The Value Function Semi-Algebraic Set in Partially Observable Markov Decision Processes
Pith reviewed 2026-06-28 09:14 UTC · model grok-4.3
The pith
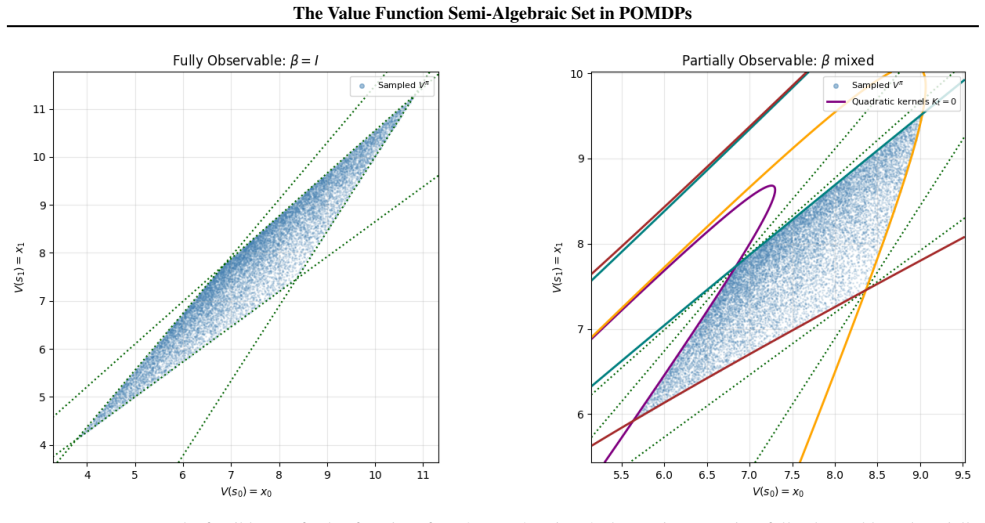
The feasible set of value functions in infinite-horizon POMDPs under memoryless stochastic policies is a semi-algebraic set defined by explicit polynomial inequalities from the transition dynamics, observation kernel, and rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
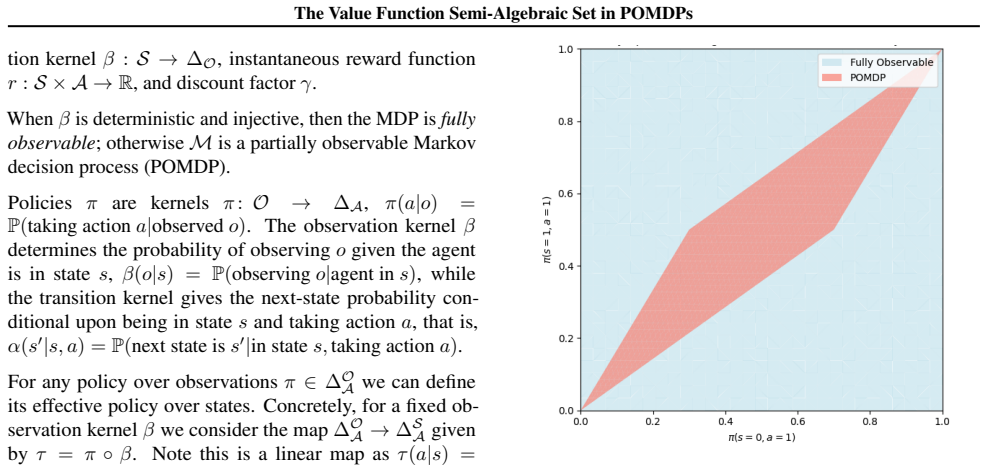
The feasible set of value functions in infinite-horizon POMDPs under memoryless stochastic policies is a semi-algebraic set defined by explicit polynomial inequalities determined by the transition dynamics, observation kernel, and reward structure of the POMDP. In contrast to the polyhedral structure in MDPs, partial observability induces fundamentally nonlinear constraints, leading to a richer geometric structure that reveals isolated local maximizers of long-term reward.
What carries the argument
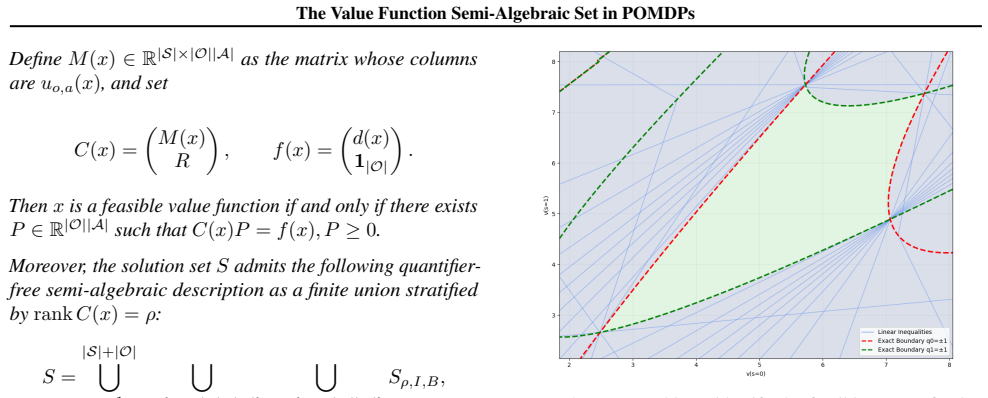
The semi-algebraic set of feasible value functions, defined by polynomial inequalities derived from the POMDP transition probabilities, observation kernel, and reward function.
If this is right
- The feasible set in POMDPs has a richer and more complex structure than the polytope arising in MDPs because of nonlinear constraints.
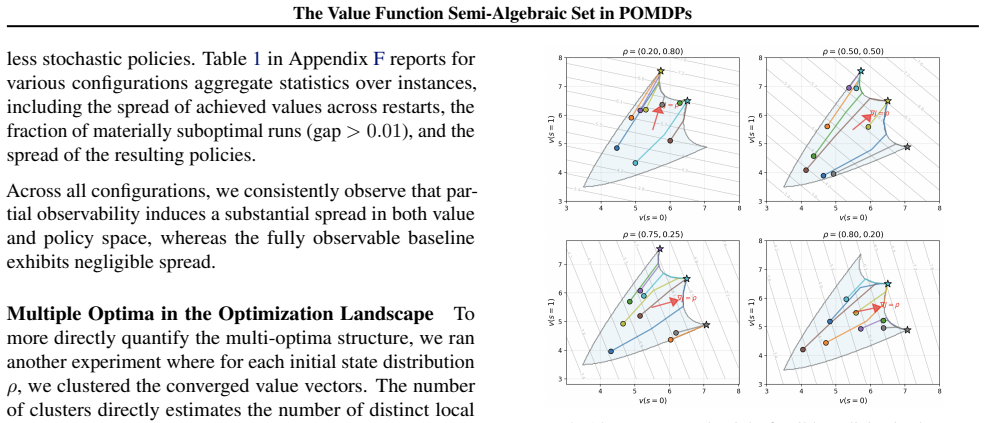
- Policy optimization in POMDPs can encounter isolated local maximizers of long-term reward that are absent in the fully observable case.
- The locations of these local maximizers depend on the initial state distribution.
- The geometric characterization supplies explicit algebraic insight into the optimization landscape for both MDPs and POMDPs.
Where Pith is reading between the lines
- The explicit polynomial description may allow algebraic or semidefinite programming techniques to certify global optimality or to enumerate local maxima in small POMDPs.
- The same style of derivation could be applied to finite-horizon or discounted settings to obtain similar semi-algebraic descriptions.
- The dependence on the initial distribution suggests that value-function geometry is not translation-invariant across belief states in the way MDP polytopes are.
Load-bearing premise
The characterization holds only for memoryless stochastic policies and does not automatically apply to history-dependent or deterministic policies.
What would settle it
A concrete value function vector that satisfies all the stated polynomial inequalities yet cannot be realized by any memoryless stochastic policy, or vice versa.
Figures
read the original abstract
We study the geometry of feasible value functions in infinite-horizon partially observable Markov decision processes (POMDPs) under memoryless stochastic policies. Our main contribution is a characterization of the feasible set of value functions as a semi-algebraic set, defined by explicit polynomial inequalities determined by the transition dynamics, observation kernel, and reward structure of the POMDP. This result extends prior work for fully observable Markov decision processes, where the feasible set is known to be a polytope, to the substantially more intricate partially observable setting. In contrast to the polyhedral structure arising in MDPs, partial observability induces fundamentally nonlinear constraints, leading to a richer and more complex geometric structure. Our geometric characterization provides new insight into the landscape of policy optimization in both MDPs and POMDPs, and reveals qualitative phenomena unique to partial observability, including the emergence of isolated local maximizers of the long-term reward and their dependence on the initial state distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
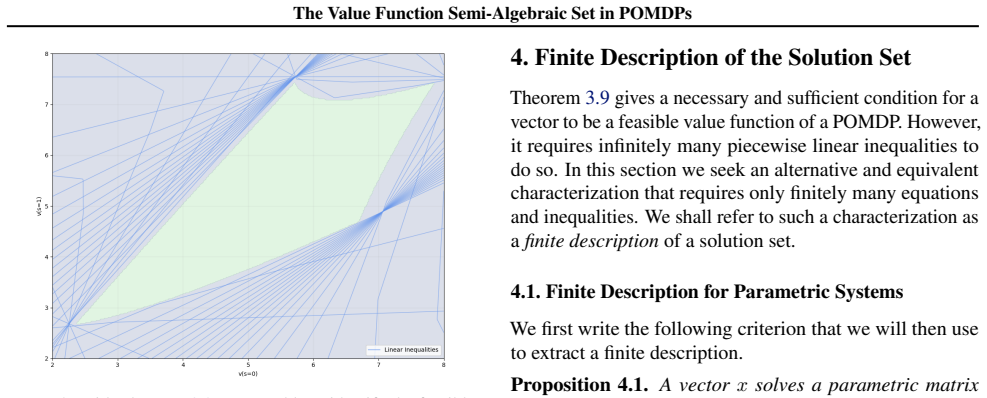
Summary. The paper claims that the feasible set of value functions achievable by memoryless stochastic policies in infinite-horizon POMDPs is a semi-algebraic set whose defining polynomial inequalities are explicitly determined by the transition matrix, observation kernel, and reward function. This extends the known polytope characterization for fully observable MDPs and is derived by viewing the value map as the projection of a semi-algebraic graph (linear Bellman equations plus simplex constraints) and invoking the Tarski–Seidenberg theorem.
Significance. If correct, the result supplies a precise algebraic-geometric description of the non-convex feasible set in POMDPs, directly explaining the emergence of isolated local maximizers and their dependence on the initial-state distribution. Such a characterization is useful for theoretical analysis of policy optimization landscapes and for designing algorithms that exploit the semi-algebraic structure.
minor comments (2)
- [Abstract / §2] The abstract states that the inequalities are 'explicit' but does not exhibit even a low-dimensional example; adding a two-state, two-observation illustration in §2 or §3 would make the construction more concrete without lengthening the paper.
- [Introduction] Notation for the value map V_π and the affine dependence of P_π, r_π on the policy parameters is introduced only in the body; a short notational table or paragraph at the end of the introduction would improve readability for readers coming from the MDP literature.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the main result, and recommendation to accept. We are pleased that the referee recognizes the significance of the semi-algebraic characterization for understanding non-convexity and local maxima in POMDP policy optimization.
Circularity Check
No significant circularity identified
full rationale
The central result characterizes the image of the memoryless stochastic policy simplex under the rational map to value functions V_π as a semi-algebraic set. This follows from recognizing that the Bellman fixed-point equations (I − γ P_π)V = r_π together with the simplex constraints on π are polynomial (because P_π and r_π are affine in π), so the graph is semi-algebraic and its projection is semi-algebraic by the Tarski–Seidenberg theorem. No step reduces to a fitted parameter renamed as a prediction, a self-definitional loop, or a load-bearing self-citation whose content is itself unverified; the derivation is self-contained in the algebraic geometry of the POMDP parameters.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The value function under a memoryless stochastic policy is a rational function of the policy parameters and the POMDP matrices.
- domain assumption The feasible set is the image of the policy simplex under the value map.
Reference graph
Works this paper leans on
-
[1]
Springer Vienna. URL https://doi.org/10. 1007/978-3-7091-6280-4_3. Axler, S. J.Linear Algebra Done Right. Undergraduate Texts in Mathematics. Springer, New York, 1997. URL http://linear.axler.net/. Azar, M. G., Osband, I., and Munos, R. Minimax regret bounds for reinforcement learning. InInter- national Conference on Machine Learning, 2017. URL https://ap...
arXiv 1997
-
[2]
URL http://www.pomdp.org/papers/ applications.pdf. Chad`es, I., Pascal, L. V ., Nicol, S., Fletcher, C. S., and Ferrer-Mestres, J. A primer on partially observ- able Markov decision processes (POMDPs).Methods in Ecology and Evolution, 12(11):2058–2072, 2021. URL https://besjournals.onlinelibrary. wiley.com/doi/10.1111/2041-210X.13692. Chen, F., Bai, Y ., ...
-
[3]
URL https://openreview.net/forum? id=n05upKp02kQ. Cohen, V . and Parmentier, A. Future memories are not needed for large classes of POMDPs.Op- erations Research Letters, 51(3):270–277, 2023. URL https://linkinghub.elsevier.com/ retrieve/pii/S016763772300041X. Crites, R. H. and Barto, A. G. Elevator Group Control Us- ing Multiple Reinforcement Learning Age...
-
[4]
PMLR, 2019. URL https://proceedings. mlr.press/v97/dadashi19a.html. Dressler, M., Garrote-L ´opez, M., Mont ´ufar, G., M¨uller, J., and Rose, K. Algebraic optimiza- tion of sequential decision problems.Journal of Symbolic Computation, 121:102241, 2024. URL https://www.sciencedirect.com/ science/article/pii/S074771712300055X. Drton, M. and Sullivant, S. Al...
arXiv 2019
-
[5]
10 The Value Function Semi-Algebraic Set in POMDPs cc/paper_files/paper/2016/file/ 2387337ba1e0b0249ba90f55b2ba2521-Paper
URL https://proceedings.neurips. 10 The Value Function Semi-Algebraic Set in POMDPs cc/paper_files/paper/2016/file/ 2387337ba1e0b0249ba90f55b2ba2521-Paper. pdf. Lauri, M., Hsu, D., and Pajarinen, J. Partially Observ- able Markov Decision Processes in Robotics: A Sur- vey.IEEE Transactions on Robotics, 39(1):21–40,
2016
-
[6]
URL https://ieeexplore.ieee.org/ document/9899480/. Li, Y ., Yin, B., and Xi, H. Finding optimal mem- oryless policies of POMDPs under the expected average reward criterion.European Journal of Operational Research, 211(3):556–567, 2011. URL https://linkinghub.elsevier.com/ retrieve/pii/S0377221710008805. Liu, Q., Szepesvari, C., and Jin, C. Sample-efficie...
arXiv 2011
-
[7]
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 743459dae9b2c5d2904e5432d5298128-Paper-Conference. pdf. Madani, O., Hanks, S., and Condon, A. On the undecid- ability of probabilistic planning and related stochastic optimization problems.Artificial Intelligence, 147(1-2):5– 34, 2003. URL https://linkinghub.elsevier. com/retrieve/pii/S00043...
-
[8]
com/retrieve/pii/0024379589900049
URL https://linkinghub.elsevier. com/retrieve/pii/0024379589900049. Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y ., Lillicrap, T., Hui, F., Sifre, L., Van Den Driessche, G., Graepel, T., and Hassabis, D. Mastering the game of Go without human knowledge. Nature, 550(76...
arXiv 2017
-
[9]
org/doi/10.1287/opre.21.5.1071
URL https://pubsonline.informs. org/doi/10.1287/opre.21.5.1071. Sondik, E. J. The Optimal Control of Partially Ob- servable Markov Processes over the Infinite Horizon: Discounted Costs.Operations Research, 26(2):282– 304, 1978. URL https://pubsonline.informs. org/doi/10.1287/opre.26.2.282. Subramanian, J., Sinha, A., Seraj, R., and Mahajan, A. Ap- proxima...
-
[10]
net/book/the-book-2nd.html
URL http://www.incompleteideas. net/book/the-book-2nd.html. Toro Icarte, R., Klassen, T. Q., Valenzano, R., Castro, M. P., Waldie, E., and McIlraith, S. A. Learning re- ward machines: A study in partially observable rein- forcement learning.Artificial Intelligence, 323:103989,
-
[11]
com/retrieve/pii/S0004370223001352
URL https://linkinghub.elsevier. com/retrieve/pii/S0004370223001352. Wang, K., Kumar, N., Zhou, K., Hooi, B., Feng, J., and Mannor, S. The geometry of robust value functions. 11 The Value Function Semi-Algebraic Set in POMDPs InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pp. ...
-
[12]
URL https://proceedings.mlr.press/ v162/wang22k.html. White, D. J. A Survey of Applications of Markov Decision Processes.Journal of the Operational Research Society, 44(11):1073–1096, 1993. URL https://www.tandfonline.com/doi/full/ 10.1057/jors.1993.181. Wolsey, L.Integer Programming. Wiley, 1 edition,
-
[13]
com/doi/book/10.1002/9781119606475
URL https://onlinelibrary.wiley. com/doi/book/10.1002/9781119606475. Wu, Y . and De Loera, J. A. Geometric Policy Iteration for Markov Decision Processes. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2070–2078, 2022. URL http:// arxiv.org/abs/2206.05809. arXiv:2206.05809 [cs]. Zhang, J., Zhang, H., Zhou, J., ...
-
[14]
URL https://linkinghub.elsevier. com/retrieve/pii/0022247X6590154X. 12 The Value Function Semi-Algebraic Set in POMDPs Appendix Contents This appendix is organized as follows: • Appendix A: Proofs of Results in Section 3 • Appendix B: Reduction to MDPs • Appendix C: Proofs of Results in Section 4 • Appendix D: Semi-algebraic Description of the Solution Se...
arXiv 2020
-
[15]
Draw an initial state distributionρ∼Dirichlet(1 S)
-
[16]
standard-normal logit initializations, each with η= 0.005 and T= 3000steps
Run 50 independent optimization trajectories from i.i.d. standard-normal logit initializations, each with η= 0.005 and T= 3000steps
-
[17]
Record the terminal triple(J i, Vi, πi)fori= 1, . . . ,50
-
[18]
For a given instance we then compute three aggregate statistics over the 50 restarts: •Value spread— the rangemax i Ji −min i Ji
Build the fully observable baseline and repeat steps 1–3,with the sameρ, on the baseline instance. For a given instance we then compute three aggregate statistics over the 50 restarts: •Value spread— the rangemax i Ji −min i Ji. •Suboptimal fraction— the share of restartsifor whichmax j Jj −J i >0.01. •Policy spread— the average pairwiseℓ 1 distance 150 2...
2019
-
[19]
Samplen inst = 20independent POMDP instances
-
[20]
For each instance, samplen ρ = 10independent initial state distributionsρ∼Dirichlet(1 S)
-
[21]
standard-normal logit initializations
For each (instance, ρ) pair, run nstarts = 50 independent optimization trajectories of length T= 3000 at η= 0.005 from i.i.d. standard-normal logit initializations
-
[22]
∥V∥ distance
Cluster the 50 terminal values {Ji} with tolerance δJ = 0.1. The number of clusters is reported as the estimated number of distinct local optima for that (instance,ρ) pair. Pooling overA,O, instances, andρ, for each state-space sizeSwe then report: • Mean number of optima, averaged over all (instance,ρ) pairs with thatS. • Share with more than one optimum...
2020
-
[23]
Increasing k tends to reduce the value spread, at least for the smallest configurations where memory is enough to substantially disambiguate the state
-
[24]
Partial observability still induces significant spread even at k= 2 : the spread for k= 2 is consistently larger than the spread in the fully observable setting, which is essentially zero
-
[25]
The suboptimal fraction does not cleanly shrink with k: on (8,2,2) and (8,3,2) it is non-monotone in k. This is consistent with the geometric reading: enlarging the policy class adds new feasible value functions and new critical points, which can shift the basin structure in ways that are not simply monotone in optimization-hardness indices. 38 The Value ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.