Polar probe linearly decodes semantic structures from LLMs
Pith reviewed 2026-05-20 20:20 UTC · model grok-4.3
The pith
Large language models encode semantic relations between entities as distances and directions between their embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
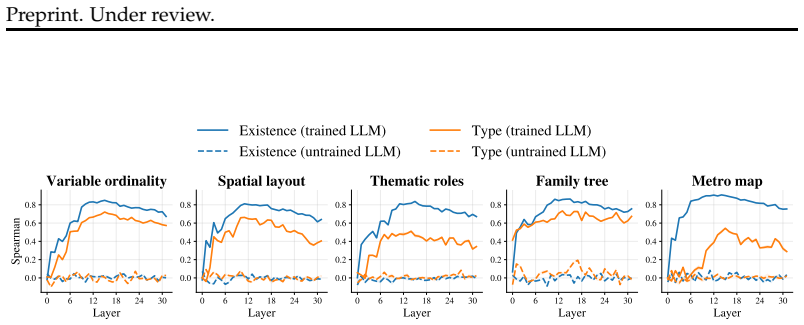
We propose a simple neural code, whereby the existence and the type of relations between entities are represented by the distance and the direction between their embeddings, respectively. We test this hypothesis in a variety of Large Language Models (LLMs), each input with natural-language descriptions of minimalist tasks from five different domains: arithmetic, visual scenes, family trees, metro maps and social interactions. Results show that the true semantic structures can be linearly recovered with a Polar Probe targeting a subspace of LLMs' layer activations. This code emerges mostly in middle layers and improves with LLM performance. These Polar Probes successfully generalize to new实体s
What carries the argument
The Polar Probe, a linear decoder applied to a subspace of LLM layer activations to recover the polar geometry of semantic structures where distance indicates relation existence and direction indicates relation type.
If this is right
- The geometrical code for binding relations appears primarily in middle layers rather than early or late ones.
- Higher-quality polar representations track better overall performance of the LLM on the semantic tasks.
- The probes generalize to new entities and relation types within the tested domains.
- Recovery accuracy drops as the number of entities and relations in a structure increases.
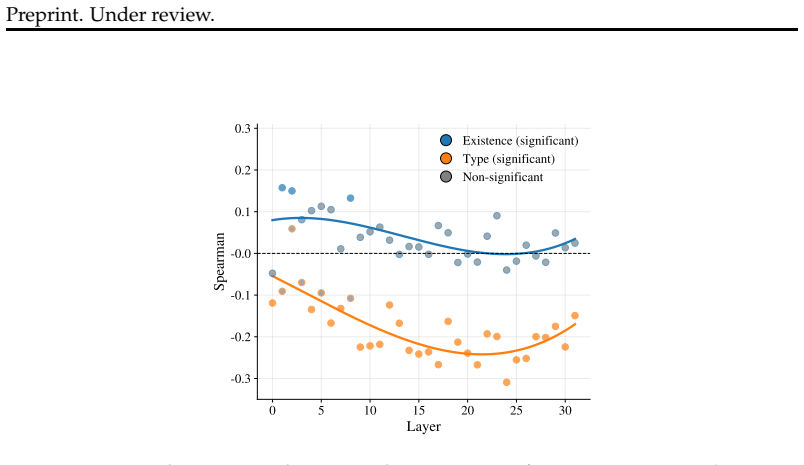
- Stronger polar decoding in activations corresponds to better model performance on questions about the semantic structures.
Where Pith is reading between the lines
- This binding principle could be tested by checking whether models lose semantic understanding when activations are perturbed along the polar directions.
- The same probe approach might reveal whether non-LLM neural networks use similar distance-direction codes for relations.
- If the code holds in open text, it would suggest LLMs build meaning without needing explicit symbolic structures.
- Larger structures degrading the signal points to a possible limit on how complex a representation one layer subspace can hold.
Load-bearing premise
The minimalist natural-language descriptions of tasks in five domains are sufficient to reveal the general mechanism by which LLMs bind concepts into semantic structures in open-ended text.
What would settle it
If a Polar Probe trained on activations from these five minimalist domains fails to recover accurate semantic structures when applied to the same models processing longer, open-ended natural language text.
Figures



















read the original abstract
How do artificial neural networks bind concepts to form complex semantic structures? Here, we propose a simple neural code, whereby the existence and the type of relations between entities are represented by the distance and the direction between their embeddings, respectively. We test this hypothesis in a variety of Large Language Models (LLMs), each input with natural-language descriptions of minimalist tasks from five different domains: arithmetic, visual scenes, family trees, metro maps and social interactions. Results show that the true semantic structures can be linearly recovered with a Polar Probe targeting a subspace of LLMs' layer activations. Second, this code emerges mostly in middle layers and improves with LLM performance. Third, these Polar Probes successfully generalize to new entities and relation types, but degrades with the size of the semantic structure. Finally, the quality of the polar representation correlates with the LLM's ability to answer questions about the semantic structure. Together, these findings suggest that LLMs learn to build complex semantic structures by binding representations with a simple geometrical principle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes that LLMs bind concepts into semantic structures via a simple polar code in which distance between entity embeddings encodes relation existence and direction encodes relation type. It introduces a linear 'Polar Probe' applied to subspaces of layer activations and tests recovery of ground-truth structures from explicit natural-language task descriptions across five domains (arithmetic, visual scenes, family trees, metro maps, social interactions). Key results include emergence of the code mainly in middle layers, improvement with model performance, successful generalization to new entities/relations (with degradation for larger structures), and correlation between probe quality and the LLM's ability to answer questions about the structures.
Significance. If the central results hold after addressing methodological gaps, the work would provide concrete evidence for a geometrical mechanism of semantic binding in LLMs, with implications for interpretability research. Strengths include the multi-domain evaluation, explicit generalization tests, and correlation with downstream task performance; these elements make the findings more falsifiable than single-domain probe studies. The approach also supplies a concrete, testable hypothesis (polar geometry) rather than purely post-hoc interpretations.
major comments (3)
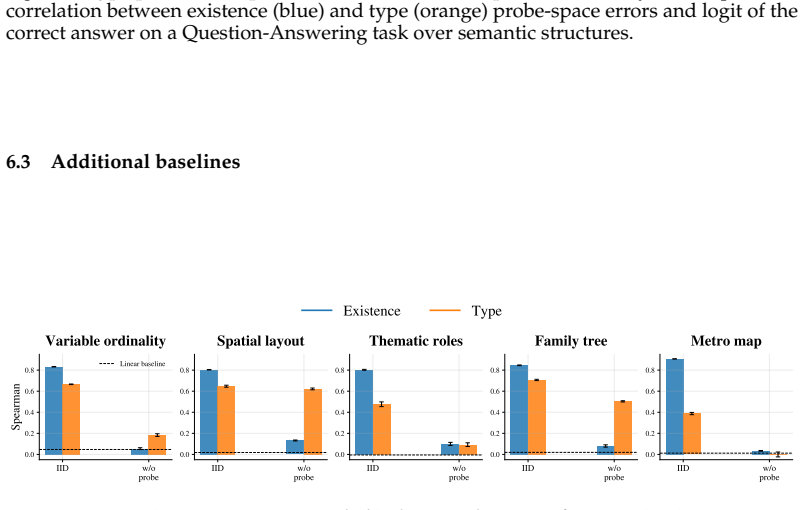
- [Methods] Methods section: The abstract and results claim successful linear recovery and generalization but supply no statistical details (e.g., p-values, confidence intervals), no controls for probe complexity (e.g., comparison to random or linear baselines of matched dimensionality), and no description of how subspaces were selected. These omissions make it impossible to judge whether the reported performance is specific to the polar hypothesis or could arise from any sufficiently expressive linear readout.
- [Results] Results (domain experiments): All inputs consist of explicit natural-language descriptions that already enumerate the full set of entities and relations. This design leaves open whether the linearly decodable polar code reflects the model's internal binding mechanism or simply its encoding of surface structure already stated in the prompt. A control condition with implicit or open-ended text (where relations must be inferred) is needed to support the broader claim about how LLMs construct semantic structures.
- [Generalization experiments] Generalization experiments: The reported degradation with semantic-structure size is interesting, but without an analysis of how probe dimensionality or regularization scales with structure size, it is unclear whether the degradation is a property of the hypothesized polar code or an artifact of probe capacity.
minor comments (2)
- [Abstract] Abstract: The term 'Polar Probe' is used without a one-sentence definition or reference to its mathematical formulation, which reduces accessibility for readers outside the immediate subfield.
- [Introduction] Notation: The distinction between 'distance' (existence) and 'direction' (type) is central yet introduced without an explicit equation or diagram in the early sections; adding a compact formal statement would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: The abstract and results claim successful linear recovery and generalization but supply no statistical details (e.g., p-values, confidence intervals), no controls for probe complexity (e.g., comparison to random or linear baselines of matched dimensionality), and no description of how subspaces were selected. These omissions make it impossible to judge whether the reported performance is specific to the polar hypothesis or could arise from any sufficiently expressive linear readout.
Authors: We agree that these details were insufficient. The revised manuscript will report p-values and confidence intervals for all probe results. We will add controls comparing the Polar Probe against random baselines and linear readouts of matched dimensionality. We will also describe the subspace selection process, which selected middle-layer subspaces based on preliminary layer-wise probe performance. revision: yes
-
Referee: [Results] Results (domain experiments): All inputs consist of explicit natural-language descriptions that already enumerate the full set of entities and relations. This design leaves open whether the linearly decodable polar code reflects the model's internal binding mechanism or simply its encoding of surface structure already stated in the prompt. A control condition with implicit or open-ended text (where relations must be inferred) is needed to support the broader claim about how LLMs construct semantic structures.
Authors: The explicit descriptions were chosen to supply verifiable ground-truth structures for quantitative probe evaluation across domains. The probe recovers geometry from post-prompt activations, and successful generalization to novel entities (absent from the original prompt) provides evidence that the representation is not limited to surface copying. We will add an explicit discussion of this limitation and note that implicit-prompt controls are a valuable direction for future work. revision: partial
-
Referee: [Generalization experiments] Generalization experiments: The reported degradation with semantic-structure size is interesting, but without an analysis of how probe dimensionality or regularization scales with structure size, it is unclear whether the degradation is a property of the hypothesized polar code or an artifact of probe capacity.
Authors: We will incorporate an analysis of probe dimensionality and regularization strength as functions of semantic-structure size. This will help determine whether the observed degradation arises from properties of the polar code itself or from capacity limits of the linear probe. revision: yes
Circularity Check
No significant circularity; empirical probe results are independent of inputs
full rationale
The paper advances a hypothesis that LLMs bind semantic structures via distance/direction in embedding space and tests it by training Polar Probes on layer activations to recover structures explicitly described in the input prompts across five domains. No load-bearing step reduces by construction to the inputs: the probe is a fitted linear decoder measuring decodability rather than a self-defined quantity, the ground-truth structures are external to the model's equations, and no self-citation chains or ansatzes are invoked to force the outcome. The reported emergence in middle layers, generalization, and correlation with question-answering are measured outcomes, not tautological renamings or fitted predictions. The derivation is therefore self-contained against the experimental benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM embeddings form a space in which linear subspaces can isolate relational information
invented entities (1)
-
Polar Probe
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the existence and the type of relations between entities are represented by the distance and the direction between their embeddings, respectively
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Polar Probe targeting a subspace of LLMs' layer activations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Tolman, Edward C. , year =. Cognitive maps in rats and men. , volume =. Psychological Review , publisher =. doi:10.1037/h0061626 , number =
-
[10]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Blondel, Mathieu and Teboul, Olivier and Berthet, Quentin and Djolonga, Josip , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[11]
The algebraic mind: Integrating connectionism and cognitive science , author=. 2003 , publisher=
work page 2003
-
[12]
arXiv preprint cs/0412059 , year=
Vector symbolic architectures answer Jackendoff's challenges for cognitive neuroscience , author=. arXiv preprint cs/0412059 , year=
- [13]
-
[14]
OLMo: Accelerating the Science of Language Models , author=. Preprint , year=
- [15]
-
[16]
Constantinescu, Alexandra O. and O’Reilly, Jill X. and Behrens, Timothy E. J. , year =. Organizing conceptual knowledge in humans with a gridlike code , volume =. Science , publisher =. doi:10.1126/science.aaf0941 , number =
-
[17]
Theves, Stephanie and Fernandez, Guillén and Doeller, Christian F. , year =. The Hippocampus Encodes Distances in Multidimensional Feature Space , volume =. Current Biology , publisher =. doi:10.1016/j.cub.2019.02.035 , number =
-
[18]
Aronov, Dmitriy and Nevers, Rhino and Tank, David W. , year =. Mapping of a non-spatial dimension by the hippocampal–entorhinal circuit , volume =. Nature , publisher =. doi:10.1038/nature21692 , number =
-
[19]
Theves, Stephanie and Fernández, Guillén and Doeller, Christian F. , year =. The Hippocampus Maps Concept Space, Not Feature Space , volume =. The Journal of Neuroscience , publisher =. doi:10.1523/jneurosci.0494-20.2020 , number =
-
[20]
A Map for Social Navigation in the Human Brain , volume =
Tavares, Rita Morais and Mendelsohn, Avi and Grossman, Yael and Williams, Christian Hamilton and Shapiro, Matthew and Trope, Yaacov and Schiller, Daniela , year =. A Map for Social Navigation in the Human Brain , volume =. Neuron , publisher =. doi:10.1016/j.neuron.2015.06.011 , number =
-
[21]
Placeunitsinthehippocampusofthefreelymovingrat.ExperimentalNeurology, 51(1):78–109, January 1976
O’Keefe, John , year =. Place units in the hippocampus of the freely moving rat , volume =. Experimental Neurology , publisher =. doi:10.1016/0014-4886(76)90055-8 , number =
-
[22]
Précis of O’Keefe &; Nadel’sThe hippocampus as a cognitive map , volume =
O’Keefe, John and Nadel, Lynn , year =. Précis of O’Keefe &; Nadel’sThe hippocampus as a cognitive map , volume =. Behavioral and Brain Sciences , publisher =. doi:10.1017/s0140525x00063949 , number =
-
[23]
and Clark, Kevin and Hewitt, John and Khandelwal, Urvashi and Levy, Omer , year =
Manning, Christopher D. and Clark, Kevin and Hewitt, John and Khandelwal, Urvashi and Levy, Omer , year =. Emergent linguistic structure in artificial neural networks trained by self-supervision , volume =. Proceedings of the National Academy of Sciences , publisher =. doi:10.1073/pnas.1907367117 , number =
-
[24]
A Structural Probe for Finding Syntax in Word Representations
Hewitt, John and Manning, Christopher D. A Structural Probe for Finding Syntax in Word Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1419
-
[25]
arXiv preprint arXiv:2312.16257 , year=
More than correlation: Do large language models learn causal representations of space? , author=. arXiv preprint arXiv:2312.16257 , year=
-
[26]
Forty-second International Conference on Machine Learning , year=
How Do Transformers Learn Variable Binding in Symbolic Programs? , author=. Forty-second International Conference on Machine Learning , year=
-
[27]
First Conference on Language Modeling , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. First Conference on Language Modeling , year=
-
[28]
Steering Language Models with Activation Engineering , author=. 2025 , url=
work page 2025
-
[29]
Language Models Encode Numbers Using Digit Representations in Base 10
Levy, Amit Arnold and Geva, Mor. Language Models Encode Numbers Using Digit Representations in Base 10. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2025. doi:10.18653/v1/2025.naacl-short.33
-
[30]
Probing for Incremental Parse States in Autoregressive Language Models
Eisape, Tiwalayo and Gangireddy, Vineet and Levy, Roger and Kim, Yoon. Probing for Incremental Parse States in Autoregressive Language Models. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.203
-
[31]
Probing for Labeled Dependency Trees
M. Probing for Labeled Dependency Trees. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.532
-
[32]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[33]
and Bruna, Joan and LeCun, Yann and Szlam, Arthur and Vandergheynst, Pierre , journal=
Bronstein, Michael M. and Bruna, Joan and LeCun, Yann and Szlam, Arthur and Vandergheynst, Pierre , journal=. Geometric Deep Learning: Going beyond Euclidean data , year=
- [34]
-
[35]
Hyperbolic neural networks , year =
Ganea, Octavian-Eugen and B\'. Hyperbolic neural networks , year =. Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages =
-
[36]
Boli Chen and Yao Fu and Guangwei Xu and Pengjun Xie and Chuanqi Tan and Mosha Chen and Liping Jing , booktitle=. Probing. 2021 , url=
work page 2021
-
[37]
Representational Analysis of Binding in Language Models
Dai, Qin and Heinzerling, Benjamin and Inui, Kentaro. Representational Analysis of Binding in Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.967
-
[38]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Transformers Represent Belief State Geometry in their Residual Stream , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[39]
The Twelfth International Conference on Learning Representations , year=
How do Language Models Bind Entities in Context? , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E
Liu, Nelson F. and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E. and Smith, Noah A. Linguistic Knowledge and Transferability of Contextual Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi...
-
[41]
What Does BERT Learn about the Structure of Language?
Jawahar, Ganesh and Sagot, Beno \^i t and Seddah, Djam \'e. What Does BERT Learn about the Structure of Language?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1356
-
[42]
Language Models Encode the Value of Numbers Linearly
Zhu, Fangwei and Dai, Damai and Sui, Zhifang. Language Models Encode the Value of Numbers Linearly. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[43]
The Thirteenth International Conference on Learning Representations , year=
Linear Representations of Political Perspective Emerge in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[44]
The Thirteenth International Conference on Learning Representations , year=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[45]
Conneau, Alexis and Kruszewski, German and Lample, Guillaume and Barrault, Lo. What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1198
-
[46]
Understanding intermediate layers using linear classifier probes , author=. 2017 , url=
work page 2017
-
[47]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
A Polar coordinate system represents syntax in large language models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[48]
Composition in Distributional Models of Semantics , volume =
Mitchell, Jeff and Lapata, Mirella , year =. Composition in Distributional Models of Semantics , volume =. Cognitive Science , publisher =. doi:10.1111/j.1551-6709.2010.01106.x , number =
-
[49]
Collins, Allan M. and Quillian, M. Ross , year =. Retrieval time from semantic memory , volume =. Journal of Verbal Learning and Verbal Behavior , publisher =. doi:10.1016/s0022-5371(69)80069-1 , number =
-
[50]
Collins, Allan M. and Loftus, Elizabeth F. , year =. A spreading-activation theory of semantic processing. , volume =. Psychological Review , publisher =. doi:10.1037/0033-295x.82.6.407 , number =
-
[51]
Simmons, R. and Slocum, J. , year =. Generating English discourse from semantic networks , volume =. Communications of the ACM , publisher =. doi:10.1145/355604.361595 , number =
-
[52]
On generative semantics , isbn =
Lakoff, George , editor =. On generative semantics , isbn =. Semantics:. 1971 , keywords =
work page 1971
- [53]
- [54]
- [55]
-
[56]
The proper treatment of quantification in ordinary English , author=. Approaches to natural language: Proceedings of the 1970 Stanford workshop on grammar and semantics , pages=. 1973 , organization=
work page 1970
-
[57]
McRae, Ken and Ferretti and Liane Amyote, Todd R. , year =. Thematic Roles as Verb-specific Concepts , volume =. Language and Cognitive Processes , publisher =. doi:10.1080/016909697386835 , number =
-
[58]
Sowa, John F , year =. Semantic Networks , ISBN =. doi:10.1002/0470018860.s00065 , journal =
-
[59]
Compositionality in Formal Semantics: Selected Papers of Barbara H
Barbara Hall Partee , editor =. Compositionality in Formal Semantics: Selected Papers of Barbara H. Partee , year =
-
[60]
Situations and Attitudes , year =
Jon Barwise and John Perry , publisher =. Situations and Attitudes , year =
-
[61]
Hans Kamp and Uwe Reyle , editor =. From Discourse to Logic: Introduction to Modeltheoretic Semantics of Natural Language, Formal Logic and Discourse Representation Theory , year =
-
[62]
The neural basis of combinatory syntax and semantics , volume =
Pylkk\". The neural basis of combinatory syntax and semantics , volume =. Science , publisher =. 2019 , month = oct, pages =. doi:10.1126/science.aax0050 , number =
-
[63]
Frankland, Steven M and Greene, Joshua D , year =. Two Ways to Build a Thought: Distinct Forms of Compositional Semantic Representation across Brain Regions , volume =. Cerebral Cortex , publisher =. doi:10.1093/cercor/bhaa001 , number =
-
[64]
Minimal Recursion Semantics: An Introduction , volume =
Copestake, Ann and Flickinger, Dan and Pollard, Carl and Sag, Ivan , year =. Minimal Recursion Semantics: An Introduction , volume =. Reseach On Language And Computation , doi =
-
[65]
A bstract M eaning R epresentation for Sembanking
Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan. A bstract M eaning R epresentation for Sembanking. Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse. 2013
work page 2013
-
[66]
Eye movements in reading and information processing: 20 years of research
Rayner, Keith , year =. Eye movements in reading and information processing: 20 years of research. , volume =. Psychological Bulletin , publisher =. doi:10.1037/0033-2909.124.3.372 , number =
-
[67]
and Spivey-Knowlton, Michael J
Tanenhaus, Michael K. and Spivey-Knowlton, Michael J. and Eberhard, Kathleen M. and Sedivy, Julie C. , year =. Integration of Visual and Linguistic Information in Spoken Language Comprehension , volume =. Science , publisher =. doi:10.1126/science.7777863 , number =
-
[68]
and Dehaene, Stanislas and King, Jean-Rémi , year =
Desbordes, Théo and Lakretz, Yair and Chanoine, Valérie and Oquab, Maxime and Badier, Jean-Michel and Trébuchon, Agnès and Carron, Romain and Bénar, Christian-G. and Dehaene, Stanislas and King, Jean-Rémi , year =. Dimensionality and Ramping: Signatures of Sentence Integration in the Dynamics of Brains and Deep Language Models , volume =. The Journal of N...
-
[69]
Disentangling Semantic Composition and Semantic Association in the Left Temporal Lobe , volume =
Li, Jixing and Pylkk\". Disentangling Semantic Composition and Semantic Association in the Left Temporal Lobe , volume =. The Journal of Neuroscience , publisher =. doi:10.1523/jneurosci.2317-20.2021 , number =
-
[70]
Human-like systematic generalization through a meta-learning neural network , author=. Nature , volume=. 2023 , publisher=
work page 2023
-
[71]
Baroni, Marco and Zamparelli, Roberto. Nouns are Vectors, Adjectives are Matrices: Representing Adjective-Noun Constructions in Semantic Space. Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. 2010
work page 2010
-
[72]
Smolensky, Paul and McCoy, Richard Thomas and Fernandez, Roland and Goldrick, Matthew and Gao, Jianfeng , year =. Neurocompositional computing: From the Central Paradox of Cognition to a new generation of AI systems , volume =. AI Magazine , publisher =. doi:10.1002/aaai.12065 , number =
-
[73]
Smolensky, Paul , year =. Tensor Product Variable Binding and the Representation of Symbolic Structures in Connectionist Systems , ISBN =. doi:10.7551/mitpress/2102.003.0006 , booktitle =
-
[74]
Proceedings of the IEEE , year=
A Review of Relational Machine Learning for Knowledge Graphs , author=. Proceedings of the IEEE , year=
-
[75]
Whittington, James C.R. and Muller, Timothy H. and Mark, Shirley and Chen, Guifen and Barry, Caswell and Burgess, Neil and Behrens, Timothy E.J. , year =. The Tolman-Eichenbaum Machine: Unifying Space and Relational Memory through Generalization in the Hippocampal Formation , volume =. Cell , publisher =. doi:10.1016/j.cell.2020.10.024 , number =
-
[76]
A review of relational machine learning for knowledge graphs
Nickel, Maximilian and Murphy, Kevin and Tresp, Volker and Gabrilovich, Evgeniy , year =. A Review of Relational Machine Learning for Knowledge Graphs , volume =. Proceedings of the IEEE , publisher =. doi:10.1109/jproc.2015.2483592 , number =
-
[77]
Translating embeddings for modeling multi-relational data , year =
Bordes, Antoine and Usunier, Nicolas and Garcia-Dur\'. Translating embeddings for modeling multi-relational data , year =. Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 , pages =
-
[78]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Biderman, Stella and Schoelkopf, Hailey and Anthony, Quentin and Bradley, Herbie and O'Brien, Kyle and Hallahan, Eric and Khan, Mohammad Aflah and Purohit, Shivanshu and Prashanth, USVSN Sai and Raff, Edward and Skowron, Aviya and Sutawika, Lintang and Van Der Wal, Oskar , title =. Proceedings of the 40th International Conference on Machine Learning , art...
work page 2023
-
[79]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[80]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.