Concordia: JIT-Compiled Persistent-Kernel Checkpointing for Fault-Tolerant LLM Inference
Pith reviewed 2026-06-26 07:16 UTC · model grok-4.3
The pith
A device-resident persistent kernel with JIT-compiled delta handlers lets LLM inference recover from GPU failures without host CPU involvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
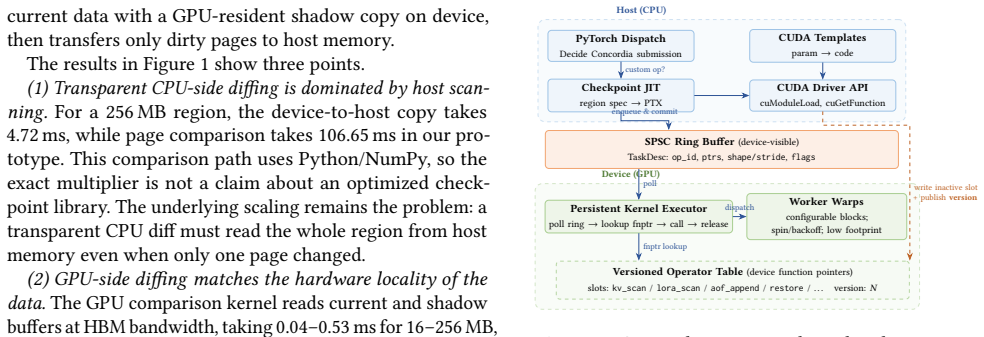
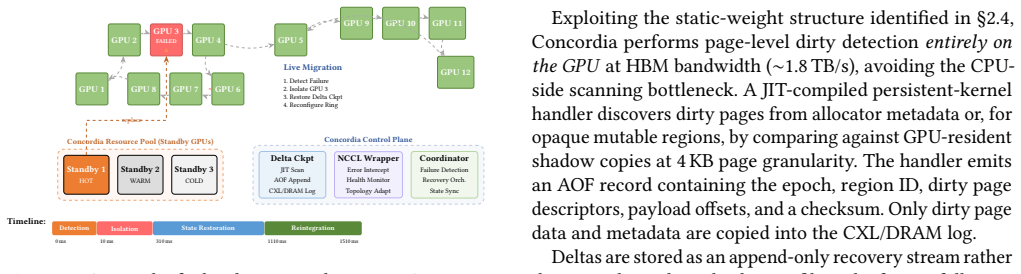
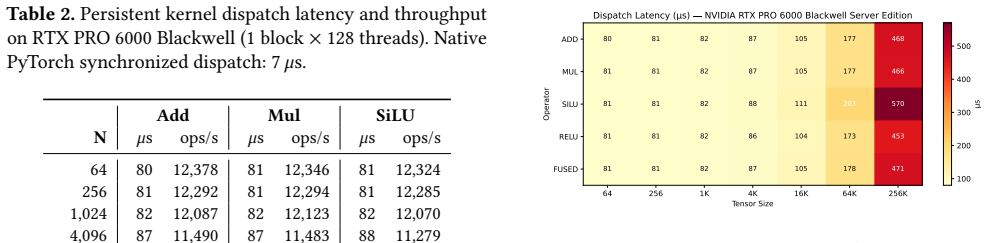
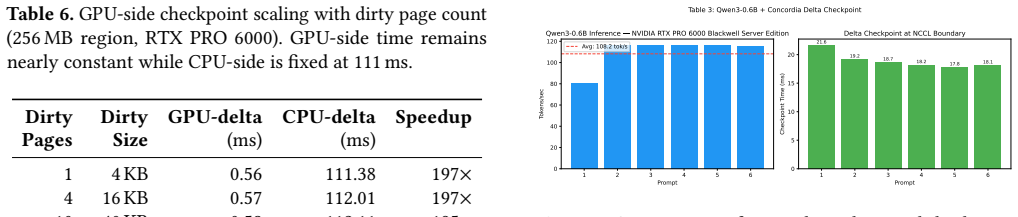
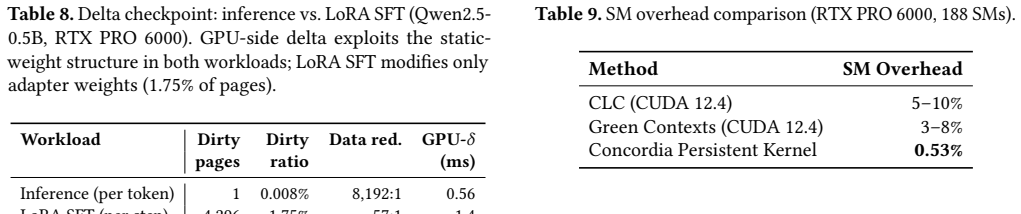
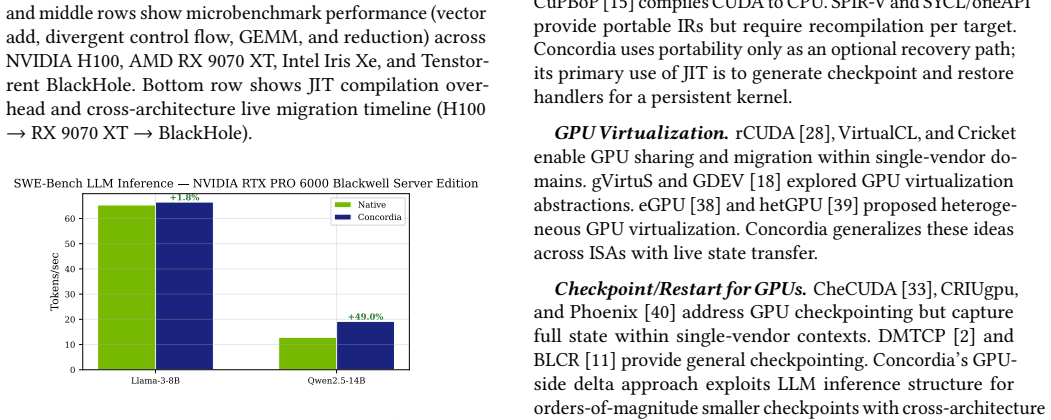
Concordia uses a device-resident persistent kernel as the substrate for fault-tolerant LLM inference. It interposes on GPU module loading and supports PTX- and SASS-level instrumentation so that checkpoint and pause hooks can be inserted below framework code and library boundaries. For each registered LLM state region, Concordia JIT-compiles a specialized delta-checkpoint handler and hot-swaps it into the persistent kernel's operator table. The kernel consumes a lock-free ring buffer of compute, checkpoint, append-log, and recovery tasks, allowing the same always-on executor to trigger dirty-page detection, stage deltas, and append committed records to a CPU-visible log.
What carries the argument
The JIT-compiled persistent kernel that hot-swaps delta-checkpoint handlers into its operator table and consumes tasks from a lock-free ring buffer to perform dirty-page detection and delta staging.
If this is right
- LLM serving can survive individual GPU failures while preserving minutes to hours of accumulated state.
- Checkpoint logic no longer needs to be duplicated inside every attention or runtime component.
- Recovery can occur at native device synchronization points rather than through host-mediated mechanisms.
- Delta checkpoints for regions such as KV blocks or adapter pages can be staged and logged without CPU intervention.
Where Pith is reading between the lines
- The same persistent-kernel substrate could support online migration of LLM state between GPUs if the ring buffer is extended to remote nodes.
- CXL-visible logs could allow coordinated recovery across multiple inference nodes without additional network protocols.
- If the instrumentation layer remains stable, the approach may generalize to other long-running GPU workloads that maintain large device-resident data structures.
Load-bearing premise
Interposing on GPU module loading and inserting PTX- and SASS-level instrumentation can be done reliably and with acceptable overhead across frameworks and libraries without breaking compatibility or introducing new failure modes.
What would settle it
Observe an LLM inference run that experiences a GPU or communicator failure and recovers the KV cache and scheduler state using only the persistent kernel's delta handlers, without a full stack restart or host CPU on the critical path.
Figures

read the original abstract
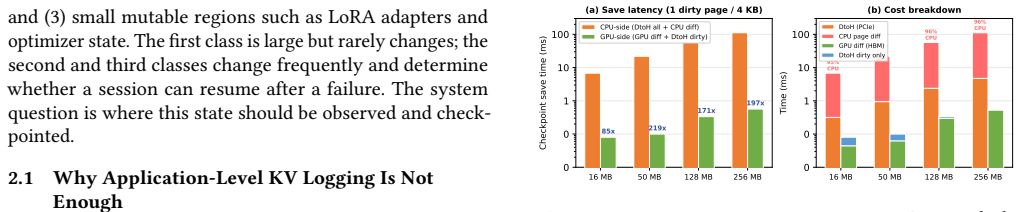
Long-running LLM agents keep valuable state resident on GPUs: KV caches, request schedulers, communication state, and sometimes online adapters. Losing this state after a GPU or communicator failure can discard minutes to hours of work, yet existing recovery mechanisms either restart the whole serving stack or require application-specific checkpoint logic inside every attention and runtime component. This paper argues that fault tolerance for such workloads needs a GPU-resident execution context: checkpoint hooks must run at device synchronization points, observe binary kernels that frameworks and libraries actually execute, and recover without putting the host CPU on the critical path. We present Concordia, a runtime that uses a device-resident persistent kernel as the substrate for fault-tolerant LLM inference. Concordia interposes on GPU module loading and supports PTX- and SASS-level instrumentation, allowing checkpoint and pause hooks to be inserted below framework code and library boundaries. For each registered LLM state region, Concordia JIT-compiles a specialized delta-checkpoint handler -- for example, a KV-block scanner, adapter-page scanner, or recovery applier -- and hot-swaps it into the persistent kernel's operator table. The persistent kernel consumes a lock-free ring buffer of compute, checkpoint, append-log, and recovery tasks, so the same always-on executor triggers dirty-page detection, stages deltas, and appends committed records to a CPU-visible log in CXL memory or host DRAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Concordia, a runtime for fault-tolerant LLM inference built around a device-resident persistent kernel. Checkpoint hooks run at device synchronization points by interposing on GPU module loading and inserting PTX- and SASS-level instrumentation below framework and library boundaries. For registered state regions (KV caches, adapters, etc.), the system JIT-compiles specialized delta-checkpoint handlers that are hot-swapped into the persistent kernel; a lock-free ring buffer feeds compute, checkpoint, append-log, and recovery tasks to the same always-on executor, with logs written to CXL or host DRAM.
Significance. If the interposition and instrumentation layer can be made robust, the approach would allow recovery of GPU-resident LLM state without restarting the serving stack or embedding application-specific checkpoint logic in every attention or runtime component. No machine-checked proofs, reproducible artifacts, or falsifiable predictions are described in the provided text.
major comments (2)
- [Abstract] Abstract (central claim paragraph): the mechanism requires reliable interposition on arbitrary cuBLAS/cuDNN/custom kernel module loads plus PTX/SASS instrumentation that succeeds without new failure modes or compatibility breakage; the manuscript supplies no implementation details, failure-mode analysis, or validation that this interposition can be performed transparently across frameworks.
- [Abstract] Abstract (persistent-kernel description): the claim that the same executor can trigger dirty-page detection, stage deltas, and append committed records while remaining GPU-resident rests on the unshown correctness of the lock-free ring buffer and JIT-compiled handlers; no pseudocode, invariants, or even high-level correctness argument is supplied.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify aspects of our work. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (central claim paragraph): the mechanism requires reliable interposition on arbitrary cuBLAS/cuDNN/custom kernel module loads plus PTX/SASS instrumentation that succeeds without new failure modes or compatibility breakage; the manuscript supplies no implementation details, failure-mode analysis, or validation that this interposition can be performed transparently across frameworks.
Authors: We agree that the abstract does not include implementation details, failure-mode analysis, or validation for the interposition mechanism. The body of the manuscript provides a description of the PTX/SASS instrumentation and module loading interposition. To address the concern, we will add a short discussion of potential failure modes and compatibility in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (persistent-kernel description): the claim that the same executor can trigger dirty-page detection, stage deltas, and append committed records while remaining GPU-resident rests on the unshown correctness of the lock-free ring buffer and JIT-compiled handlers; no pseudocode, invariants, or even high-level correctness argument is supplied.
Authors: We concur that the abstract lacks pseudocode, invariants, or a correctness argument for the lock-free ring buffer and JIT handlers. The manuscript outlines the design at a conceptual level. We will incorporate pseudocode and a high-level correctness sketch in the next version of the paper. revision: yes
Circularity Check
No circularity: systems description with no derivations or self-referential reductions
full rationale
The paper is a systems contribution that describes the design and implementation of the Concordia runtime, including interposition on GPU module loading, PTX/SASS instrumentation, JIT-compiled handlers, and a persistent kernel consuming a lock-free ring buffer. No equations, fitted parameters, predictions, uniqueness theorems, or derivation chains are present in the provided text. The central claims concern the feasibility of the described mechanisms rather than any result that reduces by construction to its own inputs or prior self-citations. The work is self-contained as an engineering artifact without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding the efficiency of ray traversal on gpus.Proc
Timo Aila and Samuli Laine. Understanding the efficiency of ray traversal on gpus.Proc. High Performance Graphics, 2009
2009
-
[2]
Dmtcp: Transparent checkpointing for cluster computations and the desktop
Jason Ansel, Kapil Arya, and Gene Cooperman. Dmtcp: Transparent checkpointing for cluster computations and the desktop. In2009 IEEE International Symposium on Parallel & Distributed Processing, pages 1–12. IEEE, 2009
2009
-
[3]
Post-failure recovery of mpi communication capability: Design and rationale
Wesley Bland, Aurelien Bouteiller, Thomas Herault, George Bosilca, and Jack Dongarra. Post-failure recovery of mpi communication capability: Design and rationale. InThe International Journal of High Performance Computing Applications, volume 27, pages 244–254. SAGE Publications, 2013
2013
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[5]
Tvm: An automated end- to-end optimizing compiler for deep learning
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. Tvm: An automated end- to-end optimizing compiler for deep learning. InProceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 578–594, C...
2018
-
[6]
Cuda graphs for work submission
Jack Choquette. Cuda graphs for work submission. NVIDIA Developer Blog, 2019.https://developer.nvidia.com/blog/cuda-graphs/
2019
-
[7]
Palm: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022
Pith/arXiv arXiv 2022
-
[8]
Lithos: An operating system for efficient machine learning on gpus
Patrick H Coppock, Brian Zhang, Eliot H Solomon, Vasilis Kypriotis, Leon Yang, Bikash Sharma, Dan Schatzberg, Todd C Mowry, and Dim- itrios Skarlatos. Lithos: An operating system for efficient machine learning on gpus. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 1–17, 2025
2025
-
[9]
Compute express link (cxl) specification 3.1
CXL Consortium. Compute express link (cxl) specification 3.1. Tech- nical report, Compute Express Link Consortium, January 2024
2024
-
[10]
Ocelot: A dynamic optimization framework for bulk- synchronous applications in heterogeneous systems
Gregory Diamos, Andrew Kerr, Sudhakar Yalamanchili, and Nathan Clark. Ocelot: A dynamic optimization framework for bulk- synchronous applications in heterogeneous systems. InProceedings of the 19th International Conference on Parallel Architectures and Compi- lation Techniques (PACT), pages 353–364. ACM, 2010
2010
-
[11]
The design and im- plementation of berkeley lab’s linux checkpoint/restart.Lawrence Berkeley National Laboratory Technical Report, 2003
Jason Duell, Paul Hargrove, and Eric Roman. The design and im- plementation of berkeley lab’s linux checkpoint/restart.Lawrence Berkeley National Laboratory Technical Report, 2003
2003
-
[12]
Tiresias: A gpu cluster manager for distributed deep learning
Juncheng Gu et al. Tiresias: A gpu cluster manager for distributed deep learning. InProceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2019
2019
-
[13]
Stuart, and John D
Kshitij Gupta, Jeff A. Stuart, and John D. Owens. A study of persistent threads style gpu programming for gpgpu workloads. InProceedings of the 2012 Innovative Parallel Computing (InPar), pages 1–14, San Jose, CA, USA, 2012. IEEE
2012
-
[14]
Lora: Low-rank adapta- tion of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adapta- tion of large language models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[15]
Cupbop: Cuda on platform-based portability
Ruobing Huang et al. Cupbop: Cuda on platform-based portability. In Proceedings of PPoPP, 2023
2023
-
[16]
Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
2019
-
[17]
Beyond data and model par- allelism for deep neural networks
Zhihao Jia, Matei Zaharia, and Alex Aiken. Beyond data and model par- allelism for deep neural networks. InProceedings of the 2nd Conference on Machine Learning and Systems (MLSys), 2019
2019
-
[18]
Gdev: First-class gpu resource management in the operating system
Shinpei Kato, Michael McThrow, Carlos Maltzahn, and Scott Brandt. Gdev: First-class gpu resource management in the operating system. InProceedings of the 2012 USENIX Annual Technical Conference (ATC), 2012
2012
-
[19]
Yuto Kojima, Jiarui Xu, Xueyan Zou, and Xiaolong Wang. Lora-ttt: Low-rank test-time training for vision-language models.arXiv preprint arXiv:2502.02069, 2025
arXiv 2025
-
[20]
Gonzalez, Hao Zhang, and Ion Sto- ica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), pages 611–626, 2023
2023
-
[21]
A formal analysis of the nvidia ptx memory consistency model
Daniel Lustig, Sameer Sahasrabuddhe, and Olivier Giroux. A formal analysis of the nvidia ptx memory consistency model. InProceed- ings of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2019
2019
-
[22]
Heterogeneity-aware cluster scheduling for deep learning workloads
Deepak Narayanan, Keshav Santhanam, et al. Heterogeneity-aware cluster scheduling for deep learning workloads. InProceedings of the 14th USENIX Symposium on Operating Systems Design and Implemen- tation (OSDI), 2020
2020
-
[23]
Memory-efficient pipeline-parallel dnn training
Deepak Narayanan, Keshav Santhanam, Fiodar Kazhamiaka, Amar Phanishayee, and Matei Zaharia. Memory-efficient pipeline-parallel dnn training. InInternational Conference on Machine Learning, pages 7937–7947. PMLR, 2021
2021
-
[24]
NVIDIA Corporation, 2023
NVIDIA Corporation.CUDA Dynamic Parallelism Technical Brief. NVIDIA Corporation, 2023. CUDA Programming Guide
2023
-
[25]
Constant-time graph launch techniques
NVIDIA Corporation. Constant-time graph launch techniques. Tech- nical brief, NVIDIA Corporation, 2024. CUDA 12.3 Release Documen- tation
2024
-
[26]
NVIDIA Corpora- tion, 2024
NVIDIA Corporation.CUDA Driver API Reference. NVIDIA Corpora- tion, 2024. CUDA Toolkit Documentation
2024
-
[27]
NVIDIA Corporation, 2024
NVIDIA Corporation.NVRTC: CUDA Runtime Compilation. NVIDIA Corporation, 2024. CUDA Toolkit Documentation
2024
-
[28]
Scale-ahead-of-time compilation of cuda for amd gpus
Manos Pavlidakis, Chris Kitching, Nicholas Tomlinson, and Michael Søndergaard. Scale-ahead-of-time compilation of cuda for amd gpus. InProceedings of the 25th International Middleware Conference: Demos, Posters and Doctoral Symposium, pages 5–6, 2024
2024
-
[29]
Pytorch 2.0: The journey to compilation
PyTorch Team. Pytorch 2.0: The journey to compilation. PyTorch Blog, 2023.https://pytorch.org/blog/pytorch-2.0-release/
2023
-
[30]
Nvidia sass disassembler
redplait. Nvidia sass disassembler. Github, June 2025
2025
-
[31]
Whippletree: Task-based scheduling of dynamic workloads on the gpu
Markus Steinberger et al. Whippletree: Task-based scheduling of dynamic workloads on the gpu. InACM SIGGRAPH, 2014
2014
-
[32]
Softshell: Dynamic sched- uling on gpus
Markus Steinberger, Michael Kenzel, et al. Softshell: Dynamic sched- uling on gpus. InACM SIGGRAPH Asia, 2012
2012
-
[33]
Checuda: A checkpoint/restart tool for cuda ap- plications
Hiroyuki Takizawa, Katsuto Koyama, Kento Sato, Kazuhiko Komatsu, and Hiroaki Kobayashi. Checuda: A checkpoint/restart tool for cuda ap- plications. In2011 International Conference on Parallel and Distributed Computing, Applications and Technologies, pages 408–413. IEEE, 2011. 15
2011
-
[34]
Xla: Tensorflow, compiled.TensorFlow Developer Blog, 2017
Google Brain Team. Xla: Tensorflow, compiled.TensorFlow Developer Blog, 2017
2017
-
[35]
Ptx on non nvidia gpus
vosen. Ptx on non nvidia gpus. Github, June 2025
2025
-
[36]
Gunrock: Gpu graph analytics
Yangzihao Wang et al. Gunrock: Gpu graph analytics. InACM Trans- actions on Parallel Computing, 2017
2017
-
[37]
Gandiva: Introspective cluster scheduling for deep learning
Wencong Xiao et al. Gandiva: Introspective cluster scheduling for deep learning. InProceedings of OSDI, 2018
2018
-
[38]
egpu: Ex- tending ebpf programmability and observability to gpus
Yiwei Yang, Tong Yu, Yusheng Zheng, and Andrew Quinn. egpu: Ex- tending ebpf programmability and observability to gpus. InProceedings of the 4th Workshop on Heterogeneous Composable and Disaggregated Systems, pages 73–79, 2025
2025
-
[39]
Yiwei Yang, Yusheng Zheng, Tong Yu, and Andi Quinn. Hetgpu: The pursuit of making binary compatibility towards gpus.arXiv preprint arXiv:2506.15993, 2025
arXiv 2025
-
[40]
Phoenix: A gpu-based serverless platform for large-scale model inference
Yuke Zhao, Chao Li, Jingyi Jiang, and Haoran Chen. Phoenix: A gpu-based serverless platform for large-scale model inference. In Proceedings of the 2024 USENIX Annual Technical Conference. USENIX, 2024
2024
-
[41]
Rtgpu: Real-time gpu scheduling of hard deadline parallel tasks with fine-grain utilization
An Zou et al. Rtgpu: Real-time gpu scheduling of hard deadline parallel tasks with fine-grain utilization. InArxiv, 2021. 16
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.