SSV: Sparse Speculative Verification for Efficient LLM Inference
Pith reviewed 2026-05-21 07:10 UTC · model grok-4.3
The pith
SSV resolves the mismatch between speculative decoding and sparse attention to reach up to 3.49x LLM inference throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
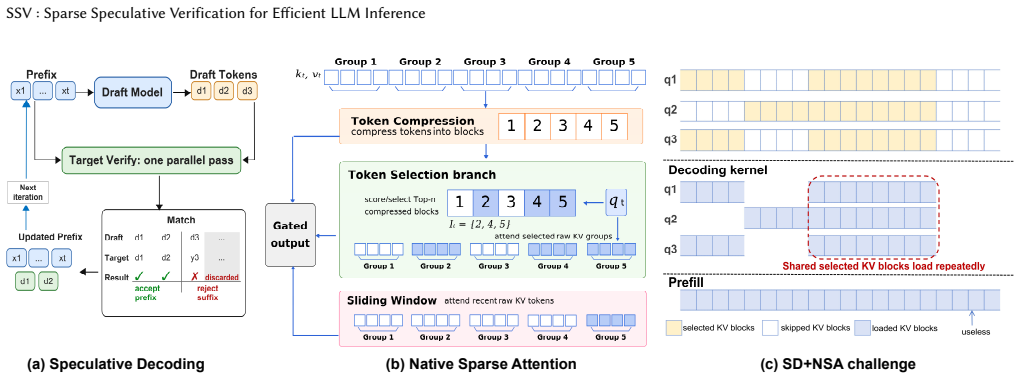
SSV turns dynamic sparse attention into a verification-oriented workload by combining overlap-aware grouped-query execution, refresh/reuse-based NSA kernel fusion, and profile-guided prompt-adaptive orchestration to improve cross-query reuse, reduce selected-index and branch-fusion overheads, and select effective draft-verification strategies under user-specified precision classes.
What carries the argument
Overlap-aware grouped-query execution paired with refresh/reuse-based NSA kernel fusion, which reclaims KV blocks across verifier queries even when each query uses its own sparse layout.
If this is right
- End-to-end throughput rises by as much as 3.49 times compared with autoregressive NSA decoding.
- Kernel speedups reach up to 6.86 times for the sparse speculative verification workload.
- Verification strategy choice becomes input- and regime-aware while staying inside given precision classes.
- Cross-query KV-block reuse improves while branch-wise and index-selection costs drop.
Where Pith is reading between the lines
- The same mismatch-resolution pattern could apply when pairing other acceleration methods that also separate shared versus per-query work.
- Profile-guided orchestration might transfer to other adaptive LLM pipelines where prompt statistics vary.
- Extending the reuse techniques to multi-GPU settings would test whether the reported speedups scale beyond single-device runs.
- Applying the approach to even longer contexts could show how reuse benefits grow with sequence length.
Load-bearing premise
The overlap-aware execution, kernel fusion, and profile-guided orchestration can close the gap between shared query patterns and per-query sparse layouts without adding overhead that wipes out the speed gains on real inputs.
What would settle it
Measure end-to-end throughput and kernel times on prompts with widely differing sparsity patterns; if gains fall below 1x or if fusion overheads exceed reported savings, the central claim does not hold.
Figures








read the original abstract
Speculative decoding and dynamic sparse attention are two complementary approaches for accelerating long-context LLM inference: the former amortizes target-model execution across multiple verifier queries, while the latter reduces each query's KV-cache working set. Directly combining them, however, exposes a structural mismatch: speculative verification relies on cross-query commonality, whereas dynamic sparse attention assigns query-specific sparse layouts. This mismatch limits KV-block reuse, amplifies NSA's branch-wise overheads, and makes verification strategy selection input- and regime-dependent. We present SSV, a sparse speculative-verification framework that turns dynamic sparse attention into a verification-oriented workload. SSV combines overlap-aware grouped-query execution, refresh/reuse-based NSA kernel fusion, and profile-guided prompt-adaptive orchestration to improve cross-query reuse, reduce selected-index and branch-fusion overheads, and select effective draft-verification strategies under user-specified precision classes. Experiments on NVIDIA H100 GPUs show that SSV achieves up to 3.49x end-to-end throughput over autoregressive NSA decoding and up to 6.86x kernel speedups for sparse speculative verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SSV, a sparse speculative-verification framework that integrates dynamic sparse attention with speculative decoding for long-context LLM inference. It identifies a structural mismatch between cross-query commonality in verification and query-specific sparse layouts, and addresses it via three techniques: overlap-aware grouped-query execution, refresh/reuse-based NSA kernel fusion, and profile-guided prompt-adaptive orchestration. Experiments on NVIDIA H100 GPUs report up to 3.49× end-to-end throughput gains over autoregressive NSA decoding and up to 6.86× kernel speedups under user-specified precision classes.
Significance. If the empirical results hold under rigorous validation, SSV would represent a meaningful systems contribution by enabling effective combination of two complementary LLM acceleration methods, with potential impact on efficient inference serving for long-context models. The work supplies concrete H100 measurements that could inform practical deployment decisions.
major comments (1)
- [Experiments] Experiments section: The abstract and reported results state concrete speedup numbers (3.49× end-to-end, 6.86× kernel) from H100 experiments, but provide no details on baselines, variance across runs, data exclusion rules, or exact measurement methodology (e.g., timing scope, batch sizes, or precision handling); this renders the central performance claims difficult to evaluate or reproduce from the manuscript alone.
minor comments (1)
- [Introduction] Introduction: The description of the structural mismatch could benefit from a small illustrative diagram or concrete example of how cross-query reuse is limited under query-specific sparse layouts.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that additional experimental details are necessary to support reproducibility of the reported performance numbers and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract and reported results state concrete speedup numbers (3.49× end-to-end, 6.86× kernel) from H100 experiments, but provide no details on baselines, variance across runs, data exclusion rules, or exact measurement methodology (e.g., timing scope, batch sizes, or precision handling); this renders the central performance claims difficult to evaluate or reproduce from the manuscript alone.
Authors: We acknowledge that the current manuscript version does not provide sufficient methodological details to fully evaluate or reproduce the reported speedups. In the revised manuscript we will expand the Experiments section with: (1) explicit descriptions of all baselines and their configurations (including autoregressive NSA, standard speculative decoding, and any other comparators); (2) variance statistics across repeated runs together with standard deviations; (3) any data exclusion or outlier-handling rules; and (4) a precise measurement protocol covering timing scope (kernel-only vs. end-to-end including overheads), batch sizes, sequence lengths, and precision settings (e.g., FP16/BF16). We will also add a dedicated “Experimental Methodology” subsection that consolidates these elements. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an engineering system (SSV) that combines speculative decoding with dynamic sparse attention via three concrete optimizations: overlap-aware grouped-query execution, refresh/reuse-based NSA kernel fusion, and profile-guided orchestration. All load-bearing claims are empirical throughput and kernel-speedup measurements on H100 hardware under stated precision classes. No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the abstract or framing; the central argument is that the listed mitigations overcome the stated structural mismatch, and this is justified by reported experimental outcomes rather than by any quantity defined in terms of itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SSV combines overlap-aware grouped-query execution, refresh/reuse-based NSA kernel fusion, and profile-guided prompt-adaptive orchestration to improve cross-query reuse...
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on NVIDIA H100 GPUs show that SSV achieves up to 3.49x end-to-end throughput...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. Gqa: Training general- ized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 4895–4901
work page 2023
-
[2]
2023.Children Stories Collection
ajibawa 2023. 2023.Children Stories Collection. doi:10.57967/hf/2480
- [3]
-
[4]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al . 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 7432–7439
work page 2020
-
[6]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating Large Language Model Decoding with Speculative Sampling.arXiv preprint arXiv:2302.01318(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabhar- wal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
2022.Introduction to algorithms
Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. 2022.Introduction to algorithms. MIT press
work page 2022
-
[10]
Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
-
[12]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2024. The L...
-
[13]
Yizhao Gao, Jianyu Wei, Qihao Zhang, Yu Cheng, Shimao Chen, Zhengju Tang, Zihan Jiang, Yifan Song, Hailin Zhang, Liang Zhao, et al
- [14]
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ankush Kadian, Amal Al-Dahle, Aiesha Letman, Anukriti Mathur, Ashwin Schelten, Angela Yang, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja Vooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, et al . 2019. A study of BFLOAT16 for deep learning training.arXiv preprint arXiv:1905.12322(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[19]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[20]
Xunhao Lai. 2025. native-sparse-attention-triton.https://github.com/ XunhaoLai/native-sparse-attention-triton
work page 2025
- [21]
-
[22]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. InProceedings of the 40th International Conference on Machine Learning. 19274–19286
work page 2023
-
[23]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. Eagle: Speculative sampling requires rethinking feature uncertainty. arXiv preprint arXiv:2401.15077(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2025. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Meta. 2024. Llama-3.1-8B-Instruct.https://huggingface.co/meta- llama/Llama-3.1-8B-InstructAccessed: 2026-05-13
work page 2024
-
[27]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna 13 Wang et al. Abhyankar, and Zhihao Jia. 2024. SpecInfer: Accelerating Large Lan- guage Model Serving with Tree-based Speculative Inference and Veri- fication. InProc...
work page 2024
-
[28]
Sanjit Neelam, Vaclav Cvicek, Daniel Heinlein, Akshay Mishra, Mahdi Nazemi, and Gilbert Hendry. 2025. Speculative Decoding with Block- wise Sparse Attention. MatX Research.https://matx.com/research/ sd_nsaAccessed: 2026-04-26
work page 2025
-
[29]
NVIDIA Corporation. 2024. NVIDIA H100 Tensor Core GPU.https: //www.nvidia.com/en-us/data-center/h100/. Accessed: 2026-04-26
work page 2024
-
[30]
PyTorch Contributors. 2025. torch.cuda.Event.https://docs.pytorch. org/docs/2.11/generated/torch.cuda.Event.html. PyTorch 2.11 docu- mentation. Accessed: 2026-05-09
work page 2025
-
[31]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: an intermediate language and compiler for tiled neural network computa- tions. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. 10–19
work page 2019
-
[32]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[33]
2026.Programming massively parallel processors: a hands-on approach
W Hwu Wen-Mei, David B Kirk, and Izzat El Hajj. 2026.Programming massively parallel processors: a hands-on approach. Morgan Kaufmann
work page 2026
-
[34]
Ran Yan, Youhe Jiang, and Binhang Yuan. 2025. Flash sparse attention: An alternative efficient implementation of native sparse attention kernel.arXiv e-prints(2025), arXiv–2508
work page 2025
-
[35]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, et al. 2025. Native sparse attention: Hardware-aligned and natively trainable sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 23078–23097
work page 2025
-
[36]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. 2020. Big bird: Transformers for longer sequences.Advances in neural information processing systems33 (2020), 17283–17297
work page 2020
-
[37]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence?. In Proceedings of the 57th annual meeting of the association for computa- tional linguistics. 4791–4800
work page 2019
-
[38]
zen-E. 2025. NSA-1B.https://huggingface.co/zen-E/NSA-1B. Accessed: 2026-05-05
work page 2025
-
[39]
zhenyi4. 2025. SSA.https://github.com/zhenyi4/ssa. Accessed: 2026- 05-05. 14
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.