation.
Load-bearing premise
The frozen wireless foundation model encoder produces channel representations that remain similar enough across different scenes for retrieval to find useful references.
What would settle it
A test in which localization error on multiple unseen scenes exceeds error on seen scenes by more than a small margin under identical model weights and database construction would falsify the cross-scene claim.
Figures
read the original abstract
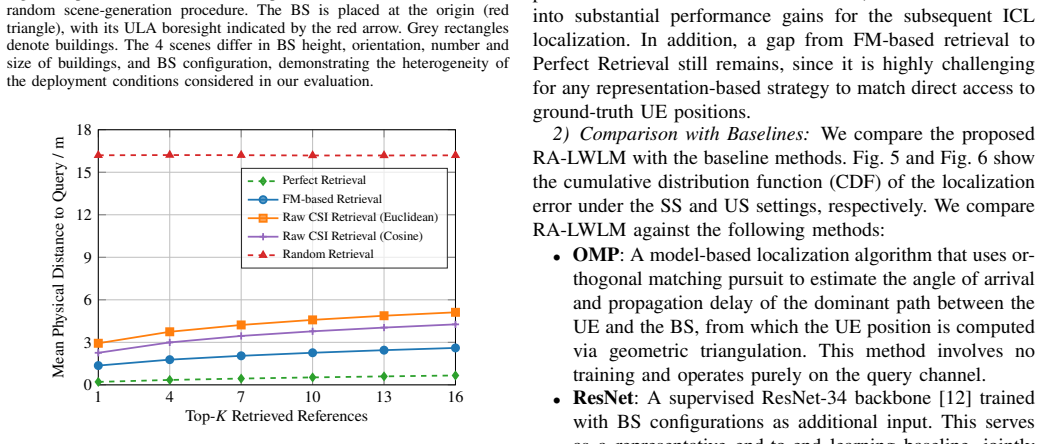
Wireless localization is a fundamental capability of sixth-generation (6G) networks. Conventional model-based methods require accurate modeling of the propagation environment and degrade in complex multipath and non-line-of-sight scenarios, while learning-based methods couple model parameters tightly to the training scene, requiring costly retraining whenever the base station (BS) configuration or propagation environment changes. In this paper, we propose RA-LWLM, a retrieval-augmented in-context localization framework that achieves training-free cross-scene adaptation by externalizing scene-specific information into a per-scene fingerprint database rather than encoding it in model weights. The framework consists of three components: a frozen wireless foundation model (FM) encoder that maps raw channel state information into a scene-agnostic representation; a retrieval module that selects the most informative references from the per-scene database via similarity search in the representation space; and a transformer-based in-context learning (ICL) module that fuses the query with the retrieved references to predict the user equipment (UE) position. To accommodate varying retrieval quality and propagation complexity across queries, the ICL module adopts a mixture-of-experts design in which experts specialize in different context sizes and are softly combined by a learnable selector. Extensive ray-tracing-based experiments across heterogeneous scenes with diverse BS configurations show that RA-LWLM achieves nearly identical accuracy on seen and unseen scenes without any per-scene retraining, substantially outperforming end-to-end and FM-based baselines. These results validate the proposed retrieval-augmented in-context paradigm as a scalable solution for cross-scene localization in 6G networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RA-LWLM, a retrieval-augmented in-context localization framework for 6G wireless positioning. It consists of a frozen wireless foundation model encoder that maps raw CSI to scene-agnostic embeddings, a similarity-based retrieval module that pulls references from a per-scene fingerprint database, and a mixture-of-experts transformer ICL module that fuses the query with retrieved contexts to predict UE position. The central claim is that this achieves nearly identical accuracy on seen and unseen scenes with no per-scene retraining and substantially outperforms end-to-end and FM-based baselines, as shown in ray-tracing experiments across heterogeneous scenes.
Significance. If the core assumption holds, the approach would offer a meaningful advance for scalable localization by externalizing scene-specific information into retrievable databases rather than model weights, addressing a key limitation of learning-based methods when BS configurations or environments change. The mixture-of-experts design for adapting to retrieval quality is a technically interesting element.
major comments (3)
- [Abstract] Abstract: The load-bearing claim that the frozen FM encoder produces scene-agnostic representations enabling reliable cross-scene retrieval via cosine similarity is asserted but unsupported by any embedding visualizations, cross-scene retrieval precision metrics, or quantitative analysis of whether embeddings cluster by scene-specific propagation effects rather than position.
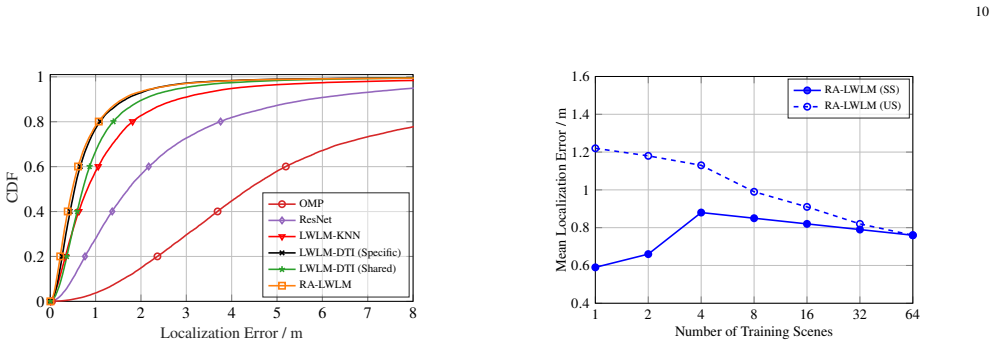
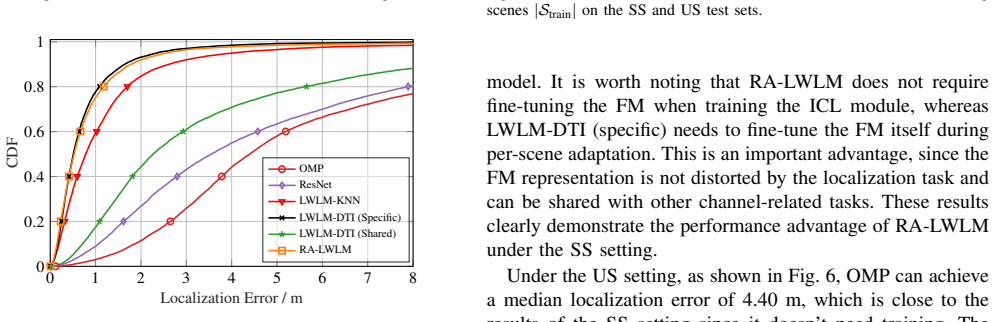
- [Abstract] Abstract: The assertion of 'nearly identical accuracy on seen and unseen scenes' and 'substantially outperforming' baselines lacks any reported error values, tables, or statistical comparisons, preventing assessment of whether the result actually holds or is driven by the retrieval step.
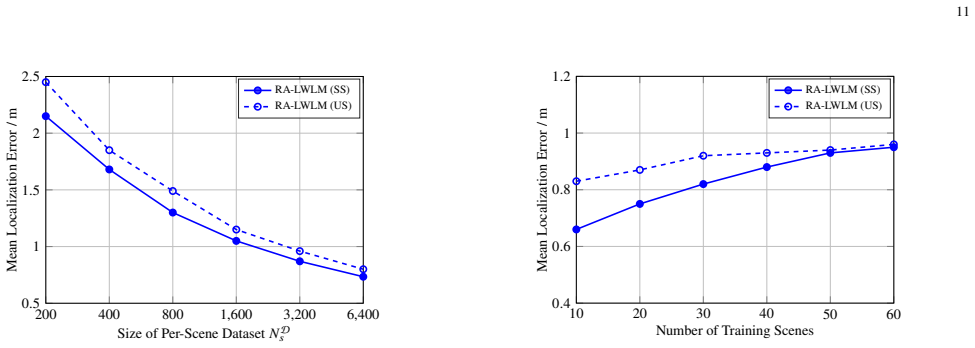
- [Abstract] Abstract: No ablation is described that isolates the contribution of the retrieval module (e.g., performance with random or no retrieval), which is required to substantiate that the ICL module cannot compensate for poor cross-scene matches.
minor comments (1)
- The abstract would be clearer if it briefly noted the pretraining corpus or architecture of the wireless FM, as this directly affects the plausibility of scene-agnostic embeddings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from greater specificity and supporting references to analyses in the main text. We will revise the abstract and ensure all requested elements are clearly presented or added to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that the frozen FM encoder produces scene-agnostic representations enabling reliable cross-scene retrieval via cosine similarity is asserted but unsupported by any embedding visualizations, cross-scene retrieval precision metrics, or quantitative analysis of whether embeddings cluster by scene-specific propagation effects rather than position.
Authors: We acknowledge that the abstract does not cite supporting evidence for this claim. The full manuscript contains t-SNE visualizations of embeddings across scenes and retrieval precision/recall metrics (Section 4.2) showing that cosine similarity primarily retrieves position-relevant references rather than scene-specific artifacts. To address the comment, we will revise the abstract to reference these results concisely and add a short quantitative statement on embedding clustering behavior. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'nearly identical accuracy on seen and unseen scenes' and 'substantially outperforming' baselines lacks any reported error values, tables, or statistical comparisons, preventing assessment of whether the result actually holds or is driven by the retrieval step.
Authors: The abstract summarizes results whose numerical details appear in Table 1 and Figures 3-4 of the manuscript, which report RMSE values (e.g., 1.8 m seen vs. 2.1 m unseen) and direct comparisons against end-to-end and FM baselines with standard deviations. We agree the abstract should be more self-contained and will incorporate representative error values plus a brief note on statistical significance. revision: yes
-
Referee: [Abstract] Abstract: No ablation is described that isolates the contribution of the retrieval module (e.g., performance with random or no retrieval), which is required to substantiate that the ICL module cannot compensate for poor cross-scene matches.
Authors: The manuscript includes ablation studies in Section 5.3 that compare the full model against variants with random retrieval and with retrieval disabled. These show clear degradation when retrieval quality drops, confirming the ICL module's dependence on informative contexts. We will revise the abstract to mention this ablation and ensure the relevant table/figure is explicitly cross-referenced. revision: yes
Circularity Check
No circularity: empirical claims rest on external experiments with frozen components
full rationale
The paper describes a framework with three explicit components (frozen FM encoder, retrieval module, ICL module) whose performance on seen vs. unseen scenes is asserted via ray-tracing experiments. No equation, definition, or cited result reduces a claimed prediction to a fitted parameter or self-referential input; the scene-agnostic representation is treated as an empirical property of the frozen encoder rather than derived by construction from the target localization task. No self-citation chains or ansatzes are invoked to justify core claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Orientation and location tracking of XR devices: 5G carrier phase-based methods,
J. Talvitie, M. S ¨aily, and M. Valkama, “Orientation and location tracking of XR devices: 5G carrier phase-based methods,”IEEE J. Sel. Topics Signal Process., vol. 17, no. 5, pp. 919–934, 2023
2023
-
[2]
AI-driven wireless positioning: Fun- damentals, standards, state-of-the-art, and challenges,
G. Pan, Y . Gao, Y . Gaoet al., “AI-driven wireless positioning: Fun- damentals, standards, state-of-the-art, and challenges,”IEEE Commun. Surveys Tuts., vol. 28, pp. 4394–4428, 2026
2026
-
[3]
Positioning using wireless networks: Applications, recent progress, and future challenges,
Y . Yang, M. Chen, Y . Blankenshipet al., “Positioning using wireless networks: Applications, recent progress, and future challenges,”IEEE J. Sel. Areas Commun., vol. 42, no. 9, pp. 2149–2178, 2024
2024
-
[4]
OpenNavMap: Structure-free topomet- ric mapping via large-scale collaborative localization,
J. Jiao, C. Liu, J. Yuet al., “OpenNavMap: Structure-free topomet- ric mapping via large-scale collaborative localization,”arXiv preprint arXiv:2601.12291, 2026
-
[5]
Location-aware com- munications for 5G networks: How location information can improve scalability, latency, and robustness of 5G,
R. Di Taranto, S. Muppirisetty, R. Raulefset al., “Location-aware com- munications for 5G networks: How location information can improve scalability, latency, and robustness of 5G,”IEEE Signal Process. Mag., vol. 31, no. 6, pp. 102–112, Oct. 2014
2014
-
[6]
Location-dependent performance analysis for RIS-aided or interference mitigation assisted large-scale networks,
C. Chen, H. Jiang, and C. Pan, “Location-dependent performance analysis for RIS-aided or interference mitigation assisted large-scale networks,”IEEE Trans. Veh. Technol., 2024
2024
-
[7]
Integrated localization and com- munication for efficient millimeter wave networks,
G. Kwon, Z. Liu, A. Contiet al., “Integrated localization and com- munication for efficient millimeter wave networks,”IEEE J. Sel. Areas Commun., vol. 41, no. 12, pp. 3925–3941, 2023
2023
-
[8]
A tutorial on terahertz-band localization for 6G communication systems,
H. Chen, H. Sarieddeen, T. Ballalet al., “A tutorial on terahertz-band localization for 6G communication systems,”IEEE Commun. Surveys Tuts., vol. 24, no. 3, pp. 1780–1815, 2022
2022
-
[9]
Multi-sources fusion learning for multi-points nlos localization in ofdm system,
B. Wang, Z. Shuai, C. Huanget al., “Multi-sources fusion learning for multi-points nlos localization in ofdm system,”IEEE J. Sel. Topics Signal Process., vol. 18, no. 7, pp. 1339–1350, 2024
2024
-
[10]
Mimo- based indoor localisation with hybrid neural networks: Leveraging synthetic images from tidy data for enhanced deep learning,
M. Castillo-Cara, J. Mart ´ınez-G´omez, J. Ballesteros-Jerezet al., “Mimo- based indoor localisation with hybrid neural networks: Leveraging synthetic images from tidy data for enhanced deep learning,”IEEE J. Sel. Topics Signal Process., vol. 19, no. 3, pp. 559–571, 2025
2025
-
[11]
Deep neural networks for wireless localization in indoor and outdoor environments,
W. Zhang, K. Liu, W. Zhanget al., “Deep neural networks for wireless localization in indoor and outdoor environments,”Neurocomputing, vol. 194, pp. 279–287, 2016
2016
-
[12]
Learning to localize: A 3D CNN approach to user positioning in massive MIMO-OFDM systems,
C. Wu, X. Yi, W. Wanget al., “Learning to localize: A 3D CNN approach to user positioning in massive MIMO-OFDM systems,”IEEE Trans. Wireless Commun., vol. 20, no. 7, pp. 4556–4570, 2021
2021
-
[13]
High accurate time-of-arrival estimation with fine-grained feature generation for internet-of-things applications,
G. Pan, T. Wang, S. Zhanget al., “High accurate time-of-arrival estimation with fine-grained feature generation for internet-of-things applications,”IEEE Wireless Commun. Lett., vol. 9, no. 11, pp. 1980– 1984, 2020
1980
-
[14]
Graph-neural-network-based WiFi indoor localization system with access point selection,
S. Wang, S. Zhang, J. Maet al., “Graph-neural-network-based WiFi indoor localization system with access point selection,”IEEE Internet Things J., vol. 11, no. 20, pp. 33 550–33 564, 2024
2024
-
[15]
Attentional graph neural network is all you need for robust massive network localization,
W. Yan, F. Yin, J. Wanget al., “Attentional graph neural network is all you need for robust massive network localization,”IEEE J. Sel. Topics Signal Process., vol. 19, no. 7, pp. 1493–1513, 2025
2025
-
[16]
Swin-loc: Transformer-based CSI fingerprinting indoor localization with MIMO ISAC system,
X. Xu, F. Zhu, S. Hanet al., “Swin-loc: Transformer-based CSI fingerprinting indoor localization with MIMO ISAC system,”IEEE Trans. Veh. Technol., 2024
2024
-
[17]
Spatial context aware dynamic fusion with mixture-of-experts for wireless localization,
B. Wang, C. Wu, C. Huanget al., “Spatial context aware dynamic fusion with mixture-of-experts for wireless localization,”IEEE J. Sel. Areas Commun., 2025
2025
-
[18]
Channel charting: Locating users within the radio environment using channel state information,
C. Studer, S. Medjkouh, E. Gonultas ¸et al., “Channel charting: Locating users within the radio environment using channel state information,” IEEE Access, vol. 6, pp. 47 682–47 698, 2018
2018
-
[19]
Angle-delay profile-based and timestamp-aided dissimilarity metrics for channel charting,
P. Stephan, F. Euchner, and S. Ten Brink, “Angle-delay profile-based and timestamp-aided dissimilarity metrics for channel charting,”IEEE Trans. Commun., vol. 72, no. 9, pp. 5611–5625, 2024
2024
-
[20]
Triplet-based wireless channel charting: Architecture and experiments,
P. Ferrand, A. Decurninge, L. G. Ordonezet al., “Triplet-based wireless channel charting: Architecture and experiments,”IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2361–2373, 2021
2021
-
[21]
UNILocPro: Unified localization integrating model-based geometry and channel charting,
Y . Zhang, G. Pan, M. F. Keskinet al., “UNILocPro: Unified localization integrating model-based geometry and channel charting,”arXiv preprint arXiv:2510.27394, 2025
-
[22]
Model-based approaches to channel charting,
A. Aly and E. Ayanoglu, “Model-based approaches to channel charting,” IEEE Trans. Commun., vol. 72, no. 2, pp. 1207–1222, 2023
2023
-
[23]
Positioning via digital-twin-aided channel charting with large-scale CSI features,
J. M. Mateos-Ramos, F. Zumegen, H. Wymeerschet al., “Positioning via digital-twin-aided channel charting with large-scale CSI features,” arXiv preprint arXiv:2511.09227, 2025
-
[24]
Transfer learning for csi-based positioning with multi-environment meta-learning,
A. Foliadis, M. H. Casta ˜neda Garcia, R. A. Stirling-Gallacheret al., “Transfer learning for csi-based positioning with multi-environment meta-learning,”IEEE Trans. Wireless Commun., vol. 24, no. 11, pp. 9735–9748, 2025
2025
-
[25]
Semi-supervised deep adversarial forest for cross-environment localization,
W. Cui, L. Zhang, B. Liet al., “Semi-supervised deep adversarial forest for cross-environment localization,”IEEE Trans. Veh. Technol., vol. 71, no. 9, pp. 10 215–10 219, 2022
2022
-
[26]
MetaLoc: Learning to learn wireless localization,
J. Gao, D. Wu, F. Yinet al., “MetaLoc: Learning to learn wireless localization,”IEEE J. Sel. Areas Commun., vol. 41, no. 12, pp. 3831– 3847, 2023
2023
-
[27]
Attentional graph meta-learning for indoor localization using extremely sparse fingerprints,
W. Yan, F. Yin, J. Gaoet al., “Attentional graph meta-learning for indoor localization using extremely sparse fingerprints,”IEEE Trans. Mob. Comput., 2025
2025
-
[28]
Towards channel foundation models (CFMs): Motivations, methodologies and opportunities
J. Jiang, Y . Gao, X. Wuet al., “Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,”arXiv preprint arXiv:2507.13637, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Large ai models for wireless physical layer,
J. Guo, Y . Cui, S. Jinet al., “Large ai models for wireless physical layer,”IEEE Commun. Mag., 2026
2026
-
[30]
A self-supervised masked au- toencoder leveraging temporal-frequency representation for CSI local- ization,
Y . Liu, H. Si, G. O. Boatenget al., “A self-supervised masked au- toencoder leveraging temporal-frequency representation for CSI local- ization,”IEEE Trans. Network Sci. Eng., 2026
2026
-
[31]
Self-supervised and invariant rep- resentations for wireless localization,
A. Salihu, M. Rupp, and S. Schwarz, “Self-supervised and invariant rep- resentations for wireless localization,”IEEE Trans. Wireless Commun., vol. 23, no. 8, pp. 8281–8296, 2024
2024
-
[32]
Large wireless localization model (LWLM): A foundation model for positioning in 6G networks,
G. Pan, K. Huang, H. Chenet al., “Large wireless localization model (lwlm): A foundation model for positioning in 6g networks,”arXiv preprint arXiv:2505.10134, 2025
-
[33]
Rankrag: Unifying context ranking with retrieval-augmented generation in llms,
Y . Yu, W. Ping, Z. Liuet al., “Rankrag: Unifying context ranking with retrieval-augmented generation in llms,”Proc. NIPS’2024, vol. 37, pp. 121 156–121 184, 2024
2024
-
[34]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktuset al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,”Proc. NIPS’2020, vol. 33, pp. 9459– 9474, 2020
2020
-
[35]
In-context learning with rep- resentations: Contextual generalization of trained transformers,
T. Yang, Y . Huang, Y . Lianget al., “In-context learning with rep- resentations: Contextual generalization of trained transformers,”Proc. NIPS’2024, vol. 37, pp. 85 867–85 898, 2024
2024
-
[36]
In-context retrieval-augmented language models,
O. Ram, Y . Levine, I. Dalmedigoset al., “In-context retrieval-augmented language models,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 1316–1331, 2023
2023
-
[37]
LLM-based retrieval- augmented generation: a novel framework for resource optimization in 6g and beyond wireless networks,
H. M. A. Zeeshan, M. Umer, M. Akbaret al., “LLM-based retrieval- augmented generation: a novel framework for resource optimization in 6g and beyond wireless networks,”IEEE Commun. Mag., vol. 63, no. 10, pp. 60–67, 2025
2025
-
[38]
Retrieval-augmented generation for genai-enabled semantic communications,
S. Tang, R. Zhang, Y . Yanet al., “Retrieval-augmented generation for genai-enabled semantic communications,”IEEE Wireless Commun., 2025
2025
-
[39]
A retrieval-assisted framework for wireless localization,
H. Huang, G. Pan, K. Huanget al., “A retrieval-assisted framework for wireless localization,”arXiv preprint arXiv:2603.06158, 2026
-
[40]
CSI2Vec: Towards a universal CSI feature representation for positioning and channel charting,
V . Palhares, S. Taner, and C. Studer, “Csi2vec: Towards a universal CSI feature representation for positioning and channel charting,”arXiv preprint arXiv:2506.05237, 2025
-
[41]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmaret al., “Attention is all you need,” inProc. NIPS’2017, vol. 30, 2017
2017
-
[42]
“Sionna,” https://nvlabs.github.io/sionna/
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.