A Blended Likelihood Approach for Achieving Fairness Using Naive Bayes
Pith reviewed 2026-06-30 11:52 UTC · model grok-4.3
The pith
The BMNB classifier uses blended likelihoods and adaptive thresholding to achieve near-ideal fairness metrics in Naive Bayes models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The BMNB classifier employs an in-processing blended likelihood approach with tunable alpha to combine group-specific and pooled likelihood estimates, paired with post-processing output calibration using adaptive thresholding, resulting in DI values of 1.000, 1.171, and 0.997 and EOD values of -0.217, -0.226, and -0.053 on the Adult, ProPublica, and Framingham datasets respectively, while preserving computational efficiency, as confirmed by ablation studies showing the combination is superior.
What carries the argument
Blended likelihood approach that mixes group-specific and pooled estimates via the blending parameter alpha to adjust class probabilities in Naive Bayes.
If this is right
- Ablation studies confirm the combination of blended likelihood and adaptive thresholding is superior to either alone.
- The classifier preserves the computational efficiency of traditional Naive Bayes.
- Fairness metrics reach near-ideal levels on Adult, ProPublica, and Framingham datasets.
- The method integrates both in-processing and post-processing steps for bias mitigation.
Where Pith is reading between the lines
- This blending strategy could be tested on other probabilistic models for similar fairness gains.
- Automated selection of alpha might make the approach more practical for deployment.
- The method assumes access to group labels during training, which may limit use in some privacy-sensitive settings.
- Further experiments on additional real-world datasets would help establish broader applicability.
Load-bearing premise
The blending parameter alpha can be selected to deliver the reported fairness levels without overfitting to these particular datasets or needing protected group labels during inference.
What would settle it
Measuring DI and EOD on a fourth dataset with similar structure but shifted distributions to see if they stay within 0.8-1.2 for DI and under 0.1 in absolute value for EOD.
Figures
read the original abstract
Concerns about algorithmic bias and fairness have increased as artificial intelligence has been incorporated into high-stakes decision-making. Traditional Naive Bayes classifiers, while efficient and interpretable, lack fairness-awareness mechanisms and perpetuate historical biases in sensitive domains such as hiring, credit scoring, and criminal justice. This study develops a fairness-aware extension of the Naive Bayes classifier that mitigates bias while maintaining computational efficiency. We propose the Bias Mitigating Naive Bayes (BMNB) classifier, integrating in-processing and post-processing interventions. The in-processing stage employs a blended likelihood approach combining group-specific and pooled likelihood estimates through a tunable blending parameter alpha to balance fairness and accuracy. The post-processing stage applies output calibration with adaptive thresholding to fine-tune group-specific decision boundaries. Experimental results indicate that BMNB attains Disparate Impact (DI) values of 1.000, 1.171, and 0.997 and Equal Opportunity Difference (EOD) values of -0.217, -0.226, and -0.053 on the Adult, ProPublica, and Framingham datasets, respectively, while maintaining computational efficiency. Ablation studies confirm that the combination of blended likelihood and adaptive thresholding yields superior performance compared to either technique in isolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Bias Mitigating Naive Bayes (BMNB) classifier, extending standard Naive Bayes with an in-processing blended likelihood that combines group-specific and pooled estimates via a tunable parameter alpha, plus a post-processing stage using adaptive thresholding. It reports DI values of 1.000, 1.171, and 0.997 together with EOD values of -0.217, -0.226, and -0.053 on the Adult, ProPublica, and Framingham datasets, respectively, while claiming computational efficiency and superiority via ablation studies.
Significance. If the experimental claims hold under proper validation, the work would supply a simple, interpretable, and efficient fairness intervention for a classical classifier. The blended-likelihood idea is a plausible way to trade off group-specific and global statistics, and the combination with adaptive thresholding is a reasonable design choice. However, the absence of information on alpha selection, the apparent dependence on test-time group labels, and lack of statistical rigor in the reported metrics substantially weaken the evidential support for the central performance claims.
major comments (3)
- [Abstract] Abstract: the reported DI and EOD values are presented without any description of how the blending parameter alpha is selected, whether it is tuned on validation data, cross-validated, or chosen post hoc to match the target fairness numbers. This information is load-bearing for assessing whether the fairness metrics reflect genuine generalization rather than fitting to the reported targets.
- [Abstract] Abstract (in-processing stage description): computing the group-specific likelihood term for any test instance requires the sensitive-attribute value of that instance. The manuscript provides no indication that inference is performed group-blind (e.g., by marginalizing over the sensitive attribute or falling back to the pooled model), which directly constrains the method's applicability in the group-agnostic deployment settings that are standard for many fairness use cases.
- [Experimental results] Experimental results paragraph: the specific metric values are given without error bars, results over multiple random seeds, or statistical significance tests. This omission makes it impossible to judge whether the claimed superiority over isolated techniques is robust or merely an artifact of a single run.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and indicate planned revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported DI and EOD values are presented without any description of how the blending parameter alpha is selected, whether it is tuned on validation data, cross-validated, or chosen post hoc to match the target fairness numbers. This information is load-bearing for assessing whether the fairness metrics reflect genuine generalization rather than fitting to the reported targets.
Authors: We agree the abstract lacks detail on alpha selection. The full manuscript describes alpha as a tunable hyperparameter chosen to balance fairness and accuracy. We will revise the abstract and methods to explicitly state that alpha is selected via grid search with cross-validation on a held-out validation set, ensuring the metrics reflect a principled process rather than post-hoc adjustment. revision: yes
-
Referee: [Abstract] Abstract (in-processing stage description): computing the group-specific likelihood term for any test instance requires the sensitive-attribute value of that instance. The manuscript provides no indication that inference is performed group-blind (e.g., by marginalizing over the sensitive attribute or falling back to the pooled model), which directly constrains the method's applicability in the group-agnostic deployment settings that are standard for many fairness use cases.
Authors: The observation is correct: the current blended likelihood formulation requires the sensitive attribute at test time. This limits applicability in fully group-agnostic settings. We will revise the manuscript to state this assumption explicitly and add discussion of a group-blind extension via marginalization over the training distribution of the sensitive attribute. revision: partial
-
Referee: [Experimental results] Experimental results paragraph: the specific metric values are given without error bars, results over multiple random seeds, or statistical significance tests. This omission makes it impossible to judge whether the claimed superiority over isolated techniques is robust or merely an artifact of a single run.
Authors: We concur that variability measures are essential. The reported values come from single runs. We will revise the experimental section to include averages and standard deviations over multiple random seeds along with statistical significance tests against baselines and ablations to substantiate the superiority claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided text describes a proposed BMNB classifier using a tunable blending parameter alpha in a blended likelihood and reports empirical fairness metrics (DI and EOD) on three datasets. No equations, self-citations, or derivation steps are shown that reduce a claimed result to its inputs by construction (e.g., no fitted parameter explicitly renamed as an independent prediction, no self-definitional loop, and no load-bearing self-citation). The central content is an experimental method proposal and results rather than a first-principles derivation that loops back on itself. The tuning of alpha is presented as part of the approach to balance fairness and accuracy, but without specific reduction exhibited, this does not meet the criteria for circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (2)
- domain assumption Features are conditionally independent given the class label
- domain assumption Disparate Impact and Equal Opportunity Difference are appropriate and sufficient measures of fairness
Reference graph
Works this paper leans on
-
[1]
Introduction ML systems are increasingly used in socially critical domains such as hiring, credit scoring, healthcare, and criminal justice, with issues of bias and fairness having emerged. Systems expected to make objective decisions have been shown to exhibit biased behaviour, potentially aggravating existing inequities embedded in historical data, lead...
-
[2]
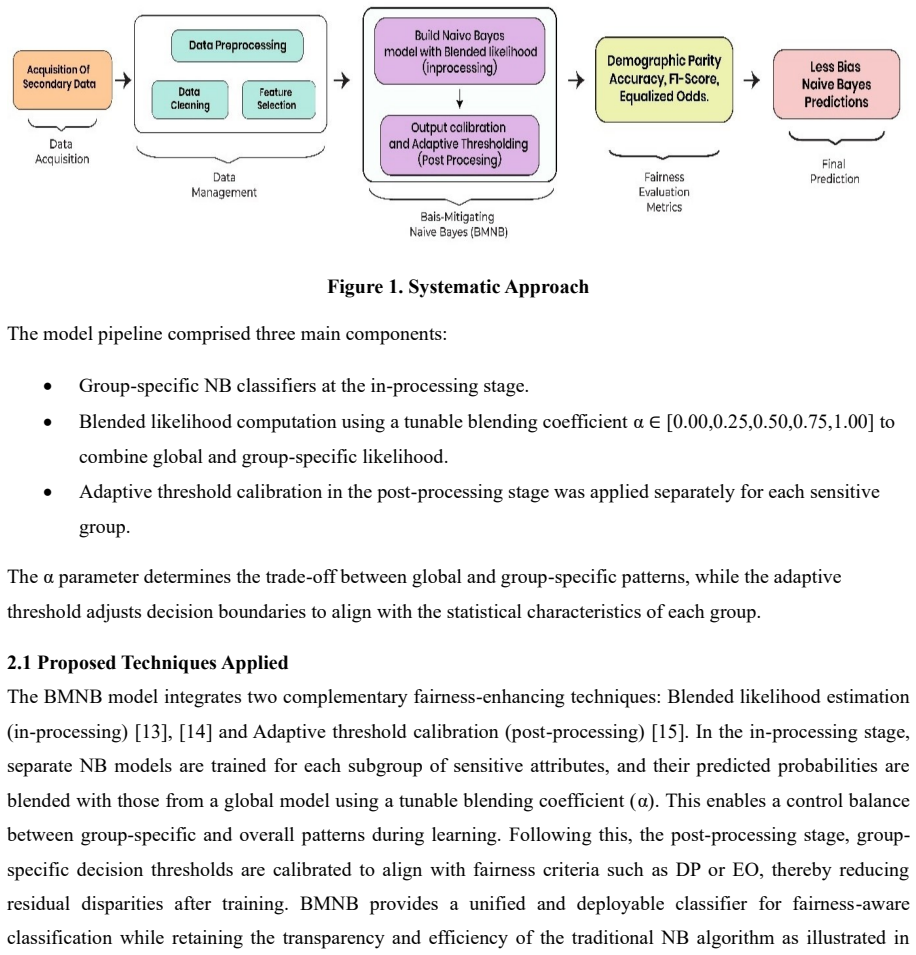
Figure 1
Proposed BMNB Model Figure 1 illustrates the systematic approach used in this study to address the algorithmic bias, highlighting the workflow from initial data acquisition and pre-processing through to model development and evaluation and finally a fair prediction. Figure 1. Systematic Approach The model pipeline comprised three main components: • Group-...
-
[3]
𝐺 = {𝑠𝑖 ∣ (𝑥𝑖, 𝑠𝑖) ∈ 𝑆𝑡𝑟𝑎𝑖𝑛}
-
[4]
𝐷𝑔𝑙𝑜𝑏𝑎𝑙 = (𝑋𝑡𝑟𝑎𝑖𝑛, 𝑌𝑡𝑟𝑎𝑖𝑛) = {(𝑥𝑖, 𝑦𝑖)}𝑖=1 𝑁𝑡𝑟𝑎𝑖𝑛
-
[5]
𝑀𝑔𝑙𝑜𝑏𝑎𝑙 = 𝑇𝑟𝑎𝑖𝑛𝑁𝐵(𝐷𝑔𝑙𝑜𝑏𝑎𝑙; 𝜀)
-
[6]
∀𝑔 ∈ 𝐺: 𝐷𝑔 = {(𝑥𝑖, 𝑦𝑖) ∣ 𝑠𝑖 = 𝑔, (𝑥𝑖, 𝑠𝑖, 𝑦𝑖 ) ∈ 𝑆𝑡𝑟𝑎𝑖𝑛} 𝑀𝑔 = 𝑇𝑟𝑎𝑖𝑛𝑁𝐵(𝐷𝑔; 𝜀)
-
[7]
𝐼𝑓 𝛼 𝑛𝑜𝑡 𝑝𝑟𝑜𝑣𝑖𝑑𝑒𝑑: 𝛼∗ = 𝐽(𝐴𝑐𝑐𝐶𝑉(𝛼), 𝐹𝑎𝑖𝑟𝐶𝑉(𝛼))𝛼∈𝛼𝑔𝑟𝑖𝑑 𝑎𝑟𝑔𝑚𝑎𝑥 𝐽(𝐴𝑐𝑐, 𝐹𝑎𝑖𝑟) = 𝜆 ⋅ 𝐴𝑐𝑐 + (1 − 𝜆) ⋅ 𝐹𝑎𝑖𝑟, 𝜆 ∈ [0,1] 𝛼 ← 𝛼∗
-
[8]
𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑝𝑟𝑜𝑏𝑎(𝑥𝑖), 𝑖𝑓 𝑔 ∉ 𝐺 𝑜𝑟 𝑀 𝑙𝑜𝑤𝑒𝑟 𝑠𝑢𝑝𝑜𝑟𝑡 𝑀𝑔
∀𝑥𝑖 ∈ 𝑋𝑡𝑒𝑠𝑡: 𝑔 = 𝑠𝑖 ∈ 𝑆𝑡𝑒𝑠𝑡 𝑃𝑔𝑟𝑜𝑢𝑝 = { 𝑀𝑔𝑙𝑜𝑏𝑎𝑙. 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑝𝑟𝑜𝑏𝑎(𝑥𝑖), 𝑖𝑓 𝑔 ∉ 𝐺 𝑜𝑟 𝑀 𝑙𝑜𝑤𝑒𝑟 𝑠𝑢𝑝𝑜𝑟𝑡 𝑀𝑔. 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑝𝑟𝑜𝑏𝑎(𝑥𝑖), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 𝑃𝑔𝑟𝑜𝑢𝑝 = 𝑀𝑔𝑙𝑜𝑏𝑎𝑙. 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑝𝑟𝑜𝑏𝑎(𝑥𝑖) 𝑃𝐵𝑀𝑁𝐵 = 𝑎𝑃𝑔𝑟𝑜𝑢𝑝 + (1 − 𝑎)𝑃𝑔𝑙𝑜𝑏𝑎𝑙 𝑦̂𝑖 = { 𝑎𝑟𝑔𝑚𝑎𝑥𝑦 𝑃𝐵𝑀𝑁𝐵[𝑦], 𝑖𝑓 𝑇𝑔 𝑛𝑜𝑡 𝑢𝑠𝑒𝑑 1, 𝑖𝑓 𝑃𝐵𝑀𝑁𝐵[𝑦𝑖] > 𝑇𝑔 𝑌𝑝𝑟𝑒𝑑 ⟵ 𝑌𝑝𝑟𝑒𝑑 ∪ {𝑦̂𝑖}
-
[9]
Group -specific thresholds are computed based on perf ormance metrics such as TPR and adapted to equalize the chosen fairness metrics across groups [17]
Return 𝑌𝑝𝑟𝑒𝑑 2.1.2 Output Calibration and Adaptive Thresholding Unlike conventional methods that use uniform thresholds for all groups, this approach adjusts thresholds separately for each sensitive group so that fairness criteria such as DP or EO are satisfied [24]. Group -specific thresholds are computed based on perf ormance metrics such as TPR and ada...
-
[10]
cost of fairn ess
Experiments and Results The BMNB classifier was implemented and tested on the Adult, ProPublica COMPAS, and Framingham datasets. The Adult dataset from the UCI Machine Learning Repository predicts income level, with gender serving as the sensitive attribute. The ProPublica COMPAS dataset is used for predicting recidivism risk and considers race as the sen...
1945
-
[11]
Acronyms and Abbreviations Machine learning (ML), Naïve Bayes (NB), Blended Likelihood Estimation (BLE), Adaptive Thresholding, Bias Mitigation, Bias Mitigating Naïve Bayes (BMNB), Equal Opportunity Difference (EOD), Disparate Impact (DI), Demographic Parity (DP), Equal Opportunity (EO), Statistical Parity Difference (SPD), True Positive Rate (TPR), False...
-
[12]
Conclusion and Future Works In this work, we propose a ready -to-implement classifier for practitioners seeking to improve fairness in NB classifiers. The BMNB classifier represents a novel approach to bias mitigation that combines the strengths of both in -processing and post -processing techniques, providing multiple layers of mitigation, unlike existin...
-
[13]
Abdul Lafeet Yussif : Methodology support, experimental validation, data preprocessing, software verification and writing (review and editing)
Author Contributions (Mandatory Section) John Arthur Junior : Conceptualization, methodology, software, implementation, experimental design, data curation and writing (draft preparation). Abdul Lafeet Yussif : Methodology support, experimental validation, data preprocessing, software verification and writing (review and editing). Maame G. Asante-Mensah: S...
-
[14]
Funding Not applicable
-
[15]
Ethical statement Not applicable
-
[16]
Data availability statement The data used in this study are publicly available benchmark datasets and were not generated by the authors. Specifically, the Adult Income dataset is available from the UCI Machine Learning Repository, the ProPublica COMPAS dataset is available from ProPublica’s public data repository, and the Framingham Heart Study dataset is...
-
[17]
Conflict of Interest The authors declare no conflict of interest
-
[18]
Acknowledgments We would like to express our profound gratitude to the researchers in our department, for their invaluable guidance, constructive feedback, and continuous encouragement throughout the course of this study. We are also grateful to the faculty and staff of the Department of Computer Science and Information Technology, University of Cape Coas...
-
[19]
Algorithmic fairness,
D. Pessach and E. Shmueli, “Algorithmic fairness,” in Machine Learning for Data Science Handbook: Data Mining and Knowledge Discovery Handbook, Springer, 2023, pp. 867 –886
2023
-
[20]
Bias and discrimination in AI: a cross - disciplinary perspective,
X. Ferrer, T. Van Nuenen, J. M. Such, M. Coté, and N. Criado, “Bias and discrimination in AI: a cross - disciplinary perspective,” arXiv preprint arXiv:2008.07309, 2020
-
[21]
A brief review on algorithmic fairness,
X. Wang, Y. Zhang, and R. Zhu, “A brief review on algorithmic fairness,” Management System Engineering, vol. 1, no. 1, p. 7, 2022
2022
-
[22]
The accuracy, fairness, and limits of predicting recidivism,
J. Dressel and H. Farid, “The accuracy, fairness, and limits of predicting recidivism,” Sci Adv, vol. 4, no. 1, p. eaao5580, 2018
2018
-
[23]
Yeung, I
D. Yeung, I. Khan, N. Kalra, and O. Osoba, Identifying systemic bias in the acquisition of machine learning decision aids for law enforcement applications. JSTOR, 2021
2021
-
[24]
Algorithmic bias in recidivism prediction: A causal perspective (student abstract),
A. Khademi and V. Honavar, “Algorithmic bias in recidivism prediction: A causal perspective (student abstract),” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 13839 –13840
2020
-
[25]
Using the Toulmin Model of Argumentation to Explore the Differences in Human and Automated Hiring Decisions.,
H. Bubakr and C. Baber, “Using the Toulmin Model of Argumentation to Explore the Differences in Human and Automated Hiring Decisions.,” in VISIGRAPP (2: HUCAPP), 2020, pp. 211 –216
2020
-
[26]
Removing biased data to improve fairness and accuracy,
S. Verma, M. Ernst, and R. Just, “Removing biased data to improve fairness and accuracy,” arXiv preprint arXiv:2102.03054, 2021
-
[27]
In-processing modeling techniques for machine learning fairness: A survey,
M. Wan, D. Zha, N. Liu, and N. Zou, “In-processing modeling techniques for machine learning fairness: A survey,” ACM Trans Knowl Discov Data, vol. 17, no. 3, pp. 1 –27, 2023
2023
-
[28]
Barocas, M
S. Barocas, M. Hardt, and A. Narayanan, Fairness and machine learning: Limitations and opportunities. MIT press, 2023
2023
-
[29]
On fairness and calibration,
G. Pleiss, M. Raghavan, F. Wu, J. Kleinberg, and K. Q. Weinberger, “On fairness and calibration,” Adv Neural Inf Process Syst, vol. 30, 2017
2017
-
[30]
Using sensitive personal data may be necessary for avoiding discrimination in data-driven decision models,
I. Žliobaitė and B. Custers, “Using sensitive personal data may be necessary for avoiding discrimination in data-driven decision models,” Artif Intell Law (Dordr), vol. 24, no. 2, pp. 183 –201, 2016
2016
-
[31]
Fairness-aware naive Bayes classifier for data with multiple sensitive features,
S. Boulitsakis-Logothetis, “Fairness-aware naive Bayes classifier for data with multiple sensitive features,” arXiv preprint arXiv:2202.11499, 2022
-
[32]
Learning fair naive bayes classifiers by discovering and eliminating discrimination patterns,
Y. Choi, G. Farnadi, B. Babaki, and G. Van den Broeck, “Learning fair naive bayes classifiers by discovering and eliminating discrimination patterns,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 10077–10084
2020
-
[34]
The optimality of naive Bayes,
H. Zhang, “The optimality of naive Bayes,” Aa, vol. 1, no. 2, p. 3, 2004
2004
-
[35]
Group-aware threshold adaptation for fair classification,
T. Jang, P. Shi, and X. Wang, “Group-aware threshold adaptation for fair classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022, pp. 6988 –6995
2022
-
[36]
Fairness and bias in artificial intelligence: A brief survey of sources, impacts, and mitigation strategies,
E. Ferrara, “Fairness and bias in artificial intelligence: A brief survey of sources, impacts, and mitigation strategies,” Sci, vol. 6, no. 1, p. 3, 2024
2024
-
[37]
C. J. S. Barr, O. Erdelyi, P. D. Docherty, and R. C. Grace, “A Review of Fairness and A Practical Guide to Selecting Context-Appropriate Fairness Metrics in Machine Learning,” arXiv preprint arXiv:2411.06624, 2024
-
[38]
Certifying and removing disparate impact
S. Friedler, C. Scheidegger, and S. Venkatasubramanian, “Certifying and removing disparate impact,” arXiv preprint arXiv:1412.3756, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
Fairness Score and process standardization: framework for fairness certification in artificial intelligence systems,
A. Agarwal, H. Agarwal, and N. Agarwal, “Fairness Score and process standardization: framework for fairness certification in artificial intelligence systems,” AI and Ethics, vol. 3, no. 1, pp. 267 –279, 2023
2023
-
[40]
Fairness in machine learning: Against false positive rate equality as a measure of fairness,
R. Long, “Fairness in machine learning: Against false positive rate equality as a measure of fairness,” J Moral Philos, vol. 19, no. 1, pp. 49–78, 2021
2021
-
[41]
Leveraging labeled and unlabeled data for consistent fair binary classification,
E. Chzhen, C. Denis, M. Hebiri, L. Oneto, and M. Pontil, “Leveraging labeled and unlabeled data for consistent fair binary classification,” Adv Neural Inf Process Syst, vol. 32, 2019
2019
-
[42]
Hardt, M., & Negri, A. (2009). Commonwealth. Harvard University Press
2009
-
[43]
D., Nilforoshan, H., Shroff, R., & Goel, S
Corbett-Davies, S., Gaebler, J. D., Nilforoshan, H., Shroff, R., & Goel, S. (2023). The measure and mismeasure of fairness. Journal of Machine Learning Research, 24(312), 1 -117
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.