GraphGP: Scalable Gaussian Processes with Vecchia's Approximation
Pith reviewed 2026-06-27 10:24 UTC · model grok-4.3
The pith
GraphGP implements Vecchia's approximation on GPU to let Gaussian processes scale to nearly a billion points with linear time and memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
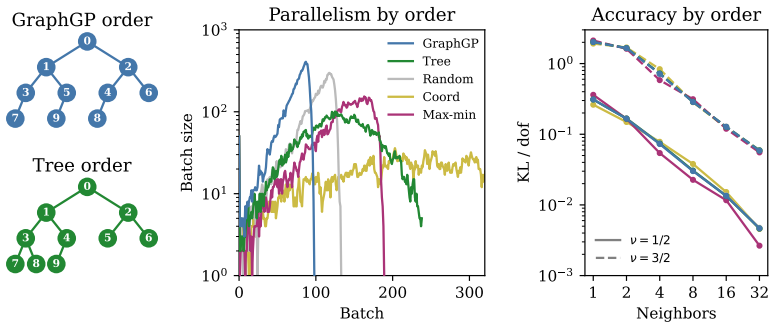
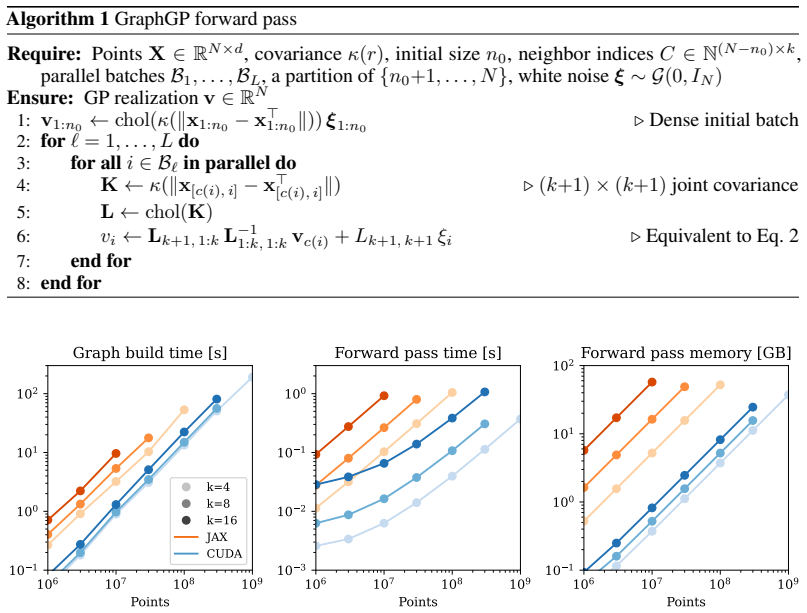
GraphGP is a GPU algorithm for Vecchia's approximation that scales to nearly a billion parameters with linear time and memory requirements, handling arbitrary point distributions over a large dynamic range. Its key contributions are a bit-reversed k-d tree ordering that allows efficient neighbor searches while also maximizing batch parallelism, and a differentiable CUDA implementation that is substantially faster and more memory efficient than a pure JAX baseline. The method supplies the building blocks for inference, including forward generation, inverse application, log-determinant, and kernel parameter derivatives.
What carries the argument
The bit-reversed k-d tree ordering paired with a differentiable CUDA implementation of the sparse precision matrix formed by conditioning each point on its k nearest neighbors.
If this is right
- All standard Gaussian-process operations become feasible at scales up to nearly a billion points.
- The same ordering and CUDA kernels support both simulation and parameter inference without quadratic memory use.
- Arbitrary point distributions, including those with large dynamic range, can be handled without special preprocessing.
- Kernel hyperparameters can be optimized by back-propagating through the log-determinant and other terms.
Where Pith is reading between the lines
- The same neighbor-ordering technique could be reused inside other sparse Gaussian-process approximations that rely on local conditioning.
- Because the implementation is differentiable, it could serve as a drop-in module inside larger models that combine Gaussian processes with neural networks.
- Linear scaling opens the possibility of real-time or online updating of Gaussian-process fields on streaming spatial data.
Load-bearing premise
The kernels must be stationary with correlations that decay rapidly enough with distance for conditioning on only k nearest neighbors to produce an accurate sparse precision matrix.
What would settle it
Measure wall-clock time and approximation error while increasing N from 10^6 to 10^9 on a stationary decaying kernel; linear scaling together with stable error would support the claim, while either super-linear growth or rapidly worsening error would falsify it.
Figures
read the original abstract
Gaussian processes are a powerful tool for modeling continuous fields, but their naive $\mathcal{O}(N^3)$ computational cost and $\mathcal{O}(N^2)$ memory requirement often limit their practical use. Vecchia's approximation is a sparse precision matrix approximation for stationary, decaying kernels that conditions each point only on its $k$ nearest neighbors. We present GraphGP, a GPU algorithm for Vecchia's approximation that scales to nearly a billion parameters with linear time and memory requirements, handling arbitrary point distributions over a large dynamic range. Our key contributions are (1) a bit-reversed k-d tree ordering that allows efficient neighbor searches while also maximizing batch parallelism, and (2) a differentiable CUDA implementation, which is substantially faster and more memory efficient than our pure JAX baseline. GraphGP provides the building blocks for inference, including forward generation, inverse application, log-determinant, and kernel parameter derivatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GraphGP, a GPU algorithm implementing Vecchia's approximation for Gaussian processes on stationary kernels with decaying correlations. It conditions each point on its k nearest neighbors to obtain a sparse precision matrix, using a bit-reversed k-d tree ordering for efficient neighbor search and batch parallelism, together with a differentiable CUDA kernel implementation. The claimed contributions include forward generation, inverse application, log-determinant evaluation, and kernel-parameter derivatives, all asserted to achieve linear time and memory scaling up to nearly 10^9 parameters for arbitrary point distributions.
Significance. If the linear scaling and numerical accuracy claims are substantiated, GraphGP would supply practical building blocks for large-scale GP inference on GPUs, extending Vecchia-type approximations to problem sizes that are currently inaccessible. The emphasis on a fully differentiable CUDA backend is a concrete strength for downstream use in gradient-based optimization frameworks.
minor comments (3)
- [Abstract] Abstract and §1: the performance claims (linear scaling to ~10^9 parameters) are stated without reference to the specific benchmark tables or figures that presumably support them; adding explicit cross-references would improve readability.
- [§3.2] §3.2: the bit-reversed k-d tree construction is described at a high level; a short pseudocode block or complexity breakdown for the ordering step itself would clarify that it remains O(N log N) and does not introduce a hidden quadratic term.
- The manuscript should include at least one table or figure that reports wall-clock time, memory footprint, and approximation error versus N for fixed k on both synthetic and real point sets, with direct comparison to a pure-JAX or CPU Vecchia baseline.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of GraphGP, the significance of the linear-scaling claims, and the recommendation for minor revision. The report contains no enumerated major comments.
Circularity Check
No significant circularity in algorithmic implementation
full rationale
The paper describes an algorithmic GPU implementation of the established Vecchia approximation (conditioning on k-nearest neighbors for sparse precision matrices of stationary kernels), with contributions limited to bit-reversed k-d tree ordering for parallelism and a differentiable CUDA kernel. No derivation chain, fitted parameters, or self-citations reduce the claimed linear scaling or efficiency claims to inputs by construction; the work is self-contained as an engineering optimization preserving the standard O(N k^2) complexity of the prior approximation without introducing circular reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- k (neighbor count)
axioms (1)
- domain assumption Kernels are stationary and correlations decay with distance
Forward citations
Cited by 1 Pith paper
-
The Via Project: Overview of the Science, Instrument, and Survey
The Via Project is a planned five-year dual-hemisphere spectroscopic survey targeting over 2 million stars with 100 m/s RV stability and transient spectroscopy to r~24 using instruments on MMT and Magellan/Clay telesc...
Reference graph
Works this paper leans on
-
[1]
2024, A&A, 685, A82, doi: 10.1051/0004-6361/202347628
Edenhofer, Gordian and Zucker, Catherine and Frank, Philipp and Saydjari, Andrew K. and Speagle, Joshua S. and Finkbeiner, Douglas and En. A parsec-scale Galactic 3D dust map out to 1.25 kpc from the Sun , volume=. 2024 , pages=. doi:10.1051/0004-6361/202347628 , journal=
-
[2]
Huan, Stephen and Guinness, Joseph and Katzfuss, Matthias and Owhadi, Houman and Sch\". Sparse Inverse Cholesky Factorization of Dense Kernel Matrices by Greedy Conditional Selection , volume=. SIAM/ASA Journal on Uncertainty Quantification , publisher=. 2025 , pages=. doi:10.1137/23m1606253 , number=
-
[3]
and Guerdi, Massin and Scheel-Platz, Lukas I
Edenhofer, Gordian and Frank, Philipp and Roth, Jakob and Leike, Reimar H. and Guerdi, Massin and Scheel-Platz, Lukas I. and Guardiani, Matteo and Eberle, Vincent and Westerkamp, Margret and En. Re-Envisioning Numerical Information Field Theory (. Journal of Open Source Software , publisher=. 2024 , pages=. doi:10.21105/joss.06593 , number=
-
[4]
McCallum, Lewis and Frank, Philipp and Hutschenreuter, Sebastian and Benjamin, Robert and Booth, Rebecca A and Clark, Susan E and Haverkorn, Marijke and Hill, Alex S and Mertsch, Philipp and Ordog, Anna and Saydjari, Andrew K and West, Jennifer , year=. The radial component of the local Galactic magnetic field in 3D , volume=. Monthly Notices of the Royal...
-
[5]
Geometric Variational Inference , volume=
Frank, Philipp and Leike, Reimar and En. Geometric Variational Inference , volume=. Entropy , publisher=. 2021 , pages=. doi:10.3390/e23070853 , number=
-
[6]
Knollm. Metric. arXiv e-prints , DOI=
-
[7]
arXiv e-prints , DOI=
A Three-Dimensional Tomographic Reconstruction of the Galactic Cosmic-Ray Proton Density , author=. arXiv e-prints , DOI=
-
[8]
Pan, Qilong and Abdulah, Sameh and Genton, Marc G. and Keyes, David E. and Ltaief, Hatem and Sun, Ying , journal=. doi:10.48550/arXiv.2403.07412 , year=
-
[9]
Leike, R. H. and Edenhofer, G. and Knollm. The Galactic 3D large-scale dust distribution via. arXiv e-prints , DOI=
-
[10]
Implementation and Analysis of
James, Zachary and Guinness, Joseph , journal=. Implementation and Analysis of. doi:10.48550/arXiv.2407.02740 , year=
-
[11]
doi:10.48550/arXiv.2211.00120 , year=
Wald, Ingo , journal=. doi:10.48550/arXiv.2211.00120 , year=
-
[12]
arXiv e-prints , DOI=
A Stack-Free Traversal Algorithm for Left-Balanced k-d Trees , author=. arXiv e-prints , DOI=
-
[13]
and Frank, Philipp and En
Edenhofer, Gordian and Leike, Reimar H. and Frank, Philipp and En. Sparse Kernel. arXiv e-prints , DOI=
-
[14]
Vecchia, A. V. , year=. Estimation and Model Identification for Continuous Spatial Processes , volume=. Journal of the Royal Statistical Society Series B: Statistical Methodology , publisher=. doi:10.1111/j.2517-6161.1988.tb01729.x , number=
-
[15]
Kernel Interpolation for Scalable Structured
Wilson, Andrew and Nickisch, Hannes , booktitle=. Kernel Interpolation for Scalable Structured. 2015 , publisher=
2015
-
[16]
Rasmussen, Carl Edward and Williams, Christopher K. I. , year=
-
[17]
Journal of Agricultural, Biological and Environmental Statistics , publisher=
Katzfuss, Matthias and Guinness, Joseph and Gong, Wenlong and Zilber, Daniel , year=. Journal of Agricultural, Biological and Environmental Statistics , publisher=. doi:10.1007/s13253-020-00401-7 , number=
-
[18]
Permutation and Grouping Methods for Sharpening
Guinness, Joseph , year=. Permutation and Grouping Methods for Sharpening. Technometrics , publisher=. doi:10.1080/00401706.2018.1437476 , number=
-
[19]
Variational Learning of Inducing Variables in Sparse
Titsias, Michalis , booktitle=. Variational Learning of Inducing Variables in Sparse. 2009 , publisher=
2009
-
[20]
Bradbury, James and Frostig, Roy and Hawkins, Peter and Johnson, Matthew James and Leary, Chris and Maclaurin, Dougal and Necula, George and Paszke, Adam and Vander
-
[21]
Smith, S. P. , year=. Differentiation of the. Journal of Computational and Graphical Statistics , publisher=. doi:10.1080/10618600.1995.10474671 , number=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.