Temporal Task Diversity: Inductive Biases Under Non-Stationarity in Synthetic Sequence Modelling
Pith reviewed 2026-05-20 12:28 UTC · model grok-4.3
The pith
Varying tasks over time during training biases small transformers toward generalization instead of memorization
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
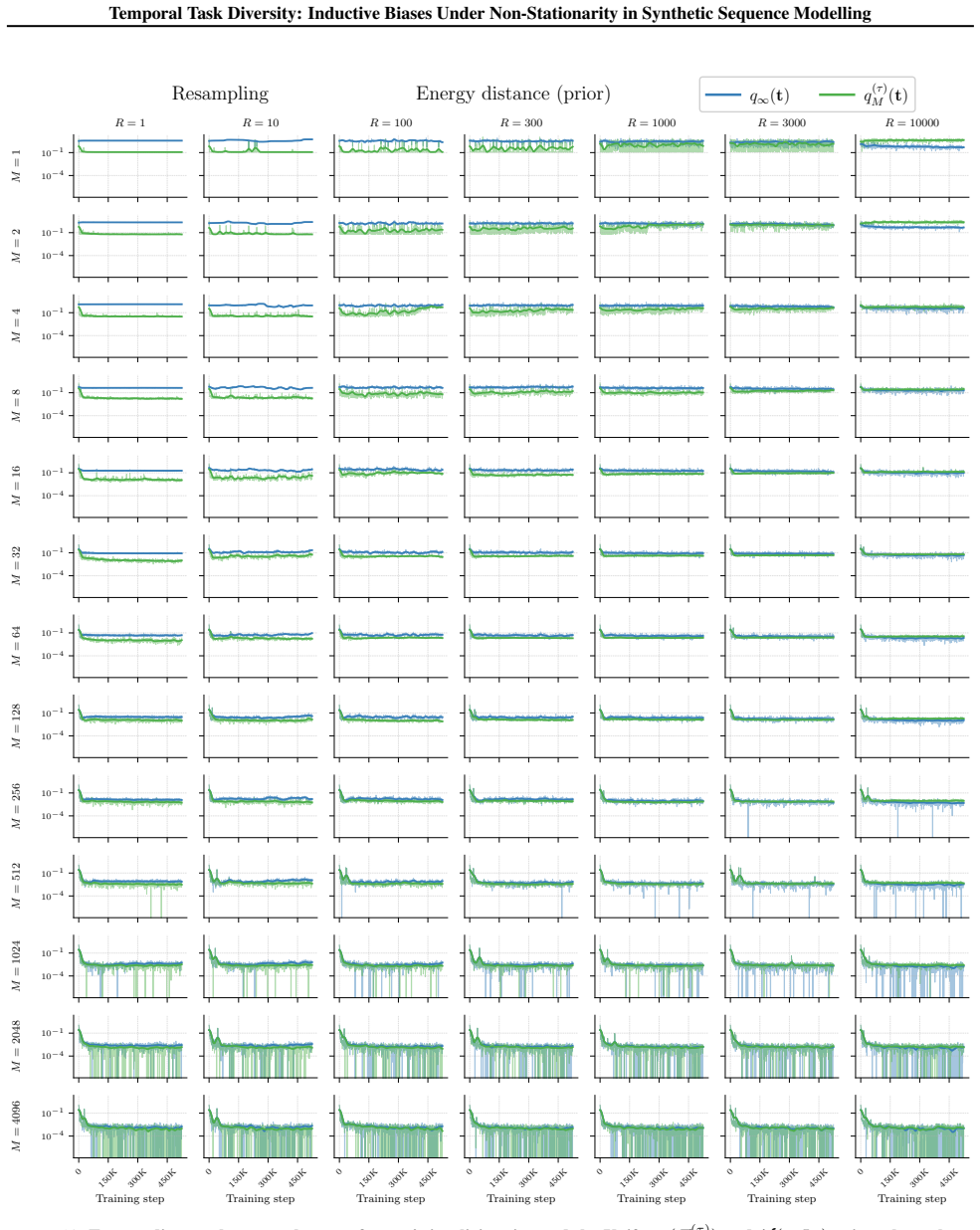
In in-context linear regression sequence modelling, diversifying the task distribution across training time leads to an increased bias towards generalisation over memorisation in small transformers.
What carries the argument
Temporal task diversity, the systematic variation of tasks in the training distribution over time, which creates non-stationarity and shifts inductive bias from memorization to generalization.
If this is right
- Models exhibit reduced reliance on memorizing specific task instances encountered during training.
- Generalization to novel tasks improves under conditions where the data distribution shifts gradually.
- Inductive biases toward safer or more robust solutions may emerge as a side effect of the same training schedule.
- Non-stationarity can be treated as a controllable design choice rather than an obstacle to avoid.
Where Pith is reading between the lines
- The same temporal-diversity mechanism might be tested in larger transformers or recurrent architectures to check whether the bias shift scales.
- Training curricula in online or continual-learning settings could deliberately introduce controlled task variation to favor generalization.
- The finding invites comparison with human learning, where exposure to changing environments often promotes flexible rather than rote strategies.
Load-bearing premise
The synthetic in-context linear regression task with small transformers serves as a faithful testbed whose observed generalization patterns will transfer to broader classes of deep learning models and real-world non-stationary data.
What would settle it
Training small transformers on temporally diverse tasks and finding no measurable increase in accuracy on held-out tasks compared with fixed-distribution training would falsify the claim.
Figures















read the original abstract
Modern deep learning science often assumes that neural networks learn from a fixed data distribution. However, many practically important learning problems involve data distributions that change throughout training. How does such non-stationarity impact the inductive biases of deep learning towards models with different structural, generalisation, and safety properties? A fruitful testbed for studying inductive bias is in-context linear regression sequence modelling, where small transformers display strikingly different generalisation patterns depending on the diversity of the (fixed) training task distribution. In this paper, we explore the effect of diversifying the task distribution across training time, finding that such temporal diversity leads to an increased bias towards generalisation over memorisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines how non-stationarity in task distributions during training affects inductive biases in small transformers performing in-context linear regression sequence modeling. It reports that introducing temporal diversity—by sequencing different task distributions over training time—produces an increased bias toward generalization rather than memorization, relative to stationary (fixed-distribution) training regimes.
Significance. If the central empirical finding holds after appropriate controls, the work would usefully extend existing synthetic testbeds for studying generalization in transformers to the non-stationary setting. This is relevant because real-world training often involves shifting distributions, and the result could inform curriculum or data-ordering strategies that favor generalization.
major comments (1)
- [Section 4] Section 4 and associated figures: the reported shift toward generalization is attributed specifically to temporal ordering of task distributions. However, the design lacks an explicit stationary control that exposes the model to the same union of tasks (matched total coverage and compute) but in shuffled order. Without this, the effect could arise from greater cumulative task variety or curriculum-like dynamics rather than non-stationarity per se.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief statement of the precise transformer architecture (layers, heads, embedding dimension) and the exact in-context regression setup (number of in-context examples, input dimension) to allow replication.
- Details on statistical significance, number of random seeds, and any exclusion criteria for runs are not visible in the provided text; adding these would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address the major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 4] Section 4 and associated figures: the reported shift toward generalization is attributed specifically to temporal ordering of task distributions. However, the design lacks an explicit stationary control that exposes the model to the same union of tasks (matched total coverage and compute) but in shuffled order. Without this, the effect could arise from greater cumulative task variety or curriculum-like dynamics rather than non-stationarity per se.
Authors: We agree that an explicit stationary control with matched total task coverage is necessary to isolate the contribution of temporal ordering. Our existing stationary baselines train on a single fixed task distribution for the entire run, while the temporal conditions cycle through a sequence of distributions. To address the concern, we will add a new stationary baseline that trains on the union of all tasks appearing in the temporal condition, presented in random shuffled order with identical total exposure and compute budget. We will include the results of this control in the revised Section 4, update the relevant figures, and revise the discussion to clarify whether the observed increase in generalization bias is specifically attributable to non-stationarity rather than cumulative variety alone. revision: yes
Circularity Check
No circularity: empirical exploration without self-referential derivations
full rationale
The paper is framed as an empirical study exploring the impact of temporal task diversity on generalization vs. memorization biases in small transformers trained on in-context linear regression tasks. No equations, derivations, or first-principles claims are presented that reduce by construction to fitted parameters, self-definitions, or self-citations from the same work. The central observation—that diversifying tasks across training time increases generalization bias—is reported from experimental results rather than any load-bearing mathematical reduction or renamed known pattern. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In-context linear regression sequence modelling is a fruitful testbed for studying inductive biases under non-stationarity.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We explore the effect of diversifying the task distribution across training time, finding that such temporal diversity leads to an increased bias towards generalisation over memorisation.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Optimisation tends towards more stable models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Battiston, M. and Cappello, L. Bayesian predictive inference beyond martingales, 2025. Preprint arXiv:2507.21874 https://arxiv.org/abs/2507.21874 [math.ST]
-
[2]
Bengio, Y., Louradour, J., Collobert, R., and Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, pp.\ 41--48, 2009
work page 2009
-
[3]
Bishop, C. M. Mixture density networks. Technical Report NCGR/94/004, Neural Computing Research Group, 1994
work page 1994
-
[4]
Bradbury, J., Frostig, R., Hawkins, P., Johnson, M. J., Leary, C., Maclaurin, D., Necula, G., Paszke, A., VanderPlas , J., Wanderman-Milne , S., and Zhang, Q. JAX: composable transformations of Python + NumPy programs. GitHub, 2018. URL http://github.com/jax-ml/jax
work page 2018
-
[5]
Statistical modeling: The two cultures (with comments and a rejoinder by the author)
Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Statistical Science, 16 0 (3): 0 199--231, 2001
work page 2001
-
[6]
Dynamics of transient structure in in-context linear regression transformers, 2025
Carroll, L., Hoogland, J., Farrugia-Roberts, M., and Murfet, D. Dynamics of transient structure in in-context linear regression transformers, 2025. Preprint arXiv:2501.17745 https://arxiv.org/abs/2501.17745 [cs.LG]
-
[7]
Data distributional properties drive emergent in-context learning in transformers
Chan, S., Santoro, A., Lampinen, A., Wang, J., Singh, A., Richemond, P., McClelland, J., and Hill, F. Data distributional properties drive emergent in-context learning in transformers. Advances in Neural Information Processing Systems 35, pp.\ 18878--18891, 2022
work page 2022
- [8]
-
[9]
Clements, M. P. and Hendry, D. F. Forecasting Non-Stationary Economic Time Series. MIT Press, 1999
work page 1999
-
[10]
Learning in nonstationary environments: A survey
Ditzler, G., Roveri, M., Alippi, C., and Polikar, R. Learning in nonstationary environments: A survey. IEEE Computational Intelligence Magazine, 10 0 (4): 0 12--25, 2015
work page 2015
-
[11]
Effiezal Aswadi , A. A., Ma, H., and Wei, S. What does a Bayes -filtered transformer believe? A predictive Monte Carlo approach. In preparation, 2026
work page 2026
-
[12]
A mathematical framework for transformer circuits
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S., and Olah, C. A mathematical framework for transformer circ...
work page 2021
-
[13]
Fong, E., Holmes, C., and Walker, S. G. Martingale posterior distributions. Journal of the Royal Statistical Society Series B: Statistical Methodology, 85 0 (5): 0 1357--1391, 2023
work page 2023
-
[14]
Fortini, S. and Petrone, S. Prediction-based uncertainty quantification for exchangeable sequences. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 381 0 (2247): 0 20220142, 2023
work page 2023
-
[15]
Fortini, S. and Petrone, S. Exchangeability, prediction and predictive modeling in Bayesian statistics. Statistical Science, 40 0 (1), January 2025
work page 2025
-
[16]
French, R. M. Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3 0 (4): 0 128--135, 1999
work page 1999
-
[17]
What can transformers learn in-context? a case study of simple function classes
Garg, S., Tsipras, D., Liang, P., and Valiant, G. What can transformers learn in-context? a case study of simple function classes. In Advances in Neural Information Processing Systems 35, pp.\ 30583--30598, 2022
work page 2022
-
[18]
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., and Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks, 2014. Published as a conference paper at ICLR 2014. Preprint arXiv:1312.6211 https://arxiv.org/abs/1312.6211 [stat.ML]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
He, T., Doshi, D., Das, A., and Gromov, A. Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks. In Advances in Neural Information Processing Systems 37, pp.\ 13244--13273, 2024
work page 2024
-
[20]
Loss landscape degeneracy and stagewise development in transformers
Hoogland, J., Wang, G., Farrugia-Roberts, M., Carroll, L., Wei, S., and Murfet, D. Loss landscape degeneracy and stagewise development in transformers. Transactions on Machine Learning Research, 2025
work page 2025
-
[21]
Transient non-stationarity and generalisation in deep reinforcement learning
Igl, M., Farquhar, G., Luketina, J., Boehmer, W., and Whiteson, S. Transient non-stationarity and generalisation in deep reinforcement learning. In International Conference on Learning Representations, 2021
work page 2021
- [22]
-
[23]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization, 2015. Published as a conference paper at ICLR 2015. Preprint arXiv:1412.6980 https://arxiv.org/abs/1412.6980 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
McCloskey, M. and Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation, 24: 0 109--165, 1989
work page 1989
-
[25]
Milly, P. C. D., Betancourt, J., Falkenmark, M., Hirsch, R. M., Kundzewicz, Z. W., Lettenmaier, D. P., and Stouffer, R. J. Stationarity is dead: Whither water management? Science, 319 0 (5863): 0 573--574, 2008
work page 2008
-
[26]
Mitchell, T. M. The need for biases in learning generalizations. Technical Report CBM-TR-117, Computer Science Department, Rutgers University, 1980
work page 1980
-
[27]
Nestor, B., McDermott, M. B. A., Boag, W., Berner, G., Naumann, T., Hughes, M. C., Goldenberg, A., and Ghassemi, M. Feature robustness in non-stationary health records: Caveats to deployable model performance in common clinical machine learning tasks. In Proceedings of the 4th Machine Learning for Healthcare Conference, volume 106, pp.\ 381--405. PMLR, 2019
work page 2019
-
[28]
The primacy bias in deep reinforcement learning
Nikishin, E., Schwarzer, M., D'Oro, P., Bacon, P.-L., and Courville, A. The primacy bias in deep reinforcement learning. In Proceedings of the 39th International Conference on Machine Learning, volume 162, pp.\ 16828--16847. PMLR, 2022
work page 2022
-
[29]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. In Advances in Neural Information Proces...
work page 2022
-
[30]
In-context learning through the Bayesian prism
Panwar, M., Ahuja, K., and Goyal, N. In-context learning through the Bayesian prism. In International Conference on Learning Representations, 2024
work page 2024
-
[31]
Papoudakis, G., Christianos, F., Rahman, A., and Albrecht, S. V. Dealing with non-stationarity in multi-agent deep reinforcement learning, 2019. Preprint arXiv:1906.04737 https://arxiv.org/abs/1906.04737 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., and Wermter, S. Continual lifelong learning with neural networks: A review. Neural Networks, 113: 0 54--71, 2019
work page 2019
-
[33]
Park, C. F., Lubana, E. S., Pres, I., and Tanaka, H. Competition dynamics shape algorithmic phases of in-context learning. In International Conference on Learning Representations, 2025
work page 2025
-
[34]
Pepin Lehalleur, S., Hoogland, J., Farrugia-Roberts, M., Wei, S., Gietelink Oldenziel, A., Wang, G., Carroll, L., and Murfet, D. You are what you eat -- AI alignment requires understanding how data shapes structure and generalisation, 2025. Preprint arXiv:2502.05475 https://arxiv.org/abs/2502.05475 [cs.LG]
-
[35]
Formal algorithms for transformers.arXiv preprint arXiv:2207.09238, 2022
Phuong, M. and Hutter, M. Formal algorithms for transformers, 2022. Preprint arXiv:2207.09238 https://arxiv.org/abs/2207.09238 [cs.LG]
-
[36]
Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions
Ratcliff, R. Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions. Psychological Review, 97 0 (2): 0 285--308, 1990
work page 1990
-
[37]
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression
Ravent\' o s, A., Paul, M., Chen, F., and Ganguli, S. Pretraining task diversity and the emergence of non-bayesian in-context learning for regression. In Advances in Neural Information Processing Systems 36, pp.\ 14228--14246, 2023
work page 2023
-
[38]
Roberts, G. O. and Tweedie, R. L. Exponential convergence of Langevin distributions and their discrete approximations. Bernoulli, 2 0 (4): 0 341--363, 1996
work page 1996
-
[39]
Schlimmer, J. C. and Fisher, D. A case study of incremental concept induction. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 5, 1986
work page 1986
-
[40]
The transient nature of emergent in-context learning in transformers
Singh, A., Chan, S., Moskovitz, T., Grant, E., Saxe, A., and Hill, F. The transient nature of emergent in-context learning in transformers. Advances in Neural Information Processing Systems 36, pp.\ 27801--27819, 2024
work page 2024
-
[41]
Sutton, R. S. and Barto, A. G. Reinforcement Learning: An Introduction. MIT Press, second edition, 2018
work page 2018
-
[42]
Sutton, R. S. and Whitehead, S. D. Online learning with random representations. In Proceedings of the Tenth International Conference on Machine Learning, pp.\ 314--321. Morgan Kaufmann, 1993
work page 1993
-
[43]
Székely, G. J. Potential and kinetic energy in statistics. Lecture notes, Budapest Institute of Technology (Technical University), 1989. As cited in Szekely+Rizzo2013
work page 1989
-
[44]
Székely, G. J. and Rizzo, M. L. Energy statistics: A class of statistics based on distances. Journal of Statistical Planning and Inference, 143 0 (8): 0 1249--1272, 2013
work page 2013
-
[45]
Thrun, S. and Mitchell, T. M. Lifelong robot learning. Robotics and Autonomous Systems, 15 0 (1): 0 25--46, 1995
work page 1995
-
[46]
The problem of concept drift: definitions and related work
Tsymbal, A. The problem of concept drift: definitions and related work. Technical Report TCD-CS-2004-15, Department of Computer Science, Trinity College Dublin, 2004
work page 2004
-
[47]
A comprehensive survey of continual learning: Theory, method and application
Wang, L., Zhang, X., Su, H., and Zhu, J. A comprehensive survey of continual learning: Theory, method and application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 0 (8): 0 5362--5383, 2024
work page 2024
-
[48]
Wentworth, J. S. Selection theorems: A program for understanding agents. AI Alignment Forum, 2021. URL https://www.alignmentforum.org/posts/G2Lne2Fi7Qra5Lbuf
work page 2021
-
[49]
Widmer, G. and Kubat, M. Learning in the presence of concept drift and hidden contexts. Machine Learning, 23: 0 69--101, 1996
work page 1996
-
[50]
Wurgaft, D., Lubana, E. S., Park, C. F., Tanaka, H., Reddy, G., and Goodman, N. In-context learning strategies emerge rationally. In Advances in Neural Information Processing Systems 38, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.