fARfetch: Enabling Collocated AR-HRC in Large Visually Diverse Environments with VLM-Driven AR Content Adaptation
Pith reviewed 2026-06-25 23:43 UTC · model grok-4.3
The pith
fARfetch uses vision-language models to adapt AR visuals so humans and robots can collaborate effectively across large outdoor spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
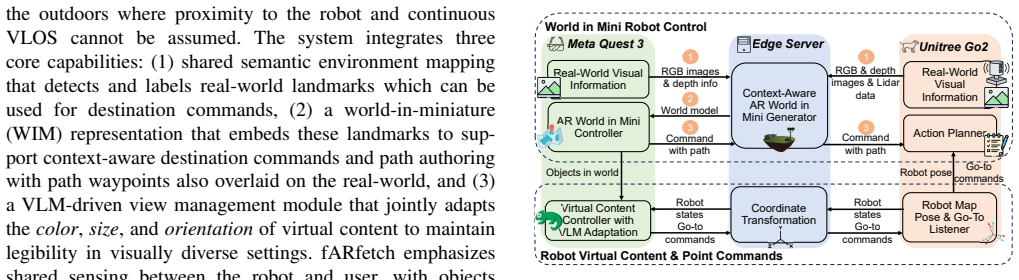
The paper establishes that a combination of shared semantic environment mapping, a context-aware world-in-miniature interface, and vision-language-model-driven adaptation of AR content color, size, and orientation enables collocated human-robot collaboration to remain usable in large visually diverse outdoor environments, as shown by significantly improved task speed and reduced workload in a real-world 30.5 m inspection study.
What carries the argument
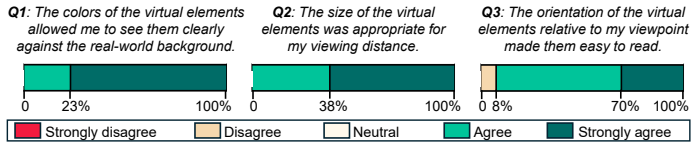
VLM-driven AR view management that jointly adapts virtual content color, size, and orientation to maintain legibility.
If this is right
- Landmark-grounded go-to commands become usable because detected landmarks appear as AR anchors visible to both human and robot.
- Fine-grained path authoring is supported through the miniature representation without requiring the operator to walk the full route.
- Virtual overlays stay readable at long distances and across varied backgrounds, removing a key barrier to outdoor AR-HRC.
- Overall operator workload decreases measurably in mental demand, temporal demand, and frustration during extended tasks.
Where Pith is reading between the lines
- The same adaptation loop could be applied to indoor scenes with rapidly changing lighting or to mobile robots operating in construction zones.
- Removing the need for manual AR tuning might let non-expert users direct robots in new environments without prior calibration.
- Extending the shared mapping to include dynamic objects could support collaboration in settings where both people and robots move continuously.
- If the VLM adaptation proves robust, similar view-management logic might transfer to other mixed-reality interfaces that must handle scale and visual diversity.
Load-bearing premise
The vision-language model can adapt AR content to preserve legibility without introducing unacceptable latency or errors across the range of outdoor visual conditions.
What would settle it
A direct test showing whether legibility scores drop or error rates rise when the same 30.5 m task is repeated under extreme lighting shifts such as full sun versus deep shadow.
Figures




read the original abstract
Augmented Reality (AR) can improve collocated human-robot collaboration by making robot state and intent visible and enabling intuitive control, yet large, visually diverse environments like the outdoors challenge both interaction and content legibility, especially at long distances and beyond visual line of sight. We present fARfetch, an AR-HRC system that integrates (i) shared semantic environment mapping across an AR headset and robot that visualizes detected landmarks in AR to support landmark-grounded go-to commands, (ii) a context-aware world-in-miniature representation of the shared environment for fine-grained path authoring, and (iii) vision-language-model driven AR view management that jointly adapts virtual content color, size, and orientation to maintain legibility in large visually diverse environments. We implement fARfetch with a Meta Quest 3 headset and Unitree Go2 quadruped robot, and conduct a within-subjects user study (N=13) on a real-world large-scale (30.5m) outdoor inspection task. fARfetch yielded significantly faster completion times than a non-AR baseline (66%) and significantly lower workload in mental demand (-43%), temporal demand (-34%), and frustration (-66%). A custom legibility survey indicated fARfetch effectively maintained virtual content legibility in the large outdoor environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents fARfetch, an AR-HRC system for collocated collaboration in large visually diverse outdoor environments. It integrates (i) shared semantic environment mapping between AR headset and robot for landmark-grounded commands, (ii) a context-aware world-in-miniature for path authoring, and (iii) VLM-driven joint adaptation of virtual content color, size, and orientation to preserve legibility. Implemented on a Meta Quest 3 and Unitree Go2, a within-subjects user study (N=13) on a real 30.5 m outdoor inspection task reports 66% faster completion times versus a non-AR baseline, workload reductions (mental demand -43%, temporal demand -34%, frustration -66%), and positive results on a custom legibility survey.
Significance. If the VLM adaptation component functions reliably, the work offers a practical contribution to outdoor AR-HRC by addressing legibility at distance and under visual variation. The real-hardware, outdoor evaluation with statistically significant time and workload gains provides ecological validity that is uncommon in AR robotics studies. The combination of mapping, miniature, and adaptive view management could inform systems for inspection, search-and-rescue, and field robotics where operators must maintain awareness beyond line-of-sight.
major comments (2)
- [User Study Results] User Study Results: The central performance claims (66% faster completion and workload reductions) are presented as resulting from the full fARfetch pipeline, yet the manuscript reports no quantitative VLM metrics—adaptation accuracy, failure rate, or latency—under the actual outdoor lighting, vegetation, and background conditions of the 30.5 m task. This omission leaves open the possibility that observed gains derive primarily from components (i) and (ii) rather than the VLM adaptation in (iii).
- [VLM-Driven AR Content Adaptation] VLM-Driven AR Content Adaptation section: The legibility claims rest on a custom survey outcome, but the paper provides no description of the VLM prompting strategy, model choice, or handling of edge cases (e.g., low light, high contrast vegetation). Without these details or failure-mode analysis, it is difficult to assess whether the adaptation introduces unacceptable latency or errors across the tested visual diversity.
minor comments (2)
- [Abstract] Abstract and Results: The abstract states results are 'significantly' different but omits the statistical test, degrees of freedom, and exact p-values; these should be supplied for reproducibility.
- [Implementation] Implementation: The description of the shared mapping and miniature components would benefit from a brief diagram or pseudocode showing data flow between headset and robot to clarify how semantic landmarks are synchronized.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarification regarding the VLM component's evaluation and implementation details. We address each major comment below and commit to revisions that strengthen the paper without misrepresenting the current work.
read point-by-point responses
-
Referee: [User Study Results] User Study Results: The central performance claims (66% faster completion and workload reductions) are presented as resulting from the full fARfetch pipeline, yet the manuscript reports no quantitative VLM metrics—adaptation accuracy, failure rate, or latency—under the actual outdoor lighting, vegetation, and background conditions of the 30.5 m task. This omission leaves open the possibility that observed gains derive primarily from components (i) and (ii) rather than the VLM adaptation in (iii).
Authors: We agree that the user study evaluates the integrated fARfetch system against a non-AR baseline and does not provide isolated quantitative metrics for the VLM adaptation component. The 66% time reduction and workload improvements are reported for the complete pipeline, which is consistent with the ecological validity goal of the outdoor evaluation. However, this leaves the specific contribution of component (iii) unquantified. In the revision, we will add a new subsection reporting VLM-specific metrics collected during the study (adaptation accuracy, failure rate, and latency) under the actual 30.5 m outdoor conditions to better attribute the observed gains. revision: yes
-
Referee: [VLM-Driven AR Content Adaptation] VLM-Driven AR Content Adaptation section: The legibility claims rest on a custom survey outcome, but the paper provides no description of the VLM prompting strategy, model choice, or handling of edge cases (e.g., low light, high contrast vegetation). Without these details or failure-mode analysis, it is difficult to assess whether the adaptation introduces unacceptable latency or errors across the tested visual diversity.
Authors: We accept that the current manuscript omits key implementation details of the VLM-driven adaptation. The legibility survey results are presented without supporting technical description. In the revised manuscript, we will expand the VLM-Driven AR Content Adaptation section to specify the VLM model, the prompting strategy for jointly adapting color, size, and orientation, and include a failure-mode analysis drawn from the outdoor trials (including low-light and vegetation contrast cases) along with measured latency. revision: yes
Circularity Check
No significant circularity: empirical user-study results with no derivation chain
full rationale
The paper presents an AR-HRC system evaluated via a within-subjects user study (N=13) on a 30.5m outdoor task, reporting completion time and workload metrics directly from participant measurements. No equations, parameter fitting, or mathematical derivations appear in the provided abstract or description. Claims rest on empirical outcomes rather than any self-referential reduction of predictions to inputs or load-bearing self-citations. The VLM adaptation component is described as implemented but its reliability is assessed only via a custom legibility survey; this is a measurement, not a circular derivation. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
May The Force be With You: Cloning Distant Objects to Improve Medium-Field Interactions in Augmented Reality
Danish Nisar Ahmed Tamboli et al. “May The Force be With You: Cloning Distant Objects to Improve Medium-Field Interactions in Augmented Reality”. In: Proc. IEEE VR. 2025
2025
-
[2]
Evaluating Transitive Per- ceptual Effects Between Virtual Entities in Outdoor Augmented Reality
Juanita Benjamin et al. “Evaluating Transitive Per- ceptual Effects Between Virtual Entities in Outdoor Augmented Reality”. In:Proc. IEEE VR. 2024
2024
-
[3]
ARROCH: Augmented Reality for Robots Collaborating with a Human
Kishan Chandan et al. “ARROCH: Augmented Reality for Robots Collaborating with a Human”. In:Proc. IEEE ICRA. 2021
2021
-
[4]
A 3D Mixed Reality Interface for Human-Robot Teaming
Jiaqi Chen et al. “A 3D Mixed Reality Interface for Human-Robot Teaming”. In:Proc. IEEE ICRA. 2024
2024
-
[5]
PinpointFly: An Egocentric Position-control Drone Interface using Mobile AR
Linfeng Chen et al. “PinpointFly: An Egocentric Position-control Drone Interface using Mobile AR”. In:Proc. ACM CHI. 2021
2021
-
[6]
Exploring User Reactions and Mental Models Towards Perceptual Manipulation Attacks in Mixed Reality
Kaiming Cheng et al. “Exploring User Reactions and Mental Models Towards Perceptual Manipulation Attacks in Mixed Reality”. In:Proc. USENIX Security. 2023
2023
-
[7]
SemanticAdapt: Optimization- based Adaptation of Mixed Reality Layouts Leverag- ing Virtual-Physical Semantic Connections
Yifei Cheng et al. “SemanticAdapt: Optimization- based Adaptation of Mixed Reality Layouts Leverag- ing Virtual-Physical Semantic Connections”. In:Proc. ACM UIST. 2021
2021
-
[8]
DroneARchery: Human- Drone Interaction through Augmented Reality with Haptic Feedback and Multi-UA V Collision Avoidance Driven by Deep Reinforcement Learning
Ekaterina Dorzhieva et al. “DroneARchery: Human- Drone Interaction through Augmented Reality with Haptic Feedback and Multi-UA V Collision Avoidance Driven by Deep Reinforcement Learning”. In:Proc. IEEE ISMAR. 2022
2022
-
[9]
Estimating Distances in Action Space in Augmented Reality
Holly C. Gagnon et al. “Estimating Distances in Action Space in Augmented Reality”. In:ACM Trans. Appl. Percept.(2021)
2021
-
[10]
Automatic generation and detection of highly reliable fiducial markers under occlusion
S. Garrido-Jurado et al. “Automatic generation and detection of highly reliable fiducial markers under occlusion”. In:Pattern Recognition(2014)
2014
-
[11]
BlendMR: A Computational Method to Create Ambient Mixed Reality Interfaces
Violet Yinuo Han et al. “BlendMR: A Computational Method to Create Ambient Mixed Reality Interfaces”. In:Proc. ACM HCI.(2023)
2023
-
[12]
Devel- opment of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research
Sandra G. Hart and Lowell E. Staveland. “Devel- opment of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research”. In:Human Mental Workload. North-Holland, 1988
1988
-
[13]
Improving Collocated Robot Teleoperation with Aug- mented Reality
Hooman Hedayati, Michael Walker, and Daniel Szafir. “Improving Collocated Robot Teleoperation with Aug- mented Reality”. In:Proc. ACM HRI. 2018
2018
-
[14]
RViz: A Toolkit for Real Domain Data Visualization
Hyeong Ryeol Kam et al. “RViz: A Toolkit for Real Domain Data Visualization”. In:Telecommun. Syst. (2015)
2015
-
[15]
Segment Anything
Alexander Kirillov et al. “Segment Anything”. In: Proc. IEEE ICCV. 2023
2023
-
[16]
In- teractive Robot Trajectory Planning With Augmented Reality for Non-expert Users
Joosun Lee, Taeyhang Lim, and Wansoo Kim. “In- teractive Robot Trajectory Planning With Augmented Reality for Non-expert Users”. In:International Jour- nal of Control, Automation and Systems(2024)
2024
-
[17]
Grounding dino: Marrying Dino with Grounded Pre-Training for Open-set Object De- tection
Shilong Liu et al. “Grounding dino: Marrying Dino with Grounded Pre-Training for Open-set Object De- tection”. In:arXiv preprint arXiv:2303.05499(2023)
Pith/arXiv arXiv 2023
-
[18]
RICO-MR: An Open-Source Architecture for Robot Intent Communication through Mixed Reality
Simone Macci `o et al. “RICO-MR: An Open-Source Architecture for Robot Intent Communication through Mixed Reality”. In:Proc. IEEE RO-MAN. 2023
2023
-
[19]
SLAM Tool- box: SLAM for the Dynamic World
Steve Macenski and Ivona Jambrecic. “SLAM Tool- box: SLAM for the Dynamic World”. In:Journal of Open Source Software(2021)
2021
-
[20]
Robot Operating System 2: Design, architecture, and uses in the wild
Steven Macenski et al. “Robot Operating System 2: Design, architecture, and uses in the wild”. In:Science Robotics7 (2022)
2022
-
[21]
The Marathon 2: A Nav- igation System
Steven Macenski et al. “The Marathon 2: A Nav- igation System”. In:2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2020
2020
-
[22]
Intuitive Robot Path Planning through Augmented Reality
Mohammad-Ehsan Matour and Alexander Winkler. “Intuitive Robot Path Planning through Augmented Reality”. In:Proc. IEEE MMAR. 2023
2023
-
[23]
AdjustAR: AI-Driven In-Situ Adjustment of Site-Specific Augmented Reality Con- tent
Nels Numan et al. “AdjustAR: AI-Driven In-Situ Adjustment of Site-Specific Augmented Reality Con- tent”. In:Proc. ACM UIST-Adjunct. 2025
2025
-
[24]
OpenAI. “GPT-4o System Card”. In:arXiv preprint arXiv:2410.21276(2024)
Pith/arXiv arXiv 2024
-
[25]
Augmented Reality-Enhanced Structural Inspection Using Aerial Robots
Christos Papachristos and Kostas Alexis. “Augmented Reality-Enhanced Structural Inspection Using Aerial Robots”. In:Proc. IEEE ISIC. 2016
2016
-
[26]
ScalAR: Authoring Semantically Adaptive Augmented Reality Experiences in Virtual Reality
Xun Qian et al. “ScalAR: Authoring Semantically Adaptive Augmented Reality Experiences in Virtual Reality”. In:Proc. ACM CHI. 2022
2022
-
[27]
Robot Programming Through Augmented Trajectories in Augmented Re- ality
Camilo Perez Quintero et al. “Robot Programming Through Augmented Trajectories in Augmented Re- ality”. In:Proc. IEEE IROS. 2018
2018
-
[28]
Enhancing Human Cobot Interaction with Mixed Reality: A Futuristic Review
Raffik R et al. “Enhancing Human Cobot Interaction with Mixed Reality: A Futuristic Review”. In:Proc. IEEE ICAECA. 2023
2023
-
[29]
Alec Radford et al.Learning Transferable Visual Models From Natural Language Supervision. 2021
2021
-
[30]
Sebastian Ramirez.FastAPI.URL:https : / / fastapi.tiangolo.com
-
[31]
ABOVE & BELOW: Inves- tigating Ceiling and Floor for Augmented Reality Content Placement
Marc Satkowski et al. “ABOVE & BELOW: Inves- tigating Ceiling and Floor for Augmented Reality Content Placement”. In:Proc. IEEE ISMAR. 2022
2022
-
[32]
Augmented Reality and Robotics: A Survey and Taxonomy for AR-enhanced Human- Robot Interaction and Robotic Interfaces
Ryo Suzuki et al. “Augmented Reality and Robotics: A Survey and Taxonomy for AR-enhanced Human- Robot Interaction and Robotic Interfaces”. In:Proc. ACM CHI. 2022
2022
-
[33]
A Mixed Reality Supervi- sion and Telepresence Interface for Outdoor Field Robotics
Michael Walker et al. “A Mixed Reality Supervi- sion and Telepresence Interface for Outdoor Field Robotics”. In:Proc. IEEE IROS. 2021
2021
-
[34]
Robot Teleoperation with Augmented Reality Virtual Surrogates
Michael E. Walker, Hooman Hedayati, and Daniel Szafir. “Robot Teleoperation with Augmented Reality Virtual Surrogates”. In:Proc. ACM HRI. 2019
2019
-
[35]
ViDDAR: Vision Language Model-Based Task- Detrimental Content Detection for Augmented Real- ity
Yanming Xiu, Tim Scargill, and Maria Gorlatova. “ViDDAR: Vision Language Model-Based Task- Detrimental Content Detection for Augmented Real- ity”. In:IEEE TVCG(2025)
2025
-
[36]
SafeSpect: Safety-First Augmented Reality Heads-up Display for Drone Inspections
Peisen Xu et al. “SafeSpect: Safety-First Augmented Reality Heads-up Display for Drone Inspections”. In: Proc. ACM CHI. 2025
2025
-
[37]
FlyAR: Augmented Reality Supported Micro Aerial Vehicle Navigation
Stefanie Zollmann et al. “FlyAR: Augmented Reality Supported Micro Aerial Vehicle Navigation”. In:IEEE TVCG(2014)
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.