Fluency and Faithfulness in Human and Machine Literary Translation
Pith reviewed 2026-05-19 16:07 UTC · model grok-4.3
The pith
Literary translations that sound more natural in the target language tend to preserve less of the source meaning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
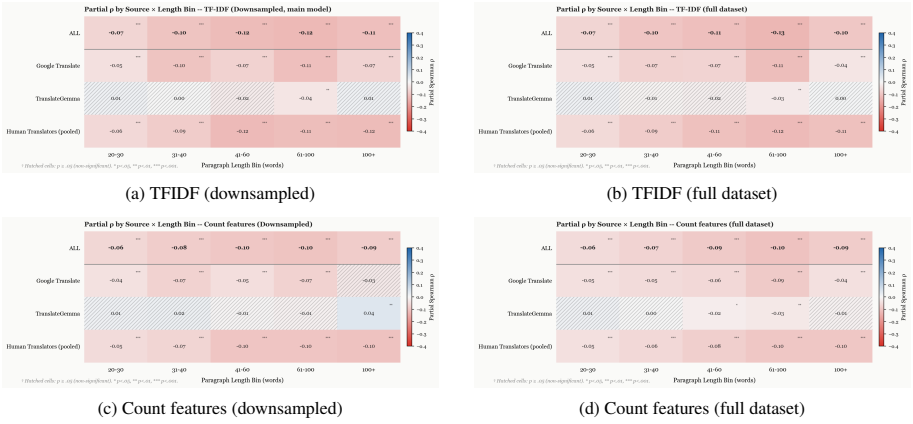
The central claim is that fluency and faithfulness trade off against each other in literary novel translation. When paragraphs are made to resemble original writing in the target language, they tend to diverge more from the semantic content of the source, a pattern that holds after controlling for length and appears in both human translations and Google Translate but is reduced in TranslateGemma.
What carries the argument
A paragraph-level part-of-speech n-gram classifier that measures original-likeness as a proxy for fluency, paired with the COMET-KIWI metric for semantic faithfulness, applied to a controlled corpus of novel paragraphs.
If this is right
- Automatic evaluation of literary translations should account for segment length because it influences the observed fluency-faithfulness relationship.
- Human translators and established machine systems exhibit similar tradeoffs when rendering novels.
- Newer LLM-based translators may reduce the strength of the tradeoff compared with earlier systems.
- The observed pattern suggests that improving fluency metrics alone may not improve overall quality for literary text.
Where Pith is reading between the lines
- The same negative relationship might appear in other genres if measured at paragraph scale, though the paper does not test this.
- Translation tools could be designed to let users explicitly choose points along the fluency-faithfulness curve rather than optimizing for one at the expense of the other.
- Paragraph-level analysis may reveal different dynamics than sentence-level evaluation in future studies of machine translation.
Load-bearing premise
The part-of-speech n-gram classifier truly captures target-language fluency and COMET-KIWI truly captures semantic faithfulness for paragraphs drawn from novels.
What would settle it
A replication on a comparable set of literary novel paragraphs that finds no negative correlation, or a positive correlation, between the fluency classifier scores and COMET-KIWI scores after length control.
Figures




read the original abstract
Literary translation requires balancing target-language fluency with faithfulness to the source. Recent large language models (LLMs) often produce fluent translations, but it remains unclear whether fluency corresponds to semantic preservation in literary text. We examine this relationship using 130,486 translated paragraphs from 106 novels in 16 source languages, including human, Google Translate, and TranslateGemma translations. Fluency is measured as original-likeness with a translationese classifier trained on paragraph part-of-speech n-grams, and faithfulness with the automatic translation evaluation metric COMET-KIWI. We control for paragraph length and find a consistent negative correlation between fluency and faithfulness. The pattern appears for both human and Google Translate, but is weaker and often non-significant for TranslateGemma. These results show that segment length matters for automatic evaluation and suggest a tradeoff between fluency and faithfulness in literary translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the relationship between fluency and faithfulness in literary translation using a dataset of 130,486 paragraphs from 106 novels across 16 source languages. Fluency is operationalized as original-likeness via a paragraph-level POS n-gram translationese classifier, while faithfulness is measured with COMET-KIWI. After controlling for paragraph length, the authors report a consistent negative correlation for human and Google Translate outputs that is weaker and frequently non-significant for TranslateGemma. The work concludes that segment length matters for automatic evaluation and that a fluency-faithfulness tradeoff exists in literary translation.
Significance. If the central measurements are valid, the study offers empirical support for a tradeoff between target fluency and source faithfulness in literary text, with implications for both human and machine translation evaluation. The large scale of the dataset and the inclusion of multiple translation sources are strengths. The result is most consequential if the POS n-gram classifier can be shown to capture fluency beyond syntactic artifacts.
major comments (2)
- [Methods] Methods section (classifier description): The claim that the paragraph-level POS n-gram translationese classifier validly measures target-language fluency (original-likeness) is load-bearing for the negative-correlation result. POS sequences primarily encode syntactic distributions; literary fluency also depends on lexical choice, collocations, and stylistic naturalness. Without validation against human fluency ratings on literary paragraphs or an ablation showing that the classifier is not reducible to length or syntax alone, the observed negative correlation with COMET-KIWI risks being an artifact of shared sensitivity to syntactic or length-related features.
- [Results] Results (correlation tables/figures): The length control is described at a high level, but the manuscript does not report the exact regression specification, variance inflation factors, or residual diagnostics. If residual length effects or genre-specific syntactic patterns remain, they could induce the reported negative correlation independently of any genuine fluency-faithfulness tradeoff.
minor comments (2)
- [Abstract] Abstract: The sentence on TranslateGemma could explicitly note the sample size or number of languages to allow readers to gauge the power of the non-significant findings.
- [Methods] Notation: The manuscript should clarify whether the translationese classifier is trained separately per language pair or pooled, as this affects interpretation of cross-language consistency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important considerations for the validity of our fluency proxy and the transparency of our statistical controls. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods] Methods section (classifier description): The claim that the paragraph-level POS n-gram translationese classifier validly measures target-language fluency (original-likeness) is load-bearing for the negative-correlation result. POS sequences primarily encode syntactic distributions; literary fluency also depends on lexical choice, collocations, and stylistic naturalness. Without validation against human fluency ratings on literary paragraphs or an ablation showing that the classifier is not reducible to length or syntax alone, the observed negative correlation with COMET-KIWI risks being an artifact of shared sensitivity to syntactic or length-related features.
Authors: We acknowledge that the POS n-gram classifier primarily captures syntactic patterns characteristic of translationese rather than the full spectrum of literary fluency, including lexical choice and stylistic naturalness. This syntactic focus is consistent with established translationese detection methods in the literature, where such features serve as reliable indicators of non-original-like text. To address the concern, we will revise the Methods and Discussion sections to explicitly discuss the scope and limitations of this proxy measure. We will also add an ablation analysis comparing the classifier against length-controlled baselines and simpler syntactic features to demonstrate that its predictions capture additional signal. While we lack human fluency ratings for the full 130k-paragraph corpus and cannot collect them within the scope of this revision, we will note this as a valuable avenue for future validation studies. revision: partial
-
Referee: [Results] Results (correlation tables/figures): The length control is described at a high level, but the manuscript does not report the exact regression specification, variance inflation factors, or residual diagnostics. If residual length effects or genre-specific syntactic patterns remain, they could induce the reported negative correlation independently of any genuine fluency-faithfulness tradeoff.
Authors: We agree that additional details on the length-control procedure will improve transparency and allow readers to assess potential residual confounds. In the revised manuscript, we will report the exact linear regression specification (faithfulness regressed on fluency score, paragraph length, and relevant covariates), include variance inflation factors to check for multicollinearity, and provide residual diagnostics (e.g., summary statistics and representative plots) to confirm that length effects have been adequately addressed. These additions will help substantiate that the observed negative correlations are not artifacts of incomplete length control. revision: yes
Circularity Check
Empirical correlation from independent metrics; no circularity
full rationale
The paper's central result is a statistical observation: after controlling for paragraph length, a negative correlation appears between fluency (original-likeness via a POS n-gram translationese classifier) and faithfulness (COMET-KIWI scores) across human, Google Translate, and LLM outputs on a large literary corpus. This chain consists of applying two pre-existing external metrics to new data and computing a correlation coefficient; it contains no equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that reduce the reported pattern to the paper's own inputs by construction. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption POS n-gram patterns can be used to train a classifier that measures how much a translation resembles original target-language text (fluency).
- domain assumption COMET-KIWI scores provide a reliable estimate of semantic faithfulness for literary paragraphs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Fluency is measured as original-likeness with a translationese classifier trained on paragraph part-of-speech n-grams, and faithfulness with the automatic translation evaluation metric COMET-KIWI.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We control for paragraph length and find a consistent negative correlation between fluency and faithfulness.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M3- Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self- Knowledge Distillation. InFindings of the Asso- ciation for Computational Linguistics: ACL 2024, pages 2318–2335, Bangkok, Thailand. Association for Computational Linguistics. Mara Finkelstein, Isaac Caswell, Tobias Domhan, Jan- Thorsten Peter, Juraj Jura...
work page 2024
-
[2]
TranslateGemma technical report.arXiv:2601.09012, 2026
TranslateGemma Technical Report.arXiv preprint. ArXiv:2601.09012 [cs]. Marzena Karpinska and Mohit Iyyer
-
[3]
DEMETR: Diagnosing Evaluation Metrics for Trans- lation.arXiv preprint. ArXiv:2210.13746 [cs]. Moshe Koppel and Noam Ordan
-
[4]
Studying Translationese at the Character Level. InProceedings of the International Conference Recent Advances in Natural Language Processing 2011, pages 634–639, Hissar, Bulgaria. Association for Computational Linguistics. Ricardo Rei, Nuno M. Guerreiro, Marcos Treviso, Luisa Coheur, Alon Lavie, and André F. T. Martins
work page 2011
-
[5]
The Inside Story: Towards Better Understanding of Machine Translation Neural Evaluation Metrics. arXiv preprint. ArXiv:2305.11806 [cs]. Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie
-
[6]
COMET: A Neural Framework for MT Evaluation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 2685–2702, Online. Association for Computational Linguistics. Ricardo Rei, Marcos Treviso, Nuno M. Guerreiro, Chrysoula Zerva, Ana C Farinha, Christine Maroti, José G. C. de Souza, Taisiya Glushkova, Duarte...
work page 2020
-
[7]
CometKiwi: IST-Unbabel 2022 Sub- mission for the Quality Estimation Shared Task. In Proceedings of the Seventh Conference on Machine Translation (WMT), pages 634–645, Abu Dhabi, United Arab Emirates (Hybrid). Association for Com- putational Linguistics. Friedrich Schleiermacher
work page 2022
-
[8]
InProceed- ings of the Fifth Conference on Machine Translation, pages 743–764, Online
Findings of the WMT 2020 Shared Task on Quality Estimation. InProceed- ings of the Fifth Conference on Machine Translation, pages 743–764, Online. Association for Computa- tional Linguistics. Phillip Benjamin Ströbel and Felix Klaus Maier
work page 2020
-
[9]
Gemma 3 Technical Report. arXiv preprint. ArXiv:2503.19786 [cs]. Katherine Thai, Marzena Karpinska, Kalpesh Krishna, Bill Ray, Moira Inghilleri, John Wieting, and Mohit Iyyer
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature.arXiv preprint. ArXiv:2210.14250 [cs]. Lawrence Venuti. 1995.The Translator’s Invisibility: A History of Translation. Routledge. V . V olansky, N. Ordan, and S. Wintner
-
[11]
Association for Computational Lin- guistics
Findings of the Quality Estima- tion Shared Task at WMT 2024: Are LLMs Closing the Gap in QE? InProceedings of the Ninth Confer- ence on Machine Translation, pages 82–109, Miami, Florida, USA. Association for Computational Lin- guistics. Ran Zhang, Wei Zhao, and Steffen Eger
work page 2024
-
[12]
How Good Are LLMs for Literary Translation, Really? Literary Translation Evaluation with Humans and LLMs. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 10961– 10988, Albuquerque, New Mexico. Association for Computatio...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.